Pareto-Guided Teacher Alignment for Fair Personalized Text Generation
Pith reviewed 2026-06-27 16:05 UTC · model grok-4.3
The pith
Fairness mitigation effects in personalized persuasive text generation depend on the specific objective and transfer inconsistently across domains and models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
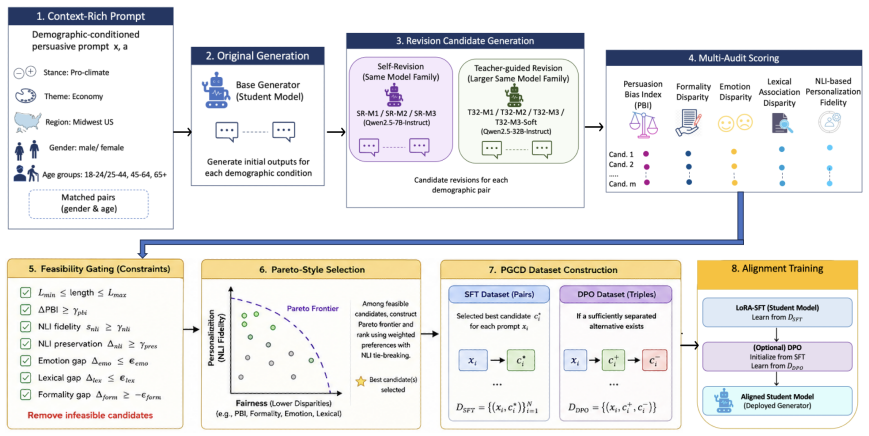
No single alignment strategy simultaneously minimizes persuasion bias, formality disparity, emotional framing disparity, and lexical association disparity while maintaining personalization fidelity and demographic stability. Methods occupy distinct positions on a fairness-personalization Pareto frontier: some deliver stronger disparity reductions at the expense of fidelity or stability, while others preserve personalization better. Fairness mitigation outcomes prove objective-dependent and transfer inconsistently between the climate and vaccination domains as well as across model families.
What carries the argument
The Pareto-guided teacher alignment framework, which combines revision-based candidate generation, pair-aware feasibility gating, Pareto-style candidate selection, and optional preference optimization via supervised fine-tuning or direct preference optimization.
If this is right
- Different alignment strategies occupy distinct regions of the fairness-personalization Pareto frontier.
- Stronger reductions in one disparity type often come with weaker performance on personalization fidelity or other disparities.
- Mitigation outcomes vary systematically by objective across the five audits.
- Performance does not transfer reliably between the climate-change and vaccination domains.
- Inconsistent cross-family transfer favors bounded-regression multi-audit selection over single-metric optimization.
Where Pith is reading between the lines
- Applications may need to choose frontier points based on which disparity matters most for their use case.
- The same framework could be tested on conditioning variables beyond gender and age.
- Automated navigation of the Pareto surface might reduce the need for exhaustive manual audits.
- Domain-specific re-auditing appears necessary before deployment in new contexts.
Load-bearing premise
The controlled demographic grid with matched gender and age pairs together with the unified five-audit suite accurately and unbiasedly measure persuasion bias, formality disparity, emotional framing disparity, lexical association disparity, and personalization fidelity.
What would settle it
A single alignment strategy that achieves the best score on all five audits in both domains and also transfers successfully to additional model families would falsify the claim that effects are objective-dependent and inconsistent.
