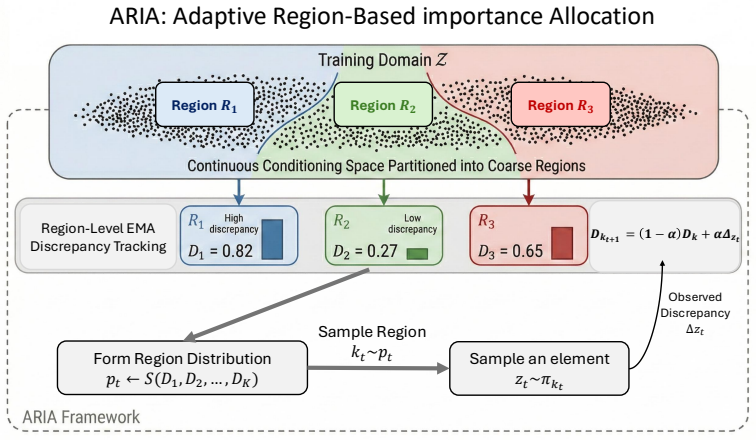
ARIA: Adaptive Region-Based Importance Allocation for Conditional Diffusion Distillation
Pith reviewed 2026-06-26 08:39 UTC · model grok-4.3
The pith
ARIA adaptively allocates distillation training effort to conditioning regions with persistent teacher-student misalignment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
ARIA maintains online region-level estimates of teacher-student discrepancy and reallocates training effort across the conditioning space accordingly; the estimates track the evolving discrepancy under bounded variance and drift assumptions, yielding measurable improvements over random-condition baselines especially in unseen and underrepresented regimes while leaving the distillation objective intact.
What carries the argument
Online region-level tracking of teacher-student discrepancy to drive adaptive allocation of distillation updates.
If this is right
- ARIA improves performance over random condition switching across most architectures and settings.
- The largest gains appear in unseen and underrepresented conditioning regimes.
- The tracking mechanism follows the evolving discrepancy under the stated bounded variance and drift assumptions.
- The original distillation objective remains unchanged.
Where Pith is reading between the lines
- The same region-tracking idea could be applied to other conditional generative tasks where condition coverage is the bottleneck.
- Coarser or finer region partitions might yield different trade-offs between tracking cost and allocation precision.
- The method assumes the conditioning space admits a stable coarse partitioning; domains without natural regions may need auxiliary clustering.
Load-bearing premise
Online region-level estimates of teacher-student discrepancy accurately identify where misalignment persists and can be maintained without introducing bias into the distillation process.
What would settle it
An experiment in which ARIA produces no improvement over random condition switching on held-out conditions or in which the online discrepancy estimates diverge from measured misalignment.
Figures
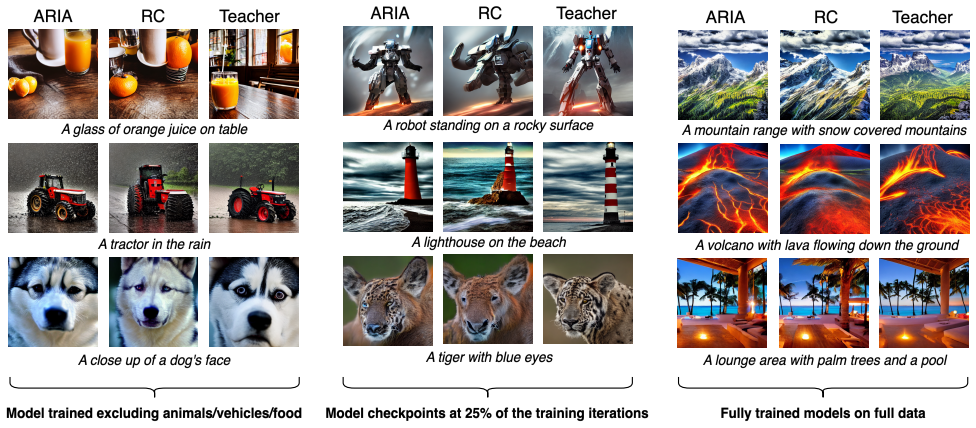
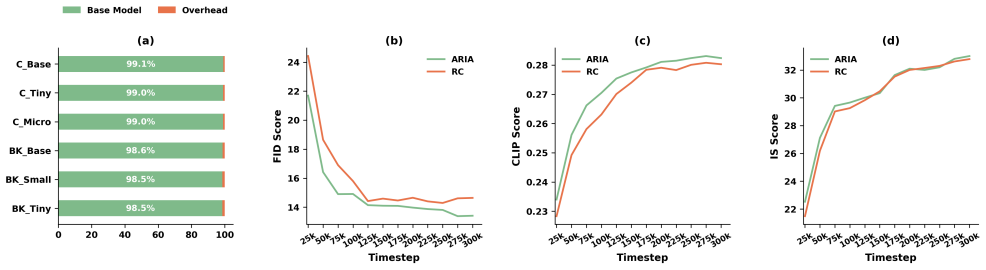
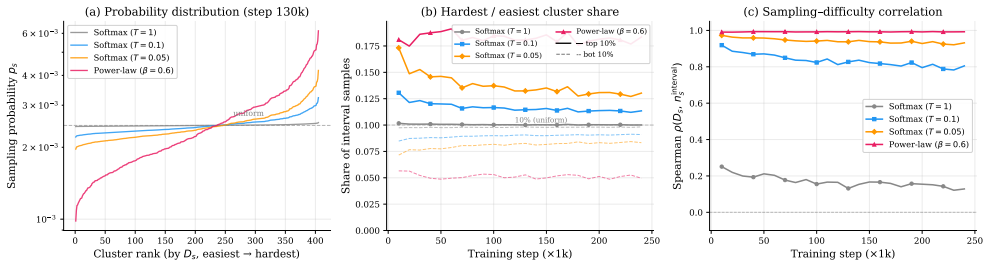
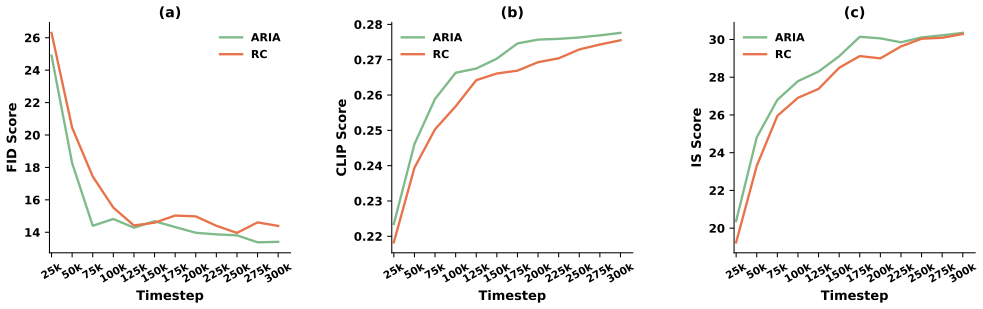




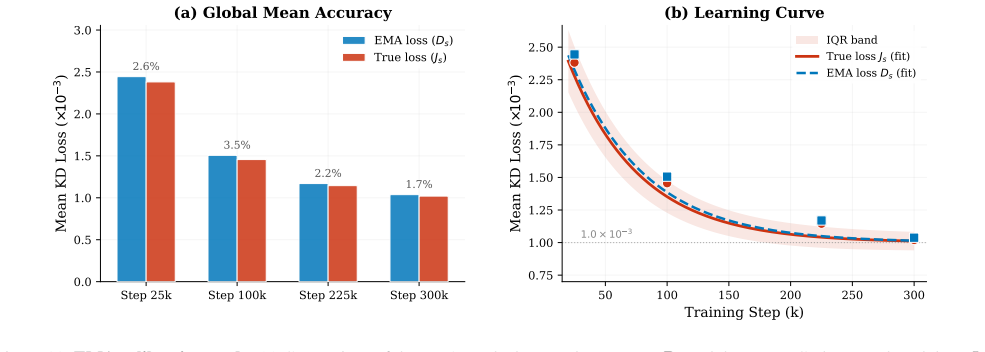
read the original abstract
