Improving Multimodal Reasoning via Worst Dimension Optimization
Pith reviewed 2026-06-27 21:54 UTC · model grok-4.3
The pith
Optimizing the worst dimension in multimodal reasoning prevents stronger factors from concealing failures in weaker ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that by optimizing the worst-performing dimension rather than using averaged rewards, the process reward model can guarantee the validity of the reasoning path across all constraints in multimodal reasoning tasks.
What carries the argument
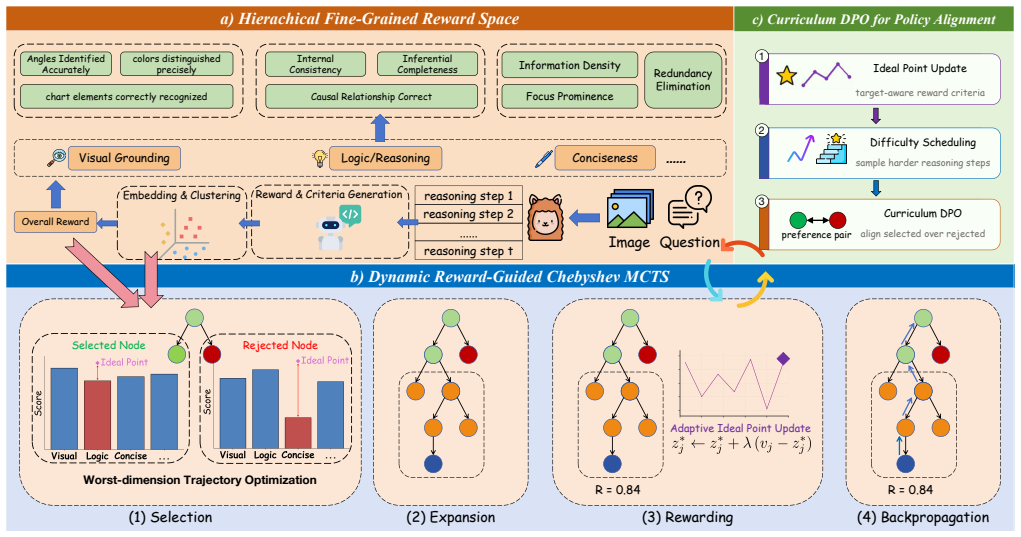
Worst Dimension Optimization, which selects and prioritizes the dimension with the minimum reward score for optimization at each step of the reasoning process.
If this is right
- Reasoning paths will be selected only if all dimensions meet a threshold rather than an average.
- The training of reward models will shift focus to the weakest link in the multimodal chain.
- Multimodal systems will produce fewer outputs with hidden invalid steps.
- Evaluation of reasoning will become more stringent on individual dimensions.
Where Pith is reading between the lines
- This method could be applied to other multi-constraint optimization problems beyond multimodal reasoning.
- It suggests that in reward modeling, min-based optimization might be preferable to mean-based in safety-critical applications.
- Testing on existing multimodal benchmarks could reveal if current models have concealed failures.
Load-bearing premise
That prioritizing the optimization of the single worst dimension will ensure no failures are concealed and the reasoning path is valid across all constraints.
What would settle it
Finding a multimodal reasoning example where the worst dimension is optimized but the path still contains a logical or grounding failure that was not the worst dimension.
