Bounding Boxes as Goals: Language-Conditioned Grasping via Neuro-Symbolic Planning
Pith reviewed 2026-06-27 06:45 UTC · model grok-4.3
The pith
GRASP maps natural-language queries to bounding-box goals for robot grasping without task-specific training
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
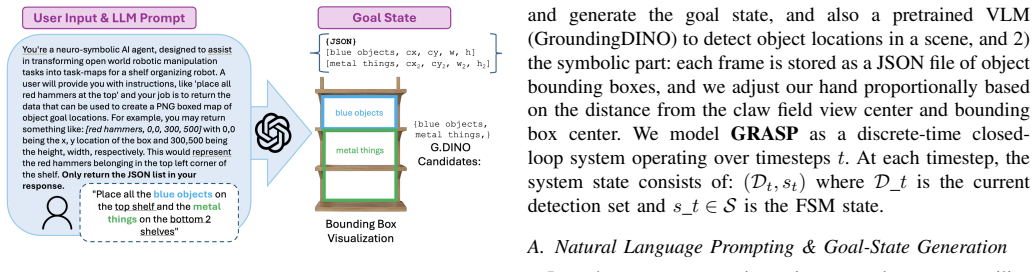
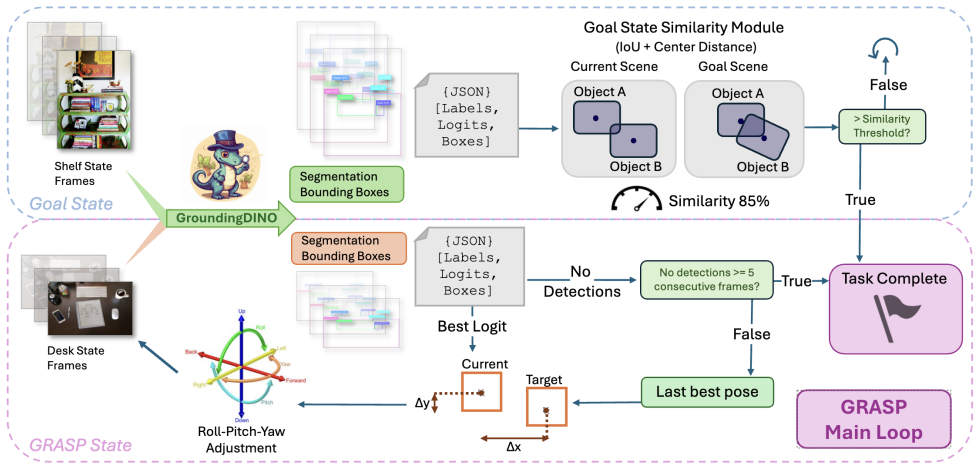
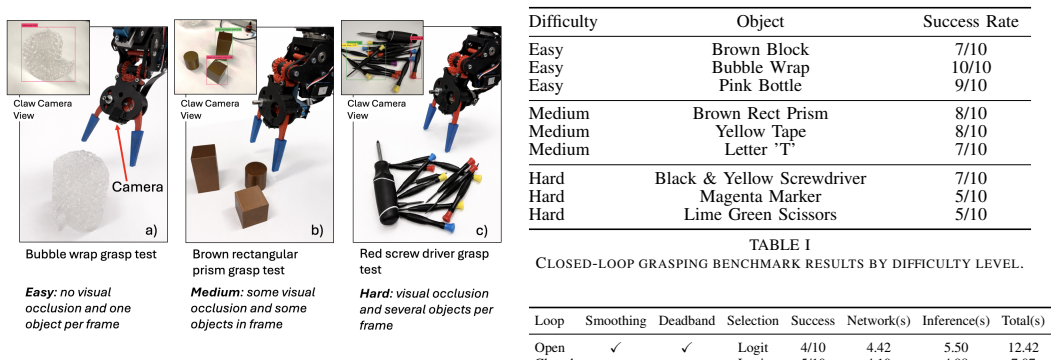
GRASP translates natural-language queries into bounding-box goal states via a pretrained VLM, grounds them physically through detection, and executes them with neuro-symbolic planning, achieving 73.3 percent success across 90 real-robot trials at three difficulty levels with no task-specific training.
What carries the argument
The bounding-box detection pipeline that converts VLM language outputs into grounded physical goal states for symbolic planning
If this is right
- Robots interpret abstract spatial concepts such as top shelf without task-specific engineering.
