WattLayer: Get Layers Right to Estimate Inference Energy of Neural Networks
Pith reviewed 2026-06-29 04:45 UTC · model grok-4.3
The pith
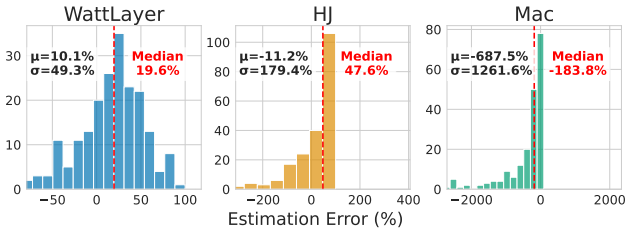
A layer-wise model estimates neural network inference energy at 19.6 percent median error across architectures and hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
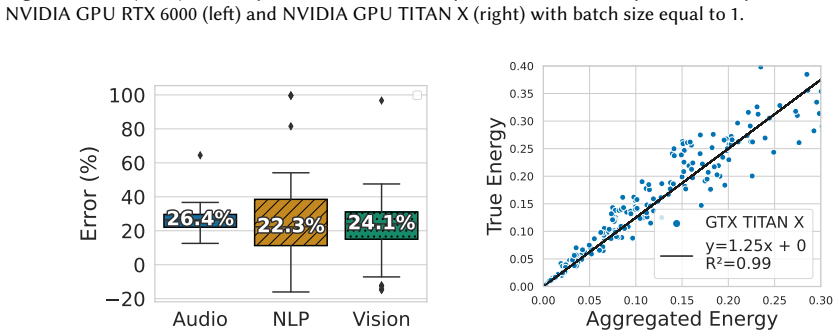
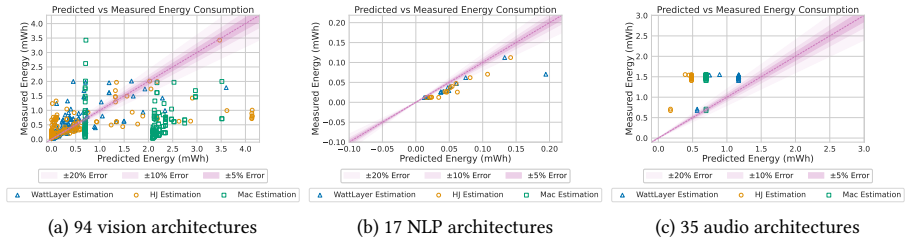
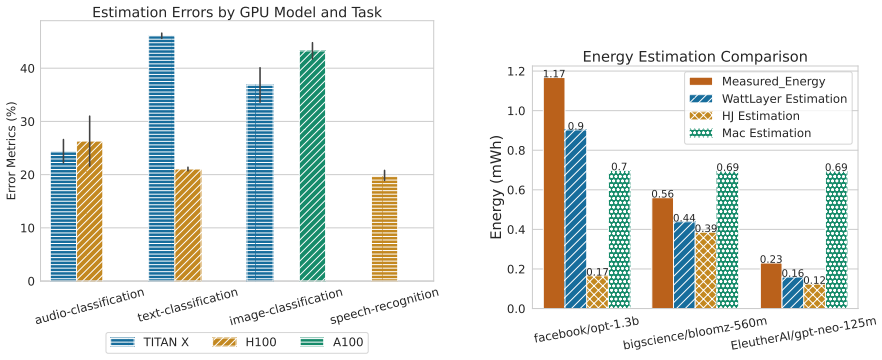
The authors introduce a layer-wise energy estimation model that decomposes inference energy into per-layer contributions using a dataset collected across many architectures, tasks, and hardware platforms. This model achieves a median error of 19.6 percent and outperforms prior techniques while also generalizing to new tasks without complete retraining by exploiting layers shared across different architectures.
What carries the argument
WattLayer, a task-independent layer-wise energy estimation model trained on per-layer execution measurements.
If this is right
- Energy estimates improve for a broad range of neural network designs without building separate models per task.
