Knowledge Distillation from Large Reasoning Models to Compact Student Models: A Case Study on the John O Bryan Mathematics Competition
Pith reviewed 2026-07-01 06:10 UTC · model grok-4.3
The pith
Fine-tuning a 7B model on chain-of-thought traces from a large reasoning model raises accuracy on math competition problems from 64.67% to 69.43%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
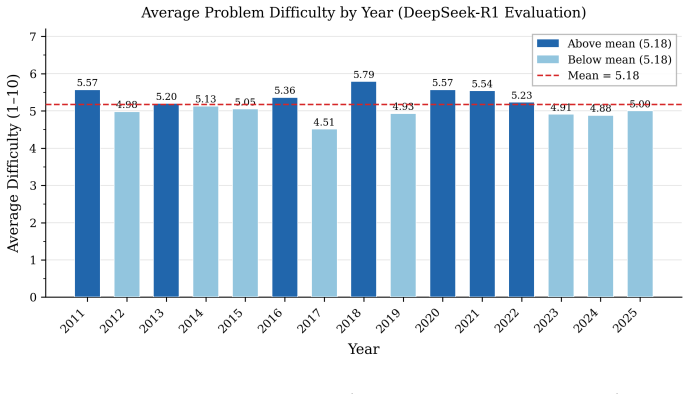
The central claim is that five independent 200-iteration LoRA runs on the CoT corpus yield a mean 69.43% accuracy (std 0.17%) on the competition problems versus the base model's 64.67%, with generalization to 73.1% (std 0.18%) on MATH-500, while accuracy declines monotonically across six response-length tiers from 69.43% at the longest tier to 41.9% at the shortest.
What carries the argument
The dual-agent framework that produces chain-of-thought training examples from the teacher model on competition problems, followed by LoRA adaptation limited to 200 iterations chosen from the validation-loss minimum observed in a preliminary 1,000-iteration run.
If this is right
- The reported accuracy gain remains consistent across five random seeds with standard deviation below 0.2 points.
- Performance gains transfer to the MATH-500 benchmark outside the original competition distribution.
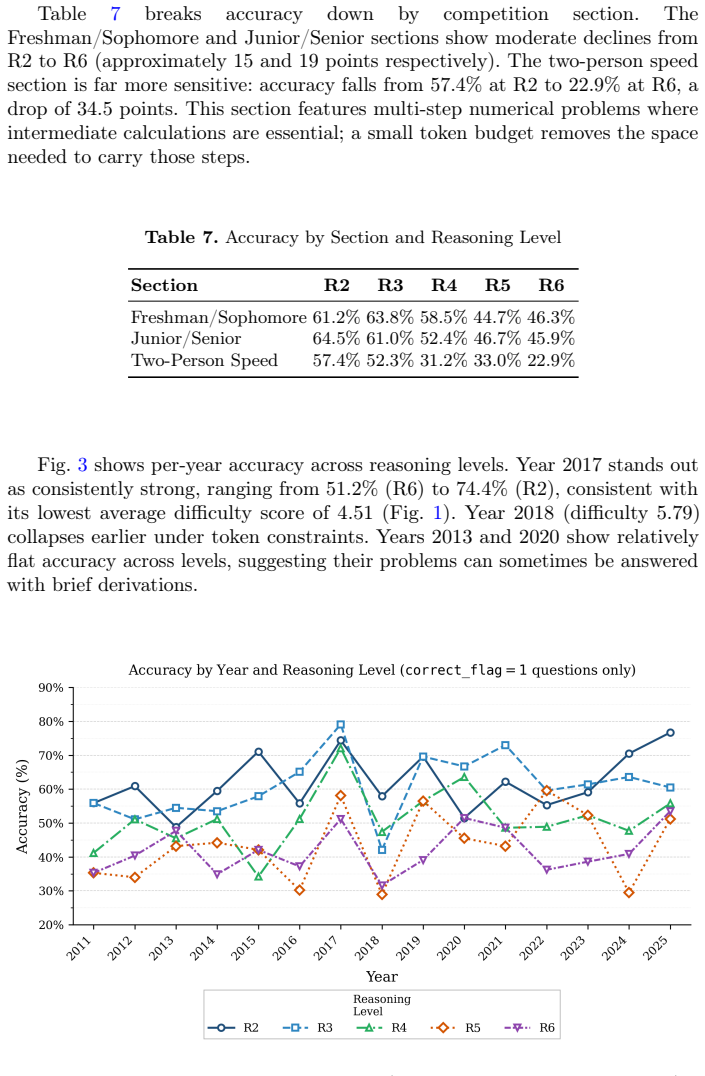
- Accuracy drops in a graded way as response length is reduced, with the speed section most sensitive.
