Context Recycling for Long-Horizon LLM Inference
Pith reviewed 2026-07-01 08:09 UTC · model grok-4.3
The pith
ContextForge recycles context via structured queries and external memory to reduce token use in long LLM conversations while keeping accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
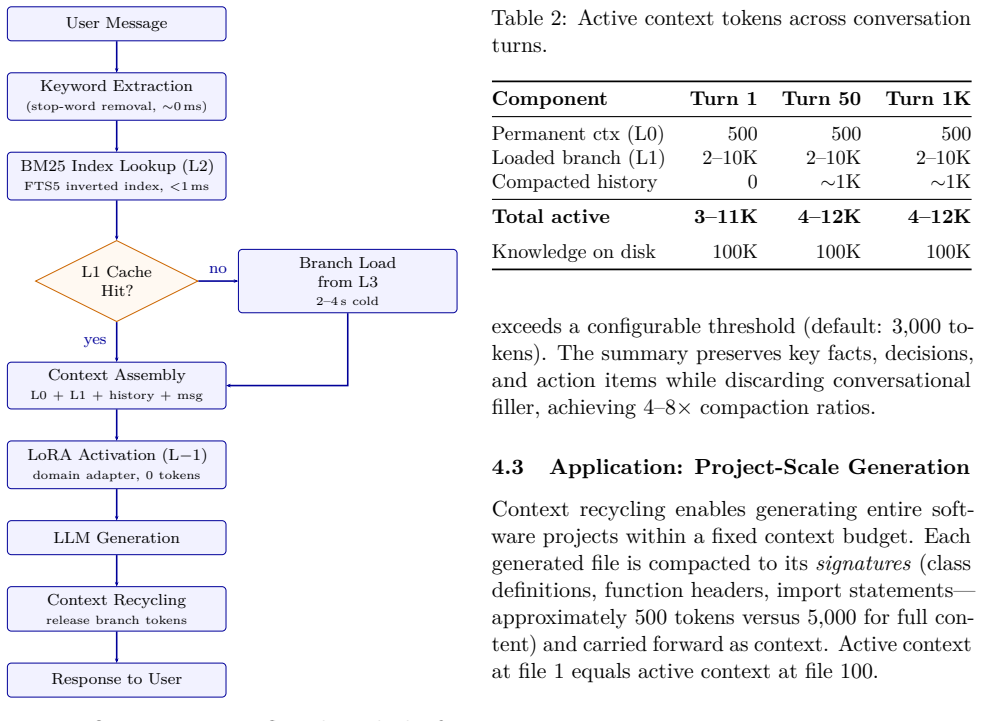
ContextForge enables efficient reuse of prior computation in LLM inference for long-horizon tasks by combining structured query generation, external memory retrieval, and controlled synthesis. This maintains task-relevant information across turns without full context replay. On a 15-turn conversational benchmark testing multi-turn reasoning, back-references, and domain shifts across structured healthcare queries, ContextForge achieves improved consistency and reduced token consumption while maintaining comparable response accuracy to baseline agents using identical underlying models.
What carries the argument
ContextForge system that recycles context through structured query generation, external memory retrieval, and controlled synthesis to reuse prior computation without full replay.
If this is right
- LLM capabilities extend to longer conversational horizons without needing larger context windows or model retraining.
- Token consumption drops in multi-turn tasks while answer quality stays comparable.
- Consistency improves on benchmarks that require back-references and domain shifts.
- Existing models can handle extended interactions through context recycling rather than full history replay.
Where Pith is reading between the lines
- The same recycling pattern could apply to long non-conversational contexts such as document summarization chains.
- Combining ContextForge with other memory techniques might further lower token counts in production systems.
- Applying the method to benchmarks with more than 15 turns or different domains would test its scaling limits.
Load-bearing premise
That structured query generation combined with external memory retrieval and controlled synthesis can keep task-relevant information intact across turns without major loss of context or accuracy.
