ASAP: Agent-System Co-Design for Wall-Clock-Centered Auto HPO Research for ML Experiments
Pith reviewed 2026-06-25 23:27 UTC · model grok-4.3
The pith
An LLM integrates proposals from multiple hyperparameter optimizers while system redesigns hide their latency under model evaluations to improve end-to-end wall-clock performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
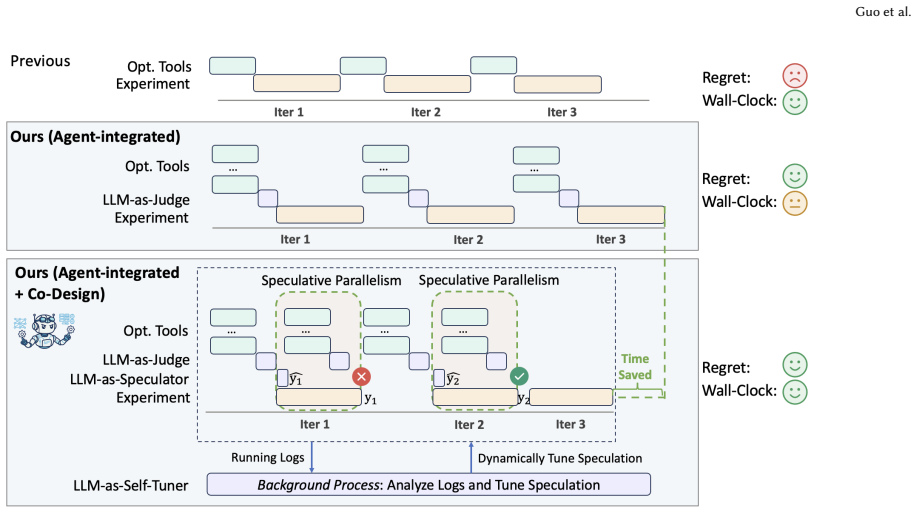
ASAP shows that an LLM can serve as an integrator that draws proposals from a diverse pool of inductive-biased optimizers and selects among them each round, while a re-architected execution loop—prefix-stable prompting for KV-cache reuse, speculation parallelism hidden behind model evaluations via a relative-error accept test, and an off-path Self-Tuner—reduces total wall-clock time without increasing regret, producing better configurations than either single-tool or iteration-centric LLM baselines on varied HPO tasks.
What carries the argument
The LLM integrator that selects among proposals from multiple optimizers, paired with speculation parallelism and relative-error accept test to hide latency.
If this is right
- HPO performance can improve by drawing on multiple priors simultaneously rather than committing to one tool or one LLM replacement.
- Practical HPO evaluation must measure total elapsed time, not iteration count, once LLM or tool calls add serial cost.
- Prefix-stable prompts and relative-error speculation can be reused in other iterative loops that mix LLM calls with expensive evaluations.
- An off-path Self-Tuner can adapt runtime parameters from execution history while keeping the main optimization path unchanged.
Where Pith is reading between the lines
- The same integrator-plus-speculation pattern may apply to other agentic workflows that currently treat LLMs as drop-in replacements for single specialized modules.
- Benchmarks for agent systems could usefully report both regret curves and cumulative wall-clock cost under realistic latency models.
- If the relative-error accept test proves robust, similar approximate checks might safely accelerate other LLM-augmented search or planning loops.
Load-bearing premise
The LLM can reliably combine and choose among proposals from different optimizers without its own pretraining bias erasing the diversity those optimizers supply.
What would settle it
A collection of HPO problems on which, after a fixed wall-clock budget, ASAP reaches final model performance no better than the strongest single baseline optimizer, or on which the speculation accept test rejects enough good proposals to raise final regret.