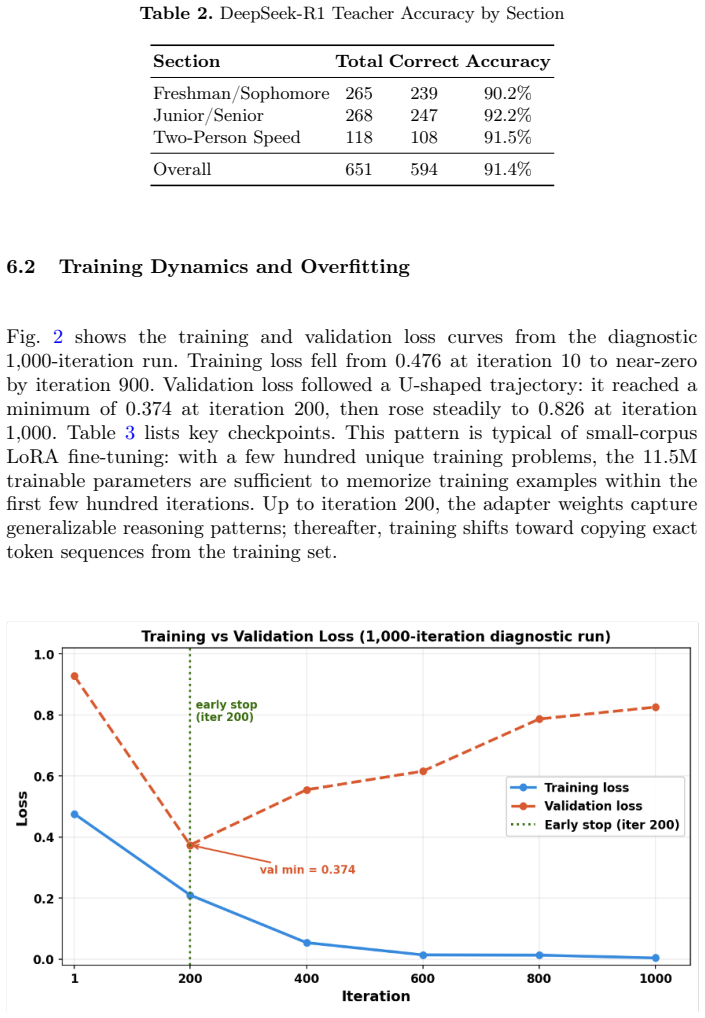
- Training beyond the 200-iteration point produces rising validation loss and overfitting on this corpus.
Where Pith is reading between the lines
- Response length may act as an independent control on reasoning reliability after distillation, independent of the specific competition problems.
- The same 200-iteration stopping heuristic could be tested on other teacher-student pairs or non-math reasoning tasks to check whether early stopping remains optimal.
- If shorter outputs systematically lose accuracy, future distillation pipelines might add explicit length or step-count objectives rather than relying on raw CoT traces alone.
Load-bearing premise
That stopping training at the iteration where validation loss reaches its minimum on a preliminary run yields stable gains rather than an artifact of that particular stopping rule on this dataset.
