Bridging Video Understanding and Generation in a Unified Framework
Pith reviewed 2026-07-01 05:55 UTC · model grok-4.3
The pith
Vega unifies video understanding and generation with a shared vocabulary and hybrid AR-diffusion model.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
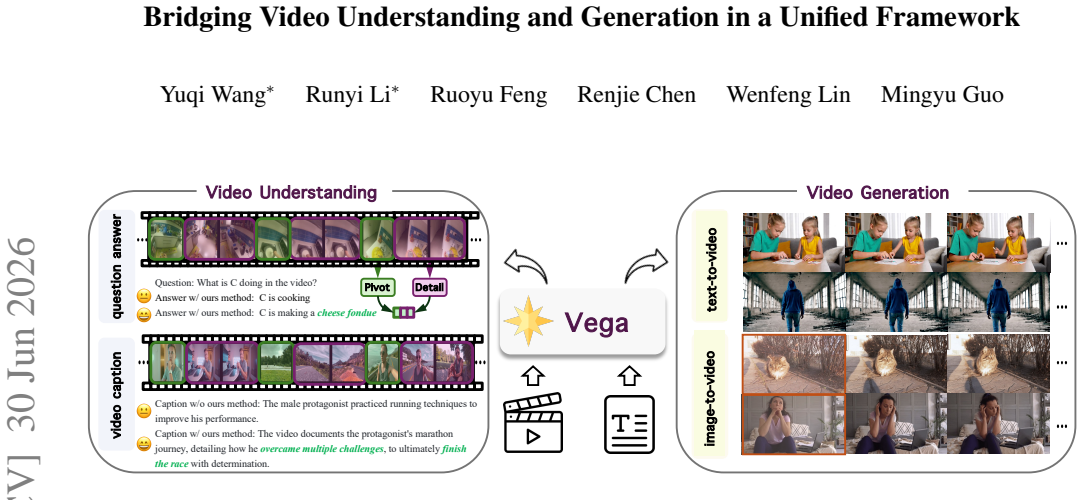
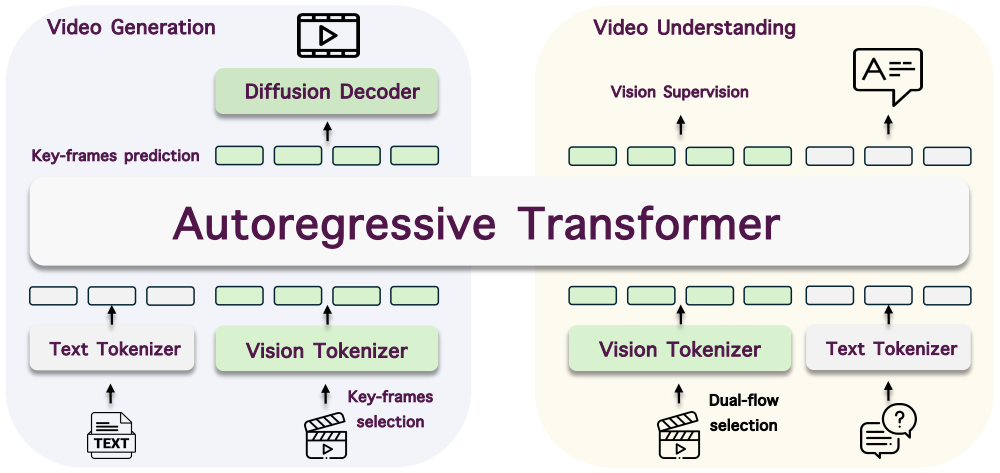
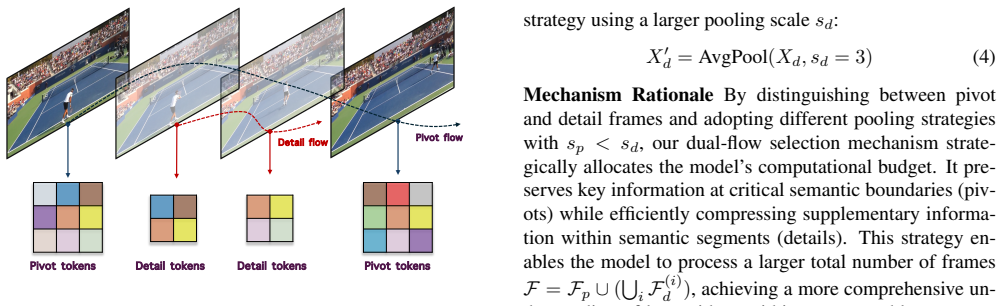
Vega leverages a shared vocabulary to jointly model text and visual representations and employs a hybrid architecture combining autoregressive prediction with diffusion-based rendering. Specifically, the AR model focuses on predicting semantically meaningful visual tokens for keyframes, providing a structured representation that guides the diffusion module in rendering dense, high-resolution video frames.
