Autonomous Video Generation with Counterfactual Controllability for Self-Evolving World Models
Pith reviewed 2026-06-26 01:37 UTC · model grok-4.3
The pith
Adding counterfactual controllability to video generation creates self-evolving world models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Video generation models learn a partial, implicit spatiotemporal world model, but not a fully grounded or controllable one. The frontier is not predictive realism alone; it emphasizes a self-evolving generative nature that requires the decisive criterion to be counterfactual controllability: the capability of asking what would happen under an action, to test whether the generated future can survive embodiment constraints and to feed the resulting action knowledge back into future imagination. Therefore, autonomous video generation with counterfactual controllability is one promising way to realize self-evolving world models.
What carries the argument
Counterfactual controllability, the ability to simulate outcomes under specific actions and check if they respect embodiment constraints, which allows feeding action knowledge back into the generative process.
If this is right
- Generated videos can be tested for validity under interventions rather than just visual plausibility.
- Action knowledge from valid futures updates the model's future imagination cycles.
- Models move toward becoming physical agents by learning controllable variables.
- Self-evolution occurs through iterative feedback from counterfactual queries.
Where Pith is reading between the lines
- Such models might serve as simulators for planning in robotics without real-world interaction.
- Benchmarks could focus on measuring how well generated futures match real intervention outcomes.
- This perspective might apply to other generative domains like text or audio for building controllable world models.
Load-bearing premise
Current video generation models lack knowledge of controllable variables and valid futures under intervention, and counterfactual controllability will lead to self-evolution instead of staying ungrounded.
What would settle it
Demonstrating a video model with added counterfactual controllability that still cannot identify controllable elements or improve its generations over time through action feedback.
Figures
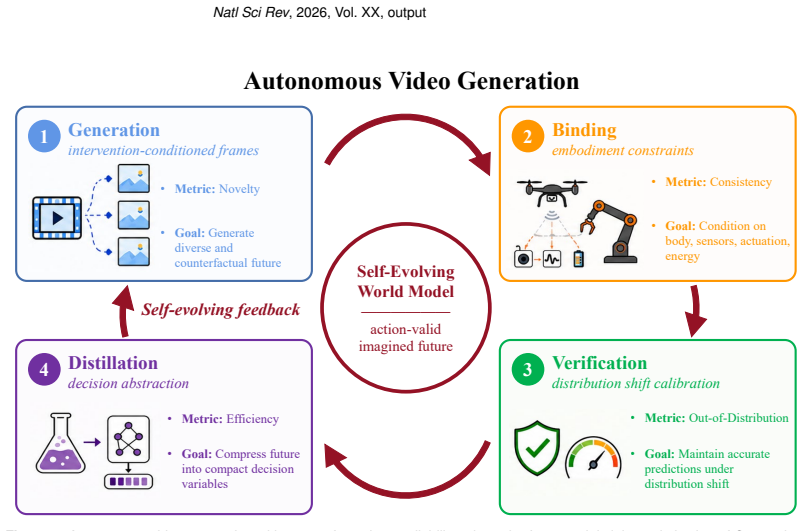
read the original abstract
Existing literature claims that video generation essentially is world modelling. On the one hand, the claim is productive because it pushes generative AI beyond static images and toward temporally extended physical scenes. On the other hand, this claim dangerously relies on the belief that scaling visual prediction alone will automatically yield physical agents. We prefer a more accurate statement: video generation models learn a partial, implicit spatiotemporal world model, but not a fully grounded or controllable one. The reason is as follows: a model may generate a plausible video of a drone crossing a forest or a robot arm manipulating a cup, yet still fail to know which variables are controllable, which constraints belong to a particular body and which futures remain valid under intervention. The frontier in essence is not predictive realism alone, instead it emphasizes a self-evolving generative nature that requires the decisive criterion to be counterfactual controllability: the capability of asking what would happen under an action, to test whether the generated future can survive embodiment constraints and to feed the resulting action knowledge back into future imagination (generation). Therefore, in this paper we present a new perspective, i.e., autonomous video generation with counterfactual controllability is one promising way to realize self-evolving world models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents a perspective arguing that existing video generation models learn only partial, implicit spatiotemporal world models rather than fully grounded or controllable ones. It identifies the key limitation as the inability to distinguish controllable variables, body-specific constraints, and valid futures under intervention, and proposes that autonomous video generation with counterfactual controllability—the capacity to query outcomes under actions, test embodiment constraints, and feed results back into generation—provides a promising route to self-evolving world models.
