MTR-Bench: A Comprehensive Benchmark for Multi-Turn Reasoning Evaluation
Pith reviewed 2026-05-22 13:33 UTC · model grok-4.3
The pith
A new benchmark shows even advanced reasoning models fall short on multi-turn interactive tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
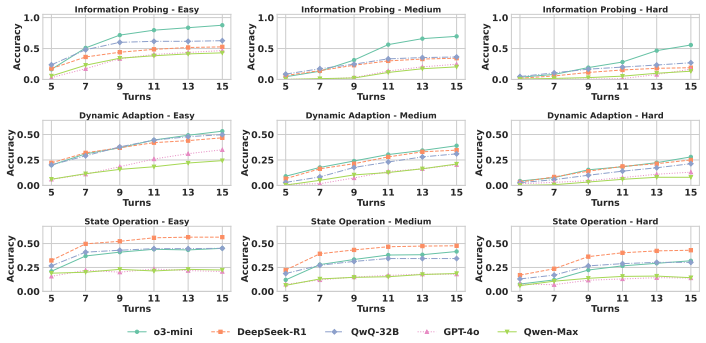
MTR-Bench supplies 4 classes, 40 tasks, and 3600 instances that force models to perform multi-turn reasoning through repeated environment interactions, with a fully automated construction and evaluation pipeline; tests on current top models demonstrate they fall short on these interactive challenges.
What carries the argument
The MTR-Bench automated framework that generates multi-turn tasks and scores model performance through direct environment interactions without human oversight.
If this is right
- Single-turn evaluations miss important weaknesses in how models handle extended problem-solving.
- New training approaches that emphasize environment feedback over multiple steps become necessary.
- The automated pipeline makes it practical to expand testing to additional domains and larger sets of tasks.
- Insights from model failures can directly inform designs for more capable interactive AI systems.
Where Pith is reading between the lines
- Benchmarks built on the same interaction principle could test long-horizon planning in other areas such as tool use or simulated environments.
- Models might improve if trained explicitly on sequences that mirror the multi-turn structure of these tasks.
- Widespread adoption of automated multi-turn tests could shift standard practice away from isolated question answering.
Load-bearing premise
The forty tasks and automatic scoring protocol accurately measure genuine multi-turn reasoning skills that depend on interaction rather than artifacts from how the test cases were created.
What would settle it
If leading models reach high success rates across all forty tasks after training focused on multi-turn interaction, the claim that they inherently fall short would be undermined.
Figures




read the original abstract
Recent advances in Large Language Models (LLMs) have shown promising results in complex reasoning tasks. However, current evaluations predominantly focus on single-turn reasoning scenarios, leaving interactive tasks largely unexplored. We attribute it to the absence of comprehensive datasets and scalable automatic evaluation protocols. To fill these gaps, we present MTR-Bench for LLMs' Multi-Turn Reasoning evaluation. Comprising 4 classes, 40 tasks, and 3600 instances, MTR-Bench covers diverse reasoning capabilities, fine-grained difficulty granularity, and necessitates multi-turn interactions with the environments. Moreover, MTR-Bench features fully-automated framework spanning both dataset constructions and model evaluations, which enables scalable assessment without human interventions. Extensive experiments reveal that even the cutting-edge reasoning models fall short of multi-turn, interactive reasoning tasks. And the further analysis upon these results brings valuable insights for future research in interactive AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MTR-Bench, a benchmark comprising 4 classes, 40 tasks, and 3600 instances for evaluating multi-turn reasoning in LLMs. It emphasizes a fully automated framework for dataset construction and model evaluation that requires interactions with environments, and reports that even state-of-the-art reasoning models underperform on these tasks, offering insights for interactive AI development.
Significance. If the automated tasks genuinely necessitate multi-turn state tracking and interaction with dynamic, partially observable environments, the benchmark would fill a clear gap in current single-turn-focused evaluations and provide scalable, reproducible assessment. The fully automated pipeline is a practical strength for enabling large-scale testing without human annotation.
major comments (2)
- [§3.2] §3.2 (Automated Task Construction): The description of the template-based or simulator-driven generation does not include explicit checks or examples confirming that state transitions are irreversible or that key information is hidden from the initial prompt, which is required to ensure failures reflect multi-turn reasoning deficits rather than single-turn solvability or construction shortcuts.