Distilling conditional diffusion models aims to transfer the behavior of a large teacher to a smaller student while preserving alignment across conditioning inputs. Unlike recognition tasks, knowledge distillation in conditional diffusion often struggles to transfer knowledge beyond the training distribution, since the predicted noise strongly depends on the conditioning signal. As a result, effective distillation requires exploring a large conditioning space. In practical settings, this creates a major bottleneck. Paired image-condition data may be limited, and generating synthetic images for every available condition is often computationally infeasible, while the pool of conditions, such as text prompts, can be extremely large. Recent work addresses this issue by switching conditions during training, exposing the student to a broader conditioning space without changing the distillation objective. Yet this raises a complementary question: once a large conditioning corpus is available, how should the training effort be allocated? In this work, we introduce ARIA, a framework that adaptively allocates training effort across coarse regions of the conditioning space. By maintaining online estimates of teacher-student discrepancy at the region level, ARIA focuses updates where misalignment persists while preserving the original distillation objective. Empirically, ARIA improves over RC across most architectures and settings, with the clearest gains observed in unseen and underrepresented regimes. We also provide a theoretical analysis showing that the proposed tracking mechanism follows the evolving discrepancy during training under bounded variance and drift assumptions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces ARIA, a framework for adaptively allocating training effort across coarse regions of the conditioning space in conditional diffusion model distillation. It maintains online region-level estimates of teacher-student discrepancy to focus updates where misalignment persists, while preserving the original distillation objective. The work claims empirical improvements over RC (random conditioning) across most architectures and settings, with clearest gains in unseen and underrepresented regimes, plus a theoretical analysis showing that the tracking mechanism follows the evolving discrepancy under bounded variance and drift assumptions.