- Shared layers allow energy predictions to extend to unseen tasks by reusing existing layer data.
- Designers can inspect individual layer contributions to identify high-energy components in a network.
- A standardized methodology becomes available for comparing energy use across different architectures and platforms.
Where Pith is reading between the lines
- The decomposition could support direct hardware comparisons by isolating layer costs from full-system measurements.
- Model developers might use the layer profiles to swap high-cost layers for lower-cost alternatives during architecture search.
- If extended, the same layer data could help estimate energy differences between training and inference phases.
Load-bearing premise
That a single set of layer energy values collected from one set of tasks and hardware remains predictive for new tasks, architectures, and platforms without any additional task-specific retraining or hardware calibration.
What would settle it
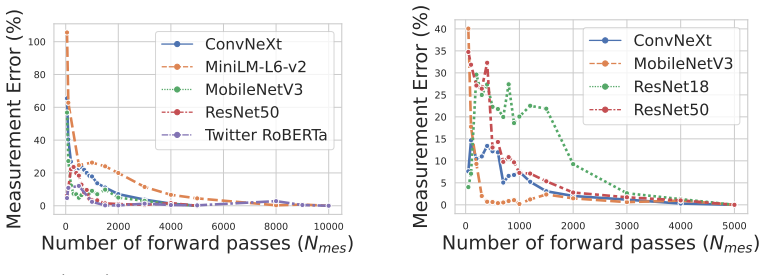
Running a new architecture on one of the tested hardware platforms, measuring its actual layer energies, and obtaining a median prediction error clearly above 19.6 percent.
Figures

read the original abstract
The widespread adoption of Artificial Intelligence (AI) has led to increasing concerns about energy consumption, yet there is a lack of standardized methodologies to accurately estimate AI inference energy consumption, particularly across various tasks and architectures. In this study, we propose a task independent, layer-wise energy estimation model for AI architectures. Our model is evaluated on a large dataset of more than 100,000 layers for 295 neural network architectures across 3 widely-used tasks and 3 distinct hardware platforms. Our approach achieves a median error of 19.6%, outperforming state-of-the-art methods. We further show that layer-wise decomposition generalize to new tasks without complete retraining, by leveraging shared layers across architectures. It offer tools, insights and a precise methodology to empower stakeholders in designing energy-efficient AI systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
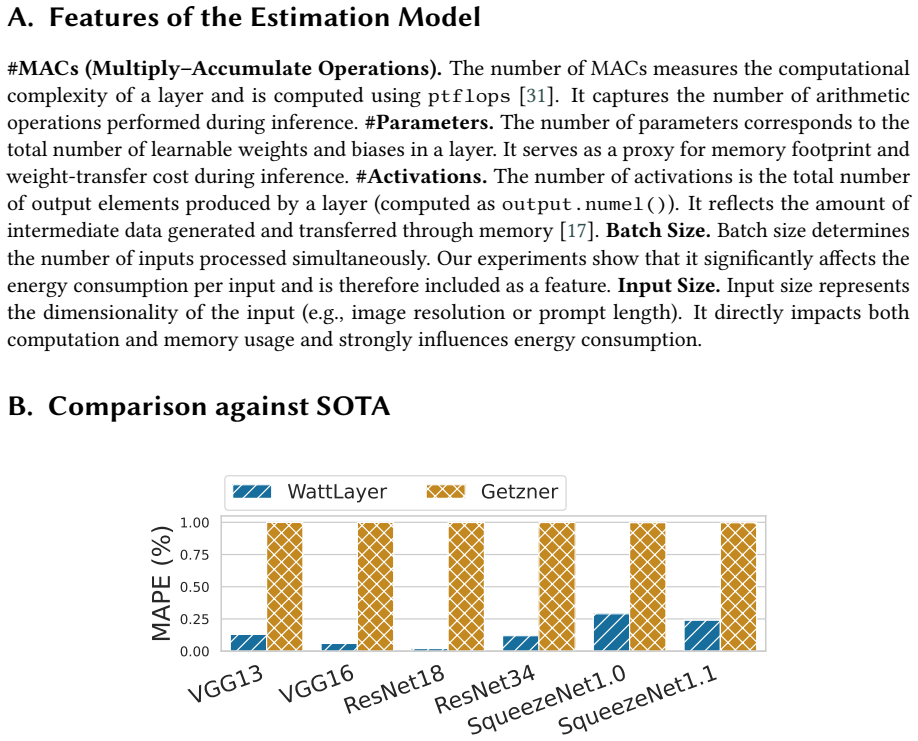
Summary. The paper proposes WattLayer, a task-independent layer-wise energy estimation model for neural network inference. It evaluates the model on a dataset of more than 100,000 layers drawn from 295 architectures spanning 3 tasks and 3 hardware platforms, reporting a median error of 19.6% that outperforms prior state-of-the-art methods. The work further claims that the layer-wise decomposition generalizes to new tasks without complete retraining by exploiting shared layers across architectures.