- [§4.3] §4.3 (Error Analysis): The results section reports aggregate performance shortfalls but lacks a per-task or per-class breakdown of failure modes (e.g., state-tracking errors vs. instruction-following errors), making it difficult to confirm that the central claim about interactive reasoning limitations is supported by the data.
minor comments (2)
- [Abstract] The abstract and §1 should explicitly name the four classes of tasks rather than leaving them as an unlabeled total.
- [Figure 2] Figure 2 (task distribution) would be clearer with an added column or annotation showing the average number of turns required per task class.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper to improve clarity and evidentiary support for our claims about multi-turn reasoning.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Automated Task Construction): The description of the template-based or simulator-driven generation does not include explicit checks or examples confirming that state transitions are irreversible or that key information is hidden from the initial prompt, which is required to ensure failures reflect multi-turn reasoning deficits rather than single-turn solvability or construction shortcuts.
Authors: We appreciate the referee pointing out the need for explicit verification of these properties. Section 3.2 describes simulator-driven construction for each of the four classes, where environments enforce irreversible state changes (e.g., consumed resources in planning tasks or updated positions in navigation) and initial prompts provide only partial observability by design. To make this fully explicit, we have added a new paragraph with concrete examples of state-transition sequences and information-hiding mechanisms for representative tasks from each class, along with a brief verification procedure used during dataset generation. These additions confirm that single-turn solutions are not feasible without interaction. revision: yes
-
Referee: [§4.3] §4.3 (Error Analysis): The results section reports aggregate performance shortfalls but lacks a per-task or per-class breakdown of failure modes (e.g., state-tracking errors vs. instruction-following errors), making it difficult to confirm that the central claim about interactive reasoning limitations is supported by the data.
Authors: We agree that granular failure-mode analysis strengthens the central claim. The original manuscript presented aggregate metrics across all 3600 instances. In the revision we have expanded §4.3 with a per-class breakdown of error types, obtained by manually categorizing a stratified sample of 200 failures per class into state-tracking, instruction-following, and higher-level reasoning errors. The results show that state-tracking and interaction errors dominate even for the strongest models, directly supporting our conclusions about limitations in interactive reasoning. revision: yes
Circularity Check
No circularity: new benchmark and empirical evaluation are self-contained
full rationale
The paper introduces MTR-Bench as a new dataset (4 classes, 40 tasks, 3600 instances) and fully-automated construction/evaluation framework. Its central claim—that cutting-edge models fall short on multi-turn interactive reasoning—rests on running existing LLMs against this freshly constructed benchmark rather than any derivation, fitted parameter, or self-citation chain. No equations, uniqueness theorems, or ansatzes are invoked; the work is empirical and the automated pipeline is presented as an independent methodological contribution. The derivation chain therefore contains no self-definitional, fitted-input, or load-bearing self-citation steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Single-turn evaluations are insufficient for assessing complex interactive reasoning in LLMs
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MTR-Bench features fully-automated framework spanning both dataset constructions and model evaluations... Generator (P) creates interactive problems... Monitor (M) generates feedback... Evaluator (E) assesses multi-turn interactions
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Comprising 4 classes, 40 tasks, and 3600 instances... necessitates multi-turn interactions with the environments
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 2 Pith papers
-
EMSDialog: Synthetic Multi-person Emergency Medical Service Dialogue Generation from Electronic Patient Care Reports via Multi-LLM Agents
EMSDialog is a dataset of 4,414 synthetic multi-speaker EMS dialogues generated by a multi-LLM agent pipeline grounded in ePCR reports, annotated with diagnoses, roles, and topics, and shown to improve accuracy, timel...
-
FACT-E: Causality-Inspired Evaluation for Trustworthy Chain-of-Thought Reasoning
FACT-E uses controlled perturbations as an instrumental signal to measure intra-chain faithfulness in CoT reasoning and combines it with answer consistency to select trustworthy trajectories.
