Look Before You Leap: Autonomous Exploration for LLM Agents
Pith reviewed 2026-05-20 17:35 UTC · model grok-4.3
The pith
LLM agents that first spend time systematically exploring new environments before acting on tasks achieve broader knowledge and stronger performance than those trained only on task rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
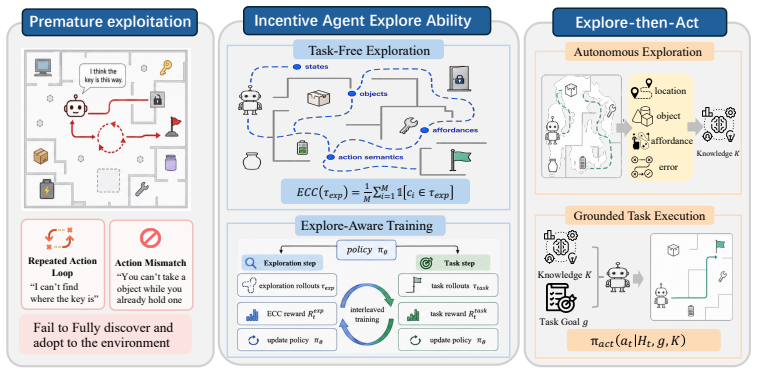
By training agents with interleaved exploration and task rollouts, each driven by its own verifiable reward, and by decoupling information gathering from task execution via the Explore-then-Act paradigm, agents acquire sufficient environmental knowledge to avoid premature exploitation and improve downstream performance in novel settings.
What carries the argument
The Explore-then-Act paradigm, which separates an initial information-gathering phase from later task execution so that agents first build grounded knowledge about states, objects, and affordances.
If this is right
- Agents will cover more key states and affordances during training.
- Downstream task performance will rise once the gathered knowledge is applied.
- Agents will exhibit fewer repetitive or narrow behaviors in new environments.
- The same interleaving method can be used to train agents across different task families without changing the core reward structure.
Where Pith is reading between the lines
- The same separation of exploration and execution phases could be tested in embodied robotic agents operating in physical spaces.
- Exploration budgets might be adjusted dynamically based on how novel the current environment appears to the agent.
- The approach may reduce reliance on hand-crafted environment-specific instructions by letting the agent discover affordances on its own.
Load-bearing premise
That running exploration rollouts with their own reward will reliably produce useful environmental knowledge that transfers to task solving without introducing new inefficiencies or biases that hurt final performance.
What would settle it
A direct comparison in which agents trained with the interleaved exploration strategy show no gain, or a loss, in task success rate or checkpoint coverage compared with standard task-only reinforcement learning on the same set of unfamiliar environments.
Figures


read the original abstract
Large language model based agents often fail in unfamiliar environments due to premature exploitation: a tendency to act on prior knowledge before acquiring sufficient environment-specific information. We identify autonomous exploration as a critical yet underexplored capability for building adaptive agents. To formalize and quantify this capability, we introduce Exploration Checkpoint Coverage, a verifiable metric that measures how broadly an agent discovers key states, objects, and affordances. Our systematic evaluation reveals that agents trained with standard task-oriented reinforcement learning consistently exhibit narrow and repetitive behaviors that impede downstream performance. To address this limitation, we develop a training strategy that interleaves task-execution rollouts and exploration rollouts, with each type of rollout optimized by its corresponding verifiable reward. Building on this training strategy, we propose the Explore-then-Act paradigm, which decouples information-gathering from task execution: agents first utilize an interaction budget to acquire grounded environmental knowledge, then leverage it for task resolution. Our results demonstrate that learning to systematically explore is imperative for building generalizable and real-world-ready agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM-based agents fail in unfamiliar environments due to premature exploitation and identifies autonomous exploration as a critical capability. It introduces Exploration Checkpoint Coverage as a verifiable metric for measuring discovery of key states, objects, and affordances. Standard task-oriented RL is shown to produce narrow, repetitive behaviors. The authors propose a training strategy that interleaves task-execution rollouts and exploration rollouts, each optimized by its own verifiable reward, and introduce the Explore-then-Act paradigm that decouples information gathering from task execution. The central result is that learning systematic exploration is imperative for generalizable, real-world-ready agents.