Significance. If the perspective is adopted, it could usefully redirect attention in generative modeling from pure predictive scaling toward intervention-aware mechanisms that better support embodied reasoning. As a conceptual position paper without empirical results, formal derivations, or testable predictions, its contribution lies in framing a distinction rather than demonstrating a mechanism.
major comments (1)
- [Abstract] Abstract: the definitions of a 'partial, implicit spatiotemporal world model' and 'counterfactual controllability' are introduced interdependently, with the former characterized precisely by the absence of the capabilities that define the latter; this interdependence makes the central distinction circular rather than independently motivated.
Simulated Author's Rebuttal
We thank the referee for the detailed review and the constructive comment on the abstract. As a perspective paper, our goal is to frame a conceptual distinction between current video generation and the requirements for self-evolving world models. We address the specific concern below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the definitions of a 'partial, implicit spatiotemporal world model' and 'counterfactual controllability' are introduced interdependently, with the former characterized precisely by the absence of the capabilities that define the latter; this interdependence makes the central distinction circular rather than independently motivated.
Authors: We acknowledge the interdependence noted in the abstract. The partial world model is motivated by empirical observations in the video generation literature (plausible outputs that nonetheless fail under intervention), while counterfactual controllability is drawn from causal reasoning principles. However, to avoid any appearance of circularity, we will revise the abstract to first characterize a partial spatiotemporal world model via its predictive limitations independent of the proposed solution, then define counterfactual controllability as an interventional capability, and only afterward connect the two as a route to self-evolving models. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper is a position paper that advances a conceptual perspective distinguishing partial implicit world models from controllable ones, without any equations, parameter fits, derivations, or technical mechanisms. No load-bearing step reduces to a self-definition, fitted input renamed as prediction, or self-citation chain. The argument is self-contained as an opinion on research direction and does not assert results whose validity depends on internal construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Video generation models as world simulators
OpenAI. Video generation models as world simulators
-
[2]
https://openai.com/index/video-generation-models- as-world-simulators/
-
[3]
A note on the eval- uation of generative models
Theis L, van den Oord A and Bethge M. A note on the eval- uation of generative models. In:International Conference on Learning Representations. 2016
2016
-
[4]
Improved preci- sion and recall metric for assessing generative models
Kynk ¨a¨anniemi T, Karras T, Laine Set al. Improved preci- sion and recall metric for assessing generative models. In: Advances in Neural Information Processing Systems 32. 2019
2019
-
[5]
The unreasonable effec- tiveness of deep features as a perceptual metric
Zhang R, Isola P , Efros AAet al. The unreasonable effec- tiveness of deep features as a perceptual metric. In:Pro- ceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018, 586–595
2018
-
[6]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner T, van Steenkiste S, Kurach Ket al. Towards accurate generative models of video: a new metric and challenges. arXiv:1812.01717, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[7]
VBench: comprehensive bench- mark suite for video generative models
Huang Z, He Y , Yu Jet al. VBench: comprehensive bench- mark suite for video generative models. In:Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2024
2024
-
[8]
Recurrent world models facili- tate policy evolution
Ha D and Schmidhuber J. Recurrent world models facili- tate policy evolution. In:Advances in Neural Information Processing Systems 31. 2018