Reference graph
Works this paper leans on
-
[1]
https://mistral.ai/news/mistral-small-3
Mistral AI. https://mistral.ai/news/mistral-small-3. Hugging Face, 2025
work page 2025
-
[2]
Anurag Ajay, Seungwook Han, Yilun Du, Shuang Li, Abhi Gupta, Tommi S. Jaakkola, Joshua B. Tenenbaum, Leslie Pack Kaelbling, Akash Srivastava, and Pulkit Agrawal. Compositional foun- dation models for hierarchical planning. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[3]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[4]
Self-playing adversarial language game enhances LLM reasoning
Pengyu Cheng, Tianhao Hu, Han Xu, Zhisong Zhang, Yong Dai, Lei Han, nan du, and Xiaolong Li. Self-playing adversarial language game enhances LLM reasoning. In The Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[5]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems. CoRR, abs/2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[6]
Selection-inference: Exploiting large language models for interpretable logical reasoning
Antonia Creswell, Murray Shanahan, and Irina Higgins. Selection-inference: Exploiting large language models for interpretable logical reasoning. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[7]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[9]
Simeng Han, Hailey Schoelkopf, Yilun Zhao, Zhenting Qi, Martin Riddell, Wenfei Zhou, James Coady, David Peng, Yujie Qiao, Luke Benson, Lucy Sun, Alexander Wardle-Solano, Hannah Szabó, Ekaterina Zubova, Matthew Burtell, Jonathan Fan, Yixin Liu, Brian Wong, Malcolm Sailor, Ansong Ni, Linyong Nan, Jungo Kasai, Tao Yu, Rui Zhang, Alexander R. Fabbri, Wojciech...
work page 2024
-
[10]
Human-like property induction is a challenge for large language models
Simon Jerome Han, Keith James Ransom, Andrew Perfors, and Charles Kemp. Human-like property induction is a challenge for large language models. In Jennifer Culbertson, Hugh Rabagliati, Verónica C. Ramenzoni, and Andrew Perfors, editors, Proceedings of the 44th Annual Meeting of the Cognitive Science Society, CogSci 2022, Toronto, ON, Canada, July 27-30, 2...
work page 2022
-
[11]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
work page 2021
-
[12]
Gamearena: Evaluating LLM reasoning through live computer games
Lanxiang Hu, Qiyu Li, Anze Xie, Nan Jiang, Ion Stoica, Haojian Jin, and Hao Zhang. Gamearena: Evaluating LLM reasoning through live computer games. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[13]
Towards reasoning in large language models: A survey
Jie Huang and Kevin Chen-Chuan Chang. Towards reasoning in large language models: A survey. In Anna Rogers, Jordan L. Boyd-Graber, and Naoaki Okazaki, editors, Findings of the Association for Computational Linguistics: ACL 2023, Toronto, Canada, July 9-14, 2023, pages 1049–1065. Association for Computational Linguistics, 2023
work page 2023
-
[14]
Language models as zero- shot planners: Extracting actionable knowledge for embodied agents
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. Language models as zero- shot planners: Extracting actionable knowledge for embodied agents. In Kamalika Chaudhuri, Stefanie Jegelka, Le Song, Csaba Szepesvári, Gang Niu, and Sivan Sabato, editors,International Conference on Machine Learning, ICML 2022, 17-23 July 2022, Baltimore, Maryland, U...
work page 2022
-
[15]
Aaron Hurst, Adam Lerer, Adam P. Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, Aleksander Madry, Alex Baker- Whitcomb, Alex Beutel, Alex Borzunov, Alex Carney, Alex Chow, Alex Kirillov, Alex Nichol, Alex Paino, Alex Renzin, Alex Tachard Passos, Alexander Kirillov, Alexi Christakis, Alexis Conneau...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Aaron Jaech, Adam Kalai, Adam Lerer, Adam Richardson, Ahmed El-Kishky, Aiden Low, Alec Helyar, Aleksander Madry, Alex Beutel, Alex Carney, Alex Iftimie, Alex Karpenko, 11 Alex Tachard Passos, Alexander Neitz, Alexander Prokofiev, Alexander Wei, Allison Tam, Ally Bennett, Ananya Kumar, Andre Saraiva, Andrea Vallone, Andrew Duberstein, Andrew Kondrich, Andr...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[17]
Livecodebench: Holistic and contamination free evaluation of large language models for code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[18]
Maieutic prompting: Logically consistent reasoning with recursive explanations
Jaehun Jung, Lianhui Qin, Sean Welleck, Faeze Brahman, Chandra Bhagavatula, Ronan Le Bras, and Yejin Choi. Maieutic prompting: Logically consistent reasoning with recursive explanations. In Yoav Goldberg, Zornitsa Kozareva, and Yue Zhang, editors,Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, EMNLP 2022, Abu Dhabi,...