Figures
read the original abstract
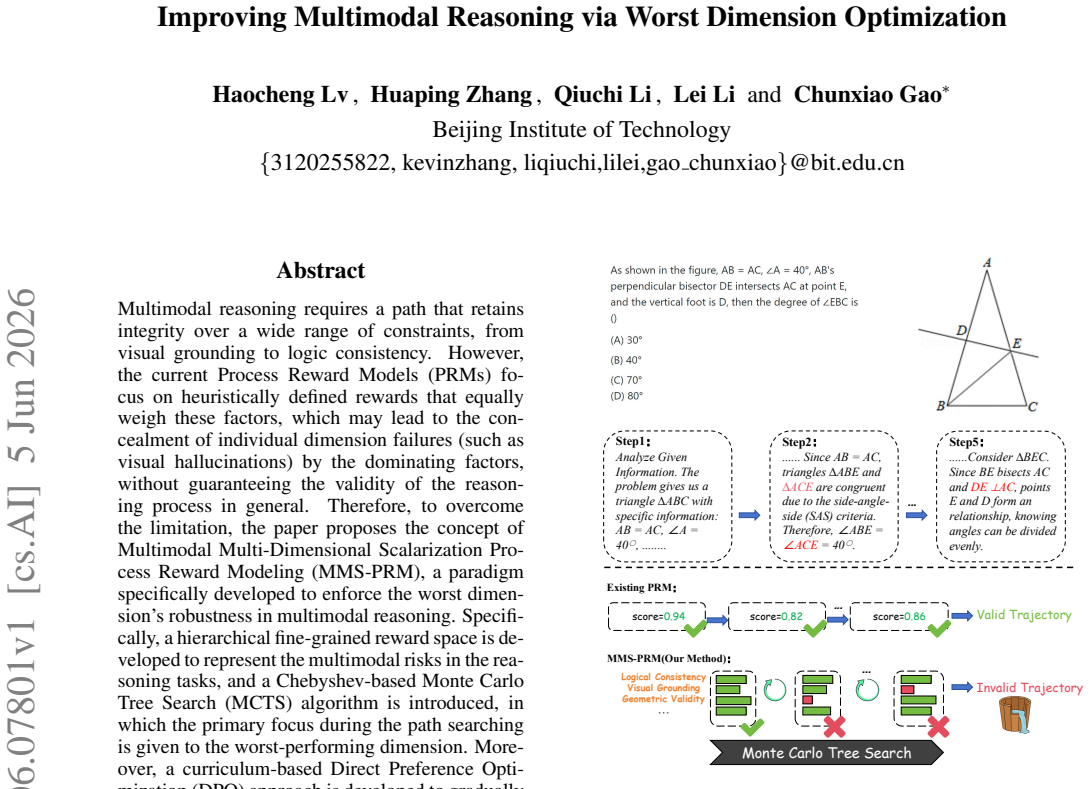
Multimodal reasoning requires a path that retains integrity over a wide range of constraints, from visual grounding to logic consistency. However, the current Process Reward Models focus on heuristically defined rewards that equally weigh these factors, which may lead to the concealment of individual dimension failures by the dominating factors, without guaranteeing the validity of the reasoning process in general.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper argues that current Process Reward Models for multimodal reasoning rely on heuristically defined rewards that equally weigh factors such as visual grounding and logical consistency, which can conceal failures in individual dimensions and fail to guarantee overall reasoning validity. It proposes Worst Dimension Optimization as a method to identify and prioritize optimization of the single worst-performing dimension to address this issue.