What carries the argument
Hybrid autoregressive-diffusion architecture with shared vocabulary, where AR prediction of semantic tokens on keyframes guides diffusion rendering of full frames.
If this is right
- Vega achieves strong performance on video generation benchmarks such as VBench.
- Vega achieves strong performance on video understanding benchmarks like VideoMME.
- The AR component supplies structured semantic guidance that enables the diffusion module to produce coherent high-resolution output.
- Videos serve as a more suitable modality than static images for unified multimodal modeling due to their inherent spatial and temporal content.
Where Pith is reading between the lines
- The keyframe-based AR guidance could be tested for extension to longer video sequences where temporal coherence becomes harder to maintain.
- Sharing the vocabulary might allow transfer of learned representations between understanding and generation tasks during joint training.
- If the hybrid split works, similar AR-diffusion divisions could apply to other sequential modalities such as audio or 3D motion.
Load-bearing premise
A single shared vocabulary and hybrid AR-diffusion architecture can satisfy both compact semantic needs of understanding and dense temporal-detail needs of generation without one task degrading the other.
What would settle it
If specialized understanding models outperform Vega on VideoMME or specialized generation models outperform it on VBench by a clear margin when tested under identical conditions.
Figures




read the original abstract
Recently, unified image generation and understanding have been extensively explored. However, extending such unified modeling paradigms to the video domain remains largely underexplored. A central challenge is that video understanding favors compact, discriminative semantic representations, whereas video generation requires dense signals that preserve visual details and temporal coherence. Videos naturally capture both spatial semantics and temporal dynamics, making them a more suitable modality for unified multimodal modeling compared to static images. In this paper, we propose Vega, a unified framework that bridges video understanding and generation. Vega leverages a shared vocabulary to jointly model text and visual representations and employs a hybrid architecture combining autoregressive (AR) prediction with diffusion-based rendering. Specifically, the AR model focuses on predicting semantically meaningful visual tokens for keyframes, providing a structured representation that guides the diffusion module in rendering dense, high-resolution video frames. Extensive experiments demonstrate that Vega achieves strong performance on video generation benchmarks such as VBench and video understanding benchmarks like VideoMME.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Vega, a unified framework for video understanding and generation. It uses a shared vocabulary to jointly model text and visual representations and a hybrid architecture that combines autoregressive (AR) prediction of semantically meaningful visual tokens for keyframes with diffusion-based rendering to produce dense, high-resolution video frames. The paper asserts that this design yields strong performance on video generation benchmarks such as VBench and video understanding benchmarks such as VideoMME.
Significance. A successful resolution of the representational conflict between compact semantics for understanding and dense temporal detail for generation would represent a meaningful advance in unified video modeling. The hybrid AR-diffusion design with shared vocabulary is a plausible architectural response to this tension. However, the complete absence of any quantitative results, baselines, ablations, or experimental protocols in the manuscript prevents any assessment of whether the claimed performance is achieved or whether one task degrades the other.
major comments (1)
- [Abstract] Abstract: The assertion that Vega 'achieves strong performance' on VBench and VideoMME supplies no metrics, baseline comparisons, ablation results, or experimental details. This omission is load-bearing because the abstract itself identifies the core challenge (compact vs. dense representations) and the central claim is that the hybrid architecture resolves it without degradation.