work page 2022
-
[19]
Understanding the effects of RLHF on LLM generalisation and diversity
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. Understanding the effects of RLHF on LLM generalisation and diversity. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[20]
Xiaoyuan Li, Moxin Li, Rui Men, Yichang Zhang, Keqin Bao, Wenjie Wang, Fuli Feng, Dayiheng Liu, and Junyang Lin. Hellaswag-pro: A large-scale bilingual benchmark for evaluating the robustness of llms in commonsense reasoning. arXiv preprint arXiv:2502.11393, 2025
-
[21]
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, and Fuli Feng. Evaluating mathematical reasoning of large language models: A focus on error identification and correction. In Findings of the Association for Computational Linguistics ACL 2024, pages 11316–11360, 2024
work page 2024
-
[22]
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[23]
Logiqa: A challenge dataset for machine reading comprehension with logical reasoning
Jian Liu, Leyang Cui, Hanmeng Liu, Dandan Huang, Yile Wang, and Yue Zhang. Logiqa: A challenge dataset for machine reading comprehension with logical reasoning. In Christian Bessiere, editor, Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence, IJCAI 2020, pages 3622–3628. ijcai.org, 2020
work page 2020
-
[24]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, and Abhinav Rastogi. Improve mathematical reasoning in language models by automated process supervision. CoRR, abs/2406.06592, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
A LLM benchmark based on the minecraft builder dialog agent task
Chris Madge and Massimo Poesio. A LLM benchmark based on the minecraft builder dialog agent task. CoRR, abs/2407.12734, 2024
-
[26]
A property induction framework for neural language models
Kanishka Misra, Julia Rayz, and Allyson Ettinger. A property induction framework for neural language models. In Jennifer Culbertson, Hugh Rabagliati, Verónica C. Ramenzoni, and Andrew Perfors, editors, Proceedings of the 44th Annual Meeting of the Cognitive Science 12 Society, CogSci 2022, Toronto, ON, Canada, July 27-30, 2022 . cognitivesciencesociety.org, 2022
work page 2022
-
[27]
Benchmark agreement testing done right: A guide for LLM benchmark evaluation
Yotam Perlitz, Ariel Gera, Ofir Arviv, Asaf Yehudai, Elron Bandel, Eyal Shnarch, Michal Shmueli-Scheuer, and Leshem Choshen. Benchmark agreement testing done right: A guide for LLM benchmark evaluation. CoRR, abs/2407.13696, 2024
-
[28]
NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark
Oscar Sainz, Jon Ander Campos, Iker García-Ferrero, Julen Etxaniz, Oier Lopez de Lacalle, and Eneko Agirre. NLP evaluation in trouble: On the need to measure LLM data contamination for each benchmark. In Houda Bouamor, Juan Pino, and Kalika Bali, editors, Findings of the Association for Computational Linguistics: EMNLP 2023, Singapore, December 6-10, 2023...
work page 2023
-
[29]
Language models are greedy reasoners: A systematic formal anal- ysis of chain-of-thought
Abulhair Saparov and He He. Language models are greedy reasoners: A systematic formal anal- ysis of chain-of-thought. In The Eleventh International Conference on Learning Representations, 2023
work page 2023
-
[30]
Encyclopedia of the Sciences of Learning
Norbert M Seel. Encyclopedia of the Sciences of Learning. Springer Science & Business Media, 2011
work page 2011
-
[31]
Commonsenseqa: A question answering challenge targeting commonsense knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. In Jill Burstein, Christy Doran, and Thamar Solorio, editors, Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAAC...
work page 2019
-
[32]
Gemma Team, Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[33]
M.-A-P. Team, Xinrun Du, Yifan Yao, Kaijing Ma, Bingli Wang, Tianyu Zheng, Kang Zhu, Minghao Liu, Yiming Liang, Xiaolong Jin, Zhenlin Wei, Chujie Zheng, Kaixin Deng, Shian Jia, Sichao Jiang, Yiyan Liao, Rui Li, Qinrui Li, Sirun Li, Yizhi Li, Yunwen Li, Dehua Ma, Yuansheng Ni, Haoran Que, Qiyao Wang, Zhoufutu Wen, Siwei Wu, Tianshun Xing, Ming Xu, Zhenzhu ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Qwq: Reflect deeply on the boundaries of the unknown
Qwen Team. Qwq: Reflect deeply on the boundaries of the unknown. Hugging Face, 2024
work page 2024
-
[35]
Oguzhan Topsakal, Colby Jacob Edell, and Jackson Bailey Harper. Evaluating large language models with grid-based game competitions: An extensible LLM benchmark and leaderboard. CoRR, abs/2407.07796, 2024
-
[36]
On the planning abilities of large language models - a critical investigation
Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. On the planning abilities of large language models - a critical investigation. In Thirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[37]
