Bridging VideoQA and Video-Guided Agentic Tasks via Generalized Keyframe Extraction
Pith reviewed 2026-06-30 07:45 UTC · model grok-4.3
The pith
A keyframe extraction method that weighs task relevance against scene changes improves results on both VideoQA and video-guided GUI agent tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
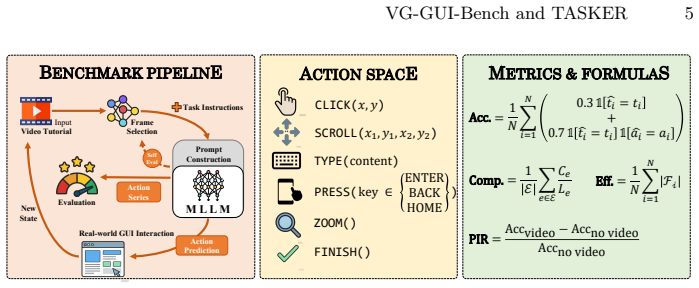
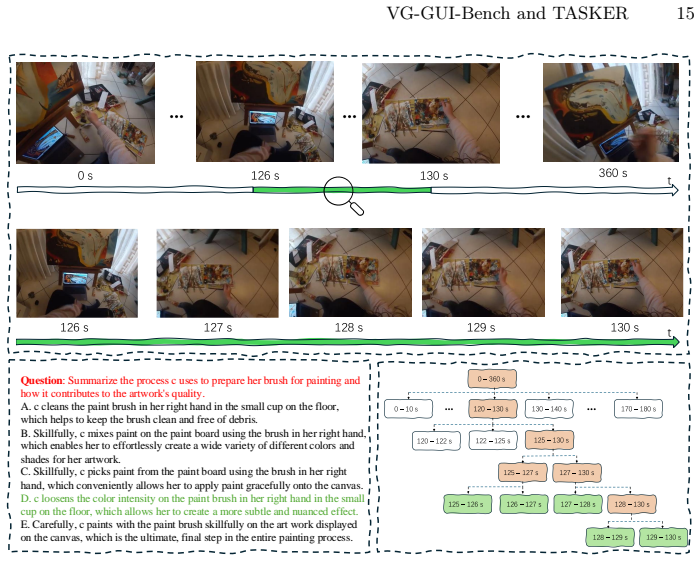
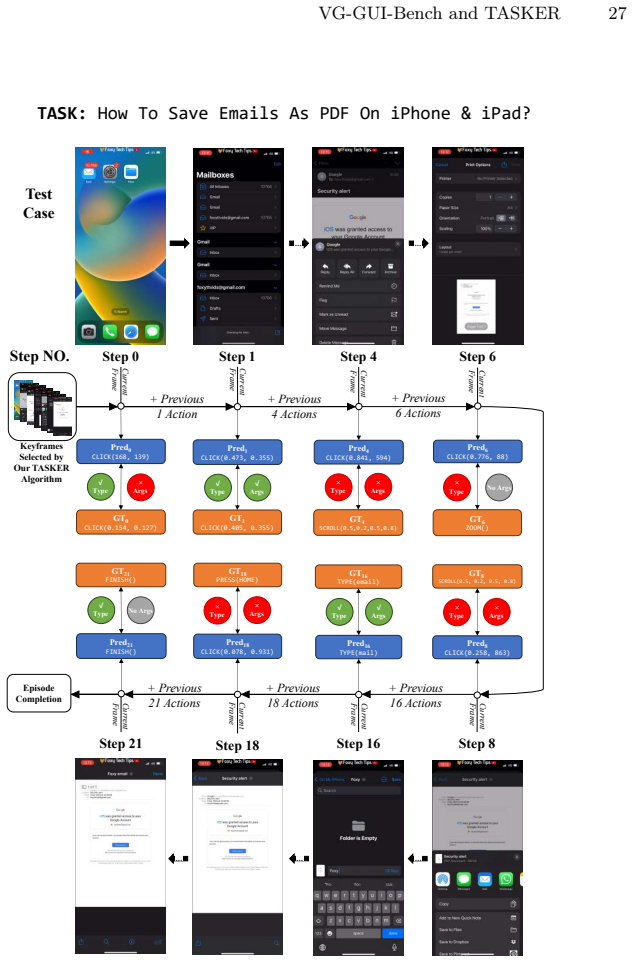
TASKER is a keyframe extraction algorithm that jointly considers task relevance and scene dynamics to identify informative frames, producing measurable gains on VideoQA datasets and on the introduced VG-GUIBench for video-guided GUI agents.