Figures






read the original abstract
Hyperparameter Optimization (HPO) is essential for maximizing machine learning model performance, and its core challenge is sample efficiency: finding strong configurations within a limited budget. Because every HPO tool relies on a surrogate prior that imparts its own inductive bias, individual tools struggle once problems become sufficiently diverse and drift from these priors. Motivated by the reasoning and generalization capabilities of LLMs, recent work has explored using LLMs for HPO and reports improved per-iteration performance. Yet these methods share two limitations with a common origin: they use the LLM as a single-tool replacement evaluated by iteration count. (i) Deployed in place of prior tools, the LLM is itself constrained by its pretraining objective to one family of inductive-biased proposals; this single-source setup still fails to handle the full diversity of problems. (ii) Per-iteration evaluation ignores that, in real runs, LLM inference or tool execution is paid serially on top of model evaluation every round, so iteration-count gains do not translate into end-to-end wall-clock gains. We present ASAP, an agent-system co-design that addresses both limitations. On the agent side, ASAP uses the LLM to integrate a diverse pool of inductive-biased optimizers and to select among their proposals each round. On the system side, ASAP re-architects the loop to reduce end-to-end wall-clock while preserving regret quality: a prefix-stable prompt maximizes KV-cache reuse across rounds; speculation parallelism hides the remaining LLM and tool latency under model evaluation via a relative-error accept test; and a Self-Tuner adapts the speculation threshold from execution logs off the critical path. Extensive experiments on diverse modern HPO tasks show that ASAP consistently outperforms baselines, underscoring the value of tool integration and agent-system co-design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ASAP, an agent-system co-design for hyperparameter optimization (HPO). The agent side uses an LLM to integrate proposals from a diverse pool of inductive-biased optimizers and select among them each round. The system side adds a prefix-stable prompt for KV-cache reuse, speculation parallelism that hides LLM/tool latency under model evaluation via a relative-error accept test, and a Self-Tuner that adapts the speculation threshold from logs. The central empirical claim is that this combination yields both lower wall-clock time and better or equal regret than baselines on diverse modern HPO tasks.
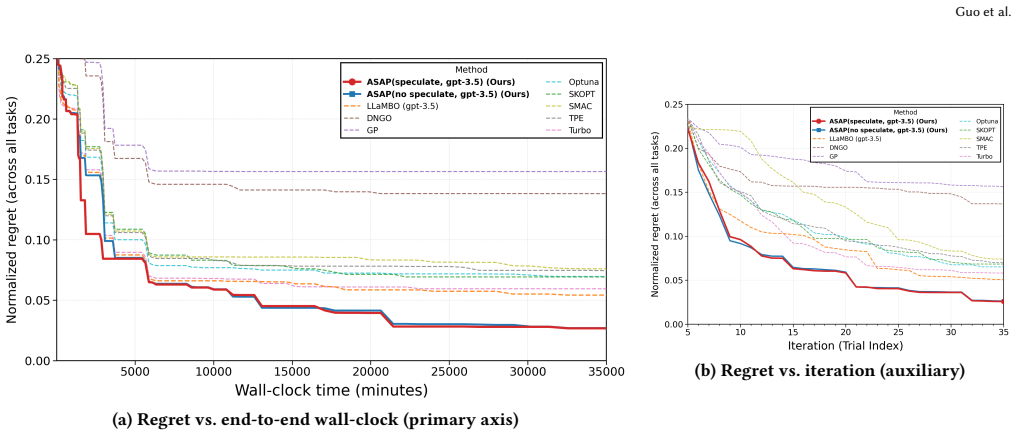
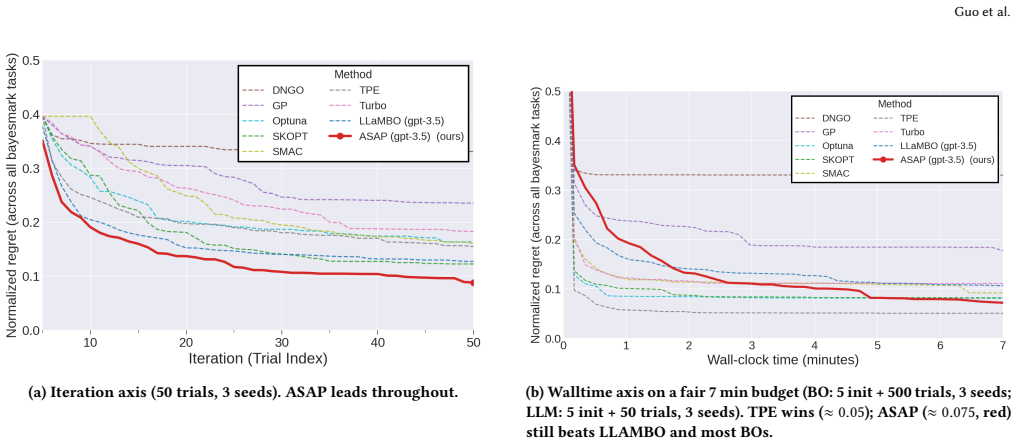
Significance. If the reported regret curves, wall-clock breakdowns, and ablations hold, the work demonstrates that LLM-based integration of existing tools plus targeted system mechanisms can overcome single-source inductive bias while delivering practical end-to-end speedups. The explicit measurement of proposal-source diversity and confirmation that the accept test preserves final regret are concrete strengths that move the field beyond iteration-count metrics.
major comments (2)
- [§4] §4 (system mechanisms), the relative-error accept test: the manuscript shows empirically that the test does not measurably degrade final regret on the reported benchmarks, but provides no analytic bound on the bias introduced when the speculation threshold is adapted by the Self-Tuner; a short worst-case argument or additional synthetic experiment would strengthen the claim that regret quality is preserved by construction rather than only on the chosen tasks.