Significance. If the reported error rates and generalization results hold under rigorous scrutiny, the work would supply a practical, standardized methodology for estimating inference energy across diverse models and platforms, directly supporting energy-efficient AI design. The scale of the collected layer dataset (>100k entries) constitutes a clear empirical strength.
major comments (2)
- [Evaluation] Evaluation section: the manuscript provides no details on layer dataset construction, train/test splits across tasks and hardware, the precise definition of the median error metric, presence or absence of error bars, or any exclusion criteria. Without these elements it is impossible to determine whether the 19.6% median error claim is reproducible or supports the central assertion of task-independent accuracy.
- [Generalization experiments] Generalization experiments: the claim that layer-wise decomposition generalizes to new tasks without retraining via shared layers is load-bearing for the task-independence thesis, yet the manuscript supplies no quantitative cross-task results, description of how shared layers are identified or leveraged, or controls for architecture overlap. This leaves the generalization result unverifiable.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important areas where additional clarity is needed to strengthen the reproducibility of our results. We address each major comment below and commit to revisions that will incorporate the requested details without altering the core claims of the work.
read point-by-point responses
-
Referee: [Evaluation] Evaluation section: the manuscript provides no details on layer dataset construction, train/test splits across tasks and hardware, the precise definition of the median error metric, presence or absence of error bars, or any exclusion criteria. Without these elements it is impossible to determine whether the 19.6% median error claim is reproducible or supports the central assertion of task-independent accuracy.
Authors: We agree that the current manuscript does not provide sufficient methodological details on these aspects. In the revised version, we will add a new subsection in the Evaluation section that explicitly describes: (1) the layer dataset construction process, including how layers were extracted and profiled from the 295 architectures; (2) the train/test split methodology, ensuring separation across the 3 tasks and 3 hardware platforms with no data leakage; (3) the precise definition of the median error as the median of per-layer absolute percentage errors; (4) the inclusion of error bars (e.g., interquartile ranges or standard deviations across multiple runs); and (5) any exclusion criteria applied (such as filtering layers with energy below a measurable threshold). These additions will directly support reproducibility of the reported 19.6% median error. revision: yes
-
Referee: [Generalization experiments] Generalization experiments: the claim that layer-wise decomposition generalizes to new tasks without retraining via shared layers is load-bearing for the task-independence thesis, yet the manuscript supplies no quantitative cross-task results, description of how shared layers are identified or leveraged, or controls for architecture overlap. This leaves the generalization result unverifiable.
