IPO Finance Agent: Benchmark of LLM Financial Analysts Beyond Finance Agent v2, with Automated Rubric Generation, on the SpaceX (SPCX) IPO
Pith reviewed 2026-07-01 06:46 UTC · model grok-4.3
The pith
Zhipu GLM-5.2 reaches 79.8% accuracy on IPO diligence for SpaceX S-1 filings, exceeding the Finance Agent v2 ceiling of 57.9%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By improving the agentic harness with contextual retrieval and introducing an automated evaluator-optimizer pipeline for rubric generation, the IPO Finance Agent benchmark evaluates LLMs on 70 SpaceX S-1 diligence questions; Zhipu GLM-5.2 achieves 79.8% accuracy and Xiaomi MiMo-2.5 Pro reaches 77.2% at 0.05 USD per query, both surpassing the Finance Agent v2 ceiling of 57.9% at higher cost.
What carries the argument
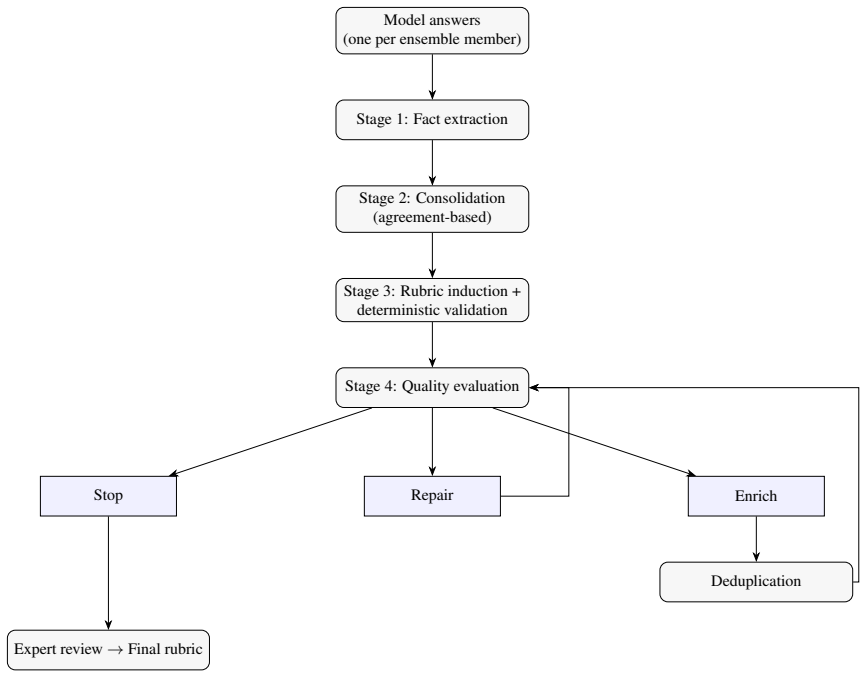
The evaluator-optimizer pipeline that extracts facts from model answers, consolidates them into draft criteria, audits for omissions, hallucinations, and redundancy, then iterates with LLM feedback to produce final rubrics.
If this is right
- Contextual retrieval enables agentic systems to process lengthy S-1 filings where the prior harness produced no output.
- Automated rubric generation allows scalable evaluation of financial tasks with reduced manual effort.
- Models can now be ranked on a Pareto frontier of accuracy versus cost for IPO-specific diligence.
- The public 70-question set supports reproducible testing while the private remainder reduces contamination risk.
Where Pith is reading between the lines
- The same rubric pipeline and retrieval upgrades could be applied to due diligence on other private companies preparing S-1 filings.
- Cost-efficient models at 0.05 USD per query open the possibility of routine automated screening for smaller investors or advisors.
- If the benchmark generalizes, it would shift evaluation focus from periodic reports to capital-formation and governance analysis.
Load-bearing premise
The 70 public SpaceX questions plus the automated rubric pipeline produce a faithful and unbiased measure of model capability on IPO due diligence.
What would settle it
A human review finding that the generated rubrics systematically omit key S-1 elements such as underwriting risk disclosures or capital-formation details would show the accuracy scores do not reflect true diligence performance.
