Framing, Judging, Steering: An Assessable Competency Model for Teach-ing Students to Reason With Generative AI
Pith reviewed 2026-06-28 01:20 UTC · model grok-4.3
The pith
Productive generative AI use requires three distinct skills—framing the task, judging the output, and steering refinements—that can be assessed separately.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
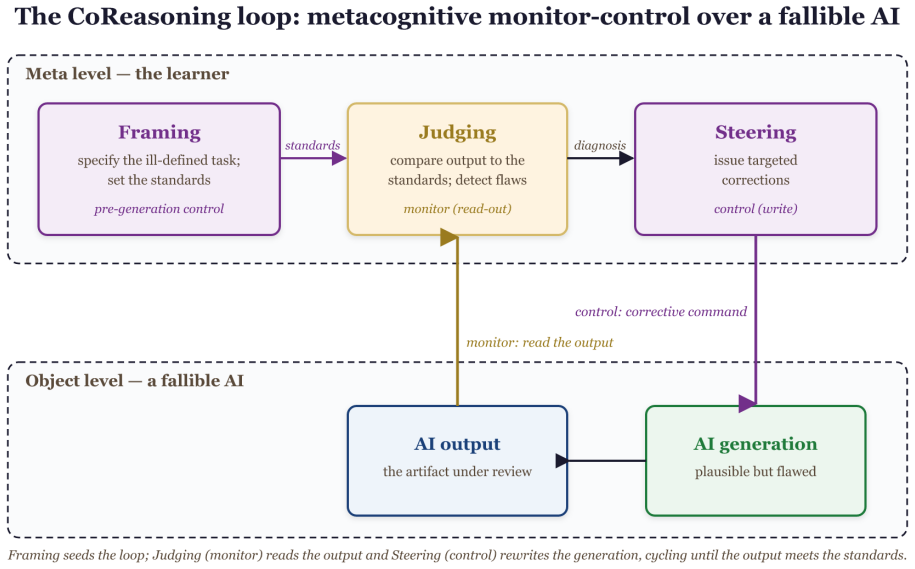
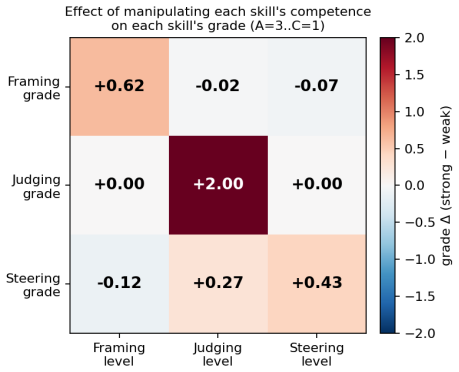
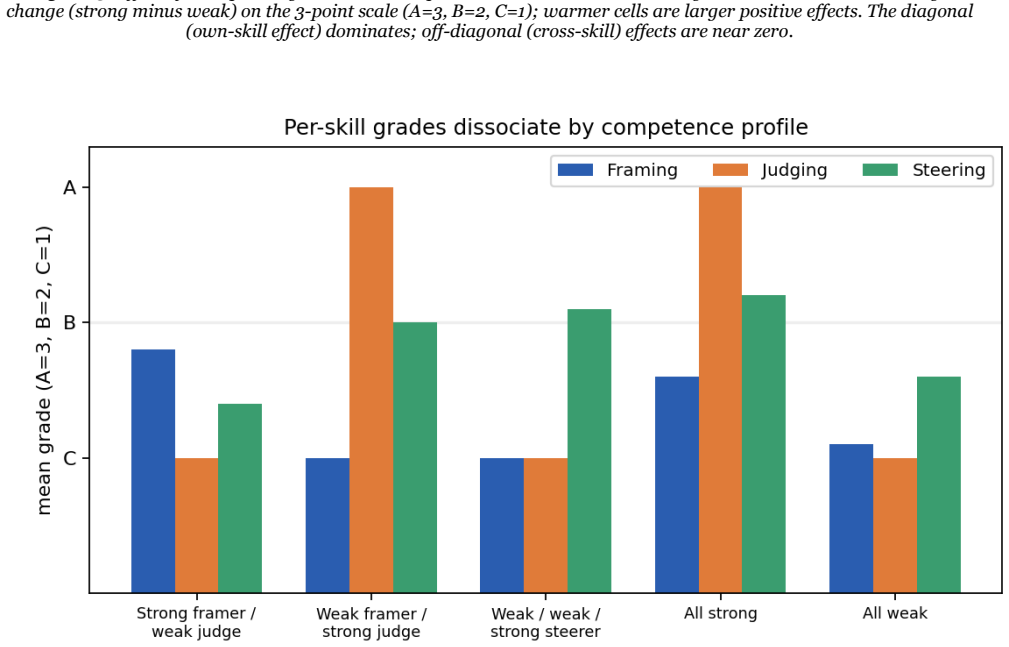
The CoRe-3 model claims that productive AI use consists of Framing an ill-defined task before invocation, Judging the output for errors and assumptions, and Steering the model through iterations, with Judging acting as the gate between pre- and post-generation phases. In tests using simulated learners, performance in each skill tracked only the manipulated competence in that skill and remained flat in the others, while shared competence across skills produced correlated grades, demonstrating discriminant and convergent validity across different model backends.
What carries the argument
The FJS competency model (Framing before generation, Judging as evaluation gate, Steering after generation), implemented in the CoReasoningLab platform that scores each skill independently on flawed AI outputs.
If this is right
- Varying competence in one skill affects only performance on tasks relying on that skill.
- When one skill is shared across phases, grades on those phases become correlated.
- The observed dissociation and validity hold across grader models from two different providers.
- The five testable propositions about the skills can be checked using the released platform and protocol.
Where Pith is reading between the lines
- If the pattern holds for humans, teaching could target specific skill gaps instead of treating AI use as one undifferentiated ability.
- Classroom assessments could move from unaided performance to measuring how effectively students frame, judge, and steer AI assistance.
- The pre/post-generation split with an evaluation gate might apply when assessing student use of other complex tools beyond AI.
Load-bearing premise
That the dissociation and validity patterns seen in AI-generated and AI-graded simulated learners will appear when real human students perform the same tasks.
What would settle it
