Multi-task learning on partially labeled datasets via invariant/equivariant semi-supervised learning
Pith reviewed 2026-05-20 13:52 UTC · model grok-4.3
The pith
Invariant and equivariant semi-supervised learning outperform supervised baselines for multi-task models on partially labeled datasets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
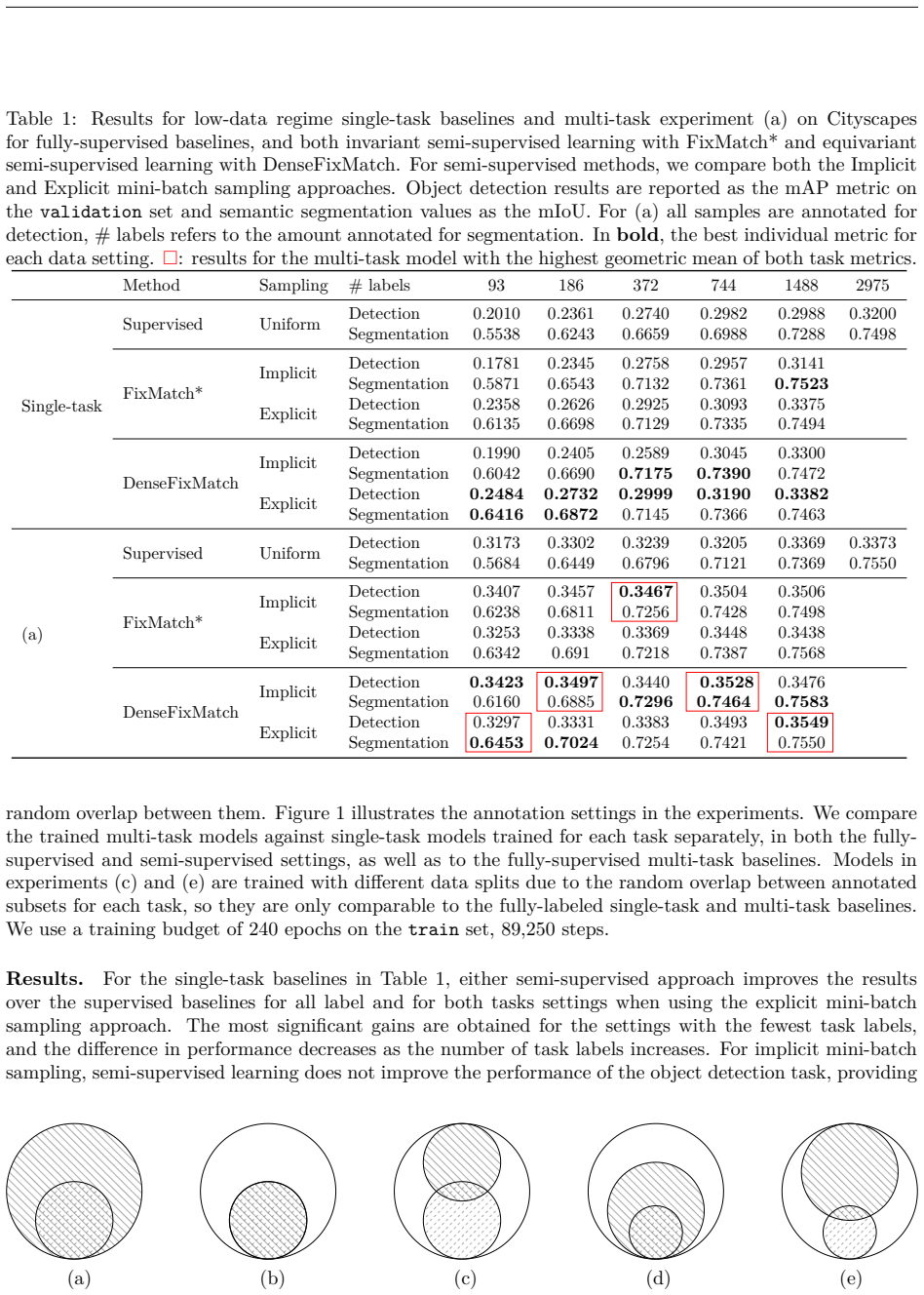
The paper claims that both invariant semi-supervised learning via FixMatch and equivariant via Dense FixMatch outperform supervised baselines in multi-task settings on partially labeled data for detection and segmentation, with larger gains at lower label counts and generally stronger results from the equivariant approach.
