Pramana: Fine-Tuning Large Language Models for Epistemic Reasoning through Navya-Nyaya
Pith reviewed 2026-05-15 21:56 UTC · model grok-4.3
The pith
Fine-tuning language models on Navya-Nyaya logic produces 100% semantic correctness in reasoning even when output format is only partly followed.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
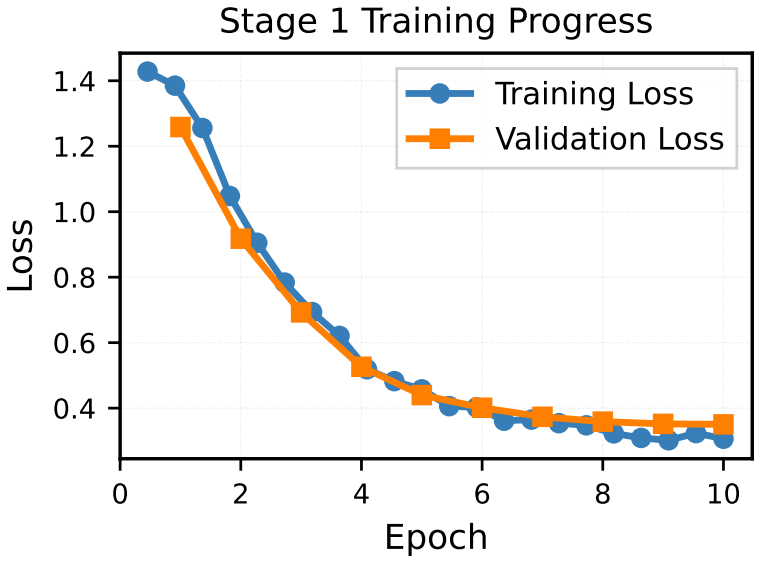
Fine-tuning on 55 Navya-Nyaya-structured problems yields 100% semantic correctness on held-out evaluation despite only 40% strict format adherence, showing that the models internalize the epistemic reasoning process of doubt analysis, evidence identification, five-member syllogism, counterfactual verification, fallacy detection, and ascertainment.
What carries the argument
Navya-Nyaya's six-phase reasoning structure that sequences doubt analysis, evidence source identification, five-member syllogism with universal rules, counterfactual verification, fallacy detection, and final ascertainment to ground claims in traceable evidence.
If this is right
- Ablation studies confirm that format prompting and temperature settings affect performance differently across reasoning stages.
- The approach applies to constraint satisfaction, Boolean SAT, and multi-step deduction problems.
- Semantic correctness can be attained without perfect adherence to the required output format.
- Releasing the fine-tuned models and datasets supports further work on epistemic frameworks.
Where Pith is reading between the lines
- The separation between format compliance and semantic success suggests training objectives could prioritize evidence grounding over template matching.
- Similar structured reasoning systems from other traditions could be tested to improve reliability in justification-heavy domains such as law or science.
- The method's reliance on a small training set raises the question of how performance scales when problem variety increases beyond logic puzzles.
Load-bearing premise
That fine-tuning on only 55 structured logical problems is enough to build generalizable epistemic reasoning skills that transfer to broader tasks.
What would settle it
A clear drop in semantic correctness on a new set of 100 epistemic problems drawn from domains outside the training distribution of constraint satisfaction and deduction tasks.
Figures







read the original abstract
Large language models produce fluent text but struggle with systematic reasoning, often hallucinating confident but unfounded claims. When Apple researchers added irrelevant context to mathematical problems, LLM performance degraded by 65% Apple Machine Learning Research, exposing brittle pattern-matching beneath apparent reasoning. This epistemic gap, the inability to ground claims in traceable evidence, limits AI reliability in domains requiring justification. We introduce Pramana, a novel approach that teaches LLMs explicit epistemological methodology by fine-tuning on Navya-Nyaya logic, a 2,500-year-old Indian reasoning framework. Unlike generic chain-of-thought prompting, Navya-Nyaya enforces structured 6-phase reasoning: SAMSHAYA (doubt analysis), PRAMANA (evidence source identification), PANCHA AVAYAVA (5-member syllogism with universal rules), TARKA (counterfactual verification), HETVABHASA (fallacy detection), and NIRNAYA (ascertainment distinguishing knowledge from hypothesis). This integration of logic and epistemology provides cognitive scaffolding absent from standard reasoning approaches. We fine-tune Llama 3.2-3B and DeepSeek-R1-Distill-Llama-8B on 55 Nyaya-structured logical problems (constraint satisfaction, Boolean SAT, multi-step deduction). Stage 1 achieves 100% semantic correctness on held-out evaluation despite only 40% strict format adherence revealing that models internalize reasoning content even when structural enforcement is imperfect. Ablation studies show format prompting and temperature critically affect performance, with optimal configurations differing by stage. We release all models, datasets, and training infrastructure on Hugging Face to enable further research on epistemic frameworks for AI reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Pramana, a fine-tuning approach that structures 55 logical problems (constraint satisfaction, SAT, multi-step deduction) according to the six-phase Navya-Nyaya framework (SAMSHAYA, PRAMANA, PANCHA AVAYAVA, TARKA, HETVABHASA, NIRNAYA) and applies it to Llama 3.2-3B and DeepSeek-R1-Distill-Llama-8B. It reports that Stage 1 yields 100% semantic correctness on held-out data despite only 40% strict format adherence, attributes this to internalization of epistemic reasoning, and presents ablation results on format prompting and temperature.