An experiment with human students in which training only one skill improves scores solely on tasks that rely on that skill and leaves the other two skills unchanged.
Figures
read the original abstract
Generative AI makes answers easy and understanding hard, and uncritical use invites cognitive offloading. Schools still measure unaided performance, yet the real task is to produce good work with AI: framing an ill-defined task, judging the output, and steering the model toward a better result. This ability is rarely assessed in its own right; where measured, it collapses into one "prompting" score that cannot diagnose why AI use succeeds or fails. We propose CoRe-3 (Co-Reasoning), a competency model factoring productive AI use into three assessable skills we abbreviate FJS: Framing (specifying an ill-defined task before invoking AI), Judging (evaluating output for errors and unstated assumptions), and Steering (iteratively redirecting the model). Its distinguishing claim is the separation of pre-generation Framing from post-generation Steering, with Judging as the gate between. We ground the skills in theory, state five testable propositions, and instantiate them in CoReasoningLab, an open platform that presents flawed AI output and scores them independently. Over simulated learners (generated and graded by different models), the skills dissociate: each tracks its own manipulated competence while staying flat in the others, and grades become correlated when one competence is shared across all three (convergent and discriminant validity), across grader backends from two providers. Human-rater agreement and outcomes are next; we release the instrument, data, and protocol.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CoRe-3 (FJS), a competency model that factors productive generative-AI use into three separable skills—Framing (pre-generation task specification), Judging (post-generation evaluation), and Steering (iterative redirection)—distinct from a single undifferentiated “prompting” score. It grounds the model in theory, states five testable propositions, implements them in the open CoReasoningLab platform, and reports simulation results in which manipulated competence in one skill affects only its own score while the others remain flat, with convergent/discriminant validity observed when competence is shared across skills and across grader backends.