Authors: The manuscript states that layer-wise decomposition generalizes to new tasks by leveraging shared layers, but we acknowledge the lack of detailed quantitative support and controls in the current text. In revision, we will expand the relevant section to include: quantitative cross-task results (e.g., median errors when training on two tasks and evaluating on the held-out task); the exact procedure for identifying shared layers (matching on layer type, input/output dimensions, and operation parameters); how shared layers are leveraged (by reusing model parameters trained on common layers without retraining); and controls for architecture overlap (ensuring no identical architectures appear in both training and test sets across tasks). If additional experiments are required to generate these metrics, they will be performed and reported. revision: yes
Circularity Check
No significant circularity
full rationale
The paper proposes an empirical task-independent layer-wise energy estimation model trained and evaluated on a collected dataset of >100k layers from 295 architectures across tasks and hardware. The central claims are measured performance (median error 19.6%) and generalization via shared layers, which are statistical outcomes of fitting and testing rather than any derivation that reduces to its own inputs by construction. No equations, self-definitional steps, fitted-input predictions, or load-bearing self-citations are present in the provided abstract or description. The work is self-contained against external benchmarks (real measurements on multiple platforms) and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
N. Maslej, L. Fattorini, R. Perrault, Y. Gil, V. Parli, N. Kariuki, E. Capstick, A. Reuel, E. Brynjolfsson, J. Etchemendy, K. Ligett, T. Lyons, J. Manyika, J. C. Niebles, Y. Shoham, R. Wald, T. Walsh, A. Hamrah, L. Santarlasci, J. B. Lotufo, A. Rome, A. Shi, S. Oak, Artificial intelligence index report 2025, 2025. URL: https://arxiv.org/abs/2504.07139.arX...
arXiv 2025
-
[2]
D. Patterson, J. Gonzalez, U. Hölzle, Q. Le, C. Liang, L.-M. Munguia, D. Rothchild, D. So, M. Texier, J. Dean, The carbon footprint of machine learning training will plateau, then shrink, 2022. URL: http: //arxiv.org/abs/2204.05149. doi:10.48550/arXiv.2204.05149.arXiv:2204.05149 [cs]
work page doi:10.48550/arxiv.2204.05149.arxiv:2204.05149 2022
-
[3]
S. Luccioni, Y. Jernite, E. Strubell, Power hungry processing: Watts driving the cost of AI deploy- ment?, in: Proceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, Rio de Janeiro, Brazil, 2024, pp. 85–99. doi:10.1145/3630106.3658542
-
[4]
C.-J. Wu, R. Raghavendra, U. Gupta, B. Acun, N. Ardalani, K. Maeng, G. Chang, F. A. Behram, J. Huang, C. Bai, M. Gschwind, A. Gupta, M. Ott, A. Melnikov, S. Candido, D. Brooks, G. Chauhan, B. Lee, H.-H. S. Lee, B. Akyildiz, M. Balandat, J. Spisak, R. Jain, M. Rabbat, K. Hazelwood, Sustainable AI: Environmental implications, challenges and opportunities, 2...
work page doi:10.48550/arxiv.2111.00364.arxiv:2111.00364 2022
-
[5]
De Chateauvieux, E
B. De Chateauvieux, E. Pick, D. Ferguson, B. Sisson, Optimize AI/ML work- loads for sustainability: Part 3, deployment and monitoring, 2022. URL https://aws.amazon.com/blogs/architecture/optimize-ai-ml-workloads-for-sustainability- part-3-deployment-and-monitoring/
2022
-
[7]
URL https://mistral.ai/news/our-contribution-to-a-global-environmental-standard-for-ai
MistralAI, Our contribution to a global environmental standard for AI, 2025. URL https://mistral.ai/news/our-contribution-to-a-global-environmental-standard-for-ai
2025
-
[8]
M. Dubois, M. Annavaram, P. Stenström, Parallel Computer Organization and Design, Cambridge University Press, 2012. doi:10.1017/CBO9781139051224