Figures
read the original abstract
Finance Agent v2 (by Vals AI) has emerged as the reference benchmark for evaluating both Anthropic Claude and OpenAI ChatGPT frontier language models on financial tasks. However, it narrowly deals with periodic reporting from publicly traded companies (SEC 10-K and 10-Q filings), and its agentic harness relies on naive, unenriched chunk retrieval. Neither the task design nor the retrieval approach addresses the distinct challenges of IPO due diligence. SEC S-1 filings combine historical financial statements, governance structures, pro forma and common-control accounting treatments, capital-formation narratives, and underwriting-sensitive risk disclosures within substantially longer documents than typical periodic filings. That is why we introduce IPO Finance Agent, which extends the Finance Agent v2 framework along two directions: task domain and retrieval architecture. During our experiments, the original Finance Agent v2 harness basically failed to deliver any output related to the SpaceX S-1 filing, due to document length. We therefore had to improve the agentic harness with contextual retrieval, a more realistic and industry-standard approach for long documents. We also built a dataset of 1,000 IPO-diligence questions, and publicly release 70 questions on the SpaceX (SPCX) S-1 filing to support reproducibility, while the remainder are held private to guard against benchmark contamination. In addition, we introduce an evaluator-optimizer pipeline to automatically generate evaluation rubrics for the benchmark: candidate facts are extracted from model answers, consolidated into draft criteria, then automatically audited for omissions, hallucinations, mistiered items, and redundancy, with LLM feedback driving iterative repair, targeted enrichment, and deduplication. Human experts only review final rubrics before deployment. Results show that the best-performing evaluated model, Zhipu GLM-5.2, reaches 79.8% accuracy, and the most cost-efficient model on the resulting Pareto frontier, Xiaomi MiMo-2.5 Pro, reaches slightly lower accuracy (77.2%) at 0.05 USD per query, while exceeding the current Finance Agent v2 leaderboard ceiling, Google Gemini 3.5 Flash at 57.9% for 2.51 USD per query, and undercutting even FABv2's cheapest entry (MiniMax M3: 48.3% at 0.32 USD) on cost-efficiency. Code and data are released on GitHub https://github.com/benstaf/ipoagent
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces IPO Finance Agent as an extension of Finance Agent v2 for evaluating LLMs on IPO due diligence, using the SpaceX S-1 filing. It adds contextual retrieval for long documents, a 1,000-question dataset (70 public on SpaceX), and an automated evaluator-optimizer pipeline for rubric generation via fact extraction, consolidation, LLM audit, and human review. Reported results show Zhipu GLM-5.2 at 79.8% accuracy and Xiaomi MiMo-2.5 Pro at 77.2% (0.05 USD/query), exceeding the Finance Agent v2 ceiling of 57.9%; code and data are released on GitHub.
Significance. If the benchmark holds, the work supplies a new evaluation domain for financial LLMs that targets S-1-specific elements (governance, pro-forma accounting, underwriting risks) absent from periodic-filing benchmarks. The public code/data release and automated rubric pipeline are concrete strengths that enable reproducibility and extension by others.
major comments (3)
- [Rubric Generation] § on automated rubric generation (evaluator-optimizer pipeline): no inter-rater agreement, coverage statistics for key IPO topics (governance, pro-forma treatments, risk disclosures), or ablation results are reported. Without these, the headline accuracies (79.8%, 77.2%) cannot be shown to measure genuine diligence capability rather than pipeline artifacts.
- [Dataset Construction] Dataset section: the 70 public SpaceX questions are sampled from a 1,000-question pool, yet no sampling protocol, representativeness metrics, or public-vs-private coverage comparison is supplied. This directly affects whether the cost-accuracy Pareto claims generalize beyond the released subset.
- [Results] Results and comparison paragraphs: the claim that new results exceed the Finance Agent v2 ceiling of 57.9% treats the two benchmarks as comparable, but the manuscript itself notes that S-1 filings differ in length, accounting treatments, and risk focus from 10-K/10-Q tasks; no alignment or difficulty calibration is provided to support the cross-benchmark ranking.
minor comments (2)
- [Agentic Harness] The description of the contextual retrieval harness would be clearer with a short pseudocode block or flowchart.
- [Reproducibility] Ensure the GitHub repository link remains stable and includes the exact 70-question set and rubric examples used for the reported numbers.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments identify clear opportunities to strengthen the presentation of the automated rubric pipeline, dataset details, and cross-benchmark comparisons. We address each point below and indicate the revisions we will make in the next version of the manuscript.
read point-by-point responses
-
Referee: [Rubric Generation] § on automated rubric generation (evaluator-optimizer pipeline): no inter-rater agreement, coverage statistics for key IPO topics (governance, pro-forma treatments, risk disclosures), or ablation results are reported. Without these, the headline accuracies (79.8%, 77.2%) cannot be shown to measure genuine diligence capability rather than pipeline artifacts.