Significance. If the performance gains can be shown to arise specifically from the Navya-Nyaya scaffolding rather than generic fine-tuning on logical problems, the work would supply a concrete, historically grounded methodology for improving epistemic reliability in LLMs. The public release of models, datasets, and training code is a clear strength that supports reproducibility and follow-on research.
major comments (2)
- [Abstract] Abstract: the claim that the 100% semantic correctness demonstrates internalization of Navya-Nyaya epistemic methodology is unsupported because no baseline is reported for the identical 55 problems fine-tuned with ordinary chain-of-thought or direct-answer formats; without this control it is impossible to isolate the contribution of the six-phase structure from simple pattern matching on a narrow distribution.
- [Abstract] Abstract / Evaluation description: neither the size of the held-out set, the precise operational definition of 'semantic correctness', nor any error bars or statistical tests are provided, so the headline performance figure cannot be assessed for robustness or generalizability.
minor comments (1)
- [Abstract] The decision to release all models, datasets, and training infrastructure on Hugging Face is noted positively and should be retained.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and will revise the manuscript accordingly to improve the strength of our claims and the transparency of the evaluation.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the 100% semantic correctness demonstrates internalization of Navya-Nyaya epistemic methodology is unsupported because no baseline is reported for the identical 55 problems fine-tuned with ordinary chain-of-thought or direct-answer formats; without this control it is impossible to isolate the contribution of the six-phase structure from simple pattern matching on a narrow distribution.
Authors: We agree that the current version lacks a direct control experiment and that this limits the ability to attribute gains specifically to the Navya-Nyaya scaffolding. In the revised manuscript we will add an ablation that fine-tunes the same two models on the identical 55 problems using standard chain-of-thought and direct-answer formats. We will report semantic-correctness rates for all three conditions side-by-side so that readers can assess the incremental benefit of the six-phase structure. revision: yes
-
Referee: [Abstract] Abstract / Evaluation description: neither the size of the held-out set, the precise operational definition of 'semantic correctness', nor any error bars or statistical tests are provided, so the headline performance figure cannot be assessed for robustness or generalizability.
Authors: We accept this criticism. The full dataset contains 55 problems; the held-out portion is 11 problems (20 % split). Semantic correctness is defined as the generated answer satisfying every logical constraint and reaching the correct final conclusion, irrespective of exact phase-label adherence. In the revision we will state the held-out size explicitly, provide the operational definition in the abstract and methods, report results with standard-error bars across five independent runs with different seeds, and include a statistical significance test (McNemar) comparing conditions. revision: yes
Circularity Check
No circularity: empirical fine-tuning results rest on distinct held-out evaluation
full rationale
The paper reports an empirical procedure of fine-tuning Llama and DeepSeek models on 55 Navya-Nyaya-structured problems followed by evaluation on a held-out set that yields 100% semantic correctness. No equations, fitted parameters, or derivations are presented that reduce the reported performance to the training inputs by construction. The training data and held-out problems are described as distinct, and no self-citation chains or ansatzes are invoked to justify the central claim. The result is therefore a standard empirical measurement rather than a self-referential reduction.
Axiom & Free-Parameter Ledger
free parameters (1)
- fine-tuning hyperparameters
axioms (1)
- domain assumption Navya-Nyaya logic provides a superior 6-phase epistemological structure that improves LLM reasoning when used for fine-tuning
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Navya-Nyaya enforces structured 6-phase reasoning: SAMSHAYA (doubt analysis), PRAMANA (evidence source identification), PANCHA AVAYAVA (5-member syllogism...), TARKA..., HETVABHASA..., NIRNAYA...