Figures
read the original abstract
Personalized persuasive text generation can improve relevance and engagement, but demographic conditioning may also introduce unequal framing across groups. We study fairness mitigation in personalized generation as a constrained multi-objective alignment problem: reduce demographic disparities while preserving personalization fidelity. We propose a Pareto-guided teacher alignment framework that combines revision-based candidate generation, pair-aware feasibility gating, Pareto-style candidate selection, and optional preference optimization through supervised fine-tuning and direct preference optimization. We evaluate the framework on climate change and vaccination persuasion tasks using a controlled context-rich demographic grid with matched gender and age pairs and a unified five-audit evaluation suite spanning persuasion bias, formality disparity, emotional framing disparity, lexical association disparity, and personalization fidelity. Across both domains and cross-family transfer settings, no single alignment strategy dominates all objectives simultaneously. Instead, methods occupy different regions of a fairness-personalization Pareto frontier: some achieve stronger disparity reductions, while others better preserve personalization or demographic stability. Our results show that fairness mitigation effects are objective-dependent and transfer inconsistently across domains and model families, motivating bounded-regression, multi-audit model selection over single-metric optimization for fairness-sensitive personalized generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a Pareto-guided teacher alignment framework for fair personalized text generation that combines revision-based candidate generation, pair-aware feasibility gating, Pareto-style candidate selection, and optional preference optimization (SFT/DPO). It evaluates the approach on climate-change and vaccination persuasion tasks using a matched demographic grid (gender/age pairs) and a unified five-audit suite that measures persuasion bias, formality disparity, emotional framing disparity, lexical association disparity, and personalization fidelity. The central empirical claim is that no single alignment strategy dominates all objectives; methods occupy distinct regions of the fairness-personalization Pareto frontier, fairness-mitigation effects are objective-dependent and transfer inconsistently across domains and model families, and this motivates bounded-regression multi-audit model selection over single-metric optimization.
Significance. If the five-audit measurements are shown to be valid and unconfounded, the work supplies concrete evidence that single-objective fairness optimization is insufficient for personalized generation and that Pareto-style multi-objective selection is practically necessary. The cross-domain and cross-family transfer results would be a useful addition to the literature on fairness trade-offs in controllable text generation.
major comments (1)
- [evaluation section (five-audit suite description)] The headline result—that fairness mitigation effects are objective-dependent and transfer inconsistently—rests entirely on the outputs of the five-audit suite applied to the demographic grid. The manuscript supplies no information on audit construction, human validation, inter-audit correlation, or controls for prompt-length/lexical confounders that could induce spurious objective dependence (see the evaluation section describing the unified five-audit suite). Without such evidence the observed Pareto regions and cross-domain inconsistency cannot be interpreted as support for the claimed objective-dependence.
minor comments (2)
- The abstract states that the framework includes 'optional preference optimization through supervised fine-tuning and direct preference optimization' but does not indicate the conditions under which the optional step is invoked or its incremental contribution to the reported Pareto fronts.
- A summary table reporting all five audit scores for every method, domain, and model family would make the claimed non-dominance and Pareto occupation concrete and easier to verify.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [evaluation section (five-audit suite description)] The headline result—that fairness mitigation effects are objective-dependent and transfer inconsistently—rests entirely on the outputs of the five-audit suite applied to the demographic grid. The manuscript supplies no information on audit construction, human validation, inter-audit correlation, or controls for prompt-length/lexical confounders that could induce spurious objective dependence (see the evaluation section describing the unified five-audit suite). Without such evidence the observed Pareto regions and cross-domain inconsistency cannot be interpreted as support for the claimed objective-dependence.
Authors: We agree that expanded documentation of the five-audit suite is necessary to support the headline claims. In the revised manuscript we will add: (1) explicit construction details for each audit, including the exact prompts, scoring functions, and base models used; (2) a human validation study on a stratified sample of outputs with inter-annotator agreement statistics; (3) pairwise correlation matrices among the five audits; and (4) explicit controls for prompt-length and lexical confounders via matched templates across demographic groups together with reported length and token-overlap statistics. These additions will allow readers to evaluate whether the observed objective dependence is robust. revision: yes
Circularity Check
No significant circularity; empirical results independent of definitions
full rationale
The paper proposes a Pareto-guided alignment framework (revision-based generation, feasibility gating, Pareto selection, optional SFT/DPO) and reports its effects on fairness-personalization tradeoffs via a fixed demographic grid and five-audit suite. No load-bearing step reduces by construction to a fitted input, self-definition, or self-citation chain; the headline finding that mitigation effects are objective-dependent follows directly from applying the described methods and audits to the tasks. The evaluation is presented as an external measurement rather than a tautology, satisfying the self-contained criterion.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Andrea E Abele and Bogdan Wojciszke. 2018. Agency and communion in social psychology, volume 10. Routledge London, UK
2018
-
[2]
Axel Abels and Tom Lenaerts. 2025. Wisdom from diversity: bias mitigation through hybrid human-llm crowds. In Proceedings of the Thirty-Fourth International Joint Conference on Artificial Intelligence, pages 321--329
2025
-
[3]
Favour Y Aghaebe, Elizabeth A Williams, Tanefa Apekey, and Nafise Sadat Moosavi. 2025. Llms do not see age: Assessing demographic bias in automated systematic review synthesis. In Proceedings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Lin...