Authors: We agree that quantitative validation of the rubric pipeline is necessary. The current pipeline already includes an LLM audit step for omissions, hallucinations, and redundancy followed by human expert review of final rubrics. In the revised manuscript we will add: (1) coverage statistics showing the distribution of rubric criteria across core IPO topics (governance, pro-forma accounting, risk disclosures, etc.); (2) ablation results comparing accuracy with and without the consolidation and audit stages; and (3) inter-rater agreement statistics from the human review phase (Cohen’s kappa or equivalent). These additions will be placed in a new subsection under the rubric-generation description and will directly address whether the reported accuracies reflect pipeline artifacts. revision: partial
-
Referee: [Dataset Construction] Dataset section: the 70 public SpaceX questions are sampled from a 1,000-question pool, yet no sampling protocol, representativeness metrics, or public-vs-private coverage comparison is supplied. This directly affects whether the cost-accuracy Pareto claims generalize beyond the released subset.
Authors: We accept this criticism. The 1,000-question pool was constructed by systematically extracting factual statements from each major section of the SpaceX S-1 and converting them into questions; the 70 public questions were chosen to span the same topic distribution while remaining self-contained. In revision we will: (a) explicitly describe the sampling protocol and stratification criteria; (b) report topic-level representativeness metrics (e.g., percentage of questions per S-1 section); and (c) provide a high-level comparison of topic coverage between the public 70 and the private remainder without disclosing private content. These details will be added to the Dataset Construction section. revision: yes
-
Referee: [Results] Results and comparison paragraphs: the claim that new results exceed the Finance Agent v2 ceiling of 57.9% treats the two benchmarks as comparable, but the manuscript itself notes that S-1 filings differ in length, accounting treatments, and risk focus from 10-K/10-Q tasks; no alignment or difficulty calibration is provided to support the cross-benchmark ranking.
Authors: We acknowledge the overstatement. The manuscript already notes the structural differences between S-1 and periodic filings, yet the comparison language implies direct equivalence. In the revised version we will: (1) remove or qualify the phrase “exceeding the Finance Agent v2 ceiling” and instead state that IPO Finance Agent achieves higher accuracy on a distinct, longer-document task with contextual retrieval; (2) add an explicit limitations paragraph clarifying the absence of difficulty calibration and the non-comparability of the two benchmarks; and (3) frame the cost-efficiency results strictly within the IPO setting. These changes will appear in the Results and Discussion sections. revision: yes
Circularity Check
No circularity; empirical benchmark results independent of inputs
full rationale
The paper reports direct empirical accuracies (e.g., GLM-5.2 at 79.8%) obtained by running models on a fixed set of 70 public questions drawn from a SpaceX S-1 filing, scored via an automated rubric pipeline. No equations, fitted parameters, predictions, or derivations are present. The methodology describes question construction and rubric generation but does not reduce any reported result to its own inputs by construction. Comparisons to Finance Agent v2 are external benchmarks, not self-referential. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Building Effective Agents
Anthropic. Building Effective Agents. Dec 19, 2024. https://www.anthropic.com/ engineering/building-effective-agents
2024
-
[2]
Introducing Contextual Retrieval
Anthropic. Introducing Contextual Retrieval. Sep 19, 2024. https://www.anthropic.com/ news/contextual-retrieval
2024
-
[3]
Claude for Financial Services
Anthropic. Claude for Financial Services. Jul 15, 2025. https://www.anthropic.com/ news/claude-for-financial-services
2025
-
[4]
Advancing Claude for Financial Services
Anthropic. Advancing Claude for Financial Services. Oct 27, 2025.https://www.anthropic. com/news/advancing-claude-for-financial-services