What would settle it
A run of the 15-turn healthcare benchmark in which ContextForge shows lower accuracy or loses critical details compared with the baseline agent on the same models.
Figures

read the original abstract
Large language models (LLMs) exhibit strong capabilities in short-context reasoning but degrade in performance over long conversational horizons due to context window limitations and inefficient token usage. We introduce ContextForge, a system for context recycling that maintains task-relevant information across turns by combining structured query generation, external memory retrieval, and controlled synthesis. The system enables efficient reuse of prior computation without relying on full context replay, reducing token overhead while preserving answer quality. We evaluate ContextForge using a 15-turn conversational benchmark that tests multi-turn reasoning, back-references, and domain shifts across structured healthcare queries. Compared to a baseline agent using identical underlying models, ContextForge demonstrates improved consistency and reduced token consumption, while maintaining comparable response accuracy. These results suggest that context recycling provides a practical approach for extending LLM capabilities in long-horizon tasks without requiring larger context windows or model retraining. Code and evaluation artifacts are available at https://github.com/Betanu701/ContextForge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ContextForge, a modular system combining structured query generation, external memory retrieval, and controlled synthesis for context recycling in long-horizon LLM conversations. It evaluates the approach on a 15-turn conversational benchmark focused on multi-turn reasoning, back-references, and domain shifts in structured healthcare queries, claiming improved consistency and reduced token consumption with comparable accuracy relative to a baseline agent using identical models. Code and evaluation artifacts are provided for reproducibility.
Significance. If the empirical claims hold, the work demonstrates a practical, modular method for extending LLM performance on long conversations without larger context windows or retraining, by reusing prior computation via external memory. The availability of code and artifacts is a strength that enables direct verification of whether task-relevant information is preserved across turns.
major comments (1)
- [Abstract and Evaluation] The abstract and evaluation description assert improved consistency, reduced token consumption, and comparable accuracy on the 15-turn benchmark but supply no quantitative metrics, error bars, baseline details, or statistical tests, preventing verification that the data support the central claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the major comment below and commit to revisions that provide the requested quantitative details.
read point-by-point responses
-
Referee: [Abstract and Evaluation] The abstract and evaluation description assert improved consistency, reduced token consumption, and comparable accuracy on the 15-turn benchmark but supply no quantitative metrics, error bars, baseline details, or statistical tests, preventing verification that the data support the central claim.
Authors: We agree that the current abstract and evaluation description lack specific quantitative metrics, error bars, baseline details, and statistical tests. This prevents full verification of the claims as presented. We will revise the abstract to report key numerical results (e.g., token reduction percentages, consistency and accuracy scores with comparisons to the baseline) and expand the evaluation section to include error bars, explicit baseline specifications, and any applicable statistical tests. These additions will be supported by the existing code and artifacts. revision: yes
Circularity Check
No significant circularity; empirical system evaluation only
full rationale
The paper presents ContextForge as an engineering system (structured query generation + external memory + controlled synthesis) evaluated empirically on a 15-turn benchmark. No equations, fitted parameters, predictions derived from inputs, or self-citations appear in the provided text. The central claims rest on direct comparison of token consumption, consistency, and accuracy against a baseline using the same models; these outcomes are externally falsifiable via the supplied code and artifacts rather than reducing to any definitional or self-referential step.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks.arXiv preprint arXiv:2005.11401,
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[2]
Improving language models by retrieving from trillions of tokens
Sebastian Borgeaud, Arthur Mensch, Jordan Hoff- mann, Trevor Cai, Elber Rutherford, Katie Mil- lican, George van den Driessche, Jean-Baptiste Lasserre, Bogdan Damoc, Aidan Clark, Diego de Las Casas, Aurelia Guy, Jacob Menick, Roman Ring, Tom Hennigan, Saffron Huang, Loren Mag- giore, Chris Jones, Albin Cassirer, Andy Brock, Michela Paganini, Geoffrey Irvi...