MINT: Evaluating LLMs in multi-turn interaction with tools and language feedback
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. MINT: Evaluating LLMs in multi-turn interaction with tools and language feedback. In The Twelfth International Conference on Learning Representations, 2024. 13
work page 2024
-
[38]
Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus
Jason Wei, Yi Tay, Rishi Bommasani, Colin Raffel, Barret Zoph, Sebastian Borgeaud, Dani Yogatama, Maarten Bosma, Denny Zhou, Donald Metzler, Ed H. Chi, Tatsunori Hashimoto, Oriol Vinyals, Percy Liang, Jeff Dean, and William Fedus. Emergent abilities of large language models. Transactions on Machine Learning Research, 2022. Survey Certification
work page 2022
-
[39]
Smartplay : A benchmark for LLMs as intelligent agents
Yue Wu, Xuan Tang, Tom Mitchell, and Yuanzhi Li. Smartplay : A benchmark for LLMs as intelligent agents. In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[40]
Zelai Xu, Chao Yu, Fei Fang, Yu Wang, and Yi Wu
Yuzhuang Xu, Shuo Wang, Peng Li, Fuwen Luo, Xiaolong Wang, Weidong Liu, and Yang Liu. Exploring large language models for communication games: An empirical study on werewolf. CoRR, abs/2309.04658, 2023
-
[41]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li, Tingyu X...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[42]
Language models as inductive reasoners
Zonglin Yang, Li Dong, Xinya Du, Hao Cheng, Erik Cambria, Xiaodong Liu, Jianfeng Gao, and Furu Wei. Language models as inductive reasoners. In Yvette Graham and Matthew Purver, editors, Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics, EACL 2024 - Volume 1: Long Papers, St. Julian’s, Malta, March ...
work page 2024
-
[43]
Physics of language models: Part 2.1, grade-school math and the hidden reasoning process
Tian Ye, Zicheng Xu, Yuanzhi Li, and Zeyuan Allen-Zhu. Physics of language models: Part 2.1, grade-school math and the hidden reasoning process. In The Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[44]
Hellaswag: Can a machine really finish your sentence? In Anna Korhonen, David R
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? In Anna Korhonen, David R. Traum, and Lluís Màrquez, editors, Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, July 28- August 2, 2019, Volume 1: Long Papers, pages 479...
work page 2019
-
[45]
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena. In Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2023. 14 A Multi-Turn R...
work page 2023
-
[46]
Some players are impostors (k) and others are crewmates (n − k)
-
[47]
The number of impostors k is between 1/3n and 2/3n Query Types:
-
[48]
Ask about three players: Format: “My Query: a, b, c” (three different player numbers) Response will be: - 0: if there are more impostors than crewmates among these three - 1: if there are more crewmates or equal numbers - -1: if query is invalid
-
[49]
Submit final answer: Format: “My Answer: x1, x2, ..., xk” (k is number of impostors, followed by their indices) Response will be: - 0 if incorrect - 1 if correct Example interaction: You: “My Query: 1,2,3” Me: “0” (means more impostors in this group) You: “My Query: 3,4,5” Me: “1” (means more crewmates in this group) You: “My Answer: 1,2,3,4” Me: 1 (if co...
-
[51]
Format your responses exactly as shown above Remember: - Player numbers must be between 1 and n - All three numbers in a query must be different Ready to start? Make your first query! Case D.2: FindTheImpostors Difficulty Levels Easy: n = 6, Medium: n = 9, Hard: n = 12 GuessMax In this task, models need to discover a hidden password by querying maximum va...
-
[52]
Hidden array A[1...50] contains numbers from 1 to 50
-
[53]
You need to guess n numbers forming the password
-
[54]
For password position i, you are given Si = subset of positions to exclude
-
[55]
Password[i] = max value among all positions EXCEPT those in Si Your subsets are: {subset desc} Password Example: For x = 4, n = 2, if: S1 = {1, 3}, S2 = {2, 4} And hidden array A = [3, 1, 2, 4] Then: - Password[1] ignores positions 1, 3 (S1) So looks at A[2] = 1 , A[4] = 4 Password[1] = 4 - Password[2] ignores positions 2, 4 (S2) 16 So looks at A[1] = 3 ,...
-
[56]
Make a query: Format: “My Query: x1 x2 ... xm” where: - xi = positions you want to query (1 ≤ m < 50) - You’ll receive the maximum value at these positions
-
[57]
Submit final answer: Format: “My Answer: p1 p2 ... pn” where: - pi = your guess for each password slot - You’ll receive “Correct” or “Incorrect” Simple Example Interaction: Given: x = 4, n = 2, S1 = {1, 3}, S2 = {2, 4}, A = [3, 1, 2, 4](hidden), Answer = [4, 3](hidden) You: “My Query: 2 4” Me: “4” You: “My Query: 1 3” Me: “3” You: “My Answer: 4 3” Me: “Co...