2025
-
[5]
Introducing Claude Opus 4.8
Anthropic. Introducing Claude Opus 4.8. May 28, 2026. https://www.anthropic.com/ news/claude-opus-4-8
2026
-
[6]
Constitutional AI: Harmlessness from AI Feedback
Yuntao Bai, Saurav Kadavath, Sandipan Kundu, Amanda Askell, Jackson Kernion, Andy Jones, Anna Chen, Anna Goldie, Azalia Mirhoseini, Cameron McKinnon, et al. Constitutional AI: Harmlessness from AI Feedback. arXiv preprint arXiv:2212.08073, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[7]
FinQA: A Dataset of Numerical Reasoning over Financial Data
Zhiyu Chen, Wenhu Chen, Charese Smiley, Sameena Shah, Iana Borova, Dylan Langdon, Reema Moussa, Matt Beane, Ting-Hao Huang, Bryan Routledge, and William Yang Wang. FinQA: A Dataset of Numerical Reasoning over Financial Data. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021
2021
-
[8]
ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering
Zhiyu Chen, Shiyang Li, Charese Smiley, Zhiqiang Ma, Sameena Shah, and William Yang Wang. ConvFinQA: Exploring the Chain of Numerical Reasoning in Conversational Finance Question Answering. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022. 11
2022
-
[9]
Securities and Exchange Commission
U.S. Securities and Exchange Commission. EDGAR — Electronic Data Gathering, Analysis, and Retrieval System. https://www.sec.gov/about/about-edgar
-
[10]
Antoine Bigeard, Langston Nashold, Rayan Krishnan, and Shirley Wu. Finance Agent Benchmark: Benchmarking LLMs on Real-world Financial Research Tasks. arXiv preprint arXiv:2508.00828, 2025
-
[11]
Finance Agent v2 Benchmark
Vals AI. Finance Agent v2 Benchmark. https://www.vals.ai/benchmarks/fabv2
-
[12]
FinanceBench: A New Benchmark for Financial Question Answering
Pranab Islam, Anand Kannappan, Douwe Kiela, Rebecca Qian, Nino Scherrer, and Bertie Vidgen. FinanceBench: A New Benchmark for Financial Question Answering. arXiv preprint arXiv:2311.11944, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
FinBen: A Holistic Financial Benchmark for Large Language Models
Qianqian Xie, Weiguang Han, Zhengyu Chen, Ruoyu Xiang, Xiao Zhang, Yueru He, Mengxi Xiao, Dong Li, Yongfu Dai, Duanyu Feng, et al. FinBen: A Holistic Financial Benchmark for Large Language Models. Advances in Neural Information Processing Systems 37 (NeurIPS Datasets and Benchmarks Track), 2024
2024
-
[14]
FinRetrieval: A benchmark for financial data retrieval by AI agents
Eric Y . Kim and Jie Huang. FinRetrieval: A Benchmark for Financial Data Retrieval by AI Agents. arXiv preprint arXiv:2603.04403, 2026
-
[15]
Time Travel in LLMs: Tracing Data Contamination in Large Language Models
Shahriar Golchin and Mihai Surdeanu. Time Travel in LLMs: Tracing Data Contamination in Large Language Models. International Conference on Learning Representations (ICLR), 2024
2024
-
[16]
Jimenez, John Yang, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
Carlos E. Jimenez, John Yang, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-bench: Can Language Models Resolve Real-World GitHub Issues? International Conference on Learning Representations (ICLR), 2024
2024
-
[17]
Dense Passage Retrieval for Open-Domain Question Answering
Vladimir Karpukhin, Barlas O ˘guz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense Passage Retrieval for Open-Domain Question Answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[18]
ColBERT: Efficient and Effective Passage Search via Con- textualized Late Interaction over BERT
Omar Khattab and Matei Zaharia. ColBERT: Efficient and Effective Passage Search via Con- textualized Late Interaction over BERT. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR), 2020
2020
-
[19]
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. Advances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[20]
Holistic Evaluation of Language Models
Percy Liang, Rishi Bommasani, Tony Lee, Dimitris Tsipras, Dilara Soylu, Michihiro Yasunaga, Yian Zhang, Deepak Narayanan, Yuhuai Wu, Ananya Kumar, et al. Holistic Evaluation of Language Models. Transactions on Machine Learning Research (TMLR), 2023
2023
-
[21]
IPO Underpricing
Alexander Ljungqvist. IPO Underpricing. In B. Espen Eckbo (ed.), Handbook of Corporate Finance: Empirical Corporate Finance, V olume 1, Chapter 7, Elsevier, 2007