Significance. If the empirical results hold and the interleaving strategy demonstrably improves downstream generalization without net-negative effects on task performance, this would be a meaningful contribution to LLM agent research by explicitly addressing the exploration-exploitation tradeoff with verifiable rewards and a decoupled paradigm. The verifiable metric and reproducible training recipe would be strengths if supported by detailed ablations.
major comments (2)
- [§4] §4 (Training Strategy) and the Explore-then-Act description: The central claim requires that interleaving task-execution and exploration rollouts with separate verifiable rewards produces agents whose acquired knowledge improves generalization without the exploration phase introducing inefficiencies or conflicting gradients that degrade the task policy. The manuscript does not appear to include ablations that isolate the net effect on task success rates when exploration rollouts are added, nor does it quantify whether the shared policy parameters cause the two reward signals to pull in opposing directions.
- [§3] §3 (Exploration Checkpoint Coverage): The metric is central to both the evaluation and the exploration reward. It is unclear from the provided description how checkpoints are selected or verified to be causally relevant to downstream task success rather than simply increasing state coverage; without this link, the claim that higher coverage directly supports real-world readiness remains under-supported.
minor comments (2)
- [Abstract] Abstract: The abstract states that standard RL agents exhibit narrow behaviors but does not specify the environments, number of trials, or statistical significance of the observed performance gap.
- Notation: The distinction between the task reward and the exploration reward should be made explicit with symbols or equations to avoid ambiguity when describing the interleaved optimization.
Simulated Author's Rebuttal
We thank the referee for the insightful comments, which help clarify key aspects of our work. We respond to each major comment below and specify the revisions we will implement.
read point-by-point responses
-
Referee: [§4] §4 (Training Strategy) and the Explore-then-Act description: The central claim requires that interleaving task-execution and exploration rollouts with separate verifiable rewards produces agents whose acquired knowledge improves generalization without the exploration phase introducing inefficiencies or conflicting gradients that degrade the task policy. The manuscript does not appear to include ablations that isolate the net effect on task success rates when exploration rollouts are added, nor does it quantify whether the shared policy parameters cause the two reward signals to pull in opposing directions.
Authors: We agree that explicit ablations are needed to isolate the net contribution of exploration rollouts and to check for gradient conflicts. In the revised manuscript we will add results comparing task success rates and generalization performance for agents trained with task-only rollouts versus the full interleaved schedule. We will also report reward curves and gradient norm statistics during joint optimization to demonstrate that the two signals do not produce opposing updates that degrade the task policy. revision: yes
-
Referee: [§3] §3 (Exploration Checkpoint Coverage): The metric is central to both the evaluation and the exploration reward. It is unclear from the provided description how checkpoints are selected or verified to be causally relevant to downstream task success rather than simply increasing state coverage; without this link, the claim that higher coverage directly supports real-world readiness remains under-supported.
Authors: Checkpoints are chosen as states, objects and affordances that are prerequisites for completing the suite of downstream tasks, identified through environment analysis. In the revision we will expand the description in §3 with the precise selection criteria and add empirical correlations between checkpoint coverage and task success on held-out tasks, thereby strengthening the causal link to generalization and real-world readiness. revision: yes
Circularity Check
No significant circularity; derivation relies on independently defined metric and verifiable rewards
full rationale
The paper introduces Exploration Checkpoint Coverage as a new verifiable metric for measuring state/object/affordance discovery and proposes an interleaving training strategy where task-execution and exploration rollouts each use their own reward signals. Neither the metric nor the interleaving procedure is defined in terms of the final generalization performance or the Explore-then-Act paradigm; the central claim that systematic exploration improves downstream readiness is presented as an empirical outcome rather than a definitional identity. No self-citation chain, fitted-input renaming, or ansatz smuggling is evident in the provided derivation steps. The approach remains falsifiable against external benchmarks of agent generalization.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agents can acquire sufficient environmental knowledge through a fixed interaction budget during exploration rollouts
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Exploration Checkpoint Coverage (ECC) ... interleaved GRPO training strategy that interleaves task-execution rollouts and exploration rollouts, with each type of rollout optimized by its corresponding verifiable reward.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning R...