Significance. If the central claims hold, ARIA could mitigate the computational bottleneck of exploring large conditioning spaces (e.g., text prompts) without requiring exhaustive synthetic data generation, improving generalization beyond the training distribution. The provision of a theoretical result under explicit assumptions is a strength, as is the focus on practical allocation rather than changing the distillation loss itself.
major comments (3)
- [Abstract] Abstract (paragraph on ARIA framework): the claim that online region-level estimates of teacher-student discrepancy 'accurately identify where misalignment persists' and 'can be maintained without introducing bias' is load-bearing for the adaptive allocation mechanism, yet the abstract provides no details on how these estimates are computed, updated, or validated against ground-truth discrepancy; this prevents assessment of whether the tracking introduces circularity or bias into the distillation process.
- [Abstract] Abstract (empirical claims): the statement that 'ARIA improves over RC across most architectures and settings' with 'clearest gains observed in unseen and underrepresented regimes' is presented without any information on architectures tested, baseline implementations, metrics, number of runs, or how regions are defined/partitioned; this makes it impossible to evaluate whether the gains are robust or whether the experimental design controls for confounding factors such as total compute or conditioning coverage.
- [Abstract] Abstract (theoretical analysis): the result that the tracking mechanism 'follows the evolving discrepancy during training under bounded variance and drift assumptions' is stated without the actual assumptions, proof sketch, or any equation; if the bounded-variance/drift conditions are strong or require additional hyperparameters, the practical significance of the guarantee is unclear.
minor comments (2)
- [Abstract] The acronym 'RC' is used without expansion or citation to the prior work that introduced random condition switching.
- [Abstract] The abstract refers to 'coarse regions of the conditioning space' but does not indicate how regions are constructed (e.g., clustering on embeddings, semantic categories) or whether region boundaries are fixed or adaptive.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major comment point by point below and will revise the abstract accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph on ARIA framework): the claim that online region-level estimates of teacher-student discrepancy 'accurately identify where misalignment persists' and 'can be maintained without introducing bias' is load-bearing for the adaptive allocation mechanism, yet the abstract provides no details on how these estimates are computed, updated, or validated against ground-truth discrepancy; this prevents assessment of whether the tracking introduces circularity or bias into the distillation process.
Authors: The abstract is a high-level summary. The estimates are computed as region-wise exponential moving averages of the per-sample discrepancy (defined in Eq. 3), updated online without modifying the distillation loss; validation against ground-truth appears in Section 4.3. We agree the abstract could better signal the mechanism and will add a short clause noting the online averaging procedure. revision: yes
-
Referee: [Abstract] Abstract (empirical claims): the statement that 'ARIA improves over RC across most architectures and settings' with 'clearest gains observed in unseen and underrepresented regimes' is presented without any information on architectures tested, baseline implementations, metrics, number of runs, or how regions are defined/partitioned; this makes it impossible to evaluate whether the gains are robust or whether the experimental design controls for confounding factors such as total compute or conditioning coverage.
Authors: The abstract omits these specifics by design. Full details (architectures, RC baselines, metrics, run counts, and region partitioning via embedding clustering) are in Section 4. We will expand the abstract with a brief clause summarizing the experimental scope and controls. revision: yes
-
Referee: [Abstract] Abstract (theoretical analysis): the result that the tracking mechanism 'follows the evolving discrepancy during training under bounded variance and drift assumptions' is stated without the actual assumptions, proof sketch, or any equation; if the bounded-variance/drift conditions are strong or require additional hyperparameters, the practical significance of the guarantee is unclear.
