Improving Adversarial Transferability on Vision-Language Pre-training Models via Surrogate-Specific Bias Correction
Pith reviewed 2026-06-27 13:44 UTC · model grok-4.3
The pith
Correcting surrogate-specific bias via a reference gradient on weak-semantic images improves adversarial transferability across vision-language pre-training models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
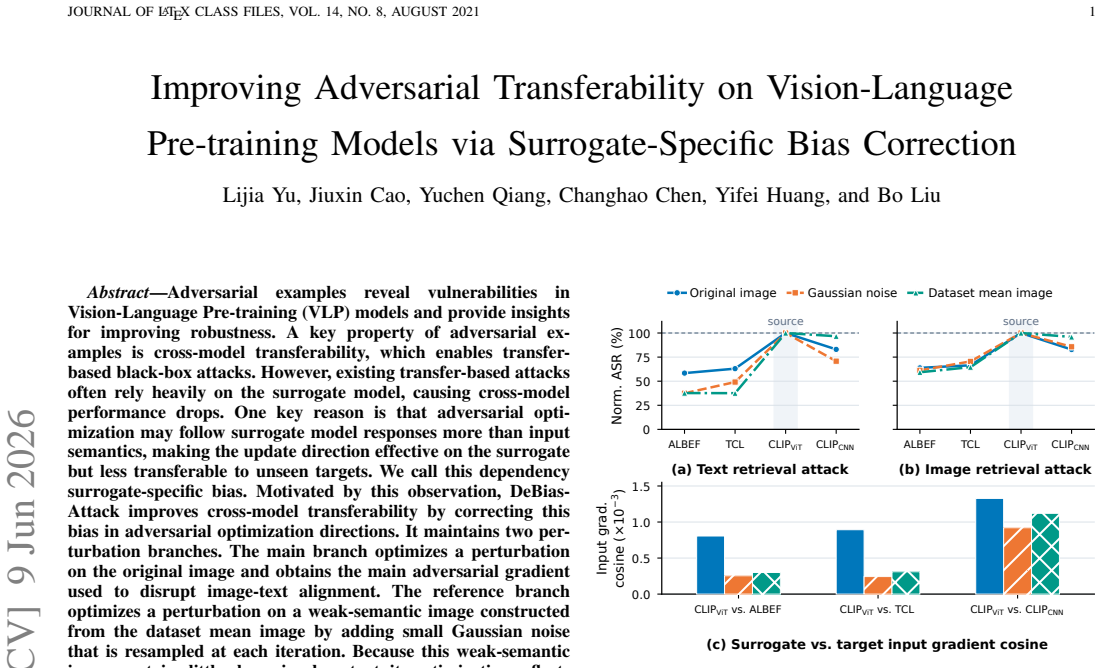
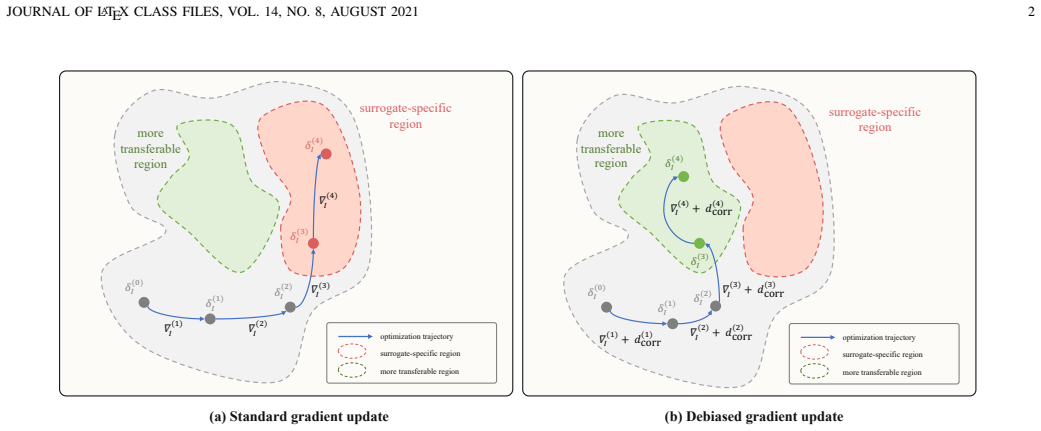
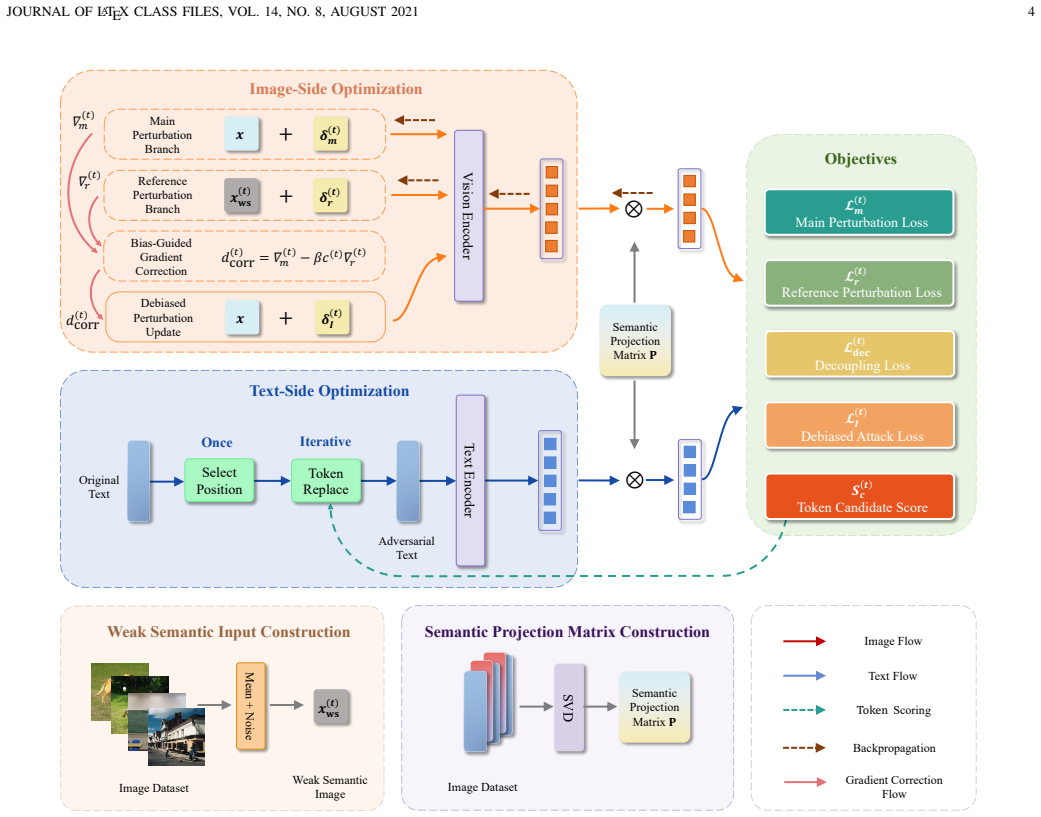
DeBias-Attack is the first transfer-based VLP attack that corrects surrogate-specific bias through gradient correction: it removes the component of the main adversarial gradient that aligns with the reference gradient obtained from a weak-semantic image, thereby producing perturbations whose optimization direction depends less on the surrogate and more on image semantics.
What carries the argument
The reference gradient computed on a weak-semantic image (dataset mean plus resampled Gaussian noise), used to estimate and subtract surrogate-specific bias from the main gradient via projection removal.
If this is right
- Perturbations transfer more reliably to unseen VLP models and downstream tasks.
- The same corrected gradients remain effective against both open-source and closed-source multimodal large language models.
- Context-aware text substitution applied after image perturbation further strengthens the attack.
Where Pith is reading between the lines
- The same two-branch correction could be tested on non-VLP vision or language models to check whether surrogate bias is a broader phenomenon.