Simulated Author's Rebuttal
We thank the referee for identifying the critical gap in experimental evidence. The submitted manuscript indeed contains no quantitative results, baselines, ablations, or protocol details, which prevents evaluation of the central claim that the hybrid architecture resolves the compact-vs-dense representation tension without degradation. We will address this directly in revision.
read point-by-point responses
-
Referee: [Abstract] Abstract: The assertion that Vega 'achieves strong performance' on VBench and VideoMME supplies no metrics, baseline comparisons, ablation results, or experimental details. This omission is load-bearing because the abstract itself identifies the core challenge (compact vs. dense representations) and the central claim is that the hybrid architecture resolves it without degradation.
Authors: We agree this is a substantive omission. The current manuscript provides only the high-level claim without supporting numbers or comparisons. In the revised version we will (1) replace the abstract claim with concrete metrics and baseline comparisons, (2) add a complete Experiments section reporting results on VBench and VideoMME, (3) include ablations isolating the contribution of the shared vocabulary and the AR-diffusion hybrid, and (4) document the evaluation protocols so that the absence of task degradation can be assessed. revision: yes
Circularity Check
No significant circularity detected
full rationale
The abstract and available description present a high-level architectural proposal (shared vocabulary + hybrid AR-diffusion) and benchmark claims without any equations, parameter-fitting steps, self-citations, or derivation chains. No load-bearing step reduces a claimed prediction or result to its own inputs by construction. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
com / research / introducing-gen-3-alpha, 2024
Introducing gen-3 alpha: A new frontier for video gen- eration.https : / / runwayml . com / research / introducing-gen-3-alpha, 2024. 6
2024
-
[2]
Cosmos World Foundation Model Platform for Physical AI
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foun- dation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2. 5-vl technical report.arXiv preprint arXiv:2502.13923, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Sequential modeling enables scalable learn- ing for large vision models
Yutong Bai, Xinyang Geng, Karttikeya Mangalam, Amir Bar, Alan L Yuille, Trevor Darrell, Jitendra Malik, and Alexei A Efros. Sequential modeling enables scalable learn- ing for large vision models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22861–22872, 2024. 1
2024
-
[5]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 2, 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Diffusion forcing: Next-token prediction meets full-sequence diffu- sion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024
Boyuan Chen, Diego Mart ´ı Mons´o, Yilun Du, Max Sim- chowitz, Russ Tedrake, and Vincent Sitzmann. Diffusion forcing: Next-token prediction meets full-sequence diffu- sion.Advances in Neural Information Processing Systems, 37:24081–24125, 2024. 4
2024
-
[7]
Junying Chen, Zhenyang Cai, Pengcheng Chen, Shunian Chen, Ke Ji, Xidong Wang, Yunjin Yang, and Benyou Wang. Sharegpt-4o-image: Aligning multimodal mod- els with gpt-4o-level image generation.arXiv preprint arXiv:2506.18095, 2025. 6
-
[8]
BLIP3-o: A Family of Fully Open Unified Multimodal Models-Architecture, Training and Dataset
Jiuhai Chen, Zhiyang Xu, Xichen Pan, Yushi Hu, Can Qin, Tom Goldstein, Lifu Huang, Tianyi Zhou, Saining Xie, Sil- vio Savarese, et al. Blip3-o: A family of fully open unified multimodal models-architecture, training and dataset.arXiv preprint arXiv:2505.09568, 2025. 1, 3, 5, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Blip3o-next: Next frontier of native image generation.arXiv preprint arXiv:2510.15857, 2025