What carries the argument
TASKER (Task-driven And Scene-aware Keyframe searchER), the algorithm that selects keyframes by balancing task relevance and scene dynamics.
If this is right
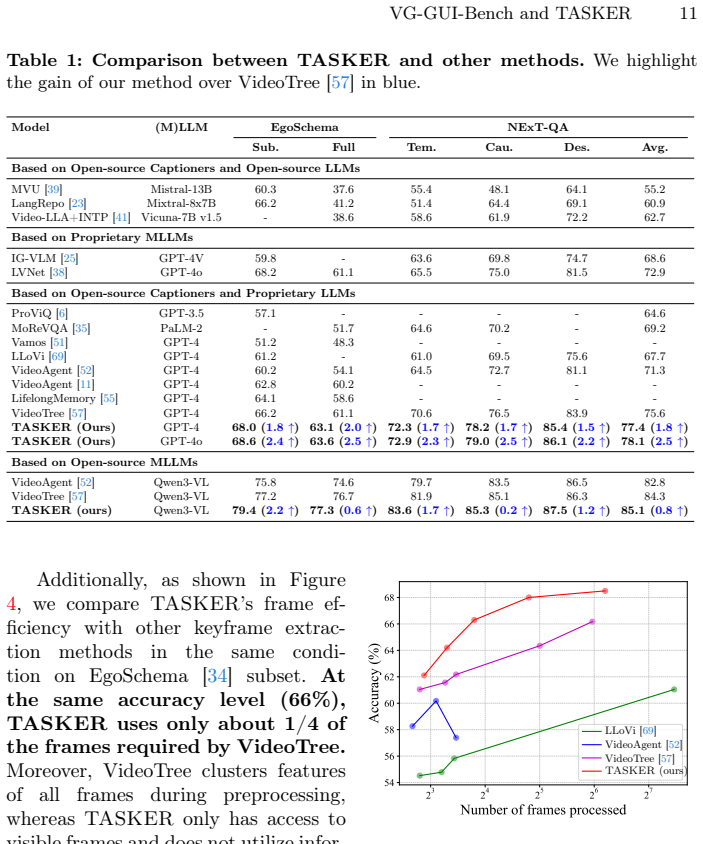
- TASKER raises accuracy 2.0 percent above the strongest baseline on the EgoSchema full set.
- TASKER raises accuracy 1.8 percent above the strongest baseline on the NExT-QA dataset.
- Effective keyframe extraction matters for both short VideoQA questions and longer video-guided GUI tasks.
- VG-GUIBench supplies a concrete way to measure whether models can translate video tutorials into GUI actions.
Where Pith is reading between the lines
- The same selection logic could be tested on robotic manipulation videos to see whether task-aware frames help agents learn physical procedures.
- If the method scales, real-time systems might process only a few dozen frames instead of entire videos and still retain most performance.
- Extending VG-GUIBench beyond desktop interfaces would clarify whether the keyframe principle applies to other long-horizon agent settings.
Load-bearing premise
The performance of models on both VideoQA and video-guided agentic tasks critically depends on effective keyframe extraction.
What would settle it
A test in which models given every video frame or randomly chosen frames match or exceed TASKER's accuracy on EgoSchema, NExT-QA, and VG-GUIBench would undermine the claim.
Figures

read the original abstract
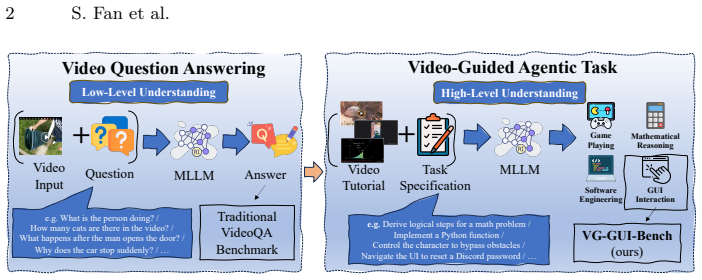
Video understanding is a fundamental capability for multimodal intelligence, and recent Multimodal Large Language Models (MLLMs) have achieved remarkable performance on Video Question Answering (VideoQA) benchmarks. However, existing benchmarks primarily evaluate whether models can perceive shallow visual cues, while rarely examining whether MLLMs can learn deeper knowledge or procedural skills from video tutorials and generalize them to downstream long-horizon agentic tasks. To address this gap, we introduce VG-GUIBench (Video-Guided GUI Benchmark), a new benchmark designed to evaluate whether MLLM-based GUI agents can follow video tutorials to complete corresponding GUI interactive tasks. Furthermore, we observe that the performance of models on both VideoQA and video-guided agentic tasks critically depends on effective keyframe extraction. Based on this observation, we propose TASKER (Task-driven And Scene-aware Keyframe searchER), a keyframe extraction algorithm that jointly considers task relevance and scene dynamics to identify informative frames. Experimental results demonstrate that TASKER achieves significant performance improvements on both VideoQA and video-guided agentic task benchmarks, outperforming the best baseline by 2.0% on the EgoSchema fullset and 1.8% on the NExT-QA dataset, respectively. These results further highlight the potential of generalized keyframe extraction methods for video understanding tasks. Our code and data are available at https://github.com/VG-GUI-TASKER/VG-GUI-TASKER.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces VG-GUIBench, a benchmark for assessing whether MLLM-based GUI agents can follow video tutorials to perform interactive tasks. It proposes TASKER, a keyframe extraction algorithm that jointly optimizes for task relevance and scene dynamics, and reports that this method yields performance gains on VideoQA datasets (EgoSchema fullset +2.0%, NExT-QA +1.8% over the best baseline) while also improving results on the new agentic benchmark, thereby bridging the two task families via generalized keyframe selection. Code and data are released.