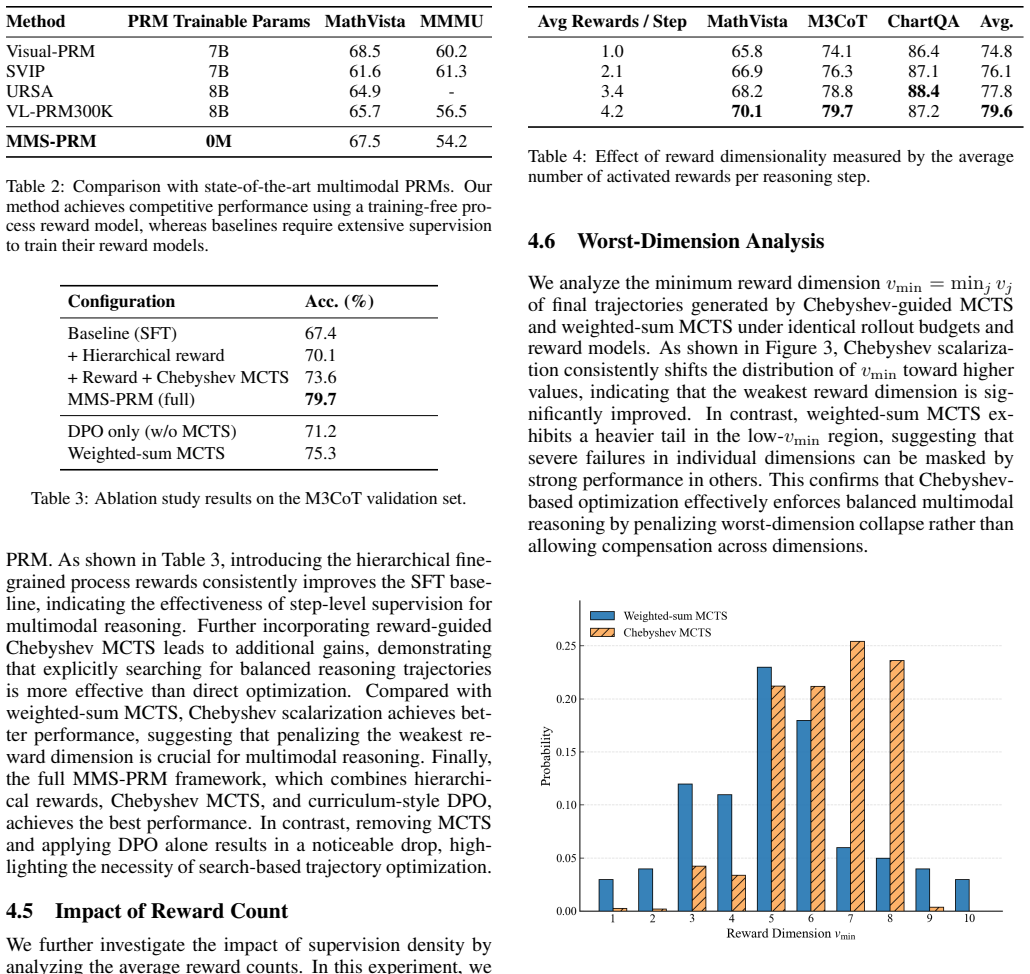
Significance. If the proposed optimization can be shown to ensure joint validity across constraints without introducing new concealment problems, it could improve the reliability of process reward models in multimodal settings. The idea targets a plausible weakness in equal-weighting approaches. However, the manuscript supplies no formal definitions of the dimensions, no algorithm for worst-dimension selection, no derivations showing why min-focus implies joint satisfaction, and no empirical results, so the significance cannot be assessed beyond the level of an untested hypothesis.
major comments (1)
- [Abstract] Abstract: The central claim that worst-dimension optimization prevents concealment of failures and guarantees validity of the full reasoning path is unsupported. The text provides neither a formal definition of the dimensions nor an argument establishing that (a) dimensions are independent enough for lifting the minimum to lift the joint or (b) the worst-dimension procedure itself is immune to the same heuristic concealment problem. Interactions between constraints (e.g., visual grounding and logical consistency) could still allow a path to pass the worst-dimension check while failing overall.
Simulated Author's Rebuttal
We thank the referee for their constructive comments on the manuscript. We address the major comment point by point below, providing the strongest honest defense of the conceptual contribution while acknowledging limitations in the current presentation.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that worst-dimension optimization prevents concealment of failures and guarantees validity of the full reasoning path is unsupported. The text provides neither a formal definition of the dimensions nor an argument establishing that (a) dimensions are independent enough for lifting the minimum to lift the joint or (b) the worst-dimension procedure itself is immune to the same heuristic concealment problem. Interactions between constraints (e.g., visual grounding and logical consistency) could still allow a path to pass the worst-dimension check while failing overall.