Significance. If the reported dissociation generalizes beyond the current simulations, the model supplies a diagnostically useful framework for assessing and teaching AI co-reasoning that could replace coarse prompting rubrics in educational settings. The open release of the instrument, data, and protocol is a concrete strength that enables direct replication and extension.
major comments (1)
- [Abstract and simulation-validation section] Abstract and simulation-validation section: the central claim that Framing, Judging, and Steering are separable, assessable competencies for human students rests entirely on LLM-generated and LLM-graded simulated learners. The manuscript explicitly defers human-rater agreement and classroom outcomes to future work, so the observed dissociation and convergent/discriminant validity have not yet been shown to reflect properties of human co-reasoning rather than model-specific encoding or detection artifacts.
Simulated Author's Rebuttal
We thank the referee for the detailed review and for highlighting the open release of the instrument, data, and protocol. Below we respond point-by-point to the major comment.
read point-by-point responses
-
Referee: [Abstract and simulation-validation section] Abstract and simulation-validation section: the central claim that Framing, Judging, and Steering are separable, assessable competencies for human students rests entirely on LLM-generated and LLM-graded simulated learners. The manuscript explicitly defers human-rater agreement and classroom outcomes to future work, so the observed dissociation and convergent/discriminant validity have not yet been shown to reflect properties of human co-reasoning rather than model-specific encoding or detection artifacts.
Authors: We agree that the reported dissociation, convergent validity, and discriminant validity are demonstrated only in LLM-simulated learners and have not been shown in human students. The manuscript already qualifies its claims accordingly, stating that the results come from 'simulated learners (generated and graded by different models)' and that 'Human-rater agreement and outcomes are next.' The simulations test the five propositions by showing that each skill tracks its own manipulated competence while remaining flat in the others, and that correlations appear when competence is shared, with patterns replicated across two grader backends. This establishes that the FJS separation is implementable and detectable in a controlled setting, providing a necessary proof-of-concept prior to human validation. The use of distinct models for generation and grading, plus cross-backend replication, reduces (though does not eliminate) the risk of single-model artifacts. Because the limitations are already stated explicitly and the claims are scoped to the simulation results, no revision to the text or claims is required. revision: no
Circularity Check
No significant circularity; claims rest on independent simulation tests and stated propositions.
full rationale
The paper grounds FJS skills in external theory, states five testable propositions, and demonstrates dissociation via cross-model simulations in CoReasoningLab (different models for generation vs. grading). No equations, fitted parameters, or self-citation chains reduce the validity claims to inputs by construction. The simulation results are presented as empirical support rather than definitional, with human validation explicitly deferred as future work. This satisfies self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The three competencies (Framing, Judging, Steering) are distinct and can be measured independently.