Jiuhai Chen, Le Xue, Zhiyang Xu, Xichen Pan, Shusheng Yang, Can Qin, An Yan, Honglu Zhou, Zeyuan Chen, Lifu Huang, et al. Blip3o-next: Next frontier of native image generation.arXiv preprint arXiv:2510.15857, 2025
-
[10]
Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling
Xiaokang Chen, Zhiyu Wu, Xingchao Liu, Zizheng Pan, Wen Liu, Zhenda Xie, Xingkai Yu, and Chong Ruan. Janus- pro: Unified multimodal understanding and generation with data and model scaling.arXiv preprint arXiv:2501.17811,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial- temporal modeling and audio understanding in video-llms. arXiv preprint arXiv:2406.07476, 2024. 2, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Emerging Properties in Unified Multimodal Pretraining
Chaorui Deng, Deyao Zhu, Kunchang Li, Chenhui Gou, Feng Li, Zeyu Wang, Shu Zhong, Weihao Yu, Xiaonan Nie, Ziang Song, et al. Emerging properties in unified multimodal pretraining.arXiv preprint arXiv:2505.14683, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Autoregressive Video Generation without Vector Quantization
Haoge Deng, Ting Pan, Haiwen Diao, Zhengxiong Luo, Yufeng Cui, Huchuan Lu, Shiguang Shan, Yonggang Qi, and Xinlong Wang. Autoregressive video generation with- out vector quantization.arXiv preprint arXiv:2412.14169,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Dreamllm: Synergistic multimodal comprehension and creation.arXiv preprint arXiv:2309.11499, 2023
Runpei Dong, Chunrui Han, Yuang Peng, Zekun Qi, Zheng Ge, Jinrong Yang, Liang Zhao, Jianjian Sun, Hongyu Zhou, Haoran Wei, et al. Dreamllm: Synergistic multimodal com- prehension and creation.arXiv preprint arXiv:2309.11499,
-
[15]
Taming transformers for high-resolution image synthesis
Patrick Esser, Robin Rombach, and Bjorn Ommer. Taming transformers for high-resolution image synthesis. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 12873–12883, 2021. 3
2021
-
[16]
Slowfast networks for video recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, and Kaiming He. Slowfast networks for video recognition. In Proceedings of the IEEE/CVF international conference on computer vision, pages 6202–6211, 2019. 2
2019
-
[17]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 24108–24118, 2025. 6
2025
-
[18]
SEED-X: Multimodal Models with Unified Multi-granularity Comprehension and Generation
Yuying Ge, Sijie Zhao, Jinguo Zhu, Yixiao Ge, Kun Yi, Lin Song, Chen Li, Xiaohan Ding, and Ying Shan. Seed-x: Mul- timodal models with unified multi-granularity comprehen- sion and generation.arXiv preprint arXiv:2404.14396, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[19]
arXiv preprint arXiv:2507.22058 (2025)
Zigang Geng, Yibing Wang, Yeyao Ma, Chen Li, Yongming Rao, Shuyang Gu, Zhao Zhong, Qinglin Lu, Han Hu, Xi- aosong Zhang, et al. X-omni: Reinforcement learning makes discrete autoregressive image generative models great again. arXiv preprint arXiv:2507.22058, 2025. 1
-
[20]
arXiv preprint arXiv:2410.18558 , year=
Shuhao Gu, Jialing Zhang, Siyuan Zhou, Kevin Yu, Zhaohu Xing, Liangdong Wang, Zhou Cao, Jintao Jia, Zhuoyi Zhang, Yixuan Wang, et al. Infinity-mm: Scaling multimodal per- formance with large-scale and high-quality instruction data. arXiv preprint arXiv:2410.18558, 2024. 5
-
[21]
Are video models ready as zero-shot reasoners? an empirical study with the mme-cof benchmark
Ziyu Guo, Xinyan Chen, Renrui Zhang, Ruichuan An, Yu Qi, Dongzhi Jiang, Xiangtai Li, Manyuan Zhang, Hongsheng Li, and Pheng-Ann Heng. Are video models ready as zero-shot reasoners? an empirical study with the mme-cof benchmark. arXiv preprint arXiv:2510.26802, 2025. 1
-
[22]
LTX-Video: Realtime Video Latent Diffusion
Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, et al. Ltx-video: Realtime video latent diffusion.arXiv preprint arXiv:2501.00103,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Jiaming Han, Hao Chen, Yang Zhao, Hanyu Wang, Qi Zhao, Ziyan Yang, Hao He, Xiangyu Yue, and Lu Jiang. Vi- sion as a dialect: Unifying visual understanding and gen- eration via text-aligned representations.arXiv preprint arXiv:2506.18898, 2025. 3, 6 9
