Hey Chat, Can You Teach Me? Structuring Socratic Dialogue for Human Learning in the Wild
Pith reviewed 2026-06-27 09:54 UTC · model grok-4.3
The pith
Structuring Socratic tutoring around a prerequisite graph and sequencing policy outperforms scaling large language models alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
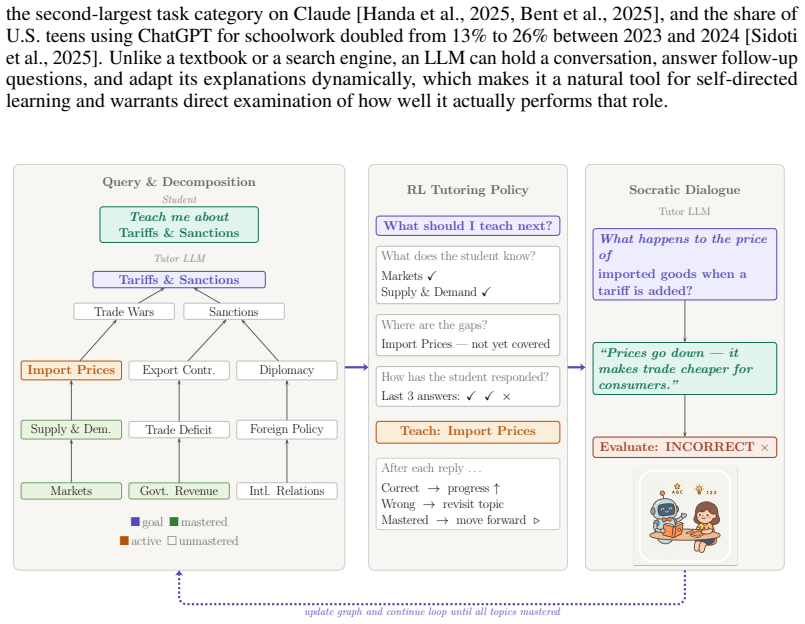
By constructing a prerequisite knowledge graph in which subtopics are nodes and dependencies are edges, then using a PPO policy to select the next node and the number of dialogue turns to allocate before advancing, while an LLM handles only the Socratic exchange and returns a progress signal, the tutor reaches full curriculum mastery faster and with fewer turns than heuristic baselines, frontier general-purpose models, or models specialized for Socratic dialogue, on both STEM and non-STEM held-out topics.
What carries the argument
A prerequisite knowledge graph whose nodes are subtopics and edges are dependencies, paired with a PPO policy that chooses the next node and the turn budget for it.
If this is right
- Students reach full curriculum mastery at higher rates than with unstructured or heuristic tutoring.
- Fewer dialogue turns are required to complete the curriculum.
- The gains appear on both STEM and non-STEM topics.
- Explicit structure produces improvements that larger or specialized language models do not match on their own.
Where Pith is reading between the lines
- The separation of graph construction, sequencing, and dialogue could be tested in other interactive teaching formats such as worked examples or project-based tasks.
- If graph accuracy improves with better extraction methods, the same policy could support longer multi-session learning paths.
- The approach invites direct comparison against human tutor sequencing decisions on the same topic graphs.
Load-bearing premise
The automatically constructed prerequisite graph correctly captures topic dependencies and the language model produces a usable progress signal that the policy can rely on for sequencing.
What would settle it
Replace the learned policy with random node selection on the same graph and measure whether mastery rate and turn count remain better than the unstructured frontier models.
Figures


read the original abstract
Large language models are now widely used for everyday learning, but the underlying interactions are typically unstructured chats rather than following a curriculum. Unlike formal online learning systems, these interactions carry no prior record of the student, so any estimate of what the student already knows must be inferred from the dialogue itself. We show that this gap is not closed by scaling models alone. Frontier and education-tuned LLMs perform poorly when asked to tutor a student over an extended session, because doing so requires three things at once. The tutor must sequence a curriculum, conduct Socratic dialogue, and infer the student's knowledge state from that dialogue. We propose separating these responsibilities. Given a student query, our system constructs a prerequisite knowledge graph in which subtopics are nodes and dependencies are edges, and frames tutoring as deciding which node to teach next and how many dialogue turns to spend on it before moving on. A lightweight PPO policy handles this sequencing decision, while an LLM conducts the Socratic exchange at the chosen node and returns a signal of student progress. Across held-out STEM and non-STEM topics, our PPO-paired tutor outperforms heuristic baselines, frontier general-purpose models, and a model specialised for Socratic dialogue: on both the rate at which students reach full curriculum mastery and the number of turns required. Explicit curriculum structure delivers gains that scaling the underlying model does not.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that separating curriculum sequencing (via automatic construction of a prerequisite knowledge graph and a lightweight PPO policy deciding which node to teach next and for how many turns) from Socratic dialogue execution (handled by an LLM that also emits a scalar progress signal) yields better outcomes than scaling LLMs or using heuristic/Socratic-specialized baselines. Specifically, the PPO-paired tutor achieves higher rates of students reaching full curriculum mastery and requires fewer turns, across held-out STEM and non-STEM topics; the central thesis is that explicit structure provides gains that model scale alone does not.