-
[9]
C. Rodriguez, L. Degioanni, L. Kameni, R. Vidal, G. Neglia, Evaluating the energy consumption of machine learning: Systematic literature review and experiments, 2024. URL: http://arxiv.org/abs/ 2408.15128. doi:10.48550/arXiv.2408.15128.arXiv:2408.15128 [cs]
work page doi:10.48550/arxiv.2408.15128.arxiv:2408.15128 2024
-
[10]
R. Saborido, V. V. Arnaoudova, G. Beltrame, F. Khomh, G. Antoniol, On the impact of sampling frequency on software energy measurements, 2015. URL: https://peerj.com/preprints/1219v2. doi:10.7287/peerj.preprints.1219v2
-
[11]
Z. Yang, K. Adamek, W. Armour, Part-time power measurements: nvidia-smi’s lack of attention, 2024. URL: http://arxiv.org/abs/2312.02741v2. doi: 10.48550/arXiv.2312.02741. arXiv:2312.02741 [cs]
-
[12]
D. Li, X. Chen, M. Becchi, Z. Zong, Evaluating the energy efficiency of deep convolutional neural networks on CPUs and GPUs, in: IEEE BDCloud-SocialCom-SustainCom, 2016, pp. 477–484. doi:10.1109/BDCloud-SocialCom-SustainCom.2016.76
work page doi:10.1109/bdcloud-socialcom-sustaincom.2016.76 2016
-
[13]
Rodrigues, G
C. Rodrigues, G. Riley, M. Luján, SyNERGY: An energy measurement and prediction framework for convolutional neural networks on Jetson TX1, in: 24th International Conference on Parallel and Distributed Processing Techniques and Applications, 2018
2018
-
[14]
S. Goel, M. Balakrishnan, R. Sen, EnergyNN: Energy estimation for neural network inference tasks on DPU, in: 2021 31st International Conference on Field-Programmable Logic and Applications (FPL), Dresden, Germany, 2021, pp. 64–68. doi:10.1109/FPL53798.2021.00019
-
[15]
R. Desislavov, F. Martínez-Plumed, J. Hernández-Orallo, Trends in AI inference energy con- sumption: Beyond the performance-vs-parameter laws of deep learning, Sustainable Computing: Informatics and Systems 38 (2023) 100857. doi:10.1016/j.suscom.2023.100857
-
[16]
J. Getzner, B. Charpentier, S. Günnemann, Accuracy is not the only metric that matters: Estimating the energy consumption of deep learning models, 2023. URL: http://arxiv.org/abs/2304.00897. doi:10.48550/arXiv.2304.00897.arXiv:2304.00897 [cs]
work page doi:10.48550/arxiv.2304.00897.arxiv:2304.00897 2023
-
[17]
V. Sze, Y.-H. Chen, T.-J. Yang, J. S. Emer, Efficient processing of deep neural networks: A tutorial and survey, Proceedings of the IEEE 105 (2017) 2295–2329. doi:10.1109/JPROC.2017.2761740
-
[18]
Z. Yang, W. Armour, The hidden Joules: Evaluating the energy consumption of vision backbones for progress towards more efficient model inference, in: ICML 2025 - 42nd International Conference on Machine Learning, 2025. URL: https://bytez.com/docs/icml/45063/paper
2025
-
[19]
NeuralPower: Predict and Deploy Energy-Efficient Convolutional Neural Networks
E. Cai, D.-C. Juan, D. Stamoulis, D. Marculescu, NeuralPower: Predict and deploy energy-efficient convolutional neural networks, 2017. URL: http://arxiv.org/abs/1710.05420. doi:10.48550/arXiv. 1710.05420.arXiv:1710.05420 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2017
-
[20]
J. Zhang, Z. Wang, H. Wang, T. Song, H.-a. Su, R. Chen, Y. Hua, X. Zhou, R. Ma, M. Pan, H. Guan, AMPERE: A generic energy estimation approach for on-device training, SIGMETRICS Perform. Eval. Rev. 53 (2025) 27–32. doi:10.1145/3764944.3764951, aCM SIGMETRICS 2025 Workshop - AI Crossroads: Systems, Energy, and Applications
-
[21]
B. Courty, V. Schmidt, S. Luccioni, Goyal-Kamal, MarionCoutarel, B. Feld, J. Lecourt, LiamConnell, A. Saboni, Inimaz, supatomic, M. Léval, L. Blanche, A. Cruveiller, ouminasara, F. Zhao, A. Joshi, A. Bogroff, H. de Lavoreille, N. Laskaris, E. Abati, D. Blank, Z. Wang, A. Catovic, M. Alencon, M. Stechly, C. Bauer, L. O. N. de Araújo, JPW, MinervaBooks, mlc...