Significance. If the empirical claims hold, the work supplies a concrete mechanism (task-driven, scene-aware keyframe search) that demonstrably lifts both perception-oriented VideoQA and procedural agentic tasks, together with a new evaluation resource. The public release of code and data strengthens the contribution by supporting direct replication and extension.
major comments (1)
- [Abstract] Abstract: the central claim that TASKER delivers improvements 'on both VideoQA and video-guided agentic task benchmarks' is only partially quantified. Concrete deltas are supplied solely for EgoSchema (+2.0%) and NExT-QA (+1.8%); no accuracy, success rate, or baseline comparison is stated for VG-GUIBench. Because the bridging thesis rests on gains in the agentic setting, the absence of these numbers is load-bearing.
minor comments (2)
- [Abstract] The abstract states that model performance 'critically depends on effective keyframe extraction' yet supplies no supporting ablation or correlation analysis in the provided text; a brief quantitative justification for this premise would strengthen the motivation.
- [Experimental Results] Experimental methodology details (number of runs, statistical tests, exact TASKER hyperparameters, and VG-GUIBench construction protocol) are referenced only at a high level; these should be expanded in §4 or the appendix to allow assessment of the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract should quantify the gains on VG-GUIBench to fully support the bridging claim between VideoQA and agentic tasks.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that TASKER delivers improvements 'on both VideoQA and video-guided agentic task benchmarks' is only partially quantified. Concrete deltas are supplied solely for EgoSchema (+2.0%) and NExT-QA (+1.8%); no accuracy, success rate, or baseline comparison is stated for VG-GUIBench. Because the bridging thesis rests on gains in the agentic setting, the absence of these numbers is load-bearing.
Authors: We agree with the observation. The full manuscript reports concrete success-rate improvements on VG-GUIBench (e.g., +X% over the strongest baseline), but these numbers were omitted from the abstract. In the revision we will insert the missing quantitative results for VG-GUIBench into the abstract so that the bridging claim is fully supported by explicit deltas on both task families. revision: yes
Circularity Check
No significant circularity; derivation is self-contained empirical proposal
full rationale
The paper introduces VG-GUIBench as a new benchmark and proposes TASKER as a keyframe extraction method based on an observation about performance dependence on keyframe quality. It reports concrete numerical gains only on VideoQA datasets (EgoSchema, NExT-QA) without any equations, fitted parameters renamed as predictions, self-citations that bear the central load, or reductions of claims to inputs by construction. No load-bearing step equates a result to its own definition or prior self-work; the method is presented as a joint consideration of task relevance and scene dynamics with external benchmark validation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Bai, S., Cai, Y., Chen, R., Chen, K., Chen, X., Cheng, Z., Deng, L., Ding, W., Gao, C., Ge, C., Ge, W., Guo, Z., Huang, Q., Huang, J., Huang, F., Hui, B., Jiang, S., Li, Z., Li, M., Li, M., Li, K., Lin, Z., Lin, J., Liu, X., Liu, J., Liu, C., Liu, Y., Liu, D., Liu, S., Lu, D., Luo, R., Lv, C., Men, R., Meng, L., Ren, X., Ren, X., Song, S., Sun, Y., Tang, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
In: Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H
Brown, T.B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Nee- lakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D.M., Wu, J., Win- ter, C., Hesse, C., Chen, M., Sigler, E., Litwin, M., Gray, S., Chess, B., Clark, J., Berner, C., McCandlish, S., Radford...