What carries the argument
Consistency regularization across tasks using shared images with differently structured outputs, implemented through FixMatch for prediction invariance and Dense FixMatch for equivariance to geometric transformations.
If this is right
- Performance improvements are most pronounced with fewer labeled samples available for a given task.
- Equivariant semi-supervised learning generally produces better results than the invariant approach.
- The methods work for common computer vision tasks including object detection and semantic segmentation.
- The benefits persist across different sizes of annotated subsets and varying overlaps in label sets.
Where Pith is reading between the lines
- This approach may help lower the cost of annotating large multi-task datasets by using the same images for multiple purposes.
- Similar consistency techniques could be applied to other combinations of tasks beyond detection and segmentation.
- Testing on additional datasets would help determine if the gains generalize to different domains.
Load-bearing premise
The consistency assumptions underlying FixMatch and Dense FixMatch hold when the same image is used for two tasks with differently structured outputs and when the label sets for the tasks have arbitrary overlap.
What would settle it
An experiment on Cityscapes or BDD100K where semi-supervised multi-task models show no improvement or worse performance than the supervised baseline with reduced labeled samples for one task would falsify the central claim.
Figures


read the original abstract
We investigate the potential of invariant and equivariant semi-supervised learning for addressing the challenges of training multi-task models on partially labeled datasets with differently structured output tasks. Specifically, we use the popular FixMatch method for invariant semi-supervised learning and its equivariant extension Dense FixMatch. We evaluate their performance on the Cityscapes and BDD100K datasets in the context of the prevalent object detection and semantic segmentation tasks in computer vision. We consider varying sizes of the subsets annotated for each task and different overlaps among them. Our results for both invariant and equivariant semi-supervised learning outperform supervised baselines in most situations, with the most significant improvements observed when fewer labeled samples are available for a task and generally better results for the latter approach. Our study suggests that invariant/equivariant learning is a promising general direction for multi-task learning from limited labeled data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates using invariant semi-supervised learning (FixMatch) and its equivariant extension (Dense FixMatch) to train multi-task models for object detection and semantic segmentation on partially labeled datasets. It evaluates the approach on Cityscapes and BDD100K across varying label subset sizes and overlaps between tasks, claiming that both methods outperform supervised multi-task baselines in most cases, with larger gains when labeled data per task is scarce and generally stronger results for the equivariant variant.
Significance. If the empirical claims hold under scrutiny, the work would offer practical value for multi-task learning in computer vision, where full per-task labeling is expensive. Adapting established SSL techniques without new cross-task losses provides a lightweight solution, and the controlled variation of label fractions and overlaps supplies a useful benchmark. The study highlights a promising direction for leveraging unlabeled data across tasks with mismatched output structures.
major comments (1)
- The central assumption that per-task pseudo-labeling via FixMatch or Dense FixMatch remains reliable when an image receives supervision for only one task is load-bearing but unaddressed. Because detection and segmentation have differently structured outputs, strong augmentations and confidence-thresholded pseudo-labels for the unlabeled task can conflict with the supervised task on the same objects (e.g., bounding-box vs. mask inconsistencies), and no cross-task consistency term is described to resolve them. This directly affects whether the reported gains on Cityscapes/BDD100K generalize.
minor comments (2)
- The abstract states consistent outperformance but provides no quantitative numbers, error bars, or details on training schedules and hyper-parameters; these should be added to the results section to allow assessment of effect sizes.