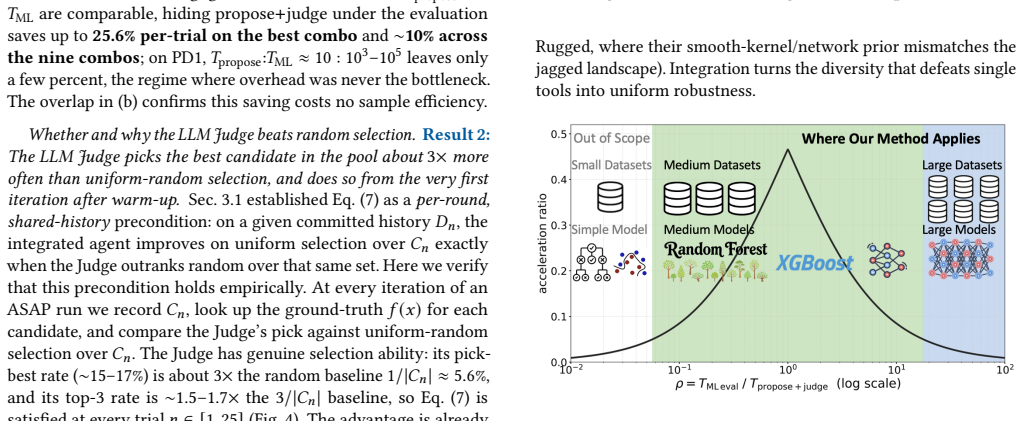
- [§5.3] §5.3 (ablations), proposal-source diversity: while the paper reports that the LLM selects from multiple sources, the diversity metric (e.g., fraction of proposals accepted per source) is only shown aggregated; per-task breakdowns would clarify whether the claimed advantage collapses on problems where one optimizer dominates.
minor comments (2)
- [Abstract / §1] The abstract and §1 repeatedly contrast “per-iteration” vs. “wall-clock” evaluation; adding a one-sentence definition of the wall-clock metric (including whether it counts only model evaluations or also LLM inference) would remove ambiguity for readers.
- [Figures in §5] Figure captions for the regret curves do not state the number of independent runs or whether shaded regions are standard deviation or standard error; this is a common omission that affects interpretability of the “consistent outperformance” claim.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and the recommendation for minor revision. We address each of the major comments below.
read point-by-point responses
-
Referee: [§4] §4 (system mechanisms), the relative-error accept test: the manuscript shows empirically that the test does not measurably degrade final regret on the reported benchmarks, but provides no analytic bound on the bias introduced when the speculation threshold is adapted by the Self-Tuner; a short worst-case argument or additional synthetic experiment would strengthen the claim that regret quality is preserved by construction rather than only on the chosen tasks.
Authors: We acknowledge that an analytic bound on the bias would provide stronger theoretical guarantees. Deriving such a bound is non-trivial because the Self-Tuner adapts the threshold based on execution logs in a data-dependent manner. However, we will add a synthetic experiment in the revised version that simulates worst-case adaptation scenarios to empirically bound the potential bias, thereby addressing the concern that regret preservation holds only on the chosen tasks. revision: yes
-
Referee: [§5.3] §5.3 (ablations), proposal-source diversity: while the paper reports that the LLM selects from multiple sources, the diversity metric (e.g., fraction of proposals accepted per source) is only shown aggregated; per-task breakdowns would clarify whether the claimed advantage collapses on problems where one optimizer dominates.