Authors: We agree that the current manuscript presents Worst Dimension Optimization primarily as a conceptual proposal without formal definitions or derivations, leaving the central claim as an intuitive hypothesis rather than a rigorously supported theorem. The manuscript's abstract highlights the motivation—equal weighting can mask failures—but does not supply the requested formal elements. In revision we will add: (1) explicit definitions of dimensions (visual grounding as feature-text alignment score, logical consistency as rule-adherence metric); (2) a selection algorithm (worst dimension = arg min_d reward_d(path)); and (3) a short argument under an independence assumption that raising the minimum cannot decrease the joint product, while noting that interactions remain possible. We will also include a brief discussion of why the min operator is less susceptible to concealment than averaging, as it forces explicit optimization of the identified bottleneck. These additions will be placed in a new Methods section. revision: yes
Circularity Check
No derivation chain or equations present; circularity cannot be assessed
full rationale
The supplied abstract and context contain no equations, formal derivations, self-citations, or load-bearing steps that reduce to inputs by construction. The central claim critiques heuristic rewards in Process Reward Models and proposes worst-dimension optimization, but offers neither a mathematical definition of dimensions nor any proof that min-dimension focus implies joint validity. Without visible formal content, no circularity of the enumerated kinds can be exhibited. This is the expected honest non-finding when the paper text supplies no chain to inspect.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
[Chenet al., 2024b ] Zhe Chen, Weiyun Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Erfei Cui, Jinguo Zhu, Shenglong Ye, Hao Tian, Zhaoyang Liu, et al. Expanding performance boundaries of open-source multimodal mod- els with model, data, and test-time scaling.arXiv preprint arXiv:2412.05271,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Dense point clouds matter: Dust-gs for scene reconstruction from sparse viewpoints
[Chenet al., 2025 ] Shen Chen, Jiale Zhou, and Lei Li. Dense point clouds matter: Dust-gs for scene reconstruction from sparse viewpoints. InICASSP 2025-2025 IEEE Interna- tional Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), pages 1–5. IEEE,
2025
-
[3]
Benchmarking multimodal cot reward model stepwise by visual program
[Gaoet al., 2025 ] Minghe Gao, Xuqi Liu, Zhongqi Yue, Yang Wu, Shuang Chen, Juncheng Li, Siliang Tang, Fei Wu, Tat-Seng Chua, and Yueting Zhuang. Benchmarking multimodal cot reward model stepwise by visual program. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1718–1728,
2025
-
[4]
rStar-Math: Small LLMs Can Master Math Reasoning with Self-Evolved Deep Thinking
[Guanet al., 2025a ] Xinyu Guan, Li Lyna Zhang, Yifei Liu, Ning Shang, Youran Sun, Yi Zhu, Fan Yang, and Mao Yang. Rstar-math: Small llms can master math rea- soning with self-evolved deep thinking.arXiv preprint arXiv:2501.04519,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
[Guanet al., 2025b ] Yunchuan Guan, Yu Liu, Ke Zhou, Hui Li, Sen Jia, Zhiqi Shen, Ziyang Wang, Xinglin Zhang, Tao Chen, Jenq-Neng Hwang, et al. Learning an efficient optimizer via hybrid-policy sub-trajectory balance.arXiv preprint arXiv:2511.00543,
-
[6]
Vision-R1: Incentivizing Reasoning Capability in Multimodal Large Language Models
[Huanget al., 2025 ] Wenxuan Huang, Bohan Jia, Zijie Zhai, Shaosheng Cao, Zheyu Ye, Fei Zhao, Zhe Xu, Xu Tang, Yao Hu, and Shaohui Lin. Vision-r1: Incentivizing reason- ing capability in multimodal large language models.arXiv preprint arXiv:2503.06749,