- domain assumption Simulated learners generated and graded by LLMs provide a valid test of the model's psychometric properties.
Reference graph
Works this paper leans on
-
[1]
Acar, O. A. (2023). AI Prompt Engineering Isn't the Future. Harvard Business Review, June 6
2023
-
[2]
W., & Krathwohl, D
Anderson, L. W., & Krathwohl, D. R. (2001). A Taxonomy for Learning, Teaching, and Assessing: A Revision of Bloom's Taxonomy of Educational Objectives. Longman
2001
-
[3]
Annapureddy, R., Fornaroli, A., & Gatica -Perez, D. (2024). Generative AI Literacy: Twelve Defining Competencies. Digital Government: Research and Practice
2024
-
[4]
T., & Weld, D
Bansal, G., Wu, T., Zhou, J., Fok, R., Nushi, B., Kamar, E., Ribeiro, M. T., & Weld, D. S. (2021). Does the Whole Ex- ceed Its Parts? The Effect of AI Explanations on Comple- mentary Team Performance. Proceedings of the 2021 14 CHI Conference on Human Factors in Computing Sys- tems
2021
-
[5]
Barzilai, S., & Chinn, C. A. (2018). On the Goals of Epistemic Education: Promoting Apt Epistemic Performance. Jour- nal of the Learning Sciences, 27(3), 353–389
2018
-
[6]
Bearman, M., Tai, J., Dawson, P., Boud, D., & Ajjawi, R. (2024). Developing Evaluative Judgement for a Time of Generative Artificial Intelligence. Assessment & Evalua- tion in Higher Education , 49(6), 893 –905. https://doi.org/10.1080/02602938.2024.2335321
-
[7]
L., & Bjork, R
Bjork, E. L., & Bjork, R. A. (2011). Making Things Hard on Yourself, but in a Good Way: Creating Desirable Difficul- ties to Enhance Learning. Psychology and the Real World, 56–64
2011
-
[8]
B., & Gajos, K
Buçinca, Z., Malaya, M. B., & Gajos, K. Z. (2021). To Trust or to Think: Cognitive Forcing Functions Can Reduce Overreliance on AI in AI-Assisted Decision-Making. Pro- ceedings of the ACM on Human -Computer Interaction, 5(CSCW1), 1–21
2021
-
[9]
T., & Fiske, D
Campbell, D. T., & Fiske, D. W. (1959). Convergent and Dis- criminant Validation by the Multitrait-Multimethod Ma- trix. Psychological Bulletin, 56(2), 81–105
1959
-
[10]
Chi, M. T. H., & Wylie, R. (2014). The ICAP Framework: Linking Cognitive Engagement to Active Learning Out- comes. Educational Psychologist, 49(4), 219–243
2014
-
[11]
Clerc, O., Abdelghani, R., Desvaux, C., Poisson, E., Oudeyer, P., & Sauzéon, H. (2026). Teaching Students to Question the Machine: An AI Literacy Intervention Im- proves Students' Regulation of LLM Use in a Science Task. arXiv preprint arXiv:2604.01955
Pith/arXiv arXiv 2026
-
[12]
S., & Newman, S
Collins, A., Brown, J. S., & Newman, S. E. (1989). Cognitive Apprenticeship: Teaching the Crafts of Reading, Writing, and Mathematics. Knowing, Learning, and Instruction: Essays in Honor of Robert Glaser, 453–494
1989
-
[13]
Dakan, R., & Feller, J. (2025). Framework for AI Fluency. Anthropic
2025
-
[14]
Dell'Acqua, F., McFowland III, E., Mollick, E., Lifshitz-As- saf, H., Kellogg, K., Rajendran, S., Krayer, L., Candelon, F., & Lakhani, K. R. (2023). Navigating the Jagged Tech- nological Frontier. Harvard Business School Working Paper 24-013
2023
-
[15]
A., & Reeves, B
Denny, P., Leinonen, J., Prather, J., Luxton -Reilly, A., Amarouche, T., Becker, B. A., & Reeves, B. N. (2024). Prompt Problems: A New Programming Exercise for the Generative AI Era. Proceedings of the 55th ACM Tech- nical Symposium on Computer Science Education (SIGCSE)
2024
-
[16]
Di Santi, E. (2026). Cognitive Amplification vs Cognitive Delegation in Human-AI Systems: A Metric Framework. arXiv preprint arXiv:2603.18677
Pith/arXiv arXiv 2026
-
[17]