Significance. If the reported gains are shown to rest on externally validated components rather than internal LLM signals, the work would be significant for LLM tutoring design: it offers a concrete, modular architecture that addresses the multi-task burden on a single model and demonstrates measurable benefits of curriculum structure over unstructured chat. The separation of concerns is a clear strength and could inform follow-on systems.
major comments (3)
- [Evaluation] Evaluation section (and abstract): the progress signal produced by the same LLM that conducts the Socratic turns is used both to train the PPO policy and to declare 'full curriculum mastery' for the headline metrics. No independent validation of this signal against human expert judgments, pre/post knowledge tests, or external rubrics is reported; without it the performance deltas cannot be distinguished from artifacts of the signal's own biases.
- [Method] Prerequisite graph construction (and method): the automatically built graph supplies the legal sequences and dependencies that the PPO policy optimizes over. The manuscript supplies no comparison of these edges to expert-curated graphs, human-validated prerequisite relations, or ablation studies that remove or perturb the graph; this component is load-bearing for the claim that explicit structure, rather than the LLM alone, drives the gains.
- [Results] Experimental design (abstract and results): comparative outperformance is asserted on mastery rate and turns, yet the abstract and summary provide no details on participant pool size or demographics, exact operationalization of 'mastery,' statistical tests, confidence intervals, or controls for confounds such as topic selection bias or varying student priors. These omissions prevent assessment of whether the data support the central claim.
minor comments (1)
- [Abstract] Abstract: the phrase 'held-out STEM and non-STEM topics' is used without enumerating the topics or the hold-out procedure, which would improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, with honest indications of where revisions will be made and where limitations must be acknowledged.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section (and abstract): the progress signal produced by the same LLM that conducts the Socratic turns is used both to train the PPO policy and to declare 'full curriculum mastery' for the headline metrics. No independent validation of this signal against human expert judgments, pre/post knowledge tests, or external rubrics is reported; without it the performance deltas cannot be distinguished from artifacts of the signal's own biases.
Authors: We agree this is a substantive limitation. Because the identical LLM-generated signal is used for training, evaluation, and all baselines, relative gains can still be attributed to the PPO sequencing component. However, we cannot rule out that the signal's biases inflate absolute mastery rates. In revision we will add an explicit limitations paragraph discussing this issue and the practical difficulties of external validation in wild, unstructured settings. No new validation data can be supplied from the existing experiments. revision: partial
-
Referee: [Method] Prerequisite graph construction (and method): the automatically built graph supplies the legal sequences and dependencies that the PPO policy optimizes over. The manuscript supplies no comparison of these edges to expert-curated graphs, human-validated prerequisite relations, or ablation studies that remove or perturb the graph; this component is load-bearing for the claim that explicit structure, rather than the LLM alone, drives the gains.
Authors: The central claim is that automatic construction of an explicit graph enables better outcomes than unstructured LLM chat; the primary evidence is the performance gap versus the no-graph baselines. We will add a new ablation that removes the graph (allowing the policy to select any node without dependency constraints) to isolate its contribution. Direct comparison to expert-curated graphs is outside the scope of the current work, which deliberately targets automatic, scalable construction without expert input. revision: yes
-
Referee: [Results] Experimental design (abstract and results): comparative outperformance is asserted on mastery rate and turns, yet the abstract and summary provide no details on participant pool size or demographics, exact operationalization of 'mastery,' statistical tests, confidence intervals, or controls for confounds such as topic selection bias or varying student priors. These omissions prevent assessment of whether the data support the central claim.
Authors: We will revise the abstract, results section, and add a summary table to include all requested details: participant pool size and demographics, precise mastery definition, statistical tests with p-values and confidence intervals, and controls for topic selection and prior knowledge via randomization. These elements appear in the full experimental protocol and will now be foregrounded. revision: yes
- Independent external validation of the LLM progress signal against human experts or pre/post tests (would require new data collection).
- Direct comparison of the automatically constructed graph against expert-curated prerequisite relations (would require additional human annotation not performed in this study).