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[7]
RAM: Recover Any 3D Human Motion in-the-Wild
[Jiaet al., 2026 ] Sen Jia, Ning Zhu, Jinqin Zhong, Jiale Zhou, Huaping Zhang, Jenq-Neng Hwang, and Lei Li. Ram: Recover any 3d human motion in-the-wild.arXiv preprint arXiv:2603.19929,
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
A diagram is worth a dozen images
[Kembhaviet al., 2016 ] Aniruddha Kembhavi, Mike Sal- vato, Eric Kolve, Minjoon Seo, Hannaneh Hajishirzi, and Ali Farhadi. A diagram is worth a dozen images. In European conference on computer vision, pages 235–251. Springer,
2016
-
[9]
Nv-embed: Improved techniques for train- ing llms as generalist embedding models
[Leeet al., 2025 ] Chankyu Lee, Rajarshi Roy, Mengyao Xu, Jonathan Raiman, Mohammad Shoeybi, Bryan Catanzaro, and Wei Ping. Nv-embed: Improved techniques for train- ing llms as generalist embedding models. InInternational Conference on Learning Representations, volume 2025, pages 79310–79333,
2025
-
[10]
LLaVA-OneVision: Easy Visual Task Transfer
[Liet al., 2024 ] Bo Li, Yuanhan Zhang, Dong Guo, Ren- rui Zhang, Feng Li, Hao Zhang, Kaichen Zhang, Peiyuan Zhang, Yanwei Li, Ziwei Liu, et al. Llava-onevision: Easy visual task transfer.arXiv preprint arXiv:2408.03326,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[11]
Human motion instruction tuning
[Liet al., 2025 ] Lei Li, Sen Jia, Jianhao Wang, Zhongyu Jiang, Feng Zhou, Ju Dai, Tianfang Zhang, Zongkai Wu, and Jenq-Neng Hwang. Human motion instruction tuning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),
2025
-
[12]
Multiple human motion understanding
[Liet al., 2026 ] Lei Li, Sen Jia, and Jenq-Neng Hwang. Multiple human motion understanding. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 6297–6305,
2026
-
[13]
Image semantic segmentation via chain- of-thought prompts
[Li, 2024] Lei Li. Image semantic segmentation via chain- of-thought prompts. InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV),
2024
-
[14]
Graph canvas for controllable 3d scene generation.arXiv preprint arXiv:2412.00091,
[Liuet al., 2024c ] Libin Liu, Shen Chen, Sen Jia, Jingzhe Shi, Zhongyu Jiang, Can Jin, Wu Zongkai, Jenq-Neng Hwang, and Lei Li. Graph canvas for controllable 3d scene generation.arXiv preprint arXiv:2412.00091,
-
[15]
Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts
[Luet al., 2024a ] Pan Lu, Hritik Bansal, Tony Xia, Jiacheng Liu, Chunyuan Li, Hannaneh Hajishirzi, Hao Cheng, Kai- Wei Chang, Michel Galley, and Jianfeng Gao. Mathvista: Evaluating mathematical reasoning of foundation models in visual contexts. InInternational Conference on Learn- ing Representations, volume 2024, pages 23439–23554,
2024
-
[16]
arXiv preprint arXiv:2405.20797 , year=
[Luet al., 2024b ] Shiyin Lu, Yang Li, Qing-Guo Chen, Zhao Xu, Weihua Luo, Kaifu Zhang, and Han-Jia Ye. Ovis: Structural embedding alignment for multimodal large lan- guage model.arXiv preprint arXiv:2405.20797,
-
[17]
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
[Luoet al., 2024 ] Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Meiqi Guo, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, et al. Improve mathemat- ical reasoning in language models by automated process supervision.arXiv preprint arXiv:2406.06592,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[18]
Ursa: Understanding and verifying chain-of- thought reasoning in multimodal mathematics.arXiv e- prints, pages arXiv–2501,