2025
-
[4]
Nikolay Babakov, David Dale, Ilya Gusev, Irina Krotova, and Alexander Panchenko. 2023. Don't lose the message while paraphrasing: A study on content preserving style transfer. In Natural Language Processing and Information Systems, pages 47--61, Cham. Springer Nature Switzerland
2023
-
[5]
Hui Bai, Jan G Voelkel, Shane Muldowney, Johannes C Eichstaedt, and Robb Willer. 2025. Llm-generated messages can persuade humans on policy issues. Nature Communications, 16(1):6037
2025
-
[6]
Pragyan Banerjee, Abhinav Java, Surgan Jandial, Simra Shahid, Shaz Furniturewala, Balaji Krishnamurthy, and Sumit Bhatia. 2024. All should be equal in the eyes of lms: Counterfactually aware fair text generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 17673--17681
2024
-
[7]
Angana Borah, Rada Mihalcea, and Veronica Perez-Rosas. 2026. https://doi.org/10.18653/v1/2026.eacl-long.234 Persuasion at play: Understanding misinformation dynamics in demographic-aware human- LLM interactions . In Proceedings of the 19th Conference of the E uropean Chapter of the A ssociation for C omputational L inguistics (Volume 1: Long Papers) , pag...
-
[8]
Simon Martin Breum, Daniel V dele Egdal, Victor Gram Mortensen, Anders Giovanni M ller, and Luca Maria Aiello. 2024. The persuasive power of large language models. In Proceedings of the International AAAI Conference on Web and Social Media, volume 18, pages 152--163
2024
-
[9]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, and 1 others. 2020. Language models are few-shot learners. Advances in neural information processing systems, 33:1877--1901
2020
-
[10]
Aylin Caliskan, Joanna J Bryson, and Arvind Narayanan. 2017. Semantics derived automatically from language corpora contain human-like biases. Science, 356(6334):183--186
2017
-
[11]
Alexandra Chouldechova. 2017. Fair prediction with disparate impact: A study of bias in recidivism prediction instruments. Big data, 5(2):153--163
2017
-
[12]
Cleo Condoravdi, Dick Crouch, Valeria De Paiva, Reinhard Stolle, and Daniel Bobrow. 2003. Entailment, intensionality and text understanding. In Proceedings of the HLT-NAACL 2003 workshop on Text meaning, pages 38--45
2003
-
[13]
Sunhao Dai, Chen Xu, Shicheng Xu, Liang Pang, Zhenhua Dong, and Jun Xu. 2024. Bias and unfairness in information retrieval systems: New challenges in the llm era. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, pages 6437--6447
2024
-
[14]
Emily Dinan, Angela Fan, Adina Williams, Jack Urbanek, Douwe Kiela, and Jason Weston. 2020. Queens are powerful too: Mitigating gender bias in dialogue generation. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), pages 8173--8188
2020
-
[15]
David Esiobu, Xiaoqing Tan, Saghar Hosseini, Megan Ung, Yuchen Zhang, Jude Fernandes, Jane Dwivedi-Yu, Eleonora Presani, Adina Williams, and Eric Smith. 2023. Robbie: Robust bias evaluation of large generative language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 3764--3814
2023
-
[16]
Xiao Fang, Shangkun Che, Minjia Mao, Hongzhe Zhang, Ming Zhao, and Xiaohang Zhao. 2024. Bias of ai-generated content: an examination of news produced by large language models. Scientific Reports, 14(1):5224
2024
-
[17]
Yaroslav Fyodorov, Yoad Winter, and Nissim Francez. 2000. A natural logic inference system. In Proceedings of the 2nd workshop on inference in computational semantics (ICoS-2)
2000
-
[18]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3
2022
-
[19]