Authors: The abstract summarizes the result. The bounded-variance and bounded-drift assumptions, together with the proof, are stated explicitly in Section 5 and do not introduce extra hyperparameters. We will revise the abstract to name the assumptions concisely. revision: yes
Circularity Check
No significant circularity detected
full rationale
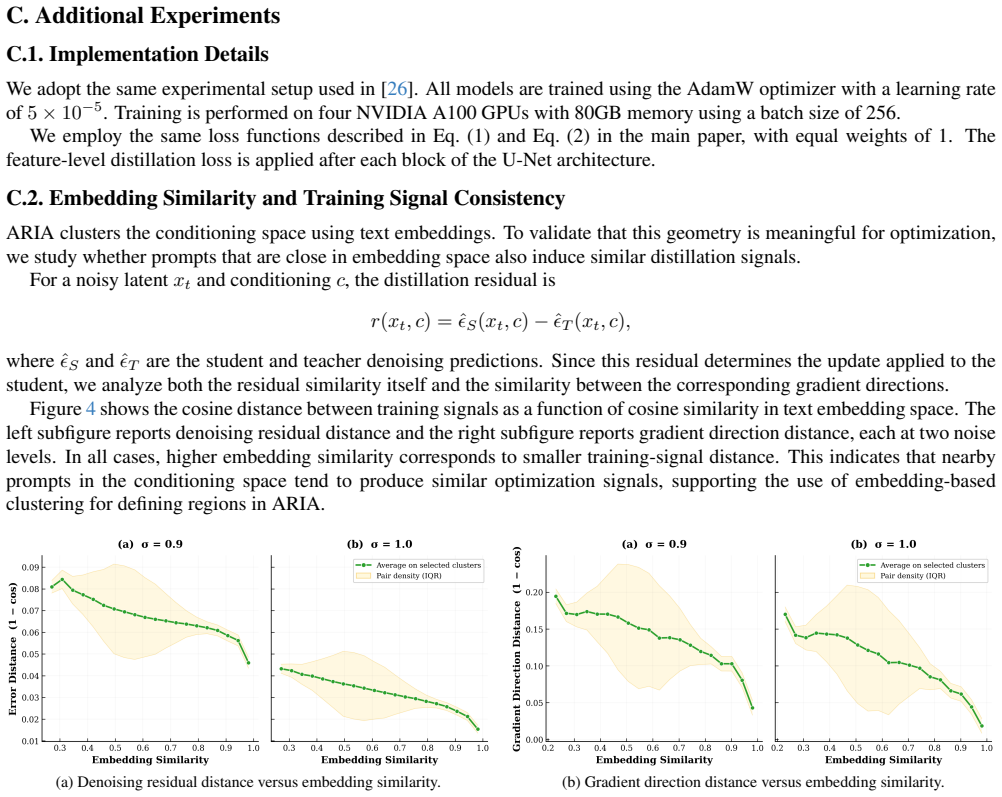
The provided abstract describes ARIA as maintaining online region-level estimates of teacher-student discrepancy to allocate training effort, with a theoretical analysis showing the tracking follows discrepancy under bounded variance and drift assumptions. No equations, self-citations, or derivations are supplied that reduce any prediction or result to a fitted quantity defined by the result itself, nor any load-bearing self-citation chains or ansatzes smuggled via prior work. The mechanism is presented as an independent tracking process under stated external assumptions rather than a self-referential construction. Without full text exhibiting specific reductions (e.g., Eq. X = input by definition), the derivation chain is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Teacher-student discrepancy tracking follows the evolving discrepancy under bounded variance and drift assumptions
Reference graph
Works this paper leans on
-
[1]
k-means++ the advan- tages of careful seeding
David Arthur and Sergei Vassilvitskii. k-means++ the advan- tages of careful seeding. InProceedings of the eighteenth an- nual ACM-SIAM symposium on Discrete algorithms, pages 1027–1035, 2007. 19
2007
-
[2]
Stephen Batifol, Andreas Blattmann, Frederic Boesel, Sak- sham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, Sumith Kulal, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv e-prints, pages arXiv–2506,
-
[3]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
Andreas Blattmann, Tim Dockhorn, Sumith Kulal, Daniel Mendelevitch, Maciej Kilian, Dominik Lorenz, Yam Levi, Zion English, Vikram V oleti, Adam Letts, et al. Stable video diffusion: Scaling latent video diffusion models to large datasets.arXiv preprint arXiv:2311.15127, 2023. 1
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Sur- vey on applications of multi-armed and contextual bandits
Djallel Bouneffouf, Irina Rish, and Charu Aggarwal. Sur- vey on applications of multi-armed and contextual bandits. In2020 IEEE congress on evolutionary computation (CEC), pages 1–8. IEEE, 2020. 12
2020
-
[5]
Efficient coreset constructions via sensitivity sampling
Vladimir Braverman, Dan Feldman, Harry Lang, Adiel Stat- man, and Samson Zhou. Efficient coreset constructions via sensitivity sampling. InAsian Conference on Machine Learning, pages 948–963. PMLR, 2021. 19
2021
-
[6]
Motion planning diffusion: Learning and adapt- ing robot motion planning with diffusion models.IEEE Transactions on Robotics, 2025
Joao Carvalho, An T Le, Piotr Kicki, Dorothea Koert, and Jan Peters. Motion planning diffusion: Learning and adapt- ing robot motion planning with diffusion models.IEEE Transactions on Robotics, 2025. 1
2025
-
[7]
Sana-video: Efficient video generation with block linear diffusion transformer,
Junsong Chen, Yuyang Zhao, Jincheng Yu, Ruihang Chu, Junyu Chen, Shuai Yang, Xianbang Wang, Yicheng Pan, Daquan Zhou, Huan Ling, et al. Sana-video: Efficient video generation with block linear diffusion transformer.arXiv preprint arXiv:2509.24695, 2025. 2
-
[8]
Distilling knowledge via knowledge review
Pengguang Chen, Shu Liu, Hengshuang Zhao, and Jiaya Jia. Distilling knowledge via knowledge review. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 5008–5017, 2021. 1, 2
2021
-
[9]
Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, 44 (10-11):1684–1704, 2025
Cheng Chi, Zhenjia Xu, Siyuan Feng, Eric Cousineau, Yilun Du, Benjamin Burchfiel, Russ Tedrake, and Shuran Song. Diffusion policy: Visuomotor policy learning via action dif- fusion.The International Journal of Robotics Research, 44 (10-11):1684–1704, 2025. 1
2025
-
[10]
Im- proved coresets for euclideank-means.Advances in Neural Information Processing Systems, 35:2679–2694, 2022
Vincent Cohen-Addad, Kasper Green Larsen, David Saulpic, Chris Schwiegelshohn, and Omar Ali Sheikh-Omar. Im- proved coresets for euclideank-means.Advances in Neural Information Processing Systems, 35:2679–2694, 2022. 12
2022
-
[11]