-
[24]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Doll´ar, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000– 16009, 2022. 5
2022
-
[25]
Vbench: Comprehensive bench- mark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive bench- mark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 21807–21818, 2024. 6
2024
-
[26]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, et al. Vbench++: Comprehensive and ver- satile benchmark suite for video generative models.arXiv preprint arXiv:2411.13503, 2024. 6
-
[27]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perel- man, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Weli- hinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card. arXiv preprint arXiv:2410.21276, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Pyramidal flow matching for efficient video generative modeling,
Yang Jin, Zhicheng Sun, Ningyuan Li, Kun Xu, Hao Jiang, Nan Zhuang, Quzhe Huang, Yang Song, Yadong Mu, and Zhouchen Lin. Pyramidal flow matching for efficient video generative modeling.arXiv preprint arXiv:2410.05954,
-
[29]
VideoPoet: A Large Language Model for Zero-Shot Video Generation
Dan Kondratyuk, Lijun Yu, Xiuye Gu, Jos ´e Lezama, Jonathan Huang, Grant Schindler, Rachel Hornung, Vigh- nesh Birodkar, Jimmy Yan, Ming-Chang Chiu, et al. Videopoet: A large language model for zero-shot video gen- eration.arXiv preprint arXiv:2312.14125, 2023. 3
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
LLaVA-OneVision: Easy Visual Task Transfer
Bo Li, Yuanhan Zhang, Dong Guo, Renrui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Zi- wei Liu, et al. Llava-onevision: Easy visual task transfer. arXiv preprint arXiv:2408.03326, 2024. 5, 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
Autoregressive image generation without vec- tor quantization.Advances in Neural Information Processing Systems, 37:56424–56445, 2024
Tianhong Li, Yonglong Tian, He Li, Mingyang Deng, and Kaiming He. Autoregressive image generation without vec- tor quantization.Advances in Neural Information Processing Systems, 37:56424–56445, 2024. 3
2024
-
[33]
Densefusion-1m: Merg- ing vision experts for comprehensive multimodal percep- tion.Advances in Neural Information Processing Systems, 37:18535–18556, 2024
Xiaotong Li, Fan Zhang, Haiwen Diao, Yueze Wang, Xin- long Wang, and Lingyu Duan. Densefusion-1m: Merg- ing vision experts for comprehensive multimodal percep- tion.Advances in Neural Information Processing Systems, 37:18535–18556, 2024. 5
2024
-
[34]
Mogao: An Omni Foundation Model for Interleaved Multi-Modal Generation
Chao Liao, Liyang Liu, Xun Wang, Zhengxiong Luo, Xinyu Zhang, Wenliang Zhao, Jie Wu, Liang Li, Zhi Tian, and Weilin Huang. Mogao: An omni foundation model for interleaved multi-modal generation.arXiv preprint arXiv:2505.05472, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
Open-Sora Plan: Open-Source Large Video Generation Model
Bin Lin, Yunyang Ge, Xinhua Cheng, Zongjian Li, Bin Zhu, Shaodong Wang, Xianyi He, Yang Ye, Shenghai Yuan, Li- uhan Chen, et al. Open-sora plan: Open-source large video generation model.arXiv preprint arXiv:2412.00131, 2024. 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
UniWorld-V1: High-Resolution Semantic Encoders for Unified Visual Understanding and Generation
Bin Lin, Zongjian Li, Xinhua Cheng, Yuwei Niu, Yang Ye, Xianyi He, Shenghai Yuan, Wangbo Yu, Shaodong Wang, Yunyang Ge, et al. Uniworld: High-resolution semantic en- coders for unified visual understanding and generation.arXiv preprint arXiv:2506.03147, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Univid: The open-source unified video model.arXiv preprint arXiv:2509.24200, 2025
Jiabin Luo, Junhui Lin, Zeyu Zhang, Biao Wu, Meng Fang, Ling Chen, and Hao Tang. Univid: The open-source unified video model.arXiv preprint arXiv:2509.24200, 2025. 2, 3
-
[38]
Step-Video-T2V Technical Report: The Practice, Challenges, and Future of Video Foundation Model