Tunazzina Islam. 2026. Who gets which message? auditing demographic bias in llm-generated targeted text. arXiv preprint arXiv:2601.17172
Pith/arXiv arXiv 2026
-
[20]
Tunazzina Islam and Dan Goldwasser. 2025. https://doi.org/10.18653/v1/2025.findings-emnlp.857 Post-hoc study of climate microtargeting on social media ads with LLM s: Thematic insights and fairness evaluation . In Findings of the Association for Computational Linguistics: EMNLP 2025, pages 15838--15859, Suzhou, China. Association for Computational Linguistics
-
[21]
Xisen Jin, Francesco Barbieri, Brendan Kennedy, Aida Mostafazadeh Davani, Leonardo Neves, and Xiang Ren. 2021. On transferability of bias mitigation effects in language model fine-tuning. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 3770--3783
2021
-
[22]
Elise Karinshak, Sunny Xun Liu, Joon Sung Park, and Jeffrey T Hancock. 2023. Working with ai to persuade: Examining a large language model's ability to generate pro-vaccination messages. Proceedings of the ACM on Human-Computer Interaction, 7(CSCW1):1--29
2023
-
[23]
Jon Kleinberg, Sendhil Mullainathan, and Manish Raghavan. 2016. Inherent trade-offs in the fair determination of risk scores. arXiv preprint arXiv:1609.05807
Pith/arXiv arXiv 2016
-
[24]
Hadas Kotek, Rikker Dockum, and David Sun. 2023. Gender bias and stereotypes in large language models. In Proceedings of the ACM collective intelligence conference, pages 12--24
2023
-
[25]
Ben Krause, Akhilesh Deepak Gotmare, Bryan McCann, Nitish Shirish Keskar, Shafiq Joty, Richard Socher, and Nazneen Fatema Rajani. 2021. Gedi: Generative discriminator guided sequence generation. In Findings of the Association for Computational Linguistics: EMNLP 2021, pages 4929--4952
2021
-
[26]
Sachin Kumar, Vidhisha Balachandran, Lucille Njoo, Antonios Anastasopoulos, and Yulia Tsvetkov. 2023. Language generation models can cause harm: So what can we do about it? an actionable survey. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, pages 3299--3321
2023
-
[27]
Matt J Kusner, Joshua Loftus, Chris Russell, and Ricardo Silva. 2017. Counterfactual fairness. Advances in neural information processing systems, 30
2017
-
[28]
Moritz Laurer, Wouter van Atteveldt, Andreu Casas, and Kasper Welbers. 2023. https://doi.org/10.48550/arXiv.2312.17543 Building Efficient Universal Classifiers with Natural Language Inference . arXiv preprint. ArXiv:2312.17543 [cs]
-
[29]
Yingji Li, Mengnan Du, Rui Song, Xin Wang, and Ying Wang. 2023 a . A survey on fairness in large language models. arXiv preprint arXiv:2308.10149
arXiv 2023
-
[30]
Yunqi Li, Lanjing Zhang, and Yongfeng Zhang. 2023 b . Fairness of chatgpt. arXiv preprint arXiv:2305.18569
arXiv 2023
-
[31]
Minqian Liu, Zhiyang Xu, Xinyi Zhang, Heajun An, Sarvech Qadir, Qi Zhang, Pamela J Wisniewski, Jin-Hee Cho, Sang Won Lee, Ruoxi Jia, and 1 others. 2025. Llm can be a dangerous persuader: Empirical study of persuasion safety in large language models. arXiv preprint arXiv:2504.10430
arXiv 2025
-
[32]
Bill MacCartney and Christopher D Manning. 2009. An extended model of natural logic. In Proceedings of the eight international conference on computational semantics, pages 140--156
2009
-
[33]
Shahed Masoudian, Cornelia Volaucnik, Markus Schedl, and Navid Rekabsaz. 2024. https://doi.org/10.18653/v1/2024.eacl-long.150 Effective controllable bias mitigation for classification and retrieval using gate adapters . In Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), p...