Swiftbrush v2: Make your one-step diffusion model better than its teacher
Trung Dao, Thuan Hoang Nguyen, Thanh Le, Duc Vu, Khoi Nguyen, Cuong Pham, and Anh Tran. Swiftbrush v2: Make your one-step diffusion model better than its teacher. In European Conference on Computer Vision, pages 176–192. Springer, 2024. 1, 2
2024
-
[12]
Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural informa- tion processing systems, 34:8780–8794, 2021. 1
2021
-
[13]
Private coresets
Dan Feldman, Amos Fiat, Haim Kaplan, and Kobbi Nissim. Private coresets. InProceedings of the forty-first annual ACM symposium on Theory of computing, pages 361–370,
-
[14]
Mosaicdiff: Training-free structural pruning for diffu- sion model acceleration reflecting pretraining dynamics
Bowei Guo, Shengkun Tang, Cong Zeng, and Zhiqiang Shen. Mosaicdiff: Training-free structural pruning for diffu- sion model acceleration reflecting pretraining dynamics. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 1655–1664, 2025. 2
2025
-
[15]
Photorealistic video generation with diffusion models
Agrim Gupta, Lijun Yu, Kihyuk Sohn, Xiuye Gu, Meera Hahn, Fei-Fei Li, Irfan Essa, Lu Jiang, and Jos ´e Lezama. Photorealistic video generation with diffusion models. In European Conference on Computer Vision, pages 393–411. Springer, 2024. 1
2024
-
[16]
Learning effi- cient vision transformers via fine-grained manifold distilla- tion.Advances in Neural Information Processing Systems, 35:9164–9175, 2022
Zhiwei Hao, Jianyuan Guo, Ding Jia, Kai Han, Yehui Tang, Chao Zhang, Han Hu, and Yunhe Wang. Learning effi- cient vision transformers via fine-grained manifold distilla- tion.Advances in Neural Information Processing Systems, 35:9164–9175, 2022. 2
2022
-
[17]
Smaller coresets for k-median and k-means clustering
Sariel Har-Peled and Akash Kushal. Smaller coresets for k-median and k-means clustering. InProceedings of the twenty-first annual symposium on Computational geometry, pages 126–134, 2005. 12
2005
-
[18]
On coresets for k- means and k-median clustering
Sariel Har-Peled and Soham Mazumdar. On coresets for k- means and k-median clustering. InProceedings of the thirty- sixth annual ACM symposium on Theory of computing, pages 291–300, 2004. 12
2004
-
[19]
Distilling the knowledge in a neural network
G Hinton. Distilling the knowledge in a neural network. In Deep Learning and Representation Learning Workshop in Conjunction with NIPS, 2014. 1, 2
2014
-
[20]
Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising dif- fusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020. 1 9
2020
-
[21]
Imagen Video: High Definition Video Generation with Diffusion Models
Jonathan Ho, William Chan, Chitwan Saharia, Jay Whang, Ruiqi Gao, Alexey Gritsenko, Diederik P Kingma, Ben Poole, Mohammad Norouzi, David J Fleet, et al. Imagen video: High definition video generation with diffusion mod- els.arXiv preprint arXiv:2210.02303, 2022. 1
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[22]
Coresets for clustering with fairness constraints.Advances in neural information processing systems, 32, 2019
Lingxiao Huang, Shaofeng Jiang, and Nisheeth Vishnoi. Coresets for clustering with fairness constraints.Advances in neural information processing systems, 32, 2019. 12
2019
-
[23]
Tinybert: Distill- ing bert for natural language understanding
Xiaoqi Jiao, Yichun Yin, Lifeng Shang, Xin Jiang, Xiao Chen, Linlin Li, Fang Wang, and Qun Liu. Tinybert: Distill- ing bert for natural language understanding. InFindings of the association for computational linguistics: EMNLP 2020, pages 4163–4174, 2020. 2
2020
-
[24]
In- troduction to coresets: Accurate coresets.arXiv preprint arXiv:1910.08707, 2019
Ibrahim Jubran, Alaa Maalouf, and Dan Feldman. In- troduction to coresets: Accurate coresets.arXiv preprint arXiv:1910.08707, 2019. 12
-
[25]
Bk-sdm: A lightweight, fast, and cheap ver- sion of stable diffusion
Bo-Kyeong Kim, Hyoung-Kyu Song, Thibault Castells, and Shinkook Choi. Bk-sdm: A lightweight, fast, and cheap ver- sion of stable diffusion. InEuropean Conference on Com- puter Vision, pages 381–399. Springer, 2024. 2, 6
2024
-
[26]
Random conditioning with distillation for data-efficient diffusion model compression
Dohyun Kim, Sehwan Park, Geonhee Han, Seung Wook Kim, and Paul Hongsuck Seo. Random conditioning with distillation for data-efficient diffusion model compression. In2025 IEEE/CVF Conference on Computer Vision and Pat- tern Recognition (CVPR), pages 18607–18618. IEEE, 2025. 1, 2, 3, 5, 6, 7, 16