- The system generalizes zero-shot to new objects and instructions.
- Planning stays lightweight compared with end-to-end trained models that require large demonstration sets.
Where Pith is reading between the lines
- Extending the pipeline to mobile bases or 3D scenes would test whether bounding-box goals remain sufficient outside tabletop settings.
- Swapping the VLM or detection model could quantify robustness without retraining the planner.
- Sequencing multiple language commands would require adding temporal logic on top of the current single-goal mechanism.
Load-bearing premise
A pretrained VLM can reliably translate natural-language queries into accurate bounding-box goal states that align with objects detected in the physical world.
What would settle it
Trials in which ambiguous language or detection failures produce incorrect bounding boxes and drive the overall success rate well below 73 percent.
Figures

read the original abstract
For robotics to be effectively integrated into household or industrial environments, machines must adapt to natural-language prompts in real time. Although Vision-Language Models (VLMs) have enabled zero-shot generalization in robot task and motion planning (TAMP), current state-of-the-art approaches often remain computationally "heavyweight" or require extensive training on thousands of demonstrations. We present GRASP (Grounded Reasoning and Symbolic Planning), a framework designed as a step toward open-vocabulary tabletop manipulation. Our approach leverages a pretrained VLM to translate natural-language queries into neuro-symbolic goal states, grounded in the physical world via a bounding-box detection pipeline. Unlike methods that rely on fixed color lists or hard-coded coordinates, GRASP enables robots to interpret abstract spatial concepts such as "top shelf" and execute tasks without additional fine-tuning. We achieve 73.3% overall success across 90 real-robot trials at three difficulty levels, requiring no task-specific training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the GRASP framework for language-conditioned tabletop grasping. A pretrained VLM translates natural-language queries into bounding-box goal states that are grounded via a detection pipeline; these goals then drive a neuro-symbolic planner. The central empirical claim is a 73.3% success rate across 90 real-robot trials spanning three difficulty levels, achieved with no task-specific training or fine-tuning.
Significance. If the experimental results can be substantiated, the work would be significant for open-vocabulary robotic manipulation. It offers a lightweight alternative to end-to-end learned policies by combining VLMs with symbolic planning to handle abstract spatial language without large demonstration datasets or fixed vocabularies.
major comments (2)
- [Abstract] Abstract: The reported 73.3% success rate over 90 trials is stated without any description of the experimental protocol, choice of baselines, error bars, statistical tests, or failure-mode breakdown. This information is required to evaluate the central claim of reliable zero-shot performance.
- [Abstract] Abstract: The assertion that the system requires 'no task-specific training' rests on the unexamined assumption that a pretrained VLM produces accurate, physically grounded bounding-box goals; no quantitative validation, ablation, or error analysis of the VLM-to-bounding-box step is supplied to support this load-bearing premise.
minor comments (1)
- [Abstract] Abstract: The expansion of the acronym GRASP is not given, which reduces immediate readability.
Simulated Author's Rebuttal
We thank the referee for the detailed feedback on the abstract. We address each major comment below, clarifying what is already in the full manuscript and indicating where revisions will strengthen the presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 73.3% success rate over 90 trials is stated without any description of the experimental protocol, choice of baselines, error bars, statistical tests, or failure-mode breakdown. This information is required to evaluate the central claim of reliable zero-shot performance.
Authors: The abstract is intentionally concise. The full manuscript details the experimental protocol (90 trials across three difficulty levels), failure-mode breakdown, and success rates in the Experiments section. No baselines are included because the work presents a zero-shot framework rather than a comparative study; no error bars or statistical tests are reported as the evaluation is a feasibility demonstration on a real robot. We will revise the abstract to briefly reference the evaluation setup and note the zero-shot nature of the approach. revision: yes
-
Referee: [Abstract] Abstract: The assertion that the system requires 'no task-specific training' rests on the unexamined assumption that a pretrained VLM produces accurate, physically grounded bounding-box goals; no quantitative validation, ablation, or error analysis of the VLM-to-bounding-box step is supplied to support this load-bearing premise.