2020
-
[3]
Carreira, J., Zisserman, A.: Quo vadis, action recognition? A new model and the kineticsdataset.In:2017IEEEConferenceonComputerVisionandPatternRecog- nition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017. pp. 4724–4733. IEEE (2017).https://doi.org/10.1109/CVPR.2017.5024
-
[4]
Chen, Z., Wang, W., Cao, Y., Liu, Y., Gao, Z., Cui, E., Zhu, J., Ye, S., Tian, H., Liu, Z., Gu, L., Wang, X., Li, Q., Ren, Y., Chen, Z., Luo, J., Wang, J., Jiang, T., Wang, B., He, C., Shi, B., Zhang, X., Lv, H., Wang, Y., Shao, W., Chu, P., Tu, Z., He, T., Wu, Z., Deng, H., Ge, J., Chen, K., Zhang, K., Wang, L., Dou, M., Lu, L., Zhu, X., Lu, T., Lin, D.,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Cheng, Z., Leng, S., Zhang, H., Xin, Y., Li, X., Chen, G., Zhu, Y., Zhang, W., Luo, Z., Zhao, D., Bing, L.: Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms (2024),https://arxiv.org/abs/2406.07476 26
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Choudhury, R., Niinuma, K., Kitani, K.M., Jeni, L.A.: Video question answering with procedural programs. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision - ECCV 2024 - 18th Euro- pean Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXXVIII. Lecture Notes in Computer Science, v...
- [7]
-
[8]
Dou, S., Zhang, M., Yin, Z., Huang, C., Shen, Y., Wang, J., Chen, J., Ni, Y., Ye, J., Zhang, C., Xie, H., Hu, J., Wang, S., Wang, W., Xiao, Y., Liu, Y., Xu, Z., Guo, Z., Zhou, P., Gui, T., Wu, Z., Qiu, X., Zhang, Q., Huang, X., Jiang, Y.G., Wang, D., Yao, S.: CL-bench: A benchmark for context learning (2026), https://arxiv.org/abs/2602.035874 VG-GUI-Bench...
-
[9]
In: Belgrave, D., Zhang, C., Montoya, L.N., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N., Ruíz, I.V.M., Loaiza-Bonilla, A
Fan, S., Cui, J., Guo, M., Yang, S.: Tool-augmented spatiotemporal reasoning for streamlining video question answering task. In: Belgrave, D., Zhang, C., Montoya, L.N., Lin, H., Pascanu, R., Koniusz, P., Ghassemi, M., Chen, N., Ruíz, I.V.M., Loaiza-Bonilla, A. (eds.) Advances in Neural Information Processing Systems 38: Annual Conference on Neural Informa...
2025
- [10]
-
[11]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Fan, Y., Ma, X., Wu, R., Du, Y., Li, J., Gao, Z., Li, Q.: VideoAgent: A memory- augmented multimodal agent for video understanding. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XXII. Lecture Notes ...
-
[13]
Gao, L., Zhong, Y., Zeng, Y., Tan, H., Li, D., Zhao, Z.: Linvt: Empower your image-level large language model to understand videos (2024),https://arxiv. org/abs/2412.0518525
-
[14]
In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagstaff, K., Zhu, J
Guo, M., Xu, J., Zhang, Y., Song, J., Peng, H., Deng, Y., Dong, X., Nakayama, K., Geng, Z., Wang, C., Ni, B., Yang, G., Rao, Y., Peng, H., Hu, H., Wetzstein, G., Hu, S.: Rbench: Graduate-level multi-disciplinary benchmarks for LLM & MLLM complex reasoning evaluation. In: Singh, A., Fazel, M., Hsu, D., Lacoste-Julien, S., Berkenkamp, F., Maharaj, T., Wagst...