2025
-
[27]
DiffWave: A Versatile Diffusion Model for Audio Synthesis
Zhifeng Kong, Wei Ping, Jiaji Huang, Kexin Zhao, and Bryan Catanzaro. Diffwave: A versatile diffusion model for audio synthesis.arXiv preprint arXiv:2009.09761, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[28]
Young D Kwon, Rui Li, Sijia Li, Da Li, Sourav Bhat- tacharya, and Stylianos I Venieris. Hierarchicalprune: Position-aware compression for large-scale diffusion mod- els.arXiv preprint arXiv:2508.04663, 2025. 2
-
[29]
Koala: Empirical lessons toward memory-efficient and fast diffusion models for text-to-image synthesis.Advances in Neural Information Processing Sys- tems, 37:51597–51633, 2024
Youngwan Lee, Kwanyong Park, Yoorhim Cho, Yong-Ju Lee, and Sung Ju Hwang. Koala: Empirical lessons toward memory-efficient and fast diffusion models for text-to-image synthesis.Advances in Neural Information Processing Sys- tems, 37:51597–51633, 2024. 2, 6, 7
2024
-
[30]
Knowledge distillation for object de- tection via rank mimicking and prediction-guided feature im- itation
Gang Li, Xiang Li, Yujie Wang, Shanshan Zhang, Yichao Wu, and Ding Liang. Knowledge distillation for object de- tection via rank mimicking and prediction-guided feature im- itation. InProceedings of the AAAI conference on artificial intelligence, pages 1306–1313, 2022. 1, 2
2022
-
[31]
Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation
Junnan Li, Dongxu Li, Caiming Xiong, and Steven Hoi. Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation. InInterna- tional conference on machine learning, pages 12888–12900. PMLR, 2022. 6
2022
-
[32]
Snap- fusion: Text-to-image diffusion model on mobile devices within two seconds.Advances in Neural Information Pro- cessing Systems, 36:20662–20678, 2023
Yanyu Li, Huan Wang, Qing Jin, Ju Hu, Pavlo Chemerys, Yun Fu, Yanzhi Wang, Sergey Tulyakov, and Jian Ren. Snap- fusion: Text-to-image diffusion model on mobile devices within two seconds.Advances in Neural Information Pro- cessing Systems, 36:20662–20678, 2023. 2
2023
-
[33]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. In European conference on computer vision, pages 740–755. Springer, 2014. 6
2014
-
[34]
Audi- oldm: Text-to-audio generation with latent diffusion models
Haohe Liu, Zehua Chen, Yi Yuan, Xinhao Mei, Xubo Liu, Danilo Mandic, Wenwu Wang, and Mark D Plumbley. Audi- oldm: Text-to-audio generation with latent diffusion models. arXiv preprint arXiv:2301.12503, 2023. 1
-
[35]
Dpm-solver: A fast ode solver for diffu- sion probabilistic model sampling in around 10 steps.Ad- vances in neural information processing systems, 35:5775– 5787, 2022
Cheng Lu, Yuhao Zhou, Fan Bao, Jianfei Chen, Chongxuan Li, and Jun Zhu. Dpm-solver: A fast ode solver for diffu- sion probabilistic model sampling in around 10 steps.Ad- vances in neural information processing systems, 35:5775– 5787, 2022. 2
2022
-
[36]
One-step diffusion distillation through score implicit matching.Advances in Neural Information Process- ing Systems, 37:115377–115408, 2024
Weijian Luo, Zemin Huang, Zhengyang Geng, J Zico Kolter, and Guo-jun Qi. One-step diffusion distillation through score implicit matching.Advances in Neural Information Process- ing Systems, 37:115377–115408, 2024. 1, 2
2024
-
[37]
Swiftbrush: One-step text-to-image diffusion model with variational score distilla- tion
Thuan Hoang Nguyen and Anh Tran. Swiftbrush: One-step text-to-image diffusion model with variational score distilla- tion. InProceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, pages 7807–7816,
-
[38]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, Pranav Shyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever, and Mark Chen. Glide: Towards photorealistic image generation and editing with text-guided diffusion models.arXiv preprint arXiv:2112.10741, 2021. 1
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[39]
Sdxl: Improving latent diffusion models for high-resolution image synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M ¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis. InThe Twelfth Interna- tional Conference on Learning Representations, 2023. 2, 6, 7
2023
-
[40]
Learning transferable visual models from natural language supervi- sion