Circularity Check
No circularity; empirical claims rest on external baseline comparisons
full rationale
The paper proposes separating curriculum sequencing (via PPO) from Socratic dialogue and progress inference (via LLM), then reports empirical gains on held-out topics versus heuristic baselines, frontier LLMs, and specialized models. No derivation chain reduces a claimed result to a fitted parameter or self-referential definition; the progress signal and graph are components whose reliability is an assumption, not a quantity defined in terms of the policy output. No self-citation load-bearing steps, uniqueness theorems, or ansatzes appear in the provided abstract and description. The evaluation metrics are measured against independent baselines, satisfying the self-contained benchmark criterion for a score of 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
doi: 10.1080/00461520.2014. 965823. David Dinucu-Jianu, Jakub Macina, Nico Daheim, Ido Hakimi, Iryna Gurevych, and Mrinmaya Sachan. From problem-solving to teaching problem-solving: Aligning llms with pedagogy using reinforcement learning. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 272–292,
-
[2]
Giselle Gonzalez Garcia and Christian Weilbach. If the sources could talk: Evaluating large language models for research assistance in history.arXiv preprint arXiv:2310.10808,
-
[3]
Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville
URL https://www.anthropic.com/news/anthropic-education-report-how-universit y-students-use-claude. Philippe Laban, Hiroaki Hayashi, Yingbo Zhou, and Jennifer Neville. Llms get lost in multi-turn conversation. InICLR 2026, May
2026
-
[4]
arXiv preprint arXiv:2412.16429 , year=
URL https://www.microsoft.com/en-us/resear ch/publication/llms-get-lost-in-multi-turn-conversation/. LearnLM Team. Learnlm: Improving gemini for learning.arXiv preprint arXiv:2412.16429,
-
[5]
Evaluating gemini in an arena for learning.arXiv preprint arXiv:2505.24477,
LearnLM Team. Evaluating gemini in an arena for learning.arXiv preprint arXiv:2505.24477,
-
[6]
Unggi Lee, Joo Young Kim, Ran Ju, Minyoung Jung, and Jeyeon Eo. A training-free large reasoning model-based knowledge tracing framework for unified prediction and prescription.arXiv preprint arXiv:2601.01708,
-
[7]
Hyunji Nam, Omer Gottesman, Amy Zhang, Dean Foster, Emma Brunskill, and Lyle Ungar. Ef- ficient rl for optimizing conversation level outcomes with an llm-based tutor.arXiv preprint arXiv:2507.16252,
-
[8]
Yilmazcan Ozyurt, Tunaberk Almaci, Stefan Feuerriegel, and Mrinmaya Sachan. Personal- ized exercise recommendation with semantically-grounded knowledge tracing.arXiv preprint arXiv:2507.11060,
-
[9]
URLhttps://arxiv.org/abs/2412.15115. Antonin Raffin, Ashley Hill, Adam Gleave, Anssi Kanervisto, Maximilian Ernestus, and Noah Dormann. Stable-baselines3: Reliable reinforcement learning implementations.Journal of Machine Learning Research, 22(268):1–8,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
URLhttps://arxiv.org/abs/2402.03300. Kumar Shridhar, Jakub Macina, Mennatallah El-Assady, Tanmay Sinha, Manu Kapur, and Mrinmaya Sachan. Automatic generation of socratic subquestions for teaching math word problems. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Proce...
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
doi: 10.18653/v1/2022.e mnlp-main.277
Association for Computational Linguistics. doi: 10.18653/v1/2022.e mnlp-main.277. URLhttps://aclanthology.org/2022.emnlp-main.277/. Olivia Sidoti, Eugenie Park, and Jeffrey Gottfried. About a quarter of U.S. teens have used ChatGPT for schoolwork – double the share in 2023,
-
[13]
Anni Siren and Vassilios Tzerpos
URL https://www.pewresearch.org/shor t-reads/2025/01/15/about-a-quarter-of-us-teens-have-used-chatgpt-for-sch oolwork-double-the-share-in-2023/. Anni Siren and Vassilios Tzerpos. Automatic learning path creation using oer: a systematic literature mapping.IEEE Transactions on Learning Technologies,
2025
-
[14]
doi: 10.1080/00461520.2011. 611369. Shouang Wei, Min Zhang, Xin Lin, Bo Jiang, Kun Kuang, and Zhongxiang Dai. Uco: A multi-turn interactive reinforcement learning method for adaptive teaching with large language models,
-
[15]
Eamon Worden, Cristina Heffernan, Neil Heffernan, and Shashank Sonkar
URLhttps://arxiv.org/abs/2511.08873. Eamon Worden, Cristina Heffernan, Neil Heffernan, and Shashank Sonkar. Foundationalassist: An educational dataset for foundational knowledge tracing and pedagogical grounding of llms.arXiv preprint arXiv:2602.00070,
-
[16]
Meriem Zerkouk, Miloud Mihoubi, and Belkacem Chikhaoui. A comprehensive review of ai-based intelligent tutoring systems: applications and challenges.arXiv preprint arXiv:2507.18882,
-
[17]
13 A End-to-End RL for Socratic Qualities Model: finetuned Teacher That’s great to hear! You’ve told me that you’re interested in learning about Pythagorean Theorem. [. . . ] Can you tell me, do you know how it relates to triangles? Student The theorem can help us find the perimeter of any triangle if we know two sides. Teacher That’s a great insight! You...
2025
-
[18]
That’s great to hear! You mentioned that you’re
Looking at these conversations side by side makes it easy to see how each model handles the same student query and how their styles diverge. We discover that the finetuned Qwen2.5-7B has collapsed into reward hacking behavior. In particular, the model leans heavily on a small set of repeated openers such as “That’s great to hear! You mentioned that you’re...
2024
-
[19]
Limitations
Rows shaded green are our proposed methods; rows shaded grey are LLM-based comparisons. Steps is∆% relative to Oracle (lower is better; Oracle raw mean =31.00±0.71 steps). Mastery is reported as a percentage. All CIs are 95% (t-distribution). †Methods using ground-truth mastery signals are not deployable. Scope Obs. Method n Success (%) Steps∆%Mastery (%)...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.