Durkin, K., & Rittle-Johnson, B. (2012). The Effectiveness of Using Incorrect Examples to Support Learning about Decimal Magnitude. Learning and Instruction , 22(3), 206–214. https://doi.org/10.1016/j.learnin- struc.2011.11.001
-
[18]
Elshall, A. S., & Badir, A. (2025). Balancing AI -Assisted Learning and Traditional Assessment: The FACT Assess- ment in Environmental Data Science Education. Frontiers in Education , 10, 1596462. https://doi.org/10.3389/feduc.2025.1596462
-
[19]
Facione, P. A. (1990). Critical Thinking: A Statement of Ex- pert Consensus for Purposes of Educational Assessment and Instruction (The Delphi Report). American Philo- sophical Association
1990
-
[20]
Fan, Y., Tang, L., Le, H., Shen, K., Tan, S., Zhao, Y., Shen, Y., Li, X., & Gašević, D. (2025). Beware of Metacognitive Laziness: Effects of Generative Artificial Intelligence on Learning Motivation, Processes, and Performance. Brit- ish Journal of Educational Technology, 56(2), 489–530. https://doi.org/10.1111/bjet.13544
-
[21]
Feng, Y., Wang, S., Cheng, Z., Wan, Y., & Chen, D. (2025). Are We on the Right Way to Assessing LLM-as-a-Judge?. arXiv preprint arXiv:2512.16041
arXiv 2025
-
[22]
Fernandes, D., Villa, S., Nicholls, S., Haavisto, O., Buschek, D., Schmidt, A., Kosch, T., Shen, C., & Welsch, R. (2024). Performance and Metacognition Disconnect when Rea- soning in Human -AI Interaction. arXiv preprint arXiv:2409.16708
arXiv 2024
-
[23]
Flavell, J. H. (1979). Metacognition and Cognitive Moni- toring: A New Area of Cognitive-Developmental Inquiry. American Psychologist, 34(10), 906–911
1979
-
[24]
Ganuthula, V. R. R., & Balaraman, K. K. (2025). Artificial Intelligence Quotient Framework for Measuring Human Collaboration with Artificial Intelligence. Discover Arti- ficial Intelligence , 5, 268. https://doi.org/10.1007/s44163-025-00516-1
-
[25]
Gerlich, M. (2025). AI Tools in Society: Impacts on Cogni- tive Offloading and the Future of Critical Thinking. Soci- eties, 15(1), 6
2025
-
[26]
Gilson, L. L., & Goldberg, C. B. (2015). Editors' Comment: So, What Is a Conceptual Paper?. Group & Organization Management, 40(2), 127 –130. https://doi.org/10.1177/1059601115576425
-
[27]
Große, C. S., & Renkl, A. (2007). Finding and Fixing Errors in Worked Examples: Can This Foster Learning Out- comes?. Learning and Instruction , 17(6), 612 –634. https://doi.org/10.1016/j.learninstruc.2007.09.008
-
[28]
Gu, X., & Ericson, B. J. (2025). AI Literacy in K -12 and Higher Education in the Wake of Generative AI: An Inte- grative Review. Proceedings of the 2025 ACM Confer- ence on International Computing Education Research (ICER), 125 –140. https://doi.org/10.1145/3702652.3744217
-
[29]
Hattie, J., & Timperley, H. (2007). The Power of Feedback. Review of Educational Research, 77(1), 81–112
2007
-
[30]
Jaakkola, E. (2020). Designing Conceptual Articles: Four Approaches. AMS Review, 10, 18–26
2020
-
[31]
Jin, Y., Martinez -Maldonado, R., Gašević, D., & Yan, L. (2024). GLAT: The Generative AI Literacy Assessment Test. arXiv preprint arXiv:2411.00283
arXiv 2024
-
[32]
Kane, M. T. (2013). Validating the Interpretations and Uses of Test Scores. Journal of Educational Measure- ment, 50(1), 1–73. https://doi.org/10.1111/jedm.12000
-
[33]
Kapur, M. (2008). Productive Failure. Cognition and In- struction, 26(3), 379–424
2008
-
[34]
Kim, P., Wang, W., & Bonk, C. J. (2025). Generative AI as a Coach to Help Students Enhance Proficiency in 15 Question Formulation. Journal of Educational Compu- ting Research , 63(3), 565 –586. https://doi.org/10.1177/07356331251314222
-
[35]
T., Situ, J., Liao, X., Beresnitzky, A