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervi- sion. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021. 6
2021
-
[41]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10684–10695, 2022. 1, 2
2022
-
[42]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj ¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 1, 6
2022
-
[43]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models.arXiv preprint arXiv:2202.00512, 2022. 2
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[44]
Adversarial diffusion distillation
Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial diffusion distillation. InEuropean Conference on Computer Vision, pages 87–103. Springer,
-
[45]
Laion- aesthetics, 2022
Christoph Schuhmann and Romain Beaumont. Laion- aesthetics, 2022. 6
2022
-
[46]
Laion-400m: 10 Open dataset of clip-filtered 400 million image-text pairs
Christoph Schuhmann, Robert Kaczmarczyk, Aran Komat- suzaki, Aarush Katta, Richard Vencu, Romain Beaumont, Je- nia Jitsev, Theo Coombes, and Clayton Mullis. Laion-400m: 10 Open dataset of clip-filtered 400 million image-text pairs. In NeurIPS Workshop Datacentric AI. J ¨ulich Supercomputing Center, 2021. 6
2021
-
[47]
Cluster quality analysis using silhouette score
Ketan Rajshekhar Shahapure and Charles Nicholas. Cluster quality analysis using silhouette score. In2020 IEEE 7th international conference on data science and advanced ana- lytics (DSAA), pages 747–748. IEEE, 2020. 18
2020
-
[48]
Post-training quantization on diffusion models
Yuzhang Shang, Zhihang Yuan, Bin Xie, Bingzhe Wu, and Yan Yan. Post-training quantization on diffusion models. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 1972–1981, 2023. 2
1972
-
[49]
Introduction to multi-armed bandits
Aleksandrs Slivkins. Introduction to multi-armed bandits. Foundations and Trends® in Machine Learning, 12(1-2):1– 286, 2019. 12
2019
-
[50]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Ab- hishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equa- tions.arXiv preprint arXiv:2011.13456, 2020. 1
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[51]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. InProceedings of the 40th International Conference on Machine Learning, pages 32211–32252, 2023. 2
2023
-
[52]
Patient knowledge distillation for bert model compression
Siqi Sun, Yu Cheng, Zhe Gan, and Jingjing Liu. Patient knowledge distillation for bert model compression. InPro- ceedings of the 2019 conference on empirical methods in nat- ural language processing and the 9th international joint con- ference on natural language processing (EMNLP-IJCNLP), pages 4323–4332, 2019. 2
2019
-
[53]
Adapt- ing to non-stationary environments: Multi-armed ban- dit enhanced retrieval-augmented generation on knowledge graphs
Xiaqiang Tang, Jian Li, Nan Du, and Sihong Xie. Adapt- ing to non-stationary environments: Multi-armed ban- dit enhanced retrieval-augmented generation on knowledge graphs. InProceedings of the AAAI Conference on Artificial Intelligence, pages 12658–12666, 2025. 12
2025
-
[54]
Learning to discretize denois- ing diffusion odes
Vinh Tong, Trung-Dung Hoang, Anji Liu, Guy Van den Broeck, and Mathias Niepert. Learning to discretize denois- ing diffusion odes. InProceedings of the 13th International Conference on Learning Representations, 2025. 2
2025
-
[55]
Training data-efficient image transformers & distillation through at- tention
Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, and Herv ´e J´egou. Training data-efficient image transformers & distillation through at- tention. InInternational conference on machine learning, pages 10347–10357. PMLR, 2021. 2
2021
-
[56]
Morad Tukan, Loay Mualem, Eitan Netzer, and Liran Sigalat. Improving model classification by optimizing the training dataset.arXiv preprint arXiv:2507.16729, 2025. 12
-
[57]
Dkdm: Data-free knowledge dis- tillation for diffusion models with any architecture
Qianlong Xiang, Miao Zhang, Yuzhang Shang, Jianlong Wu, Yan Yan, and Liqiang Nie. Dkdm: Data-free knowledge dis- tillation for diffusion models with any architecture. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2955–2965, 2025. 2
2025
-
[58]
Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer
