Learning to Foresee: Unveiling the Unlocking Efficiency of On-Policy Distillation
Pith reviewed 2026-05-22 10:06 UTC · model grok-4.3
The pith
On-policy distillation establishes a stable update trajectory early, enabling faster training through adaptive extrapolation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
On-policy distillation's efficiency stems from foresight that creates a stable update trajectory toward the final model early in training. This appears as concentrating updates on critical modules and showing stronger low-rank concentration that aligns with the final update subspace from the beginning. These insights lead to EffOPD, a method that adaptively extrapolates along the current update direction to speed up training.
What carries the argument
Foresight in on-policy distillation, shown through module-allocation focus on critical reasoning modules and early low-rank alignment of update directions with the final subspace.
If this is right
- OPD identifies low-utility regions and prioritizes updates on critical modules for reasoning.
- OPD's update directions exhibit stronger low-rank concentration that matches the final model's subspace early on.
- EffOPD uses adaptive extrapolation along the current direction to accelerate OPD by an average of 3 times.
- EffOPD requires no additional trainable modules and no complex hyperparameter tuning while maintaining comparable performance.
- The findings offer a parameter-dynamics view for improving post-training methods for large language models.
Where Pith is reading between the lines
- Similar early trajectory analysis could reveal efficiency sources in other fine-tuning techniques like supervised fine-tuning or reinforcement learning from human feedback.
- Exploiting stable early directions might allow hybrid methods that combine distillation with direct preference optimization.
- Testing the foresight property on different model scales or tasks could show if it scales generally.
- The approach might inspire new optimization algorithms that detect and follow promising trajectories automatically.
Load-bearing premise
The module focus and early low-rank alignment observed in OPD are the direct cause of its efficiency and can be used for extrapolation without reducing final performance or needing extra adjustments.
What would settle it
Running EffOPD on a model and finding that it either slows down training, degrades final performance significantly, or requires extensive tuning to work would challenge the claim.
Figures



























read the original abstract
On-policy distillation (OPD) has emerged as an efficient post-training paradigm for large language models. However, existing studies largely attribute this advantage to denser and more stable supervision, while the parameter-level mechanisms underlying OPD's efficiency remain poorly understood. In this work, we argue that OPD's efficiency stems from a form of ``foresight'': it establishes a stable update trajectory toward the final model early in training. This foresight manifests in two aspects. First, at the \textbf{Module-Allocation Level}, OPD identifies regions with low marginal utility and concentrates updates on modules that are more critical to reasoning. Second, at the \textbf{Update-Direction Level}, OPD exhibits stronger low-rank concentration, with its dominant subspaces aligning closely with the final update subspace early in training. Building on these findings, we propose \textbf{EffOPD}, a plug-and-play acceleration method that speeds up OPD by adaptively selecting an extrapolation step size and moving along the current update direction. EffOPD requires no additional trainable modules or complex hyperparameter tuning, and achieves an average training acceleration of $3\times$ while maintaining comparable final performance. Overall, our findings provide a parameter-dynamics perspective for understanding the efficiency of OPD and offer practical insights for designing more efficient post-training methods for large language models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that on-policy distillation (OPD) for large language models derives its efficiency from a 'foresight' mechanism that establishes a stable update trajectory toward the final model early in training. This manifests at the module-allocation level by concentrating updates on critical reasoning modules (avoiding low marginal utility regions) and at the update-direction level by stronger low-rank concentration whose dominant subspaces align closely with the final update subspace. The authors introduce EffOPD, a plug-and-play acceleration method that adaptively extrapolates along the current update direction, reporting an average 3× training speedup with comparable final performance and no extra trainable modules or complex tuning.