What would settle it
A new set of runs that continue past 200 iterations until validation loss stabilizes or rises further, then check whether the accuracy improvement over the base model shrinks below statistical significance or reverses.
Figures
read the original abstract
This paper investigates knowledge distillation from a large reasoning model (DeepSeek-R1) to a compact student model (Qwen2.5-7B). Using historical problems from the John O'Bryan Mathematics Competition at Northern Kentucky University (2011-2025), we build a Chain-of-Thought (CoT) training corpus through a dual-agent framework. The dataset is used to fine-tune the student model with Low-Rank Adaptation (LoRA) on Apple Silicon hardware using the MLX framework. The base Qwen2.5-7B model achieves 64.67% accuracy on competition problems, while the DeepSeek-R1 teacher achieves 91.40%. An initial 1,000-iteration training run revealed severe overfitting, with validation loss reaching a minimum at iteration 200 before rising steadily. Based on this finding, we ran five independent training runs each limited to 200 iterations with varied random seeds to assess result stability. Across these five runs, the fine-tuned student model achieves a mean accuracy of 69.43% (std dev 0.17%) on the competition dataset, a 4.76 percentage-point improvement over the base model, and generalizes to 73.1% (std dev 0.18%) on the MATH-500 benchmark. We further study how response length affects answer quality across six reasoning levels (R1-R6): accuracy declines consistently from 69.43% at R1 (mean 220 words) to 41.9% at R6 (mean 31.2 words), with the two-person speed section most sensitive to token reduction. These results demonstrate that CoT distillation improves compact student models and that response length is a critical factor in mathematical reasoning quality.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper investigates knowledge distillation of chain-of-thought reasoning from DeepSeek-R1 to Qwen2.5-7B via LoRA on John O'Bryan Mathematics Competition problems (2011-2025). After a preliminary 1,000-iteration run identified a validation-loss minimum at iteration 200, five independent 200-iteration runs yield a mean accuracy of 69.43% (std 0.17%) on the competition set (4.76 pp above the 64.67% base model), 73.1% (std 0.18%) on MATH-500, and a monotonic accuracy drop with shorter responses across six reasoning levels.
Significance. If the reported gains survive a properly isolated stopping rule, the work supplies concrete evidence that compact models can acquire improved mathematical reasoning via distillation from large reasoning models, with measurable generalization to MATH-500 and an explicit demonstration that response length modulates answer quality. The five-run protocol with reported standard deviations and the preliminary overfitting diagnosis are positive methodological features.
major comments (3)
- [Training Setup] Training Setup: the 200-iteration stopping point is selected post-hoc from the validation-loss minimum observed in a preliminary 1,000-iteration run performed on the identical problem distribution; the five seed-varied runs quantify variance only conditional on this fixed rule, so the 4.76 pp gain may partly reflect selection on the observed loss trajectory rather than a robust distillation effect.
- [Results] Results: the 4.76 percentage-point improvement is presented without a statistical significance test (paired t-test across seeds, bootstrap CI on the mean, or similar), leaving open whether the delta reliably exceeds sampling variation given the reported std dev of 0.17%.
- [Dataset Construction] Dataset Construction: the manuscript provides no details on the train/validation/test split sizes, how the held-out evaluation set was chosen, or whether the validation set used for the preliminary 1,000-iteration run overlaps with the final test problems.
minor comments (2)
- [Title / Abstract] The competition name is spelled without the apostrophe in the title and abstract; consistent use of 'O'Bryan' would improve readability.
- [Results] The response-length analysis (R1-R6) would be clearer if accompanied by a table listing exact mean word counts and accuracies per level rather than only narrative description.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive note on the methodological features such as the five-run protocol and overfitting diagnosis. We address each major comment below and will revise the manuscript to strengthen the presentation.
read point-by-point responses
-
Referee: [Training Setup] Training Setup: the 200-iteration stopping point is selected post-hoc from the validation-loss minimum observed in a preliminary 1,000-iteration run performed on the identical problem distribution; the five seed-varied runs quantify variance only conditional on this fixed rule, so the 4.76 pp gain may partly reflect selection on the observed loss trajectory rather than a robust distillation effect.