- Clarify in the method section how pseudo-label generation and thresholding are applied independently per task without introducing cross-task conflicts on shared images.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the practical relevance of adapting invariant and equivariant SSL techniques to multi-task settings with partial labels. Below we respond point-by-point to the major comment.
read point-by-point responses
-
Referee: The central assumption that per-task pseudo-labeling via FixMatch or Dense FixMatch remains reliable when an image receives supervision for only one task is load-bearing but unaddressed. Because detection and segmentation have differently structured outputs, strong augmentations and confidence-thresholded pseudo-labels for the unlabeled task can conflict with the supervised task on the same objects (e.g., bounding-box vs. mask inconsistencies), and no cross-task consistency term is described to resolve them. This directly affects whether the reported gains on Cityscapes/BDD100K generalize.
Authors: We acknowledge the concern. Our implementation applies FixMatch (or Dense FixMatch) independently to each task: when an image is labeled only for detection, the segmentation head generates pseudo-labels from strongly augmented views using the standard confidence-thresholding procedure, while the detection loss uses the provided ground-truth boxes on the corresponding views. No explicit cross-task consistency loss is present. We argue that conflicts are limited in practice because (i) pseudo-labels are discarded below the confidence threshold, (ii) the shared backbone receives direct supervision from the labeled task, and (iii) the two tasks operate on differently structured outputs that are not forced into pixel-level alignment. The controlled experiments varying label fractions and task overlaps on Cityscapes and BDD100K show consistent gains over supervised multi-task baselines, supporting that any residual inconsistencies do not negate the benefit of leveraging unlabeled data per task. To improve clarity we will expand the method section to state the independent per-task application explicitly and add a short discussion paragraph on potential output-structure mismatches. revision: partial
Circularity Check
No significant circularity; empirical evaluation on held-out data
full rationale
The paper is an empirical study that applies established semi-supervised methods (FixMatch for invariant consistency and Dense FixMatch for equivariant consistency) to multi-task object detection and semantic segmentation on partially labeled Cityscapes and BDD100K data. Results are measured directly against held-out test sets and compared to supervised multi-task baselines across varying label sizes and overlaps. No mathematical derivation, first-principles prediction, or fitted-parameter renaming occurs; performance claims rest on experimental measurements rather than any self-referential reduction of outputs to inputs. Citations to prior FixMatch work are to independent external methods and do not form a load-bearing self-citation chain for the reported gains.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Consistency under augmentation remains a useful signal even when the same image carries labels for only one of the two tasks.
Reference graph
Works this paper leans on
-
[1]
A multitask deep learning model for real-time deployment in embedded systems
Miquel Mart. A multitask deep learning model for real-time deployment in embedded systems , journal =. 2017 , url =. 1711.00146 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[2]
S. Vandenhende and S. Georgoulis and W. Van Gansbeke and M. Proesmans and D. Dai and L. Van Gool , journal =. Multi-Task Learning for Dense Prediction Tasks: A Survey , year =. doi:10.1109/TPAMI.2021.3054719 , publisher =
-
[3]
Caruana, Rich , title =. Mach. Learn. , issue_date =. 1997 , issn =. doi:10.1023/A:1007379606734 , acmid =
-
[4]
2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