Significance. If the observed module focus and early low-rank alignment are shown to be causal drivers of OPD efficiency (rather than correlates) and if EffOPD's extrapolation proves robust without hidden tuning costs, the work would supply a valuable parameter-dynamics lens on distillation and a practical acceleration recipe for LLM post-training. The emphasis on early trajectory stability could inform other efficient fine-tuning designs.
major comments (2)
- [Sections describing module-allocation and update-direction analyses (around the foresight findings)] The central mechanistic claim—that module concentration and early low-rank subspace alignment causally produce OPD's efficiency and thereby justify safe extrapolation in EffOPD—rests on observational comparisons between OPD and baselines. No intervention experiments appear that selectively disrupt the early alignment (e.g., by injecting controlled noise into early update directions while preserving dense on-policy supervision) to test whether efficiency degrades. This is load-bearing for the justification of EffOPD.
- [EffOPD experiments and results] The reported 3× average acceleration for EffOPD lacks accompanying experimental details such as error bars, number of random seeds, exact task/model suite, and direct compute-matched baselines. Without these, it is difficult to assess whether the speedup is robust or sensitive to the adaptive step-size rule.
minor comments (2)
- [Module-Allocation Level description] The term 'low marginal utility' is used without an explicit operational definition or equation showing how it is computed from the update statistics.
- [Update-Direction Level analysis] Notation for 'dominant subspaces' and 'low-rank concentration' should be formalized with a short equation or pseudocode to improve clarity and reproducibility.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major comment below, clarifying the scope of our claims and committing to specific revisions that strengthen the experimental reporting and discussion of limitations.
read point-by-point responses
-
Referee: [Sections describing module-allocation and update-direction analyses (around the foresight findings)] The central mechanistic claim—that module concentration and early low-rank subspace alignment causally produce OPD's efficiency and thereby justify safe extrapolation in EffOPD—rests on observational comparisons between OPD and baselines. No intervention experiments appear that selectively disrupt the early alignment (e.g., by injecting controlled noise into early update directions while preserving dense on-policy supervision) to test whether efficiency degrades. This is load-bearing for the justification of EffOPD.
Authors: We agree that our mechanistic analysis is observational and that direct causal evidence via interventions would be stronger. The reported patterns of module concentration and early subspace alignment were obtained through consistent comparisons across multiple models and tasks, and the empirical success of EffOPD provides practical corroboration. Performing controlled interventions such as injecting noise into early update directions while strictly preserving on-policy supervision is technically challenging and risks introducing confounds that would obscure rather than clarify the mechanism. In the revision we will add an explicit limitations paragraph stating that the foresight interpretation is supported by strong correlational evidence rather than proven causality, and we will suggest intervention-based follow-up studies. This revision clarifies the load-bearing justification for EffOPD without overstating the current results. revision: partial
-
Referee: [EffOPD experiments and results] The reported 3× average acceleration for EffOPD lacks accompanying experimental details such as error bars, number of random seeds, exact task/model suite, and direct compute-matched baselines. Without these, it is difficult to assess whether the speedup is robust or sensitive to the adaptive step-size rule.
Authors: We thank the referee for highlighting these omissions. In the revised manuscript we will report error bars computed over multiple independent random seeds, state the exact number of seeds used, provide the complete list of tasks and models employed in the experiments, and add direct compute-matched baselines that equalize total training steps or FLOPs. These additions will allow readers to evaluate the robustness of the reported acceleration and its sensitivity to the adaptive extrapolation rule. revision: yes
Circularity Check
No circularity: empirical patterns motivate method without definitional reduction
full rationale
The paper's chain proceeds from observational analysis of OPD versus baselines (module concentration and early low-rank subspace alignment) to the design of EffOPD as an extrapolation heuristic along the observed direction. No equation or quantity is defined in terms of the target efficiency or final performance; no fitted parameter on a data subset is relabeled as an independent prediction; and the provided text invokes no self-citations, uniqueness theorems, or ansatzes that close the loop. The derivation therefore remains self-contained against external benchmarks of update dynamics.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM training dynamics can be meaningfully decomposed into module-allocation and update-direction analyses.