2007
-
[22]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. AgentBench: Evaluating LLMs as Agents. arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[24]
Initial Public Offerings: A Synthesis of the Literature and Directions for Future Research
Michelle Lowry, Roni Michaely, and Ekaterina V olkova. Initial Public Offerings: A Synthesis of the Literature and Directions for Future Research. Foundations and Trends in Finance, 11(3-4):154–320, 2017
2017
-
[25]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, et al. Self-Refine: Iterative Refinement with Self-Feedback. Advances in Neural Information Processing Systems 36 (NeurIPS), 2023. 12
2023
-
[26]
GAIA: A Benchmark for General AI Assistants
Grégoire Mialon, Clémentine Fourrier, Craig Swift, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: A Benchmark for General AI Assistants. International Conference on Learning Representations (ICLR), 2024
2024
-
[27]
Kimi K2.6 is now open-weight #1 on Finance Agent Bench- mark V2
Moonshot AI (Kimi). “Kimi K2.6 is now open-weight #1 on Finance Agent Bench- mark V2.” Post on X-Twitter, May 14, 2026. https://x.com/Kimi_Moonshot/status/ 2054803169994272819
2026
-
[28]
Xueqing Peng, Lingfei Qian, Yan Wang, Ruoyu Xiang, Yueru He, Yang Ren, Mingyang Jiang, Jeff Zhao, Huan He, Yi Han, et al. MultiFinBen: A Multilingual, Multimodal, and Difficulty- Aware Benchmark for Financial LLM Evaluation. arXiv preprint arXiv:2506.14028, 2025
-
[29]
Introducing GPT-5.5
OpenAI. Introducing GPT-5.5. April 23, 2026. https://openai.com/index/ introducing-gpt-5-5/
2026
-
[30]
Jay R. Ritter. The Long-Run Performance of Initial Public Offerings. Journal of Finance, 46(1):3–27, 1991
1991
-
[31]
Ritter and Ivo Welch
Jay R. Ritter and Ivo Welch. A Review of IPO Activity, Pricing, and Allocations. Journal of Finance, 57(4):1795–1828, 2002
2002
-
[32]
Beyond the Imitation Game: Quantify- ing and Extrapolating the Capabilities of Language Models
Aarohi Srivastava, Abhinav Rastogi, Abhishek Rao, et al. Beyond the Imitation Game: Quantify- ing and Extrapolating the Capabilities of Language Models. Transactions on Machine Learning Research (TMLR), 2023
2023
-
[33]
Form S-1 Registration Statement
Space Exploration Technologies Corp. Form S-1 Registration Statement. U.S. Securities and Exchange Commission, May 20, 2026. https://www.sec.gov/Archives/edgar/data/ 1181412/000162828026036936/spaceexplorationtechnologi.htm
2026
-
[34]
VCBench: Benchmarking LLMs in Venture Capital
Rick Chen, Joseph Ternasky, Afriyie Samuel Kwesi, Ben Griffin, Aaron Ontoyin Yin, Zakari Salifu, Kelvin Amoaba, Xianling Mu, Fuat Alican, and Yigit Ihlamur. VCBench: Benchmarking LLMs in Venture Capital. arXiv preprint arXiv:2509.14448, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[35]
MBABench: Evaluating LLM Agents on End-to-End Spreadsheet Tasks in Finance
Thomson Yen et al. WorkstreamBench: Evaluating LLM Agents on End-to-End Spreadsheet Tasks in Finance. arXiv preprint arXiv:2605.22664, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[36]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains. arXiv preprint arXiv:2406.12045, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
YC Bench: a Live Benchmark for Forecasting Startup Outperformance in Y Combinator Batches
Mostapha Benhenda. YC Bench: A Live Benchmark for Forecasting Startup Outperformance in Y Combinator Batches. arXiv preprint arXiv:2604.02378, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance
Fengbin Zhu, Wenqiang Lei, Youcheng Huang, Chao Wang, Shuo Zhang, Jiancheng Lv, Fuli Feng, and Tat-Seng Chua. TAT-QA: A Question Answering Benchmark on a Hybrid of Tabular and Textual Content in Finance. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics (ACL), 2021
2021
-
[39]
Judgelm: Fine-tuned large language models are scalable judges.arXiv preprint arXiv:2310.17631, 2023
Lianghui Zhu, Xinggang Wang, and Xinlong Wang. JudgeLM: Fine-tuned Large Language Models are Scalable Judges. arXiv preprint arXiv:2310.17631, 2023
-
[40]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv preprint arXiv:2306.05685, 2023. 13
work page internal anchor Pith review Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.