- Alternative constructions for the weak-semantic reference image might isolate bias more cleanly than dataset mean plus noise.
- The method suggests that explicit bias estimation steps could become standard in black-box attack pipelines for multimodal systems.
Load-bearing premise
The optimization direction found on the weak-semantic image captures surrogate-specific bias rather than any leftover image semantics.
What would settle it
If attack success rates on held-out target models show no improvement when the projection subtraction step is included versus a standard single-branch baseline, the claimed benefit of bias correction would be refuted.
Figures

read the original abstract
Adversarial examples reveal vulnerabilities in Vision-Language Pre-training (VLP) models and provide insights for improving robustness. A key property is cross-model transferability, which enables transfer-based black-box attacks. However, existing attacks often rely heavily on the surrogate model, causing cross-model performance drops. One reason is that adversarial optimization may follow surrogate model responses more than input semantics, making the update direction effective on the surrogate but less transferable to unseen targets. We refer to this dependency as surrogate-specific bias. Motivated by this observation, DeBias-Attack improves transferability by correcting surrogate-specific bias in adversarial optimization directions. It maintains two perturbation branches. The main branch optimizes a perturbation on the original image and obtains the adversarial gradient used to disrupt image-text alignment. The reference branch optimizes a perturbation on a weak-semantic image constructed from the dataset mean image with small Gaussian noise resampled at each iteration. Since this weak-semantic image contains little clear visual content, its optimization reflects surrogate responses more than image semantics, and its reference gradient estimates surrogate-specific bias. DeBias-Attack removes the aligned projection of the main gradient on the reference gradient before updating the adversarial image, then performs context-aware text substitution using the updated adversarial image. DeBias-Attack is the first transfer-based VLP attack that corrects surrogate-specific bias through gradient correction. Experiments show strong performance across VLP models, downstream tasks, and open-source and closed-source multimodal large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DeBias-Attack, a transfer-based black-box adversarial attack method for Vision-Language Pre-training (VLP) models. It maintains two perturbation branches during optimization: a main branch that computes the adversarial gradient on the original image to disrupt image-text alignment, and a reference branch that computes a gradient on a weak-semantic image (dataset mean image plus per-iteration resampled Gaussian noise). The method subtracts the aligned projection of the main gradient onto the reference gradient to correct for surrogate-specific bias, followed by context-aware text substitution. The paper claims this is the first such gradient-correction approach for VLP attacks and reports strong performance across VLP models, downstream tasks, and both open- and closed-source multimodal LLMs.
Significance. If the central mechanism is shown to reliably isolate and remove only non-transferable surrogate bias without degrading semantic attack directions, the work would provide a concrete algorithmic advance in improving cross-model transferability for multimodal adversarial attacks. This could strengthen robustness evaluations for VLP and MLLM systems. The approach introduces no additional free parameters beyond standard attack hyperparameters and relies on an explicit gradient-projection step rather than learned components.
major comments (1)
- [Method description (DeBias-Attack)] The load-bearing assumption that the reference gradient obtained on the weak-semantic image (dataset mean plus resampled Gaussian noise) primarily captures surrogate-specific bias rather than residual image semantics is not supported by a derivation or targeted ablation. The method description asserts that this input 'contains little clear visual content' so its gradient 'reflects surrogate responses more than image semantics,' but provides no argument establishing orthogonality to transferable semantic directions or showing that the projection step cannot inadvertently remove useful components of the main gradient. This directly affects the claim that the correction improves transferability.
minor comments (1)
- [Abstract] The abstract asserts 'strong performance' and 'strong experimental results' without any quantitative numbers, baseline comparisons, or error bars; the full manuscript should include these in the experimental section for evaluability.