2025
-
[15]
Gupta, T., Kembhavi, A.: Visual programming: Compositional visual reasoning without training. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023. pp. 14953– 14962. IEEE (2023).https://doi.org/10.1109/CVPR52729.2023.014364
-
[16]
Hara, K., Kataoka, H., Satoh, Y.: Can spatiotemporal 3d cnns retrace the history of 2d cnns and imagenet? In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018. pp. 6546–6555. IEEE (2018).https://doi.org/10.1109/CVPR.2018.006854
-
[17]
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016. pp. 770–778. IEEE (2016).https: //doi.org/10.1109/CVPR.2016.904
-
[18]
Cogagent: A visual language model for gui agents, 2024
Hong, W., Wang, W., Lv, Q., Xu, J., Yu, W., Ji, J., Wang, Y., Wang, Z., Zhang, Y., Li, J., Xu, B., Dong, Y., Ding, M., Tang, J.: Cogagent: A visual language model for gui agents (2024),https://arxiv.org/abs/2312.0891426 18 S. Fan et al
- [19]
- [20]
-
[21]
Jang, Y., Song, Y., Sohn, S., Logeswaran, L., Luo, T., Kim, D., Bae, K., Lee, H.: Scalable video-to-dataset generation for cross-platform mobile agents. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 8604–8614. IEEE (2025).https: //doi.org/10.1109/CVPR52734.2025.008044, 5
- [22]
-
[23]
Rethinking cross-subject data splitting for brain-to-text decoding
Kahatapitiya, K., Ranasinghe, K., Park, J., Ryoo, M.S.: Language repository for long video understanding. In: Che, W., Nabende, J., Shutova, E., Pilehvar, M.T. (eds.) Findings of the Association for Computational Linguistics, ACL 2025, Vi- enna, Austria, July 27 - August 1, 2025. pp. 5627–5646. Findings of ACL, Associa- tion for Computational Linguistics ...
-
[24]
Computational Visual Media11(3), 655–667 (2025).https://doi.org/ 10.26599/CVM.2025.94504164
Karacan, L., Sarıgül, M.: Full-frame video stabilization via spatiotemporal trans- formers. Computational Visual Media11(3), 655–667 (2025).https://doi.org/ 10.26599/CVM.2025.94504164
-
[25]
Kim, W., Choi, C., Lee, W., Rhee, W.: An image grid can be worth a video: Zero- shot video question answering using a vlm (2024),https://arxiv.org/abs/2403. 1840611
2024
-
[26]
Li, K., Wang, Y., He, Y., Li, Y., Wang, Y., Liu, Y., Wang, Z., Xu, J., Chen, G., Luo, P., Wang, L., Qiao, Y.: Mvbench: A comprehensive multi-modal video understanding benchmark (2024),https://arxiv.org/abs/2311.1700526
work page internal anchor Pith review Pith/arXiv arXiv 2024
- [27]
-
[28]
In: Al-Onaizan, Y., Bansal, M., Chen, Y
Lin, B., Ye, Y., Zhu, B., Cui, J., Ning, M., Jin, P., Yuan, L.: Video-llava: Learn- ing united visual representation by alignment before projection. In: Al-Onaizan, Y., Bansal, M., Chen, Y. (eds.) Proceedings of the 2024 Conference on Empir- ical Methods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024. pp. 5971–5984. Assoc...
-
[29]
SWITCH: Benchmarking Modeling and Handling of Tangible Interfaces in Long-horizon Embodied Scenarios
Lin, J., Yu, Z., Karlsson, B.F.: Switch: Benchmarking modeling and handling of tangible interfaces in long-horizon embodied scenarios (2026),https://arxiv. org/abs/2511.176494
work page internal anchor Pith review Pith/arXiv arXiv 2026
- [30]
-
[31]
In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C
Lin, K.Q., Li, L., Gao, D., Wu, Q., Yan, M., Yang, Z., Wang, L., Shou, M.Z.: VideoGUI: A benchmark for GUI automation from instructional videos. In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C. (eds.) Advances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems ...
2024
- [32]
- [33]
-
[34]
In: Oh, A., Nau- mann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S
Mangalam, K., Akshulakov, R., Malik, J.: Egoschema: A diagnostic bench- mark for very long-form video language understanding. In: Oh, A., Nau- mann, T., Globerson, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Information Processing Systems 36: Annual Conference on Neu- ral Information Processing Systems 2023, NeurIPS 2023, New Orleans, ...
2023
-
[35]
Bootstrapping SparseFormers from vision foundation models
Min, J., Buch, S., Nagrani, A., Cho, M., Schmid, C.: Morevqa: Exploring mod- ular reasoning models for video question answering. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024. pp. 13235–13245. IEEE (2024).https://doi.org/10.1109/ CVPR52733.2024.0125711
-
[36]
In: Ku, L., Martins, A., Srikumar, V
Nguyen, T., Bin, Y., Xiao, J., Qu, L., Li, Y., Wu, J.Z., Nguyen, C., Ng, S., Luu, A.T.: Video-language understanding: A survey from model architecture, model training, and data perspectives. In: Ku, L., Martins, A., Srikumar, V. (eds.) Findings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16,...