2018
-
[9]
Learning latent dynam- ics for planning from pixels
Hafner D, Lillicrap T, Fischer Iet al. Learning latent dynam- ics for planning from pixels. In:Proceedings of the 36th In- ternational Conference on Machine Learning. PMLR 2019; 97: 2555–2565
2019
-
[10]
Mastering di- verse control tasks through world models.Nature2025; 640: 647–653
Hafner D, Pasukonis J, Ba J and Lillicrap T. Mastering di- verse control tasks through world models.Nature2025; 640: 647–653
-
[11]
RT -2: Vision-language-action models transfer web knowledge to robotic control
Zitkovich B, Yu T, Xu Set al. RT -2: Vision-language-action models transfer web knowledge to robotic control. In:Pro- ceedings of The 7th Conference on Robot Learning. PMLR 2023;229: 2165–2183
2023
-
[12]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Black K, Brown N, Driess Det al.𝜋 0: A vision- language-action flow model for general robot control. arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
VIMA: General robot ma- nipulation with multimodal prompts
Jiang Y , Gupta A, Zhang Zet al. VIMA: General robot ma- nipulation with multimodal prompts. In:Proceedings of the 40th International Conference on Machine Learning. PMLR 2023;202: 14975–15022
2023
-
[14]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Open X-Embodiment Collaboration, O’Neill A, Rehman A et al. Open X-Embodiment: robotic learning datasets and RT -X models. arXiv:2310.08864, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[15]
Chi C, Xu Z, Feng Set al. Diffusion policy: visuomotor policy learning via action diffusion.Int J Robot Res2025; doi:10.1177/02783649241273668
-
[16]
Learning to simulate complex physics with graph networks
Sanchez-Gonzalez A, Godwin J, Pfaff Tet al. Learning to simulate complex physics with graph networks. In:Pro- ceedings of the 37th International Conference on Machine Learning. PMLR 2020;119: 8459–8468
2020
-
[17]
Genie: generative interactive environments
Bruce J, Dennis M, Edwards Aet al. Genie: generative interactive environments. In:Proceedings of the 41st In- ternational Conference on Machine Learning. PMLR 2024; 235: 4603–4623
2024
-
[18]
Learning interactive real-world simulators
Y ang S, Du Y , Ghasemipour SKSet al. Learning interactive real-world simulators. In:The T welfth International Confer- ence on Learning Representations. 2024
2024
-
[19]
Cosmos World Foundation Model Platform for Physical AI
Agarwal N, Ali A, Bala Met al. Cosmos world foundation model platform for physical AI. arXiv:2501.03575, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran M, Bardes A, Misra Iet al. V-JEPA 2: self- supervised video models enable understanding, predic- tion and planning in the physical world. arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[21]
Pearl J.Causality: Models, Reasoning, and Inference. 2nd ed. Cambridge: Cambridge University Press, 2009
2009
-
[22]
The essential role of causality in foundation world models for embodied AI
Li Z, Chen T, Wang Yet al. The essential role of causality in foundation world models for embodied AI. arXiv:2402.06665, 2024
-
[23]
Benchmarking neural net- work robustness to common corruptions and perturbations
Hendrycks D and Dietterich T. Benchmarking neural net- work robustness to common corruptions and perturbations. In:International Conference on Learning Representations. 2019
2019
-
[24]
WILDS: a bench- mark of in-the-wild distribution shifts
Koh PW, Sagawa S, Marklund Het al. WILDS: a bench- mark of in-the-wild distribution shifts. In:Proceedings of the 38th International Conference on Machine Learning. PMLR 2021;139: 5637–5664
2021
-
[25]
Can you trust your model’s uncertainty? Evaluating predictive uncertainty un- der dataset shift
Ovadia Y , Fertig E, Ren Jet al. Can you trust your model’s uncertainty? Evaluating predictive uncertainty un- der dataset shift. In:Advances in Neural Information Pro- cessing Systems 32. 2019
2019
-
[26]
Control barrier functions: theory and applications
Ames AD, Coogan S, Egerstedt Met al. Control barrier functions: theory and applications. In:2019 18th European Control Conference. IEEE, 2019, 3420–3431. Page 5 of 5
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.