Simulated Author's Rebuttal
We thank the referee for the thoughtful review and the opportunity to address the concerns raised regarding the justification of DeBias-Attack. We respond to the major comment below and outline planned revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: The load-bearing assumption that the reference gradient obtained on the weak-semantic image (dataset mean plus resampled Gaussian noise) primarily captures surrogate-specific bias rather than residual image semantics is not supported by a derivation or targeted ablation. The method description asserts that this input 'contains little clear visual content' so its gradient 'reflects surrogate responses more than image semantics,' but provides no argument establishing orthogonality to transferable semantic directions or showing that the projection step cannot inadvertently remove useful components of the main gradient. This directly affects the claim that the correction improves transferability.
Authors: We agree that the current manuscript presents the motivation for the reference branch primarily through intuition rather than a formal derivation or targeted ablation, and that this leaves open questions about whether the reference gradient is dominated by surrogate-specific bias and whether the projection step preserves transferable semantic directions. In the revised version, we will expand the method description with a more explicit argument based on the construction of the weak-semantic image (dataset mean plus per-iteration noise) and its expected lack of semantic alignment with the original input. We will also add a new ablation subsection that (i) measures the alignment of the reference gradient with gradients obtained from images containing varying degrees of semantic content and (ii) reports the effect of the projection on both surrogate and target-model attack success rates to show that transferable directions are retained. These additions will directly address the concern about inadvertent removal of useful gradient components. revision: yes
Circularity Check
No significant circularity; method is a defined heuristic without reduction to inputs
full rationale
The paper introduces DeBias-Attack as a two-branch gradient correction procedure whose core step (subtracting the aligned projection of the main-branch gradient onto the reference-branch gradient) is explicitly constructed from the algorithm's own definitions rather than derived from or equivalent to any fitted parameter, self-citation chain, or prior result. The justification rests on an empirical assumption about the weak-semantic reference image, but this assumption is stated openly and does not create a self-referential loop in the equations or claims. No load-bearing uniqueness theorem, ansatz smuggling, or renaming of known results appears. The derivation is therefore self-contained as an algorithmic proposal.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Align before fuse: Vision and language representation learning with momentum distillation,
J. Li, R. Selvaraju, A. Gotmare, S. Joty, C. Xiong, and S. C. H. Hoi, “Align before fuse: Vision and language representation learning with momentum distillation,”Advances in neural information processing systems, vol. 34, pp. 9694–9705, 2021
2021
-
[2]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,
J. Li, D. Li, C. Xiong, and S. Hoi, “Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation,” inInternational conference on machine learning. PMLR, 2022, pp. 12 888–12 900
2022
-
[3]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inInternational conference on machine learning. PMLR, 2023, pp. 19 730–19 742
2023
-
[4]
Towards deep learning models resistant to adversarial attacks,
A. Madry, A. Makelov, L. Schmidt, D. Tsipras, and A. Vladu, “Towards deep learning models resistant to adversarial attacks,”arXiv preprint arXiv:1706.06083, 2017
Pith/arXiv arXiv 2017
-
[5]
Set-level guidance attack: Boosting adversarial transferability of vision-language pre-training models,