Authors: The 'no task-specific training' claim means the VLM and neuro-symbolic planner are used off-the-shelf without fine-tuning on robot demonstrations or task data. The bounding-box grounding occurs via a separate detection pipeline. While the manuscript does not contain an isolated quantitative ablation of VLM bounding-box accuracy, the end-to-end real-robot success rate provides supporting evidence for the overall pipeline. We will add a short discussion of VLM error modes and their contribution to failures in the revised version. revision: partial
Circularity Check
No significant circularity; empirical result stands alone
full rationale
The paper presents an empirical robotics framework (GRASP) that maps language queries to bounding-box goals via a pretrained VLM and then executes via neuro-symbolic planning. The central claim is a measured 73.3% success rate over 90 real-robot trials with no task-specific training. No equations, fitted parameters, or derived quantities appear in the provided text; the success rate is reported as a direct experimental outcome rather than a prediction or theorem. No self-citation chains, uniqueness theorems, or ansatzes are invoked to justify any derivation. The pipeline is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained VLMs generalize to abstract spatial concepts such as 'top shelf' without fine-tuning on robot data.
invented entities (1)
-
GRASP framework
no independent evidence
Reference graph
Works this paper leans on
- [1]
-
[2]
C. Cui, C. Zhu, C. Oh, and A. Cavallaro. Improving generalization of language-conditioned robot manipulation. In2025 IEEE/RSJ Interna- tional Conference on Intelligent Robots and Systems (IROS), pp. 13178– 13184. IEEE, 2025
2025
-
[3]
M. U. Din, W. Akram, L. S. Saoud, J. Rosell, and I. Hussain. Vision language action models in robotic manipulation: A systematic review. arXiv preprint arXiv:2507.10672, 2025
arXiv 2025
-
[4]
R. Gong, X. Gao, Q. Gao, S. Shakiah, G. Thattai, and G. S. Sukhatme. Lemma: Learning language-conditioned multi-robot manipulation.IEEE Robotics and Automation Letters, 8(10):6835–6842, 2023. doi: 10.1109/ LRA.2023.3313058
arXiv 2023
-
[5]
H. Guo, F. Wu, Y . Qin, R. Li, K. Li, and K. Li. Recent trends in task and motion planning for robotics: A survey.ACM Computing Surveys, 55(13s):1–36, 2023
2023
- [6]
-
[7]
Huang, X
H. Huang, X. Chen, Y . Chen, H. Li, X. Han, Z. Wang, T. Wang, J. Pang, and Z. Zhao. Roboground: Robotic manipulation with grounded vision- language priors. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 22540–22550, 2025
2025
- [8]
-
[9]
Huang, C
W. Huang, C. Wang, R. Zhang, Y . Li, J. Wu, and L. Fei-Fei. V oxposer: Composable 3d value maps for robotic manipulation with language models, 2023
2023
-
[10]
M. Jia, H. Huang, Z. Zhang, C. Wang, L. Zhao, D. Wang, J. X. Liu, R. Walters, R. Platt, and S. Tellex. Learning efficient and robust language-conditioned manipulation using textual-visual relevancy and equivariant language mapping, 2025
2025
-
[11]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation. arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[12]
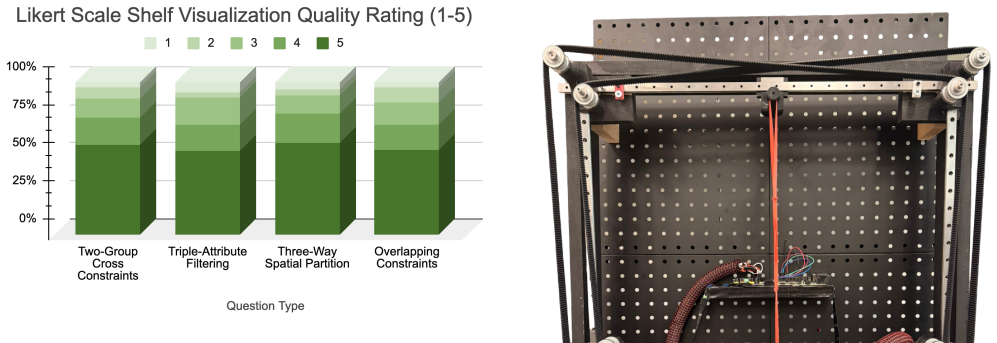
R. Likert. A technique for the measurement of attitudes.Archives of psychology, 1932
1932
-
[13]
J. Liu, M. Liu, Z. Wang, P. An, X. Li, K. Zhou, S. Yang, R. Zhang, Y . Guo, and S. Zhang. Robomamba: Efficient vision-language-action model for robotic reasoning and manipulation.Advances in Neural Information Processing Systems, 37:40085–40110, 2024