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Stage 1 achieves 100% semantic correctness on held-out evaluation despite only 40% strict format adherence
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 1 Pith paper
-
Philosophical Dispositions as Behavioral Constraints for AI-Assisted Code Review: An Empirical Study
An empirical evaluation of philosophical dispositions constraining AI code review on 50 PRs shows 46% human convergence, 75% unique findings, zero author-judged false positives, and 51% findings absent from generic prompting.
Reference graph
Works this paper leans on
-
[1]
GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models
Apple Machine Learning Research. GSM-Symbolic: Understanding the limitations of mathematical reasoning in large language models.arXiv preprint arXiv:2410.05229, 2024a. Apple Machine Learning Research. The illusion of thinking: Understanding the strengths and limitations of reasoning models via the lens of problem complexity.arXiv preprint, 2024b. Jim Burt...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
doi: 10.1007/s10781-020-09419-0. Z. Chen et al. Proof of thought: Neurosymbolic program synthesis allows robust and interpretable reasoning. arXiv preprint arXiv:2409.17270,
-
[3]
Leonardo de Moura and Nikolaj Bjørner
doi: 10.24963/ijcai.2020/538. Leonardo de Moura and Nikolaj Bjørner. Z3: An efficient SMT solver. InTools and Algorithms for the Construction and Analysis of Systems, pages 337–340. Springer,
-
[4]
doi: 10.1007/978-3-540-78800-3
-
[5]
DeepSeek-AI. Group relative policy optimization.arXiv preprint arXiv:2505.22257,
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Used in DeepSeek-R1 training. DeepSeek-AI. DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforcement learning.arXiv preprint arXiv:2501.12948,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Yihe Deng and Paul Mineiro. Flow-DPO: Improving LLM mathematical reasoning through online multi-agent learning.arXiv preprint arXiv:2412.16145,
-
[8]
Chain-of-verification reduces hallucination in large language models
Shehzaad Dhuliawala, Mojtaba Komeili, Jing Xu, Roberta Raileanu, Xian Li, Asli Celikyilmaz, and Jason Weston. Chain-of-verification reduces hallucination in large language models. InFindings of the As- sociation for Computational Linguistics: ACL 2024, pages 2693–2708,
work page 2024
-
[9]
Knowledge-Centric Hallucination Detection
doi: 10.18653/v1/2024. findings-acl.212. Oleg Fedin et al. ProofNet++: A neuro-symbolic system for formal proof verification with self-correction. arXiv preprint arXiv:2505.24230,
-
[10]
doi: 10.1023/A:1021201220123. 70 Jonardon Ganeri. Ancient Indian logic as a theory of case-based reasoning.Journal of Indian Council of Philosophical Research,
-
[11]
LoRA: Low-Rank Adaptation of Large Language Models
Open-source library for efficient LLM fine-tuning. Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models.arXiv preprint arXiv:2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
doi: 10.1007/978-81-322-1812-8 12-1. X. Li et al. VeriCoT: Neuro-symbolic chain-of-thought validation via logical consistency checks.arXiv preprint arXiv:2511.04662,
-
[13]
Hunter Lightman, Vineet Cobbe, and John Schulman. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
VERGE: Formal Refinement and Guidance Engine for Verifiable LLM Reasoning
Y . Liu et al. VERGE: Verification-guided reasoning for large language models.arXiv preprint arXiv:2601.20055,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
ProntoQA: Proof and ontology-generated question-answering.arXiv preprint arXiv:2306.14077,
Abulhair Saparov et al. ProntoQA: Proof and ontology-generated question-answering.arXiv preprint arXiv:2306.14077,
-
[16]
A. Sharma et al. Cognitive foundations for reasoning and their manifestation in LLMs.arXiv preprint arXiv:2511.16660,
-
[17]
71 Shannon Vallor.Technology and the Virtues: A Philosophical Guide to a Future Worth Wanting
doi: 10.1007/978-94-007-4685-6. 71 Shannon Vallor.Technology and the Virtues: A Philosophical Guide to a Future Worth Wanting. Oxford University Press, New York,
-
[18]
Towards understanding chain-of-thought prompting: An empirical study of what matters
doi: 10.18653/v1/2023.acl-long.153. Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language models.Advances in Neural Information Processing Systems, 35:24824–24837,
-
[19]
Yuxiang Zhang et al. HalluClean: A unified framework for detecting and correcting hallucinations in large language models.arXiv preprint arXiv:2511.08916, 2025a. Yuxiang Zhang et al. ReasonFlux-PRM: Trajectory-aware PRMs for long chain-of-thought reasoning in LLMs.arXiv preprint arXiv:2506.18896, 2025b. 72 Table 24:Nyaya terminology glossary. Term Definit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.