Authors: We agree this is a valid methodological concern. The preliminary run served to identify the onset of overfitting on the given distribution, after which the stopping rule was fixed at 200 iterations for the five independent runs. This does condition the reported variance on a data-dependent choice. In the revision we will add an explicit limitations paragraph discussing this post-hoc selection and note that more rigorous protocols such as nested validation could be used in follow-up work. revision: yes
-
Referee: [Results] Results: the 4.76 percentage-point improvement is presented without a statistical significance test (paired t-test across seeds, bootstrap CI on the mean, or similar), leaving open whether the delta reliably exceeds sampling variation given the reported std dev of 0.17%.
Authors: We concur that a formal test is warranted. The observed mean gain of 4.76 pp with a standard deviation of only 0.17% across five seeds already suggests low variability, but we will add either a one-sample t-test on the per-seed improvements or a bootstrap confidence interval for the mean accuracy in the revised results section to quantify statistical reliability. revision: yes
-
Referee: [Dataset Construction] Dataset Construction: the manuscript provides no details on the train/validation/test split sizes, how the held-out evaluation set was chosen, or whether the validation set used for the preliminary 1,000-iteration run overlaps with the final test problems.
Authors: We will supply the missing details in the revision. The full paper will state the exact sizes of the train, validation, and test partitions (allocated by competition year to preserve temporal separation), describe the random or year-based selection procedure for the held-out set, and explicitly confirm that the validation problems used in the preliminary 1,000-iteration run have no overlap with the final test problems. revision: yes
Circularity Check
No circularity; results are independent empirical measurements
full rationale
The paper's central claims consist of measured accuracies on held-out competition problems and MATH-500 after LoRA fine-tuning. The 200-iteration stopping point is selected from a preliminary run on the same distribution, but this does not algebraically force the reported accuracy values or reduce any prediction to its inputs by construction. No equations, self-citations, or ansatzes are invoked in a load-bearing manner for the accuracy figures; the evaluation remains external to the training procedure itself.
Axiom & Free-Parameter Ledger
free parameters (2)
- training iterations =
200
- LoRA rank and learning-rate schedule
axioms (1)
- domain assumption The dual-agent framework produces sufficiently accurate and pedagogically useful Chain-of-Thought traces for the student model to learn from.
Reference graph
Works this paper leans on
-
[1]
GitHub repository (2023)
Apple Inc.: MLX: An array framework for Apple silicon. GitHub repository (2023). https://github.com/ml-explore/mlx
2023
-
[2]
International Journal of Computer Vision 129(6), 1789–1819 (2021)
Gou, J., Yu, B., Maybank, S.J., Tao, D.: Knowledge distillation: A survey. International Journal of Computer Vision 129(6), 1789–1819 (2021). https: //doi.org/10.1007/s11263-021-01453-z
-
[3]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X., et al.: DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning. arXiv preprint arXiv:2501.12948 (2025).https://arxiv. org/abs/2501.12948
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
Distilling the Knowledge in a Neural Network
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. arXiv preprint arXiv:1503.02531 (2015).https://arxiv.org/abs/1503.02531
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[5]
Measuring Mathematical Problem Solving With the MATH Dataset