Authors: The aggregated diversity metric was presented to demonstrate the overall utilization of multiple sources across the benchmark suite. We agree that per-task breakdowns can provide additional clarity. In the revision, we will include per-task diversity metrics (e.g., fraction of proposals accepted per source for each task) to confirm that the multi-source advantage does not collapse on any individual problem. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper is an empirical systems contribution describing an agent-system co-design (LLM integration of optimizer proposals plus speculation accept test and Self-Tuner) whose central claim is that extensive experiments on modern HPO tasks show consistent outperformance. No equations, parameter fits, predictions derived from inputs, or load-bearing self-citations appear in the provided text; the result is presented as a measured benchmark outcome rather than a derivation that reduces to its own definitions or prior author work by construction. The derivation chain is therefore self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Takuya Akiba, Shotaro Sano, Toshihiko Yanase, Takeru Ohta, and Masanori Koyama. 2019. Optuna: A Next-generation Hyperparameter Optimization Frame- work. arXiv:1907.10902 [cs.LG] https://arxiv.org/abs/1907.10902
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[2]
Huan ang Gao, Jiayi Geng, Wenyue Hua, Mengkang Hu, Xinzhe Juan, Hongzhang Liu, Shilong Liu, Jiahao Qiu, Xuan Qi, Yiran Wu, Hongru Wang, Han Xiao, Yuhang Zhou, Shaokun Zhang, Jiayi Zhang, Jinyu Xiang, Yixiong Fang, Qiwen Zhao, Dongrui Liu, Qihan Ren, Cheng Qian, Zhenhailong Wang, Minda Hu, Huazheng Wang, Qingyun Wu, Heng Ji, and Mengdi Wang. 2026. A Survey...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
James Bergstra, Rémi Bardenet, Yoshua Bengio, and Balázs Kégl. 2011. Algorithms for Hyper-Parameter Optimization. InAdvances in Neural Information Processing Systems, J. Shawe-Taylor, R. Zemel, P. Bartlett, F. Pereira, and K. Weinberger (Eds.), Vol. 24. Curran Associates, Inc. https://proceedings.neurips.cc/paper_ files/paper/2011/file/86e8f7ab32cfd12577b...
2011
-
[4]
James Bergstra and Yoshua Bengio. 2012. Random Search for Hyper-Parameter Optimization.Journal of Machine Learning Research13, 10 (2012), 281–305. http://jmlr.org/papers/v13/bergstra12a.html
2012
- [5]
-
[6]
Yizhou Chi, Yizhang Lin, Sirui Hong, Duyi Pan, Yaying Fei, Guanghao Mei, Bangbang Liu, Tianqi Pang, Jacky Kwok, Ceyao Zhang, Bang Liu, and Chenglin Wu. 2024. SELA: Tree-Search Enhanced LLM Agents for Automated Machine Learning. arXiv:2410.17238 [cs.AI] https://arxiv.org/abs/2410.17238
-
[7]
Skeel, and Hartmut Neven
Nan Ding, Youhan Fang, Ryan Babbush, Changyou Chen, Robert D. Skeel, and Hartmut Neven. 2014. Bayesian Sampling Using Stochastic Gradient Ther- mostats. InAdvances in Neural Information Processing Systems, Z. Ghahramani, M. Welling, C. Cortes, N. Lawrence, and K. Weinberger (Eds.), Vol. 27. Cur- ran Associates, Inc. https://proceedings.neurips.cc/paper_fi...
2014
-
[8]
Katharina Eggensperger, Philipp Müller, Neeratyoy Mallik, Matthias Feurer, René Sass, Aaron Klein, Noor Awad, Marius Lindauer, and Frank Hutter. 2022. HPOBench: A Collection of Reproducible Multi-Fidelity Benchmark Problems for HPO. arXiv:2109.06716 [cs.LG] https://arxiv.org/abs/2109.06716
- [9]
- [10]
-
[11]
Siyuan Guo, Cheng Deng, Ying Wen, Hechang Chen, Yi Chang, and Jun Wang
-
[12]
Ds-agent: Automated data science by empowering large language models with case-based reasoning
DS-Agent: Automated Data Science by Empowering Large Language Models with Case-Based Reasoning. arXiv:2402.17453 [cs.LG] https://arxiv.org/ abs/2402.17453
-
[13]
Taicheng Guo, Nitesh V Chawla, Olaf Wiest, and Xiangliang Zhang. 2026. Au- toLLMResearch: Training Research Agents for Automating LLM Experiment Configuration–Learning from Cheap, Optimizing Expensive.arXiv preprint arXiv:2605.11518(2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
Taicheng Guo, Hai Wang, ChaoChun Liu, Mohsen Golalikhani, Xin Chen, Xian- gliang Zhang, and Chandan K Reddy. 2025. MTSQL-R1: Towards Long-Horizon Multi-Turn Text-to-SQL via Agentic Training.arXiv preprint arXiv:2510.12831 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Sirui Hong, Yizhang Lin, Bang Liu, Bangbang Liu, Binhao Wu, Ceyao Zhang, Chenxing Wei, Danyang Li, Jiaqi Chen, Jiayi Zhang, Jinlin Wang, Li Zhang, Lingyao Zhang, Min Yang, Mingchen Zhuge, Taicheng Guo, Tuo Zhou, Wei Tao, Xiangru Tang, Xiangtao Lu, Xiawu Zheng, Xinbing Liang, Yaying Fei, Yuheng Cheng, Zhibin Gou, Zongze Xu, and Chenglin Wu. 2024. Data Inte...