Enze Xie, Junsong Chen, Yuyang Zhao, Jincheng Yu, Ligeng Zhu, Yujun Lin, Zhekai Zhang, Muyang Li, Junyu Chen, Han Cai, et al. Sana 1.5: Efficient scaling of training-time and inference-time compute in linear diffusion transformer. InInternational Conference on Machine Learning, pages 68578–68598. PMLR, 2025. 2
2025
-
[59]
Em distillation for one-step diffusion mod- els.Advances in Neural Information Processing Systems, 37: 45073–45104, 2024
Sirui Xie, Zhisheng Xiao, Diederik Kingma, Tingbo Hou, Ying Nian Wu, Kevin P Murphy, Tim Salimans, Ben Poole, and Ruiqi Gao. Em distillation for one-step diffusion mod- els.Advances in Neural Information Processing Systems, 37: 45073–45104, 2024. 1, 2
2024
-
[60]
Knowledge distillation via softmax regres- sion representation learning
Jing Yang, Brais Martinez, Adrian Bulat, and Georgios Tz- imiropoulos. Knowledge distillation via softmax regres- sion representation learning. InInternational conference on learning representations, 2021. 1, 2
2021
-
[61]
One-step diffusion with distribution matching distillation
Tianwei Yin, Micha ¨el Gharbi, Richard Zhang, Eli Shecht- man, Fredo Durand, William T Freeman, and Taesung Park. One-step diffusion with distribution matching distillation. In Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, pages 6613–6623, 2024. 1, 2
2024
-
[62]
arXiv preprint arXiv:2204.13902 (2022)
Qinsheng Zhang and Yongxin Chen. Fast sampling of dif- fusion models with exponential integrator.arXiv preprint arXiv:2204.13902, 2022. 2
-
[63]
Decoupled knowledge distillation
Borui Zhao, Quan Cui, Renjie Song, Yiyu Qiu, and Jiajun Liang. Decoupled knowledge distillation. InProceedings of the IEEE/CVF Conference on computer vision and pattern recognition, pages 11953–11962, 2022. 1, 2
2022
-
[64]
Unipc: A unified predictor-corrector framework for fast sampling of diffusion models.Advances in Neural Information Processing Systems, 36:49842–49869, 2023
Wenliang Zhao, Lujia Bai, Yongming Rao, Jie Zhou, and Jiwen Lu. Unipc: A unified predictor-corrector framework for fast sampling of diffusion models.Advances in Neural Information Processing Systems, 36:49842–49869, 2023. 2
2023
-
[65]
Dpm- solver-v3: Improved diffusion ode solver with empirical model statistics.Advances in Neural Information Process- ing Systems, 36:55502–55542, 2023
Kaiwen Zheng, Cheng Lu, Jianfei Chen, and Jun Zhu. Dpm- solver-v3: Improved diffusion ode solver with empirical model statistics.Advances in Neural Information Process- ing Systems, 36:55502–55542, 2023. 2
2023
-
[66]
Rethinking soft labels for knowledge distillation: A bias–variance tradeoff perspec- tive
Helong Zhou and Liangchen Song. Rethinking soft labels for knowledge distillation: A bias–variance tradeoff perspec- tive. InProceedings of International Conference on Learn- ing Representations (ICLR), 2021. 1, 2
2021
-
[67]
Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation
Mingyuan Zhou, Huangjie Zheng, Zhendong Wang, Mingzhang Yin, and Hai Huang. Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation. InForty-first International Confer- ence on Machine Learning, 2024. 1, 2
2024
-
[68]
Dip-go: A diffusion pruner via few-step gradient optimiza- tion.Advances in Neural Information Processing Systems, 37:92581–92604, 2024
Haowei Zhu, Dehua Tang, Ji Liu, Mingjie Lu, Jintu Zheng, Jinzhang Peng, Dong Li, Yu Wang, Fan Jiang, Lu Tian, et al. Dip-go: A diffusion pruner via few-step gradient optimiza- tion.Advances in Neural Information Processing Systems, 37:92581–92604, 2024. 2 11 A. Additional Related Work Relation to bandit-style allocation.ARIA can be interpreted through a m...
2024
-
[69]
Embed all prompts using the CLIP text encoder, obtainingX={x i}N i=1 ⊂R d
-
[70]
Runk-means++ withK max centers onXto obtain a bicriteria solution
-
[71]
Compute sensitivity upper bounds using the bicriteria solution, and sample a weighted coreset(S, w)
-
[72]
For each candidate number of clustersk∈ K: (a) run weightedk-means on(S, w)withkclusters; (b) compute the corresponding silhouette scoreSil (S,w)(k)
-
[73]
Select ˆk= arg max k∈K Sil(S,w)(k)
-
[74]
Runk-means on the full embedding set withk= ˆkand use the resulting partition to define the semantic regions. Setting VariantFID↓IS↑CLIP↑ BaselineUniform (RC) 15.16 35.90 29.15 Sampling mapping Softmax13.8236.5229.28 Power-law 14.7036.5729.25 # RegionsK 20014.51 35.94 29.18 40513.82 36.5229.28 200014.92 36.3629.31 Tracked discrepancy Lout 13.82 36.52 29.2...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.