Taskonomy: Disentangling Task Transfer Learning , author=. 2018 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , year=
work page 2018
-
[5]
Zamir, Amir R. and Sax, Alexander and Cheerla, Nikhil and Suri, Rohan and Cao, Zhangjie and Malik, Jitendra and Guibas, Leonidas J. , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[6]
IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Li, Wei-Hong and Liu, Xialei and Bilen, Hakan , title =. IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[7]
Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =
Bilen, Hakan and Vedaldi, Andrea , title =. Proceedings of the 30th International Conference on Neural Information Processing Systems , pages =. 2016 , isbn =
work page 2016
-
[8]
Kokkinos, Iasonas , booktitle=. UberNet: Training a Universal Convolutional Neural Network for Low-, Mid-, and High-Level Vision Using Diverse Datasets and Limited Memory , year=
-
[9]
Zhou, Hongyu and Ge, Zheng and Liu, Songtao and Mao, Weixin and Li, Zeming and Yu, Haiyan and Sun, Jian , title =. Computer Vision – ECCV 2022: 17th European Conference, Tel Aviv, Israel, October 23–27, 2022, Proceedings, Part IX , pages =. 2022 , isbn =. doi:10.1007/978-3-031-20077-9_3 , abstract =
-
[10]
Amy Bearman and Olga Russakovsky and Vittorio Ferrari and Li Fei-Fei , journal=
-
[11]
The Cityscapes Dataset for Semantic Urban Scene Understanding , year=
Cordts, Marius and Omran, Mohamed and Ramos, Sebastian and Rehfeld, Timo and Enzweiler, Markus and Benenson, Rodrigo and Franke, Uwe and Roth, Stefan and Schiele, Bernt , booktitle=. The Cityscapes Dataset for Semantic Urban Scene Understanding , year=
-
[12]
Unsupervised Monocular Depth Estimation with Left-Right Consistency , author =. CVPR , year =
-
[13]
The International Conference on Computer Vision (ICCV) , month =
Digging into Self-Supervised Monocular Depth Prediction , author =. The International Conference on Computer Vision (ICCV) , month =
-
[14]
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Yu, Fisher and Chen, Haofeng and Wang, Xin and Xian, Wenqi and Chen, Yingying and Liu, Fangchen and Madhavan, Vashisht and Darrell, Trevor , title =. IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[15]
Disjoint Multi-task Learning Between Heterogeneous Human-Centric Tasks , year=
Kim, Dong-Jin and Choi, Jinsoo and Oh, Tae-Hyun and Yoon, Youngjin and Kweon, In So , booktitle=. Disjoint Multi-task Learning Between Heterogeneous Human-Centric Tasks , year=
-
[16]
Partly Supervised Multi-Task Learning , year=
Imran, Abdullah-Al-Zubaer and Huang, Chao and Tang, Hui and Fan, Wei and Xiao, Yuan and Hao, Dingjun and Qian, Zhen and Terzopoulos, Demetri , booktitle=. Partly Supervised Multi-Task Learning , year=
-
[17]
Nekrasov, Vladimir and Dharmasiri, Thanuja and Spek, Andrew and Drummond, Tom and Shen, Chunhua and Reid, Ian , title =. 2019 , publisher =. doi:10.1109/ICRA.2019.8794220 , booktitle =
-
[18]
Semi-supervised Multi-task Learning for Semantics and Depth , year=
Wang, Yufeng and Tsai, Yi-Hsuan and Hung, Wei-Chih and Ding, Wenrui and Liu, Shuo and Yang, Ming-Hsuan , booktitle=. Semi-supervised Multi-task Learning for Semantics and Depth , year=
-
[19]
Knowledge Distillation for Multi-task Learning , author=. Proceedings of the European Conference on Computer Vision Workshop on Imbalance Problems in Computer Vision , year=
-
[20]
Bhandari, Bhishan and Lee, Geonu and Cho, Jungchan , TITLE =. Applied Sciences , VOLUME =. 2020 , NUMBER =
work page 2020
-
[21]
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence , booktitle =
Kihyuk Sohn and David Berthelot and Nicholas Carlini and Zizhao Zhang and Han Zhang and Colin Raffel and Ekin Dogus Cubuk and Alexey Kurakin and Chun. FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence , booktitle =. 2020 , url =
work page 2020
-
[22]
Anthony Perez and Swetava Ganguli and Stefano Ermon and George Azzari and Marshall Burke and David B. Lobell , title =. CoRR , volume =. 2019 , url =. 1902.11110 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[23]