2024
-
[14]
S. Liu, Z. Zeng, T. Ren, F. Li, H. Zhang, J. Yang, Q. Jiang, C. Li, J. Yang, H. Su, J. Zhu, and L. Zhang. Grounding dino: Marrying dino with grounded pre-training for open-set object detection, 2024
2024
-
[15]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language-conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022. doi: 10.1109/LRA.2022.3180108
-
[16]
A. Ray, J. Arkin, H. Biggie, C. Fan, L. Carlone, and N. Roy. Structured interfaces for automated reasoning with 3d scene graphs.arXiv preprint arXiv:2510.16643, 2025
arXiv 2025
-
[17]
R. Shao, W. Li, L. Zhang, R. Zhang, Z. Liu, R. Chen, and L. Nie. Large vlm-based vision-language-action models for robotic manipulation: A survey.arXiv preprint arXiv:2508.13073, 2025
Pith/arXiv arXiv 2025
-
[18]
A. Singh, A. Fry, A. Perelman, A. Tart, A. Ganesh, A. El-Kishky, A. McLaughlin, A. Low, A. Ostrow, A. Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
Pith/arXiv arXiv 2025
- [19]
-
[20]
S. Tan, D. Zhou, X. Shao, J. Wang, and G. Sun. Language-conditioned open-vocabulary mobile manipulation with pretrained models.arXiv preprint arXiv:2507.17379, 2025
arXiv 2025
-
[21]
H. Wang, F. Shahriar, A. Azimi, G. Vasan, R. Mahmood, and C. Bellinger. Versatile and generalizable manipulation via goal- conditioned reinforcement learning with grounded object detection. arXiv preprint arXiv:2507.10814, 2025
arXiv 2025
-
[22]
S. Wang, D. Kim, A. Taalimi, C. Sun, and W. Kuo. Learning visual grounding from generative vision and language model. In 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pp. 8057–8067, 2025. doi: 10.1109/W ACV61041.2025.00782
work page doi:10.1109/w 2025
-
[23]
W. Yan, Q. Yang, S. Huang, Y . Wang, S. Punwani, M. Emberton, V . Stavrinides, Y . Hu, and D. Barratt. Tell2reg: Establishing spatial correspondence between images by the same language prompts, 2025
2025
-
[24]
X.-W. Yang, J.-J. Shao, L.-Z. Guo, B.-W. Zhang, Z. Zhou, L.-H. Jia, W.-Z. Dai, and Y .-F. Li. Neuro-symbolic artificial intelligence: Towards improving the reasoning abilities of large language models.arXiv preprint arXiv:2508.13678, 2025
arXiv 2025
-
[25]
F. Zeng, W. Gan, Y . Wang, N. Liu, and P. S. Yu. Large language models for robotics: A survey.arXiv preprint arXiv:2311.07226, 2023
arXiv 2023
- [26]
-
[27]
Zhang, Z
S. Zhang, Z. Xu, P. Liu, X. Yu, Y . Li, Q. Gao, Z. Fei, Z. Yin, Z. Wu, Y .-G. Jiang, et al. Vlabench: A large-scale benchmark for language- conditioned robotics manipulation with long-horizon reasoning tasks. InProceedings of the IEEE/CVF International Conference on Computer Vision, pp. 11142–11152, 2025
2025
-
[28]
Z. Zhao, S. Cheng, Y . Ding, Z. Zhou, S. Zhang, D. Xu, and Y . Zhao. A survey of optimization-based task and motion planning: From classical to learning approaches.IEEE/ASME Transactions on Mechatronics, 30(4):2799–2825, 2025. doi: 10.1109/TMECH.2024.3452509
-
[29]
M. Zhu, Y . Zhu, J. Li, J. Wen, Z. Xu, Z. Che, C. Shen, Y . Peng, D. Liu, F. Feng, and J. Tang. Language-conditioned robotic manipulation with fast and slow thinking. In2024 IEEE International Conference on Robotics and Automation (ICRA), pp. 4333–4339, 2024. doi: 10. 1109/ICRA57147.2024.10611525 APPENDIX A. Human Survey We evaluated our goal-state genera...
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.