Guoqing Ma, Haoyang Huang, Kun Yan, Liangyu Chen, Nan Duan, Shengming Yin, Changyi Wan, Ranchen Ming, Xi- aoniu Song, Xing Chen, et al. Step-video-t2v technical re- port: The practice, challenges, and future of video founda- tion model.arXiv preprint arXiv:2502.10248, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Janusflow: Harmonizing autore- gression and rectified flow for unified multimodal under- standing and generation
Yiyang Ma, Xingchao Liu, Xiaokang Chen, Wen Liu, Chengyue Wu, Zhiyu Wu, Zizheng Pan, Zhenda Xie, Haowei Zhang, Xingkai Yu, et al. Janusflow: Harmonizing autore- gression and rectified flow for unified multimodal under- standing and generation. InProceedings of the Computer Vi- sion and Pattern Recognition Conference, pages 7739–7751,
-
[40]
Egoschema: A diagnostic benchmark for very long- form video language understanding.Advances in Neural In- formation Processing Systems, 36:46212–46244, 2023
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long- form video language understanding.Advances in Neural In- formation Processing Systems, 36:46212–46244, 2023. 6
2023
-
[41]
OpenVid-1M: A Large-Scale High-Quality Dataset for Text-to-video Generation
Kepan Nan, Rui Xie, Penghao Zhou, Tiehan Fan, Zhen- heng Yang, Zhijie Chen, Xiang Li, Jian Yang, and Ying Tai. Openvid-1m: A large-scale high-quality dataset for text-to- video generation.arXiv preprint arXiv:2407.02371, 2024. 5
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Gpt-4v system card.https://openai.com/ index/gpt-4v-system-card/, 2023
OpenAI. Gpt-4v system card.https://openai.com/ index/gpt-4v-system-card/, 2023. 7
2023
-
[43]
Transfer between Modalities with MetaQueries
Xichen Pan, Satya Narayan Shukla, Aashu Singh, Zhuokai Zhao, Shlok Kumar Mishra, Jialiang Wang, Zhiyang Xu, Jiuhai Chen, Kunpeng Li, Felix Juefei-Xu, et al. Trans- fer between modalities with metaqueries.arXiv preprint arXiv:2504.06256, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020
Colin Raffel, Noam Shazeer, Adam Roberts, Katherine Lee, Sharan Narang, Michael Matena, Yanqi Zhou, Wei Li, and Peter J Liu. Exploring the limits of transfer learning with a unified text-to-text transformer.Journal of machine learning research, 21(140):1–67, 2020. 2
2020
-
[45]
Scaling properties of diffusion models for perceptual tasks
Rahul Ravishankar, Zeeshan Patel, Jathushan Rajasegaran, and Jitendra Malik. Scaling properties of diffusion models for perceptual tasks. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 12945–12954,
-
[46]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 3
2022
-
[47]
Pathways on the image manifold: Image editing via video generation
Noam Rotstein, Gal Yona, Daniel Silver, Roy Velich, David Bensaid, and Ron Kimmel. Pathways on the image manifold: Image editing via video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7857–7866, 2025. 2
2025
-
[48]
Journeydb: A benchmark for generative im- age understanding.Advances in neural information process- ing systems, 36:49659–49678, 2023
Keqiang Sun, Junting Pan, Yuying Ge, Hao Li, Haodong Duan, Xiaoshi Wu, Renrui Zhang, Aojun Zhou, Zipeng Qin, 10 Yi Wang, et al. Journeydb: A benchmark for generative im- age understanding.Advances in neural information process- ing systems, 36:49659–49678, 2023. 5
2023
-
[49]
Generative multimodal mod- els are in-context learners
Quan Sun, Yufeng Cui, Xiaosong Zhang, Fan Zhang, Qiy- ing Yu, Yueze Wang, Yongming Rao, Jingjing Liu, Tiejun Huang, and Xinlong Wang. Generative multimodal mod- els are in-context learners. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14398–14409, 2024. 3
2024
-
[50]
Unified multimodal discrete diffusion
Alexander Swerdlow, Mihir Prabhudesai, Siddharth Gandhi, Deepak Pathak, and Katerina Fragkiadaki. Unified multi- modal discrete diffusion.arXiv preprint arXiv:2503.20853,
-
[51]
Zhiyu Tan, Hao Yang, Luozheng Qin, Jia Gong, Meng- ping Yang, and Hao Li. Omni-video: Democratizing uni- fied video understanding and generation.arXiv preprint arXiv:2507.06119, 2025. 3