Proceedings of the Northern Lights Deep Learning Conference , volume=
Dense FixMatch: a simple semi-supervised learning method for pixel-wise prediction tasks , author =. Proceedings of the Northern Lights Deep Learning Conference , volume=. 2023 , url =
work page 2023
-
[24]
Proceedings of the Northern Lights Deep Learning Conference , volume=
An analysis of over-sampling labeled data in semi-supervised learning with FixMatch , author=. Proceedings of the Northern Lights Deep Learning Conference , volume=. 2022 , url=
work page 2022
-
[25]
International Conference on Learning Representations , year=
Theoretical Analysis of Self-Training with Deep Networks on Unlabeled Data , author=. International Conference on Learning Representations , year=
-
[26]
Rethinking Pre-training and Self-training , booktitle =
Barret Zoph and Golnaz Ghiasi and Tsung. Rethinking Pre-training and Self-training , booktitle =. 2020 , url =
work page 2020
-
[27]
Proceedings of The 33rd International Conference on Machine Learning , pages =
Group Equivariant Convolutional Networks , author =. Proceedings of The 33rd International Conference on Machine Learning , pages =. 2016 , editor =
work page 2016
-
[28]
Proceedings of the 37th International Conference on Machine Learning , pages =
A Simple Framework for Contrastive Learning of Visual Representations , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
work page 2020
-
[29]
Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning , url =
Grill, Jean-Bastien and Strub, Florian and Altch\'. Bootstrap Your Own Latent - A New Approach to Self-Supervised Learning , url =. Advances in Neural Information Processing Systems , editor =
-
[30]
Advances in neural information processing systems , volume=
Mixmatch: A holistic approach to semi-supervised learning , author=. Advances in neural information processing systems , volume=
-
[31]
Unsupervised Data Augmentation for Consistency Training , url =
Xie, Qizhe and Dai, Zihang and Hovy, Eduard and Luong, Thang and Le, Quoc , booktitle =. Unsupervised Data Augmentation for Consistency Training , url =
-
[32]
A Survey on Deep Semi-supervised Learning , publisher =
Yang, Xiangli and Song, Zixing and King, Irwin and Xu, Zenglin , keywords =. A Survey on Deep Semi-supervised Learning , publisher =. 2021 , copyright =. doi:10.48550/arxiv.2103.00550 , url =
-
[33]
Workshop on challenges in representation learning, ICML , volume=
Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks , author=. Workshop on challenges in representation learning, ICML , volume=. 2013 , url=
work page 2013
-
[34]
Self-Training With Noisy Student Improves ImageNet Classification , booktitle =
Qizhe Xie and Minh. Self-Training With Noisy Student Improves ImageNet Classification , booktitle =. 2020 , doi =
work page 2020
-
[35]
Antti Tarvainen and Harri Valpola , editor =. Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results , booktitle =. 2017 , url =
work page 2017
-
[36]
RandAugment: Practical Automated Data Augmentation with a Reduced Search Space , booktitle =
Ekin Dogus Cubuk and Barret Zoph and Jon Shlens and Quoc Le , editor =. RandAugment: Practical Automated Data Augmentation with a Reduced Search Space , booktitle =. 2020 , url =
work page 2020
-
[37]
A Simple Semi-Supervised Learning Framework for Object Detection , publisher =
Sohn, Kihyuk and Zhang, Zizhao and Li, Chun-Liang and Zhang, Han and Lee, Chen-Yu and Pfister, Tomas , keywords =. A Simple Semi-Supervised Learning Framework for Object Detection , publisher =. 2020 , copyright =. doi:10.48550/ARXIV.2005.04757 , url =
-
[38]
End-to-End Semi-Supervised Object Detection with Soft Teacher , year=
Xu, Mengde and Zhang, Zheng and Hu, Han and Wang, Jianfeng and Wang, Lijuan and Wei, Fangyun and Bai, Xiang and Liu, Zicheng , booktitle=. End-to-End Semi-Supervised Object Detection with Soft Teacher , year=
-
[39]
Consistency-based Semi-supervised Learning for Object detection , url =