-
[37]
Computational Visual Media12(1), 71–84 (2026).https://doi
Ning, M., Zhu, B., Xie, Y., Lin, B., Cui, J., Yuan, L., Chen, D., Yuan, L.: Video- bench: A comprehensive benchmark and toolkit for evaluating video-based large language models. Computational Visual Media12(1), 71–84 (2026).https://doi. org/10.26599/CVM.2025.94505164
-
[38]
Park, J., Ranasinghe, K., Kahatapitiya, K., Ryu, W., Kim, D., Ryoo, M.S.: Too many frames, not all useful: Efficient strategies for long-form video QA. In: Dem- berg, V., Inui, K., Marquez, L. (eds.) Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2026 - Volume 1: Long Papers, Rabat, Morocc...
-
[39]
In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 (2025), https://openreview.net/forum?id=OxKi02I29I11
Ranasinghe, K., Li, X., Kahatapitiya, K., Ryoo, M.S.: Understanding long videos with multimodal language models. In: The Thirteenth International Conference on Learning Representations, ICLR 2025, Singapore, April 24-28, 2025 (2025), https://openreview.net/forum?id=OxKi02I29I11
2025
-
[40]
In: Proceedings of Machine Learning Research
Ren, J., Zhao, Y., Vu, T., Liu, P.J., Lakshminarayanan, B.: Self-evaluation im- proves selective generation in large language models. In: Proceedings of Machine Learning Research. vol. 239, pp. 49–64. PMLR (2023),https://proceedings. mlr.press/v239/ren23a.html9
2023
- [41]
-
[42]
Fan et al
Shen, X., Xiong, Y., Zhao, C., Wu, L., Chen, J., Zhu, C., Liu, Z., Xiao, F., Varadarajan, B., Bordes, F., Liu, Z., Xu, H., Kim, H.J., Soran, B., Krishnamoor- 20 S. Fan et al. thi, R., Elhoseiny, M., Chandra, V.: LongVU: Spatiotemporal adaptive compres- sion for long video-language understanding. In: Proceedings of the 42nd Inter- national Conference on Ma...
2025
-
[43]
In: Oh, A., Naumann, T., Glober- son, A., Saenko, K., Hardt, M., Levine, S
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., Yao, S.: Reflexion: lan- guage agents with verbal reinforcement learning. In: Oh, A., Naumann, T., Glober- son, A., Saenko, K., Hardt, M., Levine, S. (eds.) Advances in Neural Infor- mation Processing Systems 36: Annual Conference on Neural Information Pro- cessing Systems 2023, NeurIPS 2023, New Orlea...
2023
-
[44]
Song, C.H., Song, Y., Goyal, P., Su, Y., Riva, O., Palangi, H., Pfister, T.: Watch and learn: Learning to use computers from online videos (2026),https://arxiv. org/abs/2510.046734
- [45]
-
[46]
Sun, Y., Zhao, S., Yu, T., Wen, H., Va, S., Xu, M., Li, Y., Zhang, C.: GUI-Xplore: Empowering generalizable GUI agents with one exploration. In: IEEE/CVF Con- ference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 19477–19486. IEEE (2025).https://doi.org/10. 1109/CVPR52734.2025.018144
-
[47]
Tang, Y., Bi, J., Xu, S., Song, L., Liang, S., Wang, T., Zhang, D., An, J., Lin, J., Zhu, R., Vosoughi, A., Huang, C., Zhang, Z., Liu, P., Feng, M., Zheng, F., Zhang, J., Luo, P., Luo, J., Xu, C.: Video understanding with large language models: A survey (2024),https://arxiv.org/abs/2312.174324
-
[48]
Tran, D., Bourdev, L.D., Fergus, R., Torresani, L., Paluri, M.: Learning spatiotem- poral features with 3d convolutional networks. In: 2015 IEEE International Con- ference on Computer Vision, ICCV 2015, Santiago, Chile, December 7-13, 2015. pp. 4489–4497. IEEE (2015).https://doi.org/10.1109/ICCV.2015.5104
-
[49]
Computational Visual Media11(4), 849–869 (2025).https://doi.org/10.26599/ CVM.2025.94505024
Wang, J.W., Shen, L.Y.: Spatiotemporal fusion transformer for video demoiréing. Computational Visual Media11(4), 849–869 (2025).https://doi.org/10.26599/ CVM.2025.94505024
- [50]
-
[51]
In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G
Wang, S., Zhao, Q., Do, M.Q., Agarwal, N., Lee, K., Sun, C.: Vamos: Versatile action models for video understanding. In: Leonardis, A., Ricci, E., Roth, S., Rus- sakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part XII. Lecture Notes in Computer Sc...
-
[52]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Wang, X., Zhang, Y., Zohar, O., Yeung-Levy, S.: Videoagent: Long-form video understanding with large language model as agent. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part LXXX. Lecture Notes in Com...