work page 2024
-
[2]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents.ArXiv, abs/2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments.Advances in Neural Information Proc...
work page 2024
-
[4]
τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan. τ 2-bench: Evaluating conversational agents in a dual-control environment, 2025
work page 2025
-
[5]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[6]
RAGEN: Understanding Self-Evolution in LLM Agents via Multi-Turn Reinforcement Learning
Zihan Wang, Kangrui Wang, Qineng Wang, Pingyue Zhang, Linjie Li, Zhengyuan Yang, Xing Jin, Kefan Yu, Minh Nhat Nguyen, Licheng Liu, Eli Gottlieb, Yiping Lu, Kyunghyun Cho, Jiajun Wu, Li Fei-Fei, Lijuan Wang, Yejin Choi, and Manling Li. RAGEN: understanding self-evolution in LLM agents via multi-turn reinforcement learning.CoRR, abs/2504.20073, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
Zhiheng Xi, Jixuan Huang, Chenyang Liao, Baodai Huang, Honglin Guo, Jiaqi Liu, Rui Zheng, Junjie Ye, Jiazheng Zhang, Wenxiang Chen, Wei He, Yiwen Ding, Guanyu Li, Zehui Chen, Zhengyin Du, Xuesong Yao, Yufei Xu, Jiecao Chen, Tao Gui, Zuxuan Wu, Qi Zhang, Xuanjing Huang, and Yu-Gang Jiang. Agentgym-rl: Training llm agents for long-horizon decision making th...
work page 2025
-
[8]
Group-in-Group Policy Optimization for LLM Agent Training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for llm agent training.arXiv preprint arXiv:2505.10978, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
WALL-e: World alignment by neurosymbolic learning improves world model-based LLM agents
Siyu Zhou, Tianyi Zhou, Yijun Yang, Guodong Long, Deheng Ye, Jing Jiang, and Chengqi Zhang. WALL-e: World alignment by neurosymbolic learning improves world model-based LLM agents. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[10]
Test-time adaptation for llm agents via environment interaction, 2026
Arthur Chen, Zuxin Liu, Jianguo Zhang, Akshara Prabhakar, Zhiwei Liu, Shelby Heinecke, Silvio Savarese, Victor Zhong, and Caiming Xiong. Test-time adaptation for llm agents via environment interaction, 2026
work page 2026
-
[11]
Fundamen- tals of building autonomous llm agents, 2025
Victor de Lamo Castrillo, Habtom Kahsay Gidey, Alexander Lenz, and Alois Knoll. Fundamen- tals of building autonomous llm agents, 2025
work page 2025
-
[12]
Agent-r: Training language model agents to reflect via iterative self-training, 2025
Siyu Yuan, Zehui Chen, Zhiheng Xi, Junjie Ye, Zhengyin Du, and Jiecao Chen. Agent-r: Training language model agents to reflect via iterative self-training, 2025
work page 2025
-
[13]
Dongfu Jiang, Yi Lu, Zhuofeng Li, Zhiheng Lyu, Ping Nie, Haozhe Wang, Alex Su, Hui Chen, Kai Zou, Chao Du, et al. Verltool: Towards holistic agentic reinforcement learning with tool use.arXiv preprint arXiv:2509.01055, 2025
-
[14]
Mcp-atlas: A large-scale benchmark for tool-use competency with real mcp servers, 2026
Chaithanya Bandi, Ben Hertzberg, Geobio Boo, Tejas Polakam, Jeff Da, Sami Hassaan, Manasi Sharma, Andrew Park, Ernesto Hernandez, Dan Rambado, Ivan Salazar, Rafael Cruz, Chetan Rane, Ben Levin, Brad Kenstler, and Bing Liu. Mcp-atlas: A large-scale benchmark for tool-use competency with real mcp servers, 2026. 10