[Luoet al., 2025 ] Ruilin Luo, Zhuofan Zheng, Yifan Wang, Yiyao Yu, Xinzhe Ni, Zicheng Lin, Jin Zeng, and Yu- jiu Yang. Ursa: Understanding and verifying chain-of- thought reasoning in multimodal mathematics.arXiv e- prints, pages arXiv–2501,
2025
-
[19]
Chartqa: A bench- mark for question answering about charts with visual and logical reasoning
[Masryet al., 2022 ] Ahmed Masry, Xuan Long Do, Jia Qing Tan, Shafiq Joty, and Enamul Hoque. Chartqa: A bench- mark for question answering about charts with visual and logical reasoning. InFindings of the association for com- putational linguistics: ACL 2022, pages 2263–2279,
2022
-
[20]
[Onget al., 2025 ] Brandon Ong, Tej Deep Pala, Vernon Toh, William Chandra Tjhi, and Soujanya Poria. Training vision-language process reward models for test-time scal- ing in multimodal reasoning: Key insights and lessons learned.arXiv preprint arXiv:2509.23250,
-
[21]
Mutual reason- ing makes smaller llms stronger problem-solver
[Qiet al., 2025 ] Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual reason- ing makes smaller llms stronger problem-solver. InInter- national Conference on Learning Representations, volume 2025, pages 20788–20807,
2025
-
[22]
[Shaoet al., 2024 ] Hao Shao, Shengju Qian, Han Xiao, Guanglu Song, Zhuofan Zong, Letian Wang, Yu Liu, and Hongsheng Li. Visual cot: Advancing multi-modal lan- guage models with a comprehensive dataset and bench- mark for chain-of-thought reasoning.Advances in Neural Information Processing Systems, 37:8612–8642,
2024
-
[23]
Intrinsic entropy of context length scaling in llms
[Shiet al., 2026 ] Jingzhe Shi, Qinwei Ma, Hongyi Liu, Hang Zhao, Jenq-Neng Hwang, and Lei Li. Intrinsic entropy of context length scaling in llms. InThe Four- teenth International Conference on Learning Representa- tions,
2026
-
[24]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
[Snellet al., 2024 ] Charlie Snell, Jaehoon Lee, Kelvin Xu, and Aviral Kumar. Scaling llm test-time compute opti- mally can be more effective than scaling model parame- ters.arXiv preprint arXiv:2408.03314,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Llamav-o1: Rethinking step-by-step visual reasoning in llms
[Thawakaret al., 2025 ] Omkar Thawakar, Dinura Dis- sanayake, Ketan Pravin More, Ritesh Thawkar, Ahmed Heakl, Noor Ahsan, Yuhao Li, Ilmuz Zaman Mohammed Zumri, Jean Lahoud, Rao Muhammad Anwer, et al. Llamav-o1: Rethinking step-by-step visual reasoning in llms. InFindings of the Association for Computational Linguistics: ACL 2025, pages 24290–24315,
2025
-
[26]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
[Wanget al., 2024b ] Peng Wang, Shuai Bai, Sinan Tan, Shi- jie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhanc- ing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
[Wanget al., 2024c ] Weiyun Wang, Zhe Chen, Wenhai Wang, Yue Cao, Yangzhou Liu, Zhangwei Gao, Jinguo Zhu, Xizhou Zhu, Lewei Lu, Yu Qiao, et al. Enhancing the reasoning ability of multimodal large language mod- els via mixed preference optimization.arXiv preprint arXiv:2411.10442,
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
Multi-step problem solving through a verifier: An empir- ical analysis on model-induced process supervision
[Wanget al., 2024d ] Zihan Wang, Yunxuan Li, Yuexin Wu, Liangchen Luo, Le Hou, Hongkun Yu, and Jingbo Shang. Multi-step problem solving through a verifier: An empir- ical analysis on model-induced process supervision. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 7309–7319,
2024
-
[29]
[Wanget al., 2025 ] Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, et al. Visual- prm: An effective process reward model for multimodal reasoning.arXiv preprint arXiv:2503.10291,
-
[30]