-
[60]
Explain your reasoning before each query Remember: - Each query reveals maximum value at specified positions - Password digits come from complementary position sets - Think carefully about which positions to query Ready to start? Make your first query! Case D.4: GuessMax Difficulty Levels Easy: n = 7, Medium: n = 10, Hard: n = 16 CircleFinding In this tas...
-
[61]
There is a hidden circle with center (xc, yc) and radius rc
-
[62]
All parameters are integers and |xc|, |yc|, |rc| ≤ { n}
-
[63]
The radius rc satisfies: 1 ≤ rc ≤ p x2c + y2c − 1
-
[64]
You can shoot rays from origin (0, 0) through any point (xq, yq) you specify Query Types:
-
[65]
To shoot a ray: Format: “My Query: (xq, yq) ” where: - xq, yq are integers with |xq|, |yq| ≤ { n} - At least one of xq or yq must be non-zero 17 Example: “My Query: 0 -10” You’ll receive the minimum distance from the ray to the circle (0.0 if the ray intersects the circle)
-
[66]
To submit final answer: Format: “My Answer: xc yc rc” where xc, yc, rc are the circle’s parameters Example: “My Answer: 20 10 10” You’ll receive the correctness of your answer. Instructions:
-
[70]
All distances are precise to 10−10 Remember: - Circle parameters are integers - Rays start from origin (0, 0) - Think carefully about ray directions - Use geometric properties to deduce circle location - Distance is 0 when ray intersects circle Ready to start? Make your first query! Case D.6: CircleFinding Difficulty Levels Easy: n = 200, Medium: n = 1000...
-
[71]
There is a hidden permutation of {n} numbers (0 to {n − 1})
-
[72]
Each position contains a unique number from 0 to {n − 1}
-
[73]
You can make comparison queries between OR operations: - Each query compares (a | b) with (c | d) - | denotes bitwise OR operation - You’ll receive “<”, “=”, or “>” as response Query Types:
-
[74]
To make a comparison query: Format: “My Query: a b c d ” where: - a, b, c, d are positions in array (0-based indexing) Example: “My Query: 0 2 3 1” Response will be one of: “<”, “=”, “>”
-
[75]
To submit final answer: Format: “My Answer: i j” where i and j are the positions with maximum XOR value Example: “My Answer: 3 2” Instructions:
-
[76]
Make queries based on previous comparisons
-
[78]
Explain your reasoning before each query Remember: 18 - All positions contain unique numbers from 0 to {n − 1} - Position indices start from 0 - Think carefully about which positions to compare - Use your queries wisely to find maximum XOR pair Ready to start? Make your first query! Case D.8: BitCompare Difficulty Levels Easy: n = 5, Medium: n = 7, Hard: ...
-
[79]
There is a hidden tree with n vertices (numbered 1 to n)
-
[80]
You can ask questions to discover the tree’s structure
-
[81]
For each question, you need to specify: - Set S: A group of vertices (at least one vertex) - Set T : Another group of vertices (at least one vertex) - Vertex v: Any vertex you choose Note: S and T must not have any common vertices Query Types:
-
[82]
To make a query: Format: “My Query: S | T | v” where: - S is your first set of vertices (space-separated numbers) - T is your second set of vertices (space-separated numbers) - v is the vertex you want to check Example: “My Query: 1 2 | 3 | 2” Response: You will receive the number of vertex pairs(s, t) where: - s is from set S - t is from set T - The path...
-
[83]
To submit final answer: Format: “My Answer: edge1 edge2 ...” where each edge is “u-v” Example: “My Answer: 1-2 2-3” Example Interaction: You: “My Query: 1 2 | 3 | 2” Me: “2” (meaning 2 paths through vertex 2) Instructions:
-
[84]
Use queries to gather information about the tree
-
[85]
Format your queries exactly as shown above
-
[86]
Think carefully about which vertices to select Remember: - Sets S and T must be non-empty and disjoint - Use your queries wisely to gather maximum information - Each edge in final answer should appear exactly once Ready to start? Make your first query! Case D.10: TreeDiscovery Difficulty Levels Easy: n = 5, Medium: n = 6, Hard: n = 7 19 LinkedListQuery In...
-
[87]
There is a hidden sorted linked list with n elements
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.