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Extending Context Window of Large Language Models via Positional Interpolation
Shouyuan Chen, Sherman Wong, Liangjian Chen, and Yuandong Tian. Extending context window of large language models via positional interpola- tion.arXiv preprint arXiv:2306.15595,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Ofir Press, Noah A. Smith, and Mike Lewis. Train short, test long: Attention with linear biases en- ables input length extrapolation.arXiv preprint arXiv:2108.12409,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adapta- tion of large language models.arXiv preprint arXiv:2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
MemoryBank: Enhancing Large Language Models with Long-Term Memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. MemoryBank: Enhancing large language models with long-term memory. arXiv preprint arXiv:2305.10250,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. MemGPT: Towards LLMs as operating systems.arXiv preprint arXiv:2310.08560,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Efficient Memory Management for Large Language Model Serving with PagedAttention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph E. Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with PagedAttention.arXiv preprint arXiv:2309.06180,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention
Tsendsuren Munkhdalai and Manaal Faruqui. Leave no context behind: Efficient infinite context trans- formers with infini-attention.arXiv preprint arXiv:2404.07143,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
InfiniPot: Infinite context pro- cessing on memory-constrained LLMs.arXiv preprint arXiv:2410.01518,
Myeongjun Kim, Kibeom Shim, Jungwoo Choi, and Sungjoo Chang. InfiniPot: Infinite context pro- cessing on memory-constrained LLMs.arXiv preprint arXiv:2410.01518,
-
[11]
Zhenhailong Ouyang, Zhixuan Li, and Qimin Hou. K-LoRA: Unlocking training-free fusion of any subject and style LoRAs.arXiv preprint arXiv:2502.18461,
-
[12]
Fan Xia, Min Liao, Yun Fang, Dong Li, Yuxin Xie, Wenzhong Li, and Ye Li. Cross-LoRA: A data-free LoRA transfer framework across hetero- geneous LLMs.arXiv preprint arXiv:2508.05232,
-
[13]
Ben Jia Chan, Chieh-Ting Chen, Jia-Hua Cheng, and Hen-Hsen Huang. Don’t do RAG: When cache-augmented generation is all you need for knowledge tasks.arXiv preprint arXiv:2412.15605,
-
[14]
Mengkang Hu, Tianxing Chen, Qiguang Chen, Yao Mu, Wenqi Shao, and Ping Luo. HiAgent: Hier- archical working memory management for solv- ing long-horizon agent tasks with large language model.arXiv preprint arXiv:2408.09559,
-
[15]
HiMem: Hierarchical long-term memory for LLM long-horizon agents.CoRR, abs/2601.06377, 2026
Nan Zhang, Xu Yang, Zeyu Tan, Weidong Deng, and Wei Wang. HiMem: Hierarchical long-term memory for LLM long-horizon agents.arXiv preprint arXiv:2601.06377,
-
[16]
Cognitive memory in large language models
Lei Shan, Songlin Luo, Zhuo Zhu, Yongpeng Yuan, and Yong Wu. Cognitive memory in large lan- guage models.arXiv preprint arXiv:2504.02441,
-
[17]
TreeRAG: Unleash- ing the power of hierarchical storage for en- hanced knowledge retrieval in long documents
Wenyu Tao, Xiaofen Xing, Yirong Chen, Linyi Huang, and Xiangmin Xu. TreeRAG: Unleash- ing the power of hierarchical storage for en- hanced knowledge retrieval in long documents. InFindings of the Association for Computational Linguistics: ACL 2025, pages 356–371, Vienna, Austria,
2025
-
[18]
https://aclanthology.org/2025
Association for Computational Linguistics. https://aclanthology.org/2025. findings-acl.20/. OpenAI. Introducing GPT-5.4. March 5,
2025
-
[19]
https: //learn.microsoft.com/en-us/fabric/ data-science/how-to-create-data-agent. Wu, Y., et al. ContextBudget: Budget-aware con- text management for long-horizon search agents. arXiv preprint arXiv:2604.01664,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.