[Wuet al., 2024 ] Jinyang Wu, Mingkuan Feng, Shuai Zhang, Feihu Che, Zengqi Wen, Chonghua Liao, and Jian- hua Tao. Beyond examples: High-level automated rea- soning paradigm in in-context learning via mcts.arXiv preprint arXiv:2411.18478,
-
[31]
Llava-cot: Let vi- sion language models reason step-by-step
[Xuet al., 2025 ] Guowei Xu, Peng Jin, Ziang Wu, Hao Li, Yibing Song, Lichao Sun, and Li Yuan. Llava-cot: Let vi- sion language models reason step-by-step. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2087–2098,
2025
-
[32]
[Yanet al., 2024 ] Ziyang Yan, Lei Li, Yihua Shao, Siyu Chen, Zongkai Wu, Jenq-Neng Hwang, Hao Zhao, and Fabio Remondino. 3dsceneeditor: Controllable 3d scene editing with gaussian splatting.arXiv preprint arXiv:2412.01583,
-
[33]
3dsceneeditor: Controllable 3d scene editing with gaussian splatting
[Yanet al., 2026 ] Ziyang Yan, Yihua Shao, Minwen Liao, Siyu Chen, Nan Wang, Muyuan Lin, Jenq-Neng Hwang, Hao Zhao, Fabio Remondino, and Lei Li. 3dsceneeditor: Controllable 3d scene editing with gaussian splatting. In Proceedings of the IEEE/CVF Winter Conference on Ap- plications of Computer Vision (WACV), pages 1852–1863, March
2026
-
[34]
R1- onevision: Advancing generalized multimodal reasoning through cross-modal formalization
[Yanget al., 2025 ] Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, et al. R1- onevision: Advancing generalized multimodal reasoning through cross-modal formalization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2376–2385,
2025
-
[35]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
[Yaoet al., 2024 ] Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[36]
CountLLM: Towards Generalizable Repetitive Ac- tion Counting via Large Language Model
[Yaoet al., 2025 ] Ziyu Yao, Xuxin Cheng, Zhiqi Huang, and Lei Li. CountLLM: Towards Generalizable Repetitive Ac- tion Counting via Large Language Model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR),
2025
-
[37]
Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search.Advances in Neural Information Processing Systems, 38:29918–29952,
[Yaoet al., 2026 ] Huanjin Yao, Jiaxing Huang, Wenhao Wu, Jingyi Zhang, Yibo Wang, Shunyu Liu, Yingjie Wang, Yuxin Song, Haocheng Feng, Li Shen, et al. Mulberry: Empowering mllm with o1-like reasoning and reflection via collective monte carlo tree search.Advances in Neural Information Processing Systems, 38:29918–29952,
2026
-
[38]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
[Yueet al., 2024 ] Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567,
2024
-
[39]
Birch: an efficient data clustering method for very large databases.ACM sigmod record, 25(2):103–114,
[Zhanget al., 1996 ] Tian Zhang, Raghu Ramakrishnan, and Miron Livny. Birch: an efficient data clustering method for very large databases.ACM sigmod record, 25(2):103–114,
1996
-
[40]
[Zhanget al., 2024 ] Pan Zhang, Xiaoyi Dong, Yuhang Zang, Yuhang Cao, Rui Qian, Lin Chen, Qipeng Guo, Haodong Duan, Bin Wang, Linke Ouyang, et al. Internlm- xcomposer-2.5: A versatile large vision language model supporting long-contextual input and output.arXiv preprint arXiv:2407.03320,
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[41]
[Zhanget al., 2025a ] Jingyi Zhang, Jiaxing Huang, Huanjin Yao, Shunyu Liu, Xikun Zhang, Shijian Lu, and Dacheng Tao. R1-vl: Learning to reason with multimodal large lan- guage models via step-wise group relative policy optimiza- tion.arXiv preprint arXiv:2503.12937,
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
[Zhanget al., 2026 ] Xin Zhang, Shen Chen, Jiale Zhou, and Lei Li. Psgs: Text-driven panorama sliding scene generation via gaussian splatting.arXiv preprint arXiv:2602.00463, 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.