Kosmyna, N., Hauptmann, E., Yuan, Y. T., Situ, J., Liao, X., Beresnitzky, A. V., Braunstein, I., & Maes, P. (2025). Your Brain on ChatGPT: Accumulation of Cognitive Debt when Using an AI Assistant for Essay Writing Task. arXiv pre- print arXiv:2506.08872
Pith/arXiv arXiv 2025
-
[36]
Lee, H., & Bosch, N. (2025). Calibration Discrepancy Pre- dicts Students' Subsequent Metacognitive Strategy Use in Computer-Based Learning Environments. International Journal of Artificial Intelligence in Education , 35(6), 3746–3779. https://doi.org/10.1007/s40593 -025- 00514-5
-
[37]
D., & See, K
Lee, J. D., & See, K. A. (2004). Trust in Automation: De- signing for Appropriate Reliance. Human Factors, 46(1), 50–80
2004
-
[38]
C., Baby, T., Vongvit, R., Lee, J., Kim, Y., Min, C., & Yoon, S
Lee, S. C., Baby, T., Vongvit, R., Lee, J., Kim, Y., Min, C., & Yoon, S. H. (2025). Development and Validation of a Generative AI Competence Scale. Technology in Society. https://doi.org/10.1016/j.techsoc.2025.103059
-
[39]
Li, C., Cui, H., & Hagedorn, L. S. (2026). The Cognitive Im- pact of ChatGPT in Higher Education: A Systematic Re- view of Critical and Creative Thinking Outcomes. Computers and Education: Artificial Intelligence , 10, 100571. https://doi.org/10.1016/j.caeai.2026.100571
-
[40]
Lo, L. S. (2023). The CLEAR Path: A Framework for En- hancing Information Literacy through Prompt Engineer- ing. The Journal of Academic Librarianship, 49(4)
2023
-
[41]
Long, D., & Magerko, B. (2020). What Is AI Literacy? Com- petencies and Design Considerations. Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, 1–16
2020
-
[42]
McNichols, H., Ikram, F., & Lan, A. (2025). The StudyChat Dataset: Student Dialogues With ChatGPT in an Artificial Intelligence Course. arXiv preprint arXiv:2503.07928 . https://doi.org/10.48550/arXiv.2503.07928
-
[43]
Messick, S. (1995). Validity of Psychological Assessment: Validation of Inferences from Persons' Responses and Performances as Scientific Inquiry into Score Meaning. American Psychologist , 50(9), 741 –749. https://doi.org/10.1037/0003-066X.50.9.741
-
[44]
Nazaretsky, T., Gabbay, H., & Käser, T. (2025). Can Stu- dents Judge Like Experts? A Large-Scale Study on AI and Human Personalized Formative Feedback. Computers and Education: Artificial Intelligence . https://doi.org/10.1016/j.caeai.2025.100533
-
[45]
O., & Narens, L
Nelson, T. O., & Narens, L. (1990). Metamemory: A Theo- retical Framework and New Findings. The Psychology of Learning and Motivation, 26, 125–173
1990
-
[46]
Parasuraman, R., & Manzey, D. H. (2010). Complacency and Bias in Human Use of Automation: An Attentional Integration. Human Factors, 52(3), 381–410
2010
-
[47]
Paul, R., & Elder, L. (2006). The Miniature Guide to Criti- cal Thinking: Concepts and Tools. Foundation for Criti- cal Thinking
2006
-
[48]
Randazzo, B., Lifshitz -Assaf, H., Kellogg, K., Dell'Acqua, F., Mollick, E., Candelon, F., & Lakhani, K. R. (2025). Cy- borgs, Centaurs and Self-Automators: Modes of Human- AI Collaboration in Knowledge Work. Harvard Business School Working Paper 26-036
2025
-
[49]
A., & Chand, I
Runco, M. A., & Chand, I. (1995). Cognition and Creativity. Educational Psychology Review, 7(3), 243–267
1995
-
[50]
Sadler, D. R. (1989). Formative Assessment and the Design of Instructional Systems. Instructional Science , 18(2), 119–144
1989
-
[51]
N., & Globerson, T
Salomon, G., Perkins, D. N., & Globerson, T. (1991). Part- ners in Cognition: Extending Human Intelligence with Intelligent Technologies. Educational Researcher, 20(3), 2–9
1991
-
[52]