2024
-
[53]
Springer (2024).https://doi.org/10.1007/978-3-031-72989-8_44, 10, 11, 12, 26
- [54]
-
[55]
Wang, Y., Li, K., Li, Y., He, Y., Huang, B., Zhao, Z., Zhang, H., Xu, J., Liu, Y., Wang, Z., Xing, S., Chen, G., Pan, J., Yu, J., Wang, Y., Wang, L., Qiao, Y.: InternVideo: General video foundation models via generative and discriminative learning (2022),https://arxiv.org/abs/2212.031914
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[56]
0526910, 11
Wang, Y., Yang, Y., Ren, M.: Lifelongmemory: Leveraging llms for answering queries in long-form egocentric videos (2024),https://arxiv.org/abs/2312. 0526910, 11
2024
-
[57]
In: Koenig, S., Jenk- ins, C., Taylor, M.E
Wang, Z., Chen, B., Yue, Z., Wang, Y., Qiao, Y., Wang, L., Wang, Y.: Videochat- a1: Thinking with long videos by chain-of-shot reasoning. In: Koenig, S., Jenk- ins, C., Taylor, M.E. (eds.) Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innovative Applications of Artificial Intelligence, Sixteenth Symposium on Educational ...
-
[58]
Wang, Z., Yu, S., Stengel-Eskin, E., Yoon, J., Cheng, F., Bertasius, G., Bansal, M.: VideoTree: Adaptive tree-based video representation for LLM reasoning on long videos. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 3272–3283. IEEE (2025). https://doi.org/10.1109/CVPR52734.2025.00...
-
[59]
In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G
Weng, Y., Han, M., He, H., Chang, X., Zhuang, B.: LongVLM: Efficient long video understanding via large language models. In: Leonardis, A., Ricci, E., Roth, S., Russakovsky, O., Sattler, T., Varol, G. (eds.) Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, PartXXXIII.LectureNotesinComputerSci...
-
[60]
In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C
Wu, H., Li, D., Chen, B., Li, J.: Longvideobench: A benchmark for long- context interleaved video-language understanding. In: Globersons, A., Mackey, L., Belgrave, D., Fan, A., Paquet, U., Tomczak, J.M., Zhang, C. (eds.) Ad- vances in Neural Information Processing Systems 37: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, V...
2024
-
[61]
Xiao, J., Huang, N., Qin, H., Li, D., Li, Y., Zhu, F., Tao, Z., Yu, J., Lin, L., Chua, T., Yao, A.: Videoqa in the era of llms: An empirical study. Int. J. Comput. Vis. 133(7), 3970–3993 (2025).https://doi.org/10.1007/S11263-025-02385-84
-
[62]
In: IEEE Conference on Computer Vi- sion and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021
Xiao, J., Shang, X., Yao, A., Chua, T.: NExT-QA: Next phase of question- answering to explaining temporal actions. In: IEEE Conference on Computer Vi- sion and Pattern Recognition, CVPR 2021, virtual, June 19-25, 2021. pp. 9777–
2021
-
[63]
IEEE (2021).https://doi.org/10.1109/CVPR46437.2021.009653, 4, 10, 25, 26
-
[64]
Fan et al
Xie, T., Zhang, D., Chen, J., Li, X., Zhao, S., Cao, R., Hua, T.J., Cheng, Z., Shin, D., Lei, F., Liu, Y., Xu, Y., Zhou, S., Savarese, S., Xiong, C., Zhong, V., Yu, T.: OS- World: Benchmarking multimodal agents for open-ended tasks in real computer en- vironments.In:Globersons,A.,Mackey,L.,Belgrave,D.,Fan,A.,Paquet,U.,Tom- 22 S. Fan et al. czak, J.M., Zha...
2024
-
[65]
Yang, J., Zhang, H., Li, F., Zou, X., Li, C., Gao, J.: Set-of-mark prompting un- leashes extraordinary visual grounding in gpt-4v (2023),https://arxiv.org/abs/ 2310.114414, 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[66]
In: Salakhutdinov, R., Kolter, Z., Heller, K.A., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F
Yang, Z., Chen, G., Li, X., Wang, W., Yang, Y.: Doraemongpt: Toward under- standing dynamic scenes with large language models (exemplified as A video agent). In: Salakhutdinov, R., Kolter, Z., Heller, K.A., Weller, A., Oliver, N., Scarlett, J., Berkenkamp, F. (eds.) Forty-first International Conference on Ma- chine Learning, ICML 2024, Vienna, Austria, Ju...