-
[16]
Pascal Kerschke. 2017. Comprehensive Feature-Based Landscape Analysis of Continuous and Constrained Optimization Problems Using the R-Package flacco. arXiv:1708.05258 [stat.ML] https://arxiv.org/abs/1708.05258 ASAP: Agent-System Co-Design for Wall-Clock-Centered A uto HPO Research for ML Experiments
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[17]
Yaniv Leviathan, Matan Kalman, and Yossi Matias. 2023. Fast Inference from Transformers via Speculative Decoding. arXiv:2211.17192 [cs.LG] https://arxiv. org/abs/2211.17192
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [18]
-
[19]
Marius Lindauer, Katharina Eggensperger, Matthias Feurer, André Biedenkapp, Difan Deng, Carolin Benjamins, Tim Ruhopf, René Sass, and Frank Hutter. 2022. SMAC3: A Versatile Bayesian Optimization Package for Hyperparameter Opti- mization. arXiv:2109.09831 [cs.LG] https://arxiv.org/abs/2109.09831
- [20]
- [21]
- [22]
-
[23]
scikit optimize. [n. d.]. https://scikit-optimize.github.io/stable/
-
[24]
Jasper Snoek, Hugo Larochelle, and Ryan P. Adams. 2012. Practical Bayesian Optimization of Machine Learning Algorithms. arXiv:1206.2944 [stat.ML] https: //arxiv.org/abs/1206.2944
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[25]
Scalable Bayesian Optimization Using Deep Neural Networks
Jasper Snoek, Oren Rippel, Kevin Swersky, Ryan Kiros, Nadathur Satish, Narayanan Sundaram, Md. Mostofa Ali Patwary, Prabhat, and Ryan P. Adams. 2015. Scalable Bayesian Optimization Using Deep Neural Networks. arXiv:1502.05700 [stat.ML] https://arxiv.org/abs/1502.05700
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[26]
Alexander Tornede, Difan Deng, Theresa Eimer, Joseph Giovanelli, Aditya Mo- han, Tim Ruhkopf, Sarah Segel, Daphne Theodorakopoulos, Tanja Tornede, Henning Wachsmuth, and Marius Lindauer. 2024. AutoML in the Age of Large Language Models: Current Challenges, Future Opportunities and Risks. arXiv:2306.08107 [cs.LG] https://arxiv.org/abs/2306.08107
-
[27]
Dahl, Kevin Swersky, Chansoo Lee, Zachary Nado, Justin Gilmer, Jasper Snoek, and Zoubin Ghahramani
Zi Wang, George E. Dahl, Kevin Swersky, Chansoo Lee, Zachary Nado, Justin Gilmer, Jasper Snoek, and Zoubin Ghahramani. 2024. Pre-trained Gaussian Processes for Bayesian Optimization. arXiv:2109.08215 [cs.LG] https://arxiv.org/ abs/2109.08215
-
[28]
Shuhei Watanabe. 2026. Tree-Structured Parzen Estimator: Understanding Its Algorithm Components and Their Roles for Better Empirical Performance. arXiv:2304.11127 [cs.LG] https://arxiv.org/abs/2304.11127
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Christopher Williams and Carl Rasmussen. 1995. Gaussian Processes for Regres- sion. InAdvances in Neural Information Processing Systems, D. Touretzky, M.C. Mozer, and M. Hasselmo (Eds.), Vol. 8. MIT Press. https://proceedings.neurips. cc/paper_files/paper/1995/file/7cce53cf90577442771720a370c3c723-Paper.pdf
1995
-
[30]
David H Wolpert and William G Macready. 2002. No free lunch theorems for optimization.IEEE transactions on evolutionary computation1, 1 (2002), 67–82
2002
-
[31]
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, and Botian Shi. 2026. EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle. arXiv:2510.16079 [cs.CL] https://arxiv.org/abs/2510.16079
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[32]
Naimeng Ye, Arnav Ahuja, Georgios Liargkovas, Yunan Lu, Kostis Kaffes, and Tianyi Peng. 2026. Speculative Actions: A Lossless Framework for Faster Agentic Systems. arXiv:2510.04371 [cs.AI] https://arxiv.org/abs/2510.04371
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Michael R. Zhang, Nishkrit Desai, Juhan Bae, Jonathan Lorraine, and Jimmy Ba. 2024. Using Large Language Models for Hyperparameter Optimization. arXiv:2312.04528 [cs.LG] https://arxiv.org/abs/2312.04528 Guo et al. Appendix A Implementation Details This section collects everything needed to reproduce our exper- iments: the benchmark tasks we evaluate on (S...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.