Sidra, S., & Mason, C. (2025). Generative AI in Human-AI Collaboration: Validation of the Collaborative AI Literacy and Collaborative AI Metacognition Scales. Interna- tional Journal of Human -Computer Interaction . https://doi.org/10.1080/10447318.2025.2543997
-
[53]
Sperber, D., Clément, F., Heintz, C., Mascaro, O., Mercier, H., Origgi, G., & Wilson, D. (2010). Epistemic Vigilance. Mind & Language, 25(4), 359–393
2010
-
[54]
Srinath, S., Vadaparty, A., Smith IV, D. H., Porter, L., & Zingaro, D. (2025). Assessing Problem Decomposition in CS1 for the GenAI Era. arXiv preprint arXiv:2511.05764
arXiv 2025
-
[55]
E., Sarkar, A., Sellen, A., & Rintel, S
Tankelevitch, L., Kewenig, V., Simkute, A., Scott, A. E., Sarkar, A., Sellen, A., & Rintel, S. (2024). The Metacog- nitive Demands and Opportunities of Generative AI. Pro- ceedings of the 2024 CHI Conference on Human Factors in Computing Systems
2024
-
[56]
Tour, E., & Zadorozhnyy, A. (2025). Conceptualizing and Operationalizing Prompt Literacy for English Language Learners. Journal of Adolescent & Adult Literacy . https://doi.org/10.1002/jaal.70020
-
[57]
Vaccaro, M., Almaatouq, A., & Malone, T. (2024). When Combinations of Humans and AI Are Useful: A System- atic Review and Meta -Analysis. Nature Human Behav- iour, 8, 2293–2303
2024
-
[58]
Vygotsky, L. S. (1978). Mind in Society: The Development of Higher Psychological Processes. Harvard University Press
1978
-
[59]
Walton, J., Bearman, M., Crawford, N., Tai, J., & Boud, D. (2025). How University Students Work on Assessment Tasks with Generative Artificial Intelligence: Matters of Judgement. Assessment & Evaluation in Higher Educa- tion (advance online publication). https://doi.org/10.1080/02602938.2025.2570328
-
[60]
L., Straub, T., & Schweitzer, S
Wingerter, T. L., Straub, T., & Schweitzer, S. (2025). Miti- gating Automation Bias in Generative AI through Nudges: A Cognitive Reflection Test Study. Procedia Computer Science , 270, 2106 –2114. https://doi.org/10.1016/j.procs.2025.09.331
-
[61]
H., & Hadwin, A
Winne, P. H., & Hadwin, A. F. (1998). Studying as Self-Reg- ulated Learning. Metacognition in Educational Theory and Practice, 277–304
1998
-
[62]
Wirth, J., Weber-Reuter, X.-L., Schuster, C., Fleischer, J., Leutner, D., & Stebner, F. (2025). Far Transfer of Meta- cognitive Regulation: From Cognitive Learning Strategy Use to Mental Effort Regulation. Educational Psychol- ogy Review , 37(1), 7. https://doi.org/10.1007/s10648 - 024-09983-x 16
-
[63]
Yao, G., & Fan, L. (2025). Cognitive Load Scale for AI -As- sisted L2 Writing: Scale Development and Validation. Frontiers in Psychology , 16, 1666974. https://doi.org/10.3389/fpsyg.2025.1666974
-
[64]
Yavuz, F., Çelik, Ö., & Yavaş Çelik, G. (2025). Utilizing Large Language Models for EFL Essay Grading: An Ex- amination of Reliability and Validity in Rubric-Based As- sessments. British Journal of Educational Technology , 56(4), 1–17. https://doi.org/10.1111/bjet.13494
-
[65]
Zimmerman, B. J. (2000). Attaining Self-Regulation: A So- cial Cognitive Perspective. Handbook of Self-Regulation, 13–39
2000
-
[66]
As a member of the AI Ethics Committee at a technology company, you have been tasked with developing a set of ethical guidelines for the deployment of a new AI system
UNESCO (2024). AI Competency Framework for Students. UNESCO. Appendix A. System walkthrough Figure A1 shows a single challenge run in CoReason- ingLab, illustrating how the three skills appear as dis- tinct, separately -scored stages of one continuous task. In Phase 1 the learner refines an ill-defined problem and receives a Framing grade. The system then...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.