-
[52]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon Team. Chameleon: Mixed-modal early-fusion foundation models.arXiv preprint arXiv:2405.09818, 2024. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[53]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Petko Georgiev, Ving Ian Lei, Ryan Burnell, Libin Bai, Anmol Gulati, Garrett Tanzer, Damien Vincent, Zhufeng Pan, Shibo Wang, et al. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of con- text.arXiv preprint arXiv:2403.05530, 2024. 7
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Kling 1.6, 2024
Kuaishou Technology. Kling 1.6, 2024. 2, 6
2024
-
[55]
Thinking with Video: Video Generation as a Promising Multimodal Reasoning Paradigm
Jingqi Tong, Yurong Mou, Hangcheng Li, Mingzhe Li, Yongzhuo Yang, Ming Zhang, Qiguang Chen, Tianyi Liang, Xiaomeng Hu, Yining Zheng, et al. Thinking with video: Video generation as a promising multimodal reasoning paradigm.arXiv preprint arXiv:2511.04570, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muham- mad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, et al. Siglip 2: Multilingual vision-language en- coders with improved semantic understanding, localization, and dense features.arXiv preprint arXiv:2502.14786, 2025. 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[57]
Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017
Aaron Van Den Oord, Oriol Vinyals, et al. Neural discrete representation learning.Advances in neural information pro- cessing systems, 30, 2017. 3, 4
2017
-
[58]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video gen- erative models.arXiv preprint arXiv:2503.20314, 2025. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[59]
Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content
Qiuheng Wang, Yukai Shi, Jiarong Ou, Rui Chen, Ke Lin, Jiahao Wang, Boyuan Jiang, Haotian Yang, Mingwu Zheng, Xin Tao, et al. Koala-36m: A large-scale video dataset improving consistency between fine-grained conditions and video content. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 8428–8437, 2025. 5
2025
-
[60]
Images speak in images: A generalist painter for in-context visual learning
Xinlong Wang, Wen Wang, Yue Cao, Chunhua Shen, and Tiejun Huang. Images speak in images: A generalist painter for in-context visual learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6830–6839, 2023. 1
2023
-
[61]
Emu3: Next-Token Prediction is All You Need
Xinlong Wang, Xiaosong Zhang, Zhengxiong Luo, Quan Sun, Yufeng Cui, Jinsheng Wang, Fan Zhang, Yueze Wang, Zhen Li, Qiying Yu, et al. Emu3: Next-token prediction is all you need.arXiv preprint arXiv:2409.18869, 2024. 1, 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Yuqing Wang, Tianwei Xiong, Daquan Zhou, Zhijie Lin, Yang Zhao, Bingyi Kang, Jiashi Feng, and Xihui Liu. Loong: Generating minute-level long videos with autoregressive lan- guage models.arXiv preprint arXiv:2410.02757, 2024. 3
-
[63]
InternVideo2.5: Empowering Video MLLMs with Long and Rich Context Modeling
Yi Wang, Xinhao Li, Ziang Yan, Yinan He, Jiashuo Yu, Xi- angyu Zeng, Chenting Wang, Changlian Ma, Haian Huang, Jianfei Gao, et al. Internvideo2. 5: Empowering video mllms with long and rich context modeling.arXiv preprint arXiv:2501.12386, 2025. 2
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[64]
Cong Wei, Quande Liu, Zixuan Ye, Qiulin Wang, Xintao Wang, Pengfei Wan, Kun Gai, and Wenhu Chen. Univideo: Unified understanding, generation, and editing for videos. arXiv preprint arXiv:2510.08377, 2025. 2, 3
-
[65]
Video models are zero-shot learners and reasoners
Thadd ¨aus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learn- ers and reasoners.arXiv preprint arXiv:2509.20328, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[66]
FineVision: Open Data Is All You Need
Luis Wiedmann, Orr Zohar, Amir Mahla, Xiaohan Wang, Rui Li, Thibaud Frere, Leandro von Werra, Aritra Roy Gosthipaty, and Andr ´es Marafioti. Finevision: Open data is all you need.arXiv preprint arXiv:2510.17269, 2025. 5