work page 2026
-
[15]
Cues: A curiosity-driven and environment-grounded synthesis framework for agentic rl, December 2025
Shinji Mai, Yunpeng Zhai, Ziqian Chen, Cheng Chen, Anni Zou, Shuchang Tao, Zhaoyang Liu, and Bolin Ding. Cues: A curiosity-driven and environment-grounded synthesis framework for agentic rl, December 2025
work page 2025
-
[16]
Learn-by- interact: A data-centric framework for self-adaptive agents in realistic environments
Hongjin SU, Ruoxi Sun, Jinsung Yoon, Pengcheng Yin, Tao Yu, and Sercan O Arik. Learn-by- interact: A data-centric framework for self-adaptive agents in realistic environments. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[17]
Explorer: Scaling exploration-driven web trajectory synthesis for multimodal web agents
Vardaan Pahuja, Yadong Lu, Corby Rosset, Boyu Gou, Arindam Mitra, Spencer Whitehead, Yu Su, and Ahmed Hassan Awadallah. Explorer: Scaling exploration-driven web trajectory synthesis for multimodal web agents. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: A...
work page 2025
-
[18]
Wese: Weak exploration to strong exploitation for llm agents, 2024
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Wese: Weak exploration to strong exploitation for llm agents, 2024
work page 2024
-
[19]
Automanual: Generating instruction manuals by LLM agents via interactive environmental learning
Minghao Chen, Yihang Li, Yanting Yang, Shiyu Yu, Binbin Lin, and Xiaofei He. Automanual: Generating instruction manuals by LLM agents via interactive environmental learning. InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[20]
Vitabench: Benchmarking LLM agents with versatile interactive tasks in real-world applications
Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Qi GU, Hui Su, and Xunliang Cai. Vitabench: Benchmarking LLM agents with versatile interactive tasks in real-world applications. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[21]
Envscaler: Scaling tool-interactive environments for llm agent via programmatic synthesis, 2026
Xiaoshuai Song, Haofei Chang, Guanting Dong, Yutao Zhu, Ji-Rong Wen, and Zhicheng Dou. Envscaler: Scaling tool-interactive environments for llm agent via programmatic synthesis, 2026
work page 2026
-
[22]
Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
Jason Wei, Zhiqing Sun, Spencer Papay, Scott McKinney, Jeffrey Han, Isa Fulford, Hyung Won Chung, Alex Tachard Passos, William Fedus, and Amelia Glaese. Browsecomp: A simple yet challenging benchmark for browsing agents, 2025
work page 2025
-
[23]
{ALFW}orld: Aligning text and embodied environments for interactive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Cote, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. {ALFW}orld: Aligning text and embodied environments for interactive learning. InInternational Conference on Learning Representations, 2021
work page 2021
-
[24]
Ruoyao Wang, Peter Jansen, Marc-Alexandre Côté, and Prithviraj Ammanabrolu. Science- World: Is your agent smarter than a 5th grader? In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 11279–11298, Abu Dhabi, United Arab Emirates, December 2022. Associati...