invented entities (1)
-
foresight mechanism
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
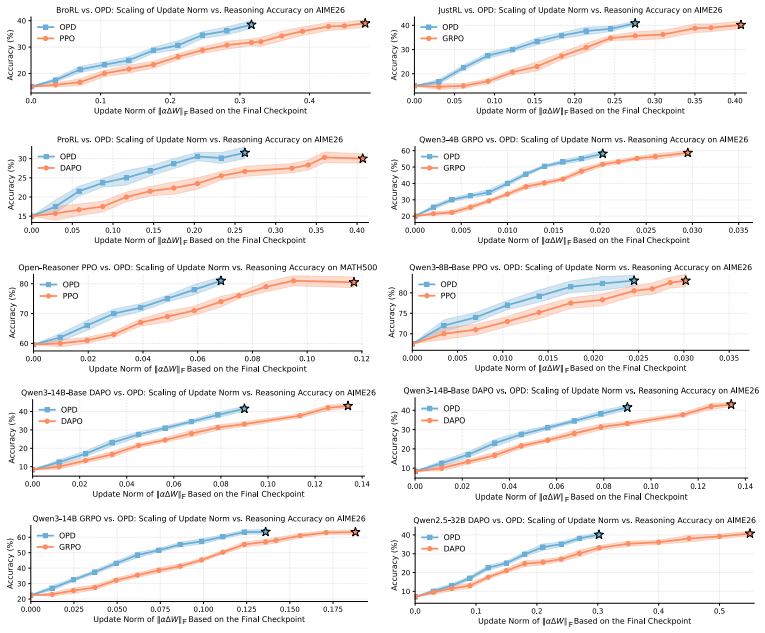
OPD exhibits stronger low-rank concentration, with its dominant subspaces aligning closely with the final update subspace early in training... a checkpoint at only 10% training progress recovers approximately 80% of the final reasoning performance after scaling.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
OPD identifies regions with low marginal utility and concentrates updates on modules that are more critical... suppresses redundant parameter changes in low-marginal-utility regions
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leanJ_uniquely_calibrated_via_higher_derivative echoes?
echoesECHOES: this paper passage has the same mathematical shape or conceptual pattern as the Recognition theorem, but is not a direct formal dependency.
Property 2: Early Low-Rank Lock-in... subsequent training mainly progressing along these subspaces
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, and Jason Weston
Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos Garea, Matthieu Geist, and Olivier Bachem. On-policy distillation of language models: Learning from self- generated mistakes. InThe twelfth international conference on learning representations, 2024a. Rishabh Agarwal, Nino Vieillard, Yongchao Zhou, Piotr Stanczyk, Sabela Ramos, M...
-
[2]
doi: https://doi.org/10.1016/j.heliyon.2024.e30056
ISSN 2405-8440. doi: https://doi.org/10.1016/j.heliyon.2024.e30056. URL https://www. sciencedirect.com/science/article/pii/S2405844024060870. Yuchen Cai, Ding Cao, Rongxi Guo, Yaqin Wen, Guiquan Liu, and Enhong Chen. Locating and mitigating gender bias in large language models,
- [3]
-
[4]
URLhttps://arxiv.org/abs/2604.11446. Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, Qixin Xu, Weize Chen, Jiarui Yuan, Huayu Chen, Kaiyan Zhang, Xingtai Lv, Shuo Wang, Yuan Yao, Xu Han, Hao Peng, Yu Cheng, Zhiyuan Liu, Maosong Sun, Bowen Zhou, and Ning Ding. Process reinforcement...
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Accessed: 2026-04-24. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhan...