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[67]
OmniGen2: Towards Instruction-Aligned Multimodal Generation
Chenyuan Wu, Pengfei Zheng, Ruiran Yan, Shitao Xiao, Xin Luo, Yueze Wang, Wanli Li, Xiyan Jiang, Yexin Liu, Junjie Zhou, et al. Omnigen2: Exploration to advanced multimodal generation.arXiv preprint arXiv:2506.18871, 2025. 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[68]
Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2024
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding.Advances in Neural Informa- tion Processing Systems, 37:28828–28857, 2024. 6
2024
-
[69]
VILA-U: a Unified Foundation Model Integrating Visual Understanding and Generation
Yecheng Wu, Zhuoyang Zhang, Junyu Chen, Haotian Tang, Dacheng Li, Yunhao Fang, Ligeng Zhu, Enze Xie, Hongxu Yin, Li Yi, et al. Vila-u: a unified foundation model inte- grating visual understanding and generation.arXiv preprint arXiv:2409.04429, 2024. 1, 2, 3, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[70]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF con- ference on computer vision and pattern recognition, pages 9777–9786, 2021. 6
2021
-
[71]
Yicheng Xiao, Lin Song, Rui Yang, Cheng Cheng, Zun- nan Xu, Zhaoyang Zhang, Yixiao Ge, Xiu Li, and Ying Shan. Haploomni: Unified single transformer for multi- modal video understanding and generation.arXiv preprint arXiv:2506.02975, 2025. 6, 7
-
[72]
Show-o: One Single Transformer to Unify Multimodal Understanding and Generation
Jinheng Xie, Weijia Mao, Zechen Bai, David Junhao Zhang, Weihao Wang, Kevin Qinghong Lin, Yuchao Gu, Zhijie Chen, Zhenheng Yang, and Mike Zheng Shou. Show-o: One single transformer to unify multimodal understanding and generation.arXiv preprint arXiv:2408.12528, 2024. 3
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[73]
Show-o2: Improved Native Unified Multimodal Models
Jinheng Xie, Zhenheng Yang, and Mike Zheng Shou. Show- o2: Improved native unified multimodal models.arXiv preprint arXiv:2506.15564, 2025. 1, 3, 6, 7 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[74]
Muse- vl: Modeling unified vlm through semantic discrete encod- ing
Rongchang Xie, Chen Du, Ping Song, and Chang Liu. Muse- vl: Modeling unified vlm through semantic discrete encod- ing. InProceedings of the IEEE/CVF International Confer- ence on Computer Vision, pages 24135–24146, 2025. 3
2025
-
[75]
Shenghao Xie, Wenqiang Zu, Mingyang Zhao, Duo Su, Shi- long Liu, Ruohua Shi, Guoqi Li, Shanghang Zhang, and Lei Ma. Towards unifying understanding and generation in the era of vision foundation models: A survey from the au- toregression perspective.arXiv preprint arXiv:2410.22217,
-
[76]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025. 6
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[77]
MMaDA: Multimodal Large Diffusion Language Models
Ling Yang, Ye Tian, Bowen Li, Xinchen Zhang, Ke Shen, Yunhai Tong, and Mengdi Wang. Mmada: Mul- timodal large diffusion language models.arXiv preprint arXiv:2505.15809, 2025. 1, 3
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[78]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiao- han Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024. 2, 6
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[79]
Junyan Ye, Dongzhi Jiang, Zihao Wang, Leqi Zhu, Zheng- hao Hu, Zilong Huang, Jun He, Zhiyuan Yan, Jinghua Yu, Hongsheng Li, et al. Echo-4o: Harnessing the power of gpt- 4o synthetic images for improved image generation.arXiv preprint arXiv:2508.09987, 2025. 6
-
[80]
From slow bidirectional to fast autoregressive video diffusion mod- els
Tianwei Yin, Qiang Zhang, Richard Zhang, William T Free- man, Fredo Durand, Eli Shechtman, and Xun Huang. From slow bidirectional to fast autoregressive video diffusion mod- els. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22963–22974, 2025. 6
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.