2024
-
[67]
Ye, J., Wang, Z., Sun, H., Chandrasegaran, K., Durante, Z., Eyzaguirre, C., Bisk, Y., Niebles, J.C., Adeli, E., Fei-Fei, L., Wu, J., Li, M.: Re-thinking temporal search for long-form video understanding. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 8579–8591. IEEE (2025).https://d...
-
[68]
Yu, S., Ling, Y., Fang, C., Zhou, Q., Zhao, Y., Chen, C., Zhu, S., Chen, Z.: LLM- guided scenario-based gui testing (2025),https://arxiv.org/abs/2506.05079 4
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[69]
Computational Visual Media12(3), 615–642 (2026).https://doi.org/10.26599/CVM.2025.94504614
Zhang, B., Guo, Y., Yang, R., Zhang, Z., Xie, J., Suo, J.: Darkvision: A benchmark and study for low-light image/video analysis. Computational Visual Media12(3), 615–642 (2026).https://doi.org/10.26599/CVM.2025.94504614
-
[70]
In: Koenig, S., Jenkins, C., Taylor, M.E
Zhang, B., Shang, Z., Gao, Z., Zhang, W., Xie, R., Ma, X., Yuan, T., Wu, X., Zhu, S., Li, Q.: Tongui: Internet-scale trajectories from multimodal web tutorials for generalized GUI agents. In: Koenig, S., Jenkins, C., Taylor, M.E. (eds.) Fortieth AAAI Conference on Artificial Intelligence, Thirty-Eighth Conference on Innova- tive Applications of Artificial...
-
[71]
Zhang, C., Lu, T., Islam, M.M., Wang, Z., Yu, S., Bansal, M., Bertasius, G.: A sim- ple LLM framework for long-range video question-answering. In: Al-Onaizan, Y., Bansal,M.,Chen,Y.(eds.)Proceedingsofthe2024ConferenceonEmpiricalMeth- ods in Natural Language Processing, EMNLP 2024, Miami, FL, USA, November 12-16, 2024. pp. 21715–21737. Association for Compu...
-
[72]
In: Feng, Y., Lefever, E
Zhang, H., Li, X., Bing, L.: Video-llama: An instruction-tuned audio-visual lan- guage model for video understanding. In: Feng, Y., Lefever, E. (eds.) Proceed- ings of the 2023 Conference on Empirical Methods in Natural Language Process- ing, EMNLP 2023 - System Demonstrations, Singapore, December 6-10, 2023. pp. 543–553. Association for Computational Lin...
2023
- [73]
-
[74]
Zhang, Y., Guo, X., Goh, Y., Hu, J., Chen, Z., Wang, X., Gao, D., Shou, M.Z.: Showui-aloha: Human-taught gui agent (2026),https://arxiv.org/abs/2601. 071814
2026
- [75]
-
[76]
In: Goldberg, Y., Kozareva, Z., Zhang, Y
Zhong, Y., Ji, W., Xiao, J., Li, Y., Deng, W., Chua, T.: Video question answer- ing: Datasets, algorithms and challenges. In: Goldberg, Y., Kozareva, Z., Zhang, Y. (eds.) Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi, United Arab Emirates, Decem- ber 7-11, 2022. pp. 6439–6455. Association for...
-
[77]
Zhou, J., Shu, Y., Zhao, B., Wu, B., Liang, Z., Xiao, S., Qin, M., Yang, X., Xiong, Y., Zhang, B., Huang, T., Liu, Z.: MLVU: benchmarking multi-task long video un- derstanding. In: IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, CVPR 2025, Nashville, TN, USA, June 11-15, 2025. pp. 13691–13701. IEEE (2025).https://doi.org/10.1109/CVPR5273...
-
[78]
Without seeing the frames in this segment, the operation flow has an unexplained gap
GOAL PROXIMITY: The segment likely contains crucial missing UI actions that are necessary steps toward achieving the Goal. Without seeing the frames in this segment, the operation flow has an unexplained gap
-
[79]
frame_descriptions
STATE CHANGE MAGNITUDE: Look at the start frame and end frame images of each segment. The segment whose boundary frames show the MOST different UI states is more likely to contain important operations. In GUI operations, even subtle visual differences can represent critical steps (e.g., a single checkbox toggle, a dropdown selection, text typed into a fie...
-
[80]
This is the screen you must interact with
**Target Screen (The ONLY image):** This is the Current State of the device UI. This is the screen you must interact with. YOUR REASONING PROCESS:
-
[81]
Task Goal
**Understand the goal:** Read the "Task Goal" to understand what the user is trying to accomplish
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.