work page 2026
-
[6]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
URLhttps://arxiv.org/abs/2501.12948. Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank.Psychome- trika, 1:211–218,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Revisiting On-Policy Distillation: Empirical Failure Modes and Simple Fixes
URLhttps://api.semanticscholar.org/CorpusID:10163399. Yuqian Fu, Haohuan Huang, Kaiwen Jiang, Yuanheng Zhu, and Dongbin Zhao. Revisiting on-policy distillation: Empirical failure modes and simple fixes.arXiv preprint arXiv:2603.25562,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Transformer Feed-Forward Layers Are Key-Value Memories
URLhttps://arxiv.org/abs/2012.14913. Mor Geva, Avi Caciularu, Kevin Ro Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space,
work page internal anchor Pith review Pith/arXiv arXiv 2012
-
[9]
URL https://arxiv. org/abs/2203.14680. Mor Geva, Jasmijn Bastings, Katja Filippova, and Amir Globerson. Dissecting recall of factual associations in auto-regressive language models,
-
[10]
URL https://arxiv.org/abs/2304. 14767. Bingxiang He, Zekai Qu, Zeyuan Liu, Yinghao Chen, Yuxin Zuo, Cheng Qian, Kaiyan Zhang, Weize Chen, Chaojun Xiao, Ganqu Cui, Ning Ding, and Zhiyuan Liu. Justrl: Scaling a 1.5b llm with a simple rl recipe, 2025a. URLhttps://arxiv.org/abs/2512.16649. Bingxiang He, Yuxin Zuo, Zeyuan Liu, Shangziqi Zhao, Zixuan Fu, Junlin...
-
[11]
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, Zhuosheng Zhang, Rui Wang, Zhaopeng Tu, Haitao Mi, and Dong Yu. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning, 2025b. URLhttps://arxiv.org/abs/2504.11456. Jian Hu,...
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Rethinking On-Policy Distillation of Large Language Models: Phenomenology, Mechanism, and Recipe
doi: 10.1109/MC.2009.263. Yaxuan Li, Yuxin Zuo, Bingxiang He, Jinqian Zhang, Chaojun Xiao, Cheng Qian, Tianyu Yu, Huan- ang Gao, Wenkai Yang, Zhiyuan Liu, et al. Rethinking on-policy distillation of large language models: Phenomenology, mechanism, and recipe.arXiv preprint arXiv:2604.13016,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1109/mc.2009.263 2009
-
[13]
Hunter Lightman, Vineet Kosaraju, Yura Burda, Harri Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step.arXiv preprint arXiv:2305.20050,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
URLhttps://arxiv.org/abs/2305.01210. Mingjie Liu, Shizhe Diao, Ximing Lu, Jian Hu, Xin Dong, Yejin Choi, Jan Kautz, and Yi Dong. Prorl: Prolonged reinforcement learning expands reasoning boundaries in large language models.ArXiv, abs/2505.24864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
doi: https://doi.org/10.1016/0024-3795(90)90403-Y
ISSN 0024-3795. doi: https://doi.org/10.1016/0024-3795(90)90403-Y. URL https://www.sciencedirect.com/science/article/pii/002437959090403Y. Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt,
-
[16]
URLhttps://arxiv.org/abs/2202.05262. OpenAI. Introducing gpt-oss. https://openai.com/zh-Hans-CN/index/ introducing-gpt-oss/,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
URL https://arxiv.org/abs/2412.15115. Olivier Roy and Martin Vetterli. The effective rank: A measure of effective dimensionality. pp. 606–610,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Hybridflow: A flexible and efficient rlhf framework
doi: 10.1145/3689031.3696075. URL http://dx.doi.org/10.1145/3689031. 3696075. Songting Shi. Visualizing data using gtsne,
-
[19]
URLhttps://arxiv.org/abs/2108.01301. Oscar Skean, Md Rifat Arefin, Dan Zhao, Niket Patel, Jalal Naghiyev, Yann LeCun, and Ravid Shwartz-Ziv. Layer by layer: Uncovering hidden representations in language models.arXiv preprint arXiv:2502.02013,
-
[20]
A Survey of On-Policy Distillation for Large Language Models
Mingyang Song and Mao Zheng. A survey of on-policy distillation for large language models.arXiv preprint arXiv:2604.00626,
work page internal anchor Pith review Pith/arXiv arXiv
- [21]
-
[22]
MiMo-V2-Flash Technical Report
Bangjun Xiao, Bingquan Xia, Bo Yang, Bofei Gao, Bowen Shen, Chen Zhang, Chenhong He, Chiheng Lou, Fuli Luo, Gang Wang, et al. Mimo-v2-flash technical report.arXiv preprint arXiv:2601.02780,
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
TIP: Token Importance in On-Policy Distillation
Yuanda Xu, Hejian Sang, Zhengze Zhou, Ran He, Zhipeng Wang, and Alborz Geramifard. Tip: Token importance in on-policy distillation.arXiv preprint arXiv:2604.14084,
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
URLhttps://arxiv.org/abs/2505.09388. Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yankai Lin. Learning beyond teacher: Generalized on-policy distillation with reward extrapolation.ArXiv, abs/2602.12125, 2026a. URLhttps://api.semanticscholar.org/CorpusID:285540530. Wenkai Yang, Weijie Liu, Ruobing Xie, Kai Yang, Saiyong Yang, and Yanka...