-
[22]
Wightman, Pytorch image models, https://github.com/rwightman/pytorch-image-models, 2019
R. Wightman, Pytorch image models, https://github.com/rwightman/pytorch-image-models, 2019. doi:10.5281/zenodo.4414861
-
[23]
T. Wolf, L. Debut, V. Sanh, J. Chaumond, C. Delangue, A. Moi, P. Cistac, T. Rault, R. Louf, M. Fun- towicz, J. Davison, S. Shleifer, P. von Platen, C. Ma, Y. Jernite, J. Plu, C. Xu, T. Le Scao, S. Gugger, M. Drame, Q. Lhoest, A. Rush, Transformers: State-of-the-art natural language processing, in: Proceedings of the 2020 Conference on Empirical Methods in...
-
[24]
TorchVision maintainers, contributors, Torchvision: Pytorch’s computer vision library, https: //github.com/pytorch/vision, 2016
2016
-
[25]
K. He, X. Zhang, S. Ren, J. Sun, [resnet] deep residual learning for image recognition, 2015. URL: http://arxiv.org/abs/1512.03385. doi:10.48550/arXiv.1512.03385. arXiv:1512.03385 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1512.03385 2015
-
[26]
OPT: Open Pre-trained Transformer Language Models
S. Zhang, S. Roller, N. Goyal, M. Artetxe, M. Chen, S. Chen, C. Dewan, M. Diab, X. Li, X. V. Lin, T. Mihaylov, M. Ott, S. Shleifer, K. Shuster, D. Simig, P. S. Koura, A. Sridhar, T. Wang, L. Zettlemoyer, OPT: Open pre-trained transformer language models, 2022. URL: http://arxiv.org/abs/2205.01068. doi:10.48550/arXiv.2205.01068.arXiv:2205.01068 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2205.01068.arxiv:2205.01068 2022
-
[27]
N. Muennighoff, T. Wang, L. Sutawika, A. Roberts, S. Biderman, T. L. Scao, M. S. Bari, S. Shen, Z.-X. Yong, H. Schoelkopf, X. Tang, D. Radev, A. F. Aji, K. Almubarak, S. Albanie, Z. Alyafeai, A. Webson, E. Raff, C. Raffel, Crosslingual generalization through multitask finetuning, 2022. URL: http://arxiv.org/abs/2211.01786. doi:10.48550/arXiv.2211.01786
-
[28]
S. Black, G. Leo, P. Wang, C. Leahy, S. Biderman, GPT-Neo: Large Scale Autoregressive Language Modeling with Mesh-Tensorflow, 2021. URL: https://doi.org/10.5281/zenodo.5297715. doi:10.5281/zenodo.5297715
-
[29]
L. Gao, S. Biderman, S. Black, L. Golding, T. Hoppe, C. Foster, J. Phang, H. He, A. Thite, N. Nabeshima, et al., The Pile: An 800GB dataset of diverse text for language modeling, 2020. URL: https://doi.org/10.48550/arXiv.2101.00027. doi:10.48550/arXiv.2101.00027
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2101.00027 2020
-
[30]
M. Z. a. Mayaki, V. Charpenay, Modeling energy consumption in deep learning architectures using power laws, IOS Press, 2025. URL: https://hal.science/hal-04977474. doi:10.3233/FAIA250900
-
[31]
Sovrasov, ptflops: a flops counting tool for neural networks in pytorch framework, 2018-2024
V. Sovrasov, ptflops: a flops counting tool for neural networks in pytorch framework, 2018-2024. URL: https://github.com/sovrasov/flops-counter.pytorch. A. Features of the Estimation Model #MACs (Multiply–Accumulate Operations).The number of MACs measures the computational complexity of a layer and is computed using ptflops [31]. It captures the number of...
2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.