-
[34]
Amalie Brogaard Pauli, Isabelle Augenstein, and Ira Assent. 2025. Measuring and benchmarking large language models’ capabilities to generate persuasive language. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 10056--10075
2025
-
[35]
Amalie Brogaard Pauli, Maria Barrett, Max M \"u ller-Eberstein, Isabelle Augenstein, and Ira Assent. 2026. Analysing differences in persuasive language in llm-generated text: Uncovering stereotypical gender patterns. arXiv preprint arXiv:2601.05751
Pith/arXiv arXiv 2026
-
[36]
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. 2023. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728--53741
2023
-
[37]
Lucas Rosenblatt and R Teal Witter. 2023. Counterfactual fairness is basically demographic parity. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 37, pages 14461--14469
2023
-
[38]
Matthew Sag. 2023. Fairness and fair use in generative ai. Fordham Law Review, Forthcoming
2023
-
[39]
Maarten Sap, Marcella Cindy Prasettio, Ariel Holtzman, Hannah Rashkin, and Yejin Choi. 2017. Connotation frames of agency and power in modern films. In Conference on Empirical Methods in Natural Language Processing
2017
-
[40]
Timo Schick, Sahana Udupa, and Hinrich Sch \"u tze. 2021. Self-diagnosis and self-debiasing: A proposal for reducing corpus-based bias in nlp. Transactions of the Association for Computational Linguistics, 9:1408--1424
2021
-
[41]
when ai writes personas
Sankalp Sethi, Joni Salminen, Danial Amin, and Bernard J Jansen. 2025. " when ai writes personas": Analyzing lexical diversity in llm-generated persona descriptions. In Proceedings of the Extended Abstracts of the CHI Conference on Human Factors in Computing Systems, pages 1--8
2025
-
[42]
Maja Stahl, Maximilian Splieth \"o ver, and Henning Wachsmuth. 2022. To prefer or to choose? generating agency and power counterfactuals jointly for gender bias mitigation. In Proceedings of the Fifth Workshop on Natural Language Processing and Computational Social Science (NLP+ CSS), pages 39--51
2022
-
[43]
Joseph E Stiglitz. 1981. Pareto optimality and competition. The Journal of Finance, 36(2):235--251
1981
-
[44]
Magdalena Szumilas. 2010. Explaining odds ratios. Journal of the Canadian academy of child and adolescent psychiatry, 19(3):227
2010
-
[45]
Bryan Chen Zhengyu Tan and Roy Ka-Wei Lee. 2025. Unmasking implicit bias: Evaluating persona-prompted llm responses in power-disparate social scenarios. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 1075--1108
2025
-
[46]
Aleksandra Urman and Mykola Makhortykh. 2023. The silence of the llms: Cross-lingual analysis of political bias and false information prevalence in chatgpt, google bard, and bing chat
2023
-
[47]
Yixin Wan and Kai-Wei Chang. 2025. White men lead, black women help? benchmarking and mitigating language agency social biases in llms. In Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9082--9108
2025
-
[48]
kelly is a warm person, joseph is a role model
Yixin Wan, George Pu, Jiao Sun, Aparna Garimella, Kai-Wei Chang, and Nanyun Peng. 2023. “kelly is a warm person, joseph is a role model”: Gender biases in llm-generated reference letters. In Findings of the Association for Computational Linguistics: EMNLP 2023, pages 3730--3748
2023
-
[49]
Xuewei Wang, Weiyan Shi, Richard Kim, Yoojung Oh, Sijia Yang, Jingwen Zhang, and Zhou Yu. 2019. Persuasion for good: Towards a personalized persuasive dialogue system for social good. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, pages 5635--5649
2019
-
[50]
Ye Wang and Kexin Gu. 2026. Who invests, who gets funded: Gender and racial bias in llm-generated investment advice: Y. wang and k. gu. Journal of Business Ethics, pages 1--37
2026
-
[51]
Zeyu Zhou, Tianci Liu, Ruqi Bai, Jing Gao, Murat Kocaoglu, and David I Inouye. 2024. Counterfactual fairness by combining factual and counterfactual predictions. Advances in Neural Information Processing Systems, 37:47876--47907
2024
-
[52]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
Analysis of Twitter Users' Lifestyle Choices using Joint Embedding Model , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[53]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
Twitter user representation using weakly supervised graph embedding , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[54]
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
A Holistic Framework for Analyzing the COVID-19 Vaccine Debate , author=. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies , pages=
2022
-
[55]
Proceedings of the Fourth Workshop on Data Science with Human-in-the-Loop (Language Advances) , pages=
Interactively uncovering latent arguments in social media platforms: A case study on the covid-19 vaccine debate , author=. Proceedings of the Fourth Workshop on Data Science with Human-in-the-Loop (Language Advances) , pages=