D. Lu, Z. Wang, T. Wang, W. Guan, H. Gao, and F. Zheng, “Set-level guidance attack: Boosting adversarial transferability of vision-language pre-training models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 102–111
2023
-
[6]
Explaining and harnessing adversarial examples,
I. J. Goodfellow, J. Shlens, and C. Szegedy, “Explaining and harnessing adversarial examples,”arXiv preprint arXiv:1412.6572, 2014
Pith/arXiv arXiv 2014
-
[7]
Bert-attack: Adversarial attack against bert using bert,
L. Li, R. Ma, Q. Guo, X. Xue, and X. Qiu, “Bert-attack: Adversarial attack against bert using bert,” inProceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020, pp. 6193–6202
2020
-
[8]
Vision-language pre-training with triple contrastive learning,
J. Yang, J. Duan, S. Tran, Y . Xu, S. Chanda, L. Chen, B. Zeng, T. Chilimbi, and J. Huang, “Vision-language pre-training with triple contrastive learning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 15 671–15 680
2022
-
[9]
A survey on transferability of adversarial examples across deep neural networks,
J. Gu, X. Jia, P. de Jorge, W. Yu, X. Liu, A. Ma, Y . Xun, A. Hu, A. Khakzar, Z. Li, X. Cao, and P. Torr, “A survey on transferability of adversarial examples across deep neural networks,” Transactions on Machine Learning Research, 2024. [Online]. Available: https://openreview.net/forum?id=AYJ3m7BocI
2024
-
[10]
Towards adversarial attack on vision- language pre-training models,
J. Zhang, Q. Yi, and J. Sang, “Towards adversarial attack on vision- language pre-training models,” inProceedings of the 30th ACM Inter- national Conference on Multimedia, 2022, pp. 5005–5013
2022
-
[11]
An image is worth 1000 lies: Adversarial transferability across prompts on vision-language models,
H. Luo, J. Gu, F. Liu, and P. Torr, “An image is worth 1000 lies: Adversarial transferability across prompts on vision-language models,” arXiv preprint arXiv:2403.09766, 2024
arXiv 2024
-
[12]
Dual attention suppression attack: Generate adversarial camouflage in physical world,
J. Wang, A. Liu, Z. Yin, S. Liu, S. Tang, and X. Liu, “Dual attention suppression attack: Generate adversarial camouflage in physical world,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 8565–8574
2021
-
[13]
Enhancing the transferability of adversarial examples with random patch
Y . Zhang, Y .-a. Tan, T. Chen, X. Liu, Q. Zhang, and Y . Li, “Enhancing the transferability of adversarial examples with random patch.” inIJCAI, vol. 8, 2022, p. 13
2022
-
[14]
Z. Zhao, H. Zhang, R. Li, R. Sicre, L. Amsaleg, M. Backes, Q. Li, and C. Shen, “Revisiting transferable adversarial image examples: Attack categorization, evaluation guidelines, and new insights,”arXiv preprint arXiv:2310.11850, 2023
arXiv 2023
-
[15]
Gen- erating transferable adversarial examples against vision transformers,
Y . Wang, J. Wang, Z. Yin, R. Gong, J. Wang, A. Liu, and X. Liu, “Gen- erating transferable adversarial examples against vision transformers,” in Proceedings of the 30th ACM International Conference on Multimedia, 2022, pp. 5181–5190
2022
-
[16]
Feature importance-aware transferable adversarial attacks,
Z. Wang, H. Guo, Z. Zhang, W. Liu, Z. Qin, and K. Ren, “Feature importance-aware transferable adversarial attacks,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 7639– 7648
2021
-
[17]
On success and simplicity: A second look at transferable targeted attacks,
Z. Zhao, Z. Liu, and M. Larson, “On success and simplicity: A second look at transferable targeted attacks,”Advances in Neural Information Processing Systems, vol. 34, pp. 6115–6128, 2021
2021
-
[18]
Why do adversarial attacks transfer? explaining transferability of evasion and poisoning attacks,
A. Demontis, M. Melis, M. Pintor, M. Jagielski, B. Biggio, A. Oprea, C. Nita-Rotaru, and F. Roli, “Why do adversarial attacks transfer? explaining transferability of evasion and poisoning attacks,” in28th USENIX security symposium (USENIX security 19), 2019, pp. 321–338
2019
-
[19]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inInternational conference on machine learning. PMLR, 2021, pp. 8748–8763
2021
-
[20]
An image is worth 16x16 words: Transformers for image recognition at scale,
A. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[21]
Uniter: Universal image-text representation learning,
Y .-C. Chen, L. Li, L. Yu, A. El Kholy, F. Ahmed, Z. Gan, Y . Cheng, and J. Liu, “Uniter: Universal image-text representation learning,” in European conference on computer vision. Springer, 2020, pp. 104– 120
2020
-
[22]
Lxmert: Learning cross-modality encoder representations from transformers,
H. Tan and M. Bansal, “Lxmert: Learning cross-modality encoder representations from transformers,”arXiv preprint arXiv:1908.07490, 2019
arXiv 1908
-
[23]
Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,
J. Lu, D. Batra, D. Parikh, and S. Lee, “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks,”Advances in neural information processing systems, vol. 32, 2019
2019
-
[24]
Improving visual grounding with visual-linguistic verification and iterative reasoning,
L. Yang, Y . Xu, C. Yuan, W. Liu, B. Li, and W. Hu, “Improving visual grounding with visual-linguistic verification and iterative reasoning,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 9499–9508
2022
-
[25]
Seqtr: A simple yet universal network for visual grounding,
C. Zhu, Y . Zhou, Y . Shen, G. Luo, X. Pan, M. Lin, C. Chen, L. Cao, X. Sun, and R. Ji, “Seqtr: A simple yet universal network for visual grounding,” inEuropean Conference on Computer Vision. Springer, 2022, pp. 598–615
2022
-
[26]
Transvg: End-to-end visual grounding with transformers,
J. Deng, Z. Yang, T. Chen, W. Zhou, and H. Li, “Transvg: End-to-end visual grounding with transformers,” inProceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 1769–1779
2021
-
[27]
A compre- hensive survey of deep learning for image captioning,
M. Z. Hossain, F. Sohel, M. F. Shiratuddin, and H. Laga, “A compre- hensive survey of deep learning for image captioning,”ACM Computing Surveys (CsUR), vol. 51, no. 6, pp. 1–36, 2019
2019
-
[28]
Meacap: Memory-augmented zero-shot image captioning,
Z. Zeng, Y . Xie, H. Zhang, C. Chen, B. Chen, and Z. Wang, “Meacap: Memory-augmented zero-shot image captioning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 14 100–14 110
2024
-
[29]
From recognition to cogni- tion: Visual commonsense reasoning,
R. Zellers, Y . Bisk, A. Farhadi, and Y . Choi, “From recognition to cogni- tion: Visual commonsense reasoning,” inProceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2019, pp. 6720– 6731
2019
-
[30]
Beyond boundaries: A comprehensive survey of transferable attacks on ai systems,
G. Wang, C. Zhou, Y . Wang, B. Chen, H. Guo, and Q. Yan, “Beyond boundaries: A comprehensive survey of transferable attacks on ai systems,”arXiv preprint arXiv:2311.11796, 2023
arXiv 2023
-
[31]
Enhancing cross-task black-box transferability of adversarial examples with dispersion reduction,
Y . Lu, Y . Jia, J. Wang, B. Li, W. Chai, L. Carin, and S. Velipasalar, “Enhancing cross-task black-box transferability of adversarial examples with dispersion reduction,” inProceedings of the IEEE/CVF conference on Computer Vision and Pattern Recognition, 2020, pp. 940–949
2020
-
[32]
Cross-task attack: A self-supervision generative framework based on attention shift,
Q. Zeng, Y . Gong, and M. Jiang, “Cross-task attack: A self-supervision generative framework based on attention shift,” in2024 International Joint Conference on Neural Networks (IJCNN). IEEE, 2024, pp. 1–8. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
2024
-
[33]
Semantic-aligned adversarial evolution triangle for high- transferability vision-language attack,
X. Jia, S. Gao, Q. Guo, S. Qin, K. Ma, Y . Huang, Y . Liu, I. Tsang, and X. Cao, “Semantic-aligned adversarial evolution triangle for high- transferability vision-language attack,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 47, no. 10, pp. 8489–8505, 2025
2025
-
[34]
Rethinking model ensemble in transfer-based adversarial attacks,
H. Chen, Y . Zhang, Y . Dong, X. Yang, H. Su, and J. Zhu, “Rethinking model ensemble in transfer-based adversarial attacks,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[35]