work page 2022
-
[25]
Agentgym: Evolving large language model-based agents across diverse environments, 2024
Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Dingwen Yang, Chenyang Liao, Xin Guo, Wei He, Songyang Gao, Lu Chen, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, and Yu-Gang Jiang. Agentgym: Evolving large language model-based agents across diverse environments, 2024
work page 2024
-
[26]
V oyager: An open-ended embodied agent with large language models
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. V oyager: An open-ended embodied agent with large language models. Transactions on Machine Learning Research, 2024
work page 2024
-
[27]
A real-world webagent with planning, long context understanding, and program synthesis
Izzeddin Gur, Hiroki Furuta, Austin V Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust. A real-world webagent with planning, long context understanding, and program synthesis. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[28]
Os-atlas: A foundation action model for generalist gui agents, 2024
Zhiyong Wu, Zhenyu Wu, Fangzhi Xu, Yian Wang, Qiushi Sun, Chengyou Jia, Kanzhi Cheng, Zichen Ding, Liheng Chen, Paul Pu Liang, and Yu Qiao. Os-atlas: A foundation action model for generalist gui agents, 2024
work page 2024
-
[29]
Kechi Zhang, Jia Li, Ge Li, Xianjie Shi, and Zhi Jin. Codeagent: Enhancing code generation with tool-integrated agent systems for real-world repo-level coding challenges, 2024. 11
work page 2024
-
[30]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R. Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5,
work page 2023
-
[31]
OpenReview.net, 2023
work page 2023
-
[32]
Reflex- ion: language agents with verbal reinforcement learning
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflex- ion: language agents with verbal reinforcement learning. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine, editors,Advances in Neural Information Processing Systems, volume 36, pages 8634–8652. Curran Associates, Inc., 2023
work page 2023
-
[33]
Agenttuning: Enabling generalized agent abilities for llms, 2023
Aohan Zeng, Mingdao Liu, Rui Lu, Bowen Wang, Xiao Liu, Yuxiao Dong, and Jie Tang. Agenttuning: Enabling generalized agent abilities for llms, 2023
work page 2023
-
[34]
ToolLLM: Facilitating large language models to master 16000+ real-world APIs
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, Sihan Zhao, Lauren Hong, Runchu Tian, Ruobing Xie, Jie Zhou, Mark Gerstein, dahai li, Zhiyuan Liu, and Maosong Sun. ToolLLM: Facilitating large language models to master 16000+ real-world APIs. InThe Twelfth International Conference on Learning...
work page 2024
- [35]
-
[36]
Yun Luo, Zhen Yang, Fandong Meng, Yafu Li, Jie Zhou, and Yue Zhang. An empirical study of catastrophic forgetting in large language models during continual fine-tuning, 2025
work page 2025
-
[37]
Agentrl: Scaling agentic reinforcement learning with a multi-turn, multi-task framework, 2025
Hanchen Zhang, Xiao Liu, Bowen Lv, Xueqiao Sun, Bohao Jing, Iat Long Iong, Zhenyu Hou, Zehan Qi, Hanyu Lai, Yifan Xu, Rui Lu, Hongning Wang, Jie Tang, and Yuxiao Dong. Agentrl: Scaling agentic reinforcement learning with a multi-turn, multi-task framework, 2025
work page 2025
-
[38]
Hierarchy-of-groups policy optimization for long-horizon agentic tasks
Shuo He, Lang Feng, Qi Wei, Xin Cheng, Lei Feng, and Bo An. Hierarchy-of-groups policy optimization for long-horizon agentic tasks. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[39]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[40]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jian Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, Le Yu, Liangha...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, Aurélien Rodriguez, Armand Joulin, Edouard Grave, and Guillaume Lample. Llama: Open and efficient foundation language models.CoRR, abs/2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
OpenAI. GPT-4 technical report.CoRR, abs/2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Anthropic. Introducing claude opus 4.5. https://www.anthropic.com/news/ claude-opus-4-5, November 2025. Accessed: 2026-04-29. 12 A Limitations and Future work. Our work takes an initial step toward incentivizing autonomous exploration abilities in LLM-based agents. Looking ahead, we consider following potential limitations and future work. First, this wor...
work page 2025
-
[44]
Systematically explore all available actions and observe their effects
-
[45]
Map out the information structure of the environment
-
[46]
Identify reliable patterns and clues Exploration Strategy - Try different actions to understand state transitions - Note what information is available at each state - Track which actions are reversible vs irreversible - Identify key decision points - Explore different paths and branches IMPORTANT NOTE All findings must be grounded in direct interaction wi...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.