-
[56]
Interactive Concept Learning for Uncovering Latent Themes in Large Text Collections
Pacheco, Maria Leonor and Islam, Tunazzina and Ungar, Lyle and Yin, Ming and Goldwasser, Dan. Interactive Concept Learning for Uncovering Latent Themes in Large Text Collections. Findings of the Association for Computational Linguistics: ACL 2023. 2023. doi:10.18653/v1/2023.findings-acl.313
-
[57]
2022 IEEE International Conference on Big Data (Big Data) , pages=
Understanding COVID-19 Vaccine Campaign on Facebook using Minimal Supervision , author=. 2022 IEEE International Conference on Big Data (Big Data) , pages=. 2022 , organization=
2022
-
[58]
Proceedings of the International AAAI Conference on Web and Social Media , volume=
Weakly Supervised Learning for Analyzing Political Campaigns on Facebook , author=. Proceedings of the International AAAI Conference on Web and Social Media , volume=
-
[59]
Evaluating Biased Attitude Associations of Language Models in an Intersectional Context , url=
Islam, Tunazzina and Zhang, Ruqi and Goldwasser, Dan , title =. 2023 , isbn =. doi:10.1145/3600211.3604665 , booktitle =
-
[60]
Publications Manual , year = "1983", publisher =
1983
-
[61]
Aho and Jeffrey D
Alfred V. Aho and Jeffrey D. Ullman , title =. 1972
1972
-
[62]
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year = "1981", title =. doi:10.1145/322234.322243
-
[63]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of
-
[64]
Dan Gusfield , title =. 1997
1997
-
[65]
Tetreault , title =
Mohammad Sadegh Rasooli and Joel R. Tetreault , title =. Computing Research Repository , volume =. 2015 , url =
2015
-
[66]
A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =
Ando, Rie Kubota and Zhang, Tong , Issn =. A Framework for Learning Predictive Structures from Multiple Tasks and Unlabeled Data , Volume =. Journal of Machine Learning Research , Month = dec, Numpages =
-
[67]
Scientific reports , volume=
Forecasting the onset and course of mental illness with Twitter data , author=. Scientific reports , volume=. 2017 , publisher=
2017
-
[68]
PloS one , volume=
Twitter: a good place to detect health conditions , author=. PloS one , volume=. 2014 , publisher=
2014
-
[69]
International conference on social computing, behavioral-cultural modeling, and prediction , pages=
Identifying health-related topics on twitter , author=. International conference on social computing, behavioral-cultural modeling, and prediction , pages=. 2011 , organization=
2011
-
[70]
arXiv preprint arXiv:1906.07668 , year=
Yoga-Veganism: Correlation Mining of Twitter Health Data , author=. arXiv preprint arXiv:1906.07668 , year=
arXiv 1906
-
[71]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Recognizing counterfactual thinking in social media texts , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[72]
Proceedings of the National Academy of Sciences , volume=
Facebook language predicts depression in medical records , author=. Proceedings of the National Academy of Sciences , volume=. 2018 , publisher=
2018
-
[73]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Leveraging behavioral and social information for weakly supervised collective classification of political discourse on Twitter , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[74]
Seventh international AAAI conference on weblogs and social media , year=
Predicting depression via social media , author=. Seventh international AAAI conference on weblogs and social media , year=
-
[75]
Fifth international AAAI conference on weblogs and social media , year=
A machine learning approach to twitter user classification , author=. Fifth international AAAI conference on weblogs and social media , year=
-
[76]
An analysis of the user occupational class through Twitter content , author=. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (Volume 1: Long Papers) , pages=
-
[77]
Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
Learning multiview embeddings of twitter users , author=. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) , pages=
-
[78]
Proceedings of the national academy of sciences , volume=
Private traits and attributes are predictable from digital records of human behavior , author=. Proceedings of the national academy of sciences , volume=. 2013 , publisher=
2013
-
[79]
PloS one , volume=
Personality, gender, and age in the language of social media: The open-vocabulary approach , author=. PloS one , volume=. 2013 , publisher=
2013
-
[80]
Twenty-fourth international joint conference on artificial intelligence , year=
Detecting emotions in social media: A constrained optimization approach , author=. Twenty-fourth international joint conference on artificial intelligence , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.