J. Fu, Z. Chen, K. Jiang, H. Guo, J. Wang, S. Gao, and W. Zhang, “Improving adversarial transferability of vision-language pre-training models through collaborative multimodal interaction,”arXiv preprint arXiv:2403.10883, 2024
arXiv 2024
-
[36]
Mirrorcheck: Efficient adversarial defense for vision-language models,
S. Fares, K. Ziu, T. Aremu, N. Durasov, M. Tak ´aˇc, P. Fua, K. Nan- dakumar, and I. Laptev, “Mirrorcheck: Efficient adversarial defense for vision-language models,”arXiv preprint arXiv:2406.09250, 2024
Pith/arXiv arXiv 2024
-
[37]
Boosting transferability in vision-language attacks via diversification along the intersection region of adversarial trajectory,
S. Gao, X. Jia, X. Ren, I. Tsang, and Q. Guo, “Boosting transferability in vision-language attacks via diversification along the intersection region of adversarial trajectory,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 442–460
2024
-
[38]
Transferable multimodal attack on vision-language pre-training models,
H. Wang, K. Dong, Z. Zhu, H. Qin, A. Liu, X. Fang, J. Wang, and X. Liu, “Transferable multimodal attack on vision-language pre-training models,” in2024 IEEE Symposium on Security and Privacy (SP). IEEE, 2024, pp. 1722–1740
2024
-
[39]
Gleam: Enhanced transferable ad- versarial attacks for vision-language pre-training models via global- local transformations,
Y . Liu, X. Ouyang, and X. Cui, “Gleam: Enhanced transferable ad- versarial attacks for vision-language pre-training models via global- local transformations,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 1665–1674
2025
-
[40]
Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,
B. A. Plummer, L. Wang, C. M. Cervantes, J. C. Caicedo, J. Hocken- maier, and S. Lazebnik, “Flickr30k entities: Collecting region-to-phrase correspondences for richer image-to-sentence models,” inProceedings of the IEEE international conference on computer vision, 2015, pp. 2641– 2649
2015
-
[41]
Microsoft coco: Common objects in context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Doll ´ar, and C. L. Zitnick, “Microsoft coco: Common objects in context,” inEuropean conference on computer vision. Springer, 2014, pp. 740–755
2014
-
[42]
Modeling context in referring expressions,
L. Yu, P. Poirson, S. Yang, A. C. Berg, and T. L. Berg, “Modeling context in referring expressions,” inEuropean conference on computer vision. Springer, 2016, pp. 69–85
2016
-
[43]
Bleu: a method for automatic evaluation of machine translation,
K. Papineni, S. Roukos, T. Ward, and W.-J. Zhu, “Bleu: a method for automatic evaluation of machine translation,” inProceedings of the 40th annual meeting of the Association for Computational Linguistics, 2002, pp. 311–318
2002
-
[44]
Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,
S. Banerjee and A. Lavie, “Meteor: An automatic metric for mt evalua- tion with improved correlation with human judgments,” inProceedings of the acl workshop on intrinsic and extrinsic evaluation measures for machine translation and/or summarization, 2005, pp. 65–72
2005
-
[45]
Rouge: A package for automatic evaluation of summaries,
C.-Y . Lin, “Rouge: A package for automatic evaluation of summaries,” inText summarization branches out, 2004, pp. 74–81
2004
-
[46]
Cider: Consensus- based image description evaluation,
R. Vedantam, C. Lawrence Zitnick, and D. Parikh, “Cider: Consensus- based image description evaluation,” inProceedings of the IEEE confer- ence on computer vision and pattern recognition, 2015, pp. 4566–4575
2015
-
[47]
Spice: Semantic propositional image caption evaluation,
P. Anderson, B. Fernando, M. Johnson, and S. Gould, “Spice: Semantic propositional image caption evaluation,” inEuropean conference on computer vision. Springer, 2016, pp. 382–398
2016
-
[48]
Reevaluating adversarial examples in natural language,
J. Morris, E. Lifland, J. Lanchantin, Y . Ji, and Y . Qi, “Reevaluating adversarial examples in natural language,” inFindings of the association for computational linguistics: EMNLP 2020, 2020, pp. 3829–3839. Lijia Yureceived the B.S. degree in computer science and technology from Nanchang University, Nanchang, China, in 2023. He is currently pursuing the...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.