Jeong, Jisoo and Lee, Seungeui and Kim, Jeesoo and Kwak, Nojun , booktitle =. Consistency-based Semi-supervised Learning for Object detection , url =
-
[40]
International Conference on Learning Representations , year=
Unbiased Teacher for Semi-Supervised Object Detection , author=. International Conference on Learning Representations , year=
-
[41]
British Machine Vision Conference , number=
Semi-supervised semantic segmentation needs strong, varied perturbations , author=. British Machine Vision Conference , number=
-
[42]
International Conference on Learning Representations , year=
PseudoSeg: Designing Pseudo Labels for Semantic Segmentation , author=. International Conference on Learning Representations , year=
-
[43]
Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision , year=
Chen, Xiaokang and Yuan, Yuhui and Zeng, Gang and Wang, Jingdong , booktitle=. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision , year=
-
[44]
Ke, Zhanghan and Qiu, Di and Li, Kaican and Yan, Qiong and Lau, Rynson W.H. , title =. European Conference on Computer Vision (ECCV) , month =. doi:10.1007/978-3-030-58601-0_26
-
[45]
ST++: Make Self-training Work Better for Semi-supervised Semantic Segmentation , author=. CVPR , year=
-
[46]
Advances in Neural Information Processing Systems , volume=
Semi-supervised semantic segmentation via adaptive equalization learning , author=. Advances in Neural Information Processing Systems , volume=
-
[47]
Semi-Supervised Semantic Segmentation Using Unreliable Pseudo Labels , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision and Pattern Recognition (CVPR) , year=
-
[48]
5th International Conference on Learning Representations,
Samuli Laine and Timo Aila , title =. 5th International Conference on Learning Representations,. 2017 , url =
work page 2017
-
[49]
Miyato, Takeru and Maeda, Shin-Ichi and Koyama, Masanori and Ishii, Shin , journal=. Virtual Adversarial Training: A Regularization Method for Supervised and Semi-Supervised Learning , year=
-
[50]
A survey on. Journal of Big Data , author =. 2019 , pages =. doi:10.1186/s40537-019-0197-0 , abstract =
-
[51]
Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month =
Lin, Tsung-Yi and Goyal, Priya and Girshick, Ross and He, Kaiming and Dollar, Piotr , title =. Proceedings of the IEEE International Conference on Computer Vision (ICCV) , month =
-
[52]
The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Rezatofighi, Hamid and Tsoi, Nathan and Gwak, JunYoung and Sadeghian, Amir and Reid, Ian and Savarese, Silvio , title =. The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) , month =
-
[53]
Advances in Neural Information Processing Systems 32 , editor =
PyTorch: An Imperative Style, High-Performance Deep Learning Library , author =. Advances in Neural Information Processing Systems 32 , editor =. 2019 , url =
work page 2019
-
[54]
E. Riba and D. Mishkin and D. Ponsa and E. Rublee and G. Bradski , title =. Winter Conference on Applications of Computer Vision , year =
-
[55]
Deep Residual Learning for Image Recognition , year=
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , booktitle=. Deep Residual Learning for Image Recognition , year=
-
[56]
Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation
Chen, Liang-Chieh and Zhu, Yukun and Papandreou, George and Schroff, Florian and Adam, Hartwig. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. Computer Vision -- ECCV 2018. 2018. doi:10.1007/978-3-030-01234-2_49
-
[57]
Luo, Yadan and Wang, Ziwei and Huang, Zi and Yang, Yang and Zhao, Cong , title =. Proceedings of the 27th ACM International Conference on Information and Knowledge Management , pages =. 2018 , isbn =. doi:10.1145/3269206.3271672 , abstract =
-
[58]
and McGuinness, Kevin , booktitle=
Arazo, Eric and Ortego, Diego and Albert, Paul and O’Connor, Noel E. and McGuinness, Kevin , booktitle=. Pseudo-Labeling and Confirmation Bias in Deep Semi-Supervised Learning , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.