Hendrycks, D., Burns, C., Kadavath, S., Arora, A., Basart, S., Tang, E., Song, D., Steinhardt, J.: Measuring mathematical problem solving with the MATH dataset. In: Proceedings of the NeurIPS 2021 Datasets and Benchmarks Track (2021). https://arxiv.org/abs/2103.03874
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Training Verifiers to Solve Math Word Problems
Cobbe, K., Kosaraju, V., Bavarian, M., Chen, M., Jun, H., Kaiser, L., Plappert, M., Tworek, J., Hilton, J., Nakano, R., Hesse, C., Schulman, J.: Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168 (2021).https: //arxiv.org/abs/2110.14168
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[7]
arXiv preprint arXiv:2403.09053 (2024).https://arxiv.org/abs/2403.09053
Boix-Adsera, E.: Towards a theory of model distillation. arXiv preprint arXiv:2403.09053 (2024).https://arxiv.org/abs/2403.09053
-
[8]
Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
Deng, Y., Prasad, K., Fernandez, R., Smolensky, P., Chaudhary, V., Shieber, S.: Implicit chain of thought reasoning via knowledge distillation. arXiv preprint arXiv:2311.01460 (2023).https://arxiv.org/abs/2311.01460
-
[9]
arXiv preprint arXiv:2212.10071 (2023).https://arxiv.org/abs/2212.10071
Ho, N., Schmid, L., Yun, S.-Y.: Large language models are reasoning teachers. arXiv preprint arXiv:2212.10071 (2023).https://arxiv.org/abs/2212.10071
-
[10]
Magister, L.C., Mallinson, J., Adamek, J., Malmi, E., Severyn, A.: Teaching small language models to reason. In: Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL 2023), pp. 14209–14223 (2023). https://arxiv.org/abs/2212.08410 14
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Chen, W.: LoRA: Low-rank adaptation of large language models. In: Proceedings of the 10th International Conference on Learning Representations (ICLR 2022) (2022). https://arxiv.org/abs/2106.09685
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[12]
Instruction tuning for large language models: A survey.arXiv preprint arXiv:2308.10792, 2023
Zhang, S., Dong, L., Li, X., Zhang, S., Sun, X., Wang, S., Li, J., Hu, R., Zhang, T., Wu, F., Wang, G.: Instruction tuning for large language models: A survey. arXiv preprint arXiv:2308.10792 (2023).https://arxiv.org/abs/2308.10792
-
[13]
Nature Machine Intelligence 5, 220–235 (2023).https://doi
Ding, N., Qin, Y., Yang, G., Wei, F., Yang, Z., Su, Y., Hu, S., Chen, Y., Chan, C.M., Chen, W., Yi, X., Zhao, W., Wang, L., Liu, Z., Zheng, H., Chen, J., Liu, Y., Tang, J., Li, J., Sun, M.: Parameter-efficient fine-tuning of large-scale pre-trained language models. Nature Machine Intelligence 5, 220–235 (2023).https://doi. org/10.1038/s42256-023-00626-4
-
[14]
Zhang, T., Li, Y., Chou, Y.-C., Chen, J., Yuille, A., Wei, C., Xiao, J.: Vision-Language-Vision Auto-Encoder: Scalable Knowledge Distillation from Diffusion Models. Advances in Neural Information Processing Systems 38 (NeurIPS 2025), 79174–79202.https://arxiv.org/abs/2507.07104
-
[15]
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Wei, J., Wang, X., Schuurmans, D., Bosma, M., Ichter, B., Xia, F., Chi, E., Le, Q., Zhou, D.: Chain-of-thought prompting elicits reasoning in large language models. In: Proceedings of the 36th Conference on Neural Information Processing Systems (NeurIPS 2022) (2022).https://arxiv.org/abs/2201.11903
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[16]
arXiv preprint arXiv:2305.16366 (2023).https: //arxiv.org/abs/2305.16366
Zhao, X., Li, W., Kong, L.: Decomposing the enigma: Subgoal-based demonstration learning for formal theorem proving. arXiv preprint arXiv:2305.16366 (2023).https: //arxiv.org/abs/2305.16366
-
[17]
Lightman, H., Kosaraju, V., Burda, Y., Edwards, H., Baker, B., Lee, T., Leike, J., Schulman, J., Sutskever, I., Cobbe, K.: Let’s verify step by step. arXiv preprint arXiv:2305.20050 (2023).https://arxiv.org/abs/2305.20050 15
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.