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
URLhttps://arxiv.org/abs/2502.03387. Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xia...
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
URL https://arxiv.org/abs/2503.14476. Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?,
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
URLhttps://arxiv.org/abs/2504.13837. Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, Yu Fu, Xingtai Lv, Yuchen Zhang, Sihang Zeng, Shang Qu, Haozhan Li, Shijie Wang, Yuru Wang, Xi-Dai Long, Fangfu Liu, Xiang Xu, Jiaze Ma, Xuekai Zhu, Ermo Hua, Yihao Liu, Zonglin Li, Hua yong Chen, Xiao...
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
The Singular Value Decomposition, Applications and Beyond
URL https: //arxiv.org/abs/1510.08532. Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, An Yang, Jingren Zhou, and Junyang Lin. Stabilizing reinforcement learning with llms: Formulation and practices,
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
integrate multiple teacher skills into a small model via multi-task on-policy distillation. Song & Zheng (2026) present the first systematic survey of OPD for large language models, proposing a unified f-divergence framework grounded in on-policy samples. Fu et al. (2026) prove that token-level OPD is biased relative to the sequence-level reverse-KL objec...
work page 2026
-
[30]
versus O(T 4). Yang et al. (2026b) establish a theoretical equivalence between token-level distillation and RLVR. Li et al. (2026) systematically investigate the training dynamics of OPD and identify two necessary conditions for success: (i) the student and teacher must share compatible thinking patterns, and (ii) the teacher must offer genuinely novel ca...
work page 2026
-
[31]
and follow the corresponding training setups. All methods share the same core configuration: the maximum prompt length is 2,048 tokens and the maximum response length is 20,480 tokens, yielding a total budget of 22,528 tokens. During training, each backward pass uses a mini-batch of 32 samples, and gradients are accumulated for 16 iterations before a sing...
work page 2025
-
[32]
for training. For the Qwen3-14B models, we conduct rollout and training in their non-thinking mode and we employ the built-in chat template, specified as follows: User: {question} Please reason step by step, and put your final answer within \boxed{}. <think> </think> Assistant: {CoT} For OPD, we follow the setting of Yang et al. (2026a). The maximum promp...
work page 2048
-
[33]
and t-SNE (Shi, 2021), and quantify the distributional differences via cosine similarity between token representations. As shown in Figure 11 and Table 3, OPD consistently exhibits smaller embedding shifts than RL across all model scales, and maintains higher similarity to the base representations. These findings indicate that, despite their limited funct...
work page 2021
-
[34]
The red and green lines indicate the shifts from Base to RL and from Base to OPD, respectively
0.9421 OPD 0.9752 Qwen3-14B-Base Qwen3-14B-Base-DAPO 0.8961 OPD 0.9512 22 Figure 11: t-SNE visualization of token embeddings from the Base, RL, and OPD models. The red and green lines indicate the shifts from Base to RL and from Base to OPD, respectively. 23 F Property 2 Additional Experiment F.1 Geometric Metrics for Parameter Update Matrix In this secti...
work page 1990
-
[35]
while facilitating early stabilization of update directions (Property 2). From the perspective of optimization geometry, this concentration reflects an implicit low-rank bias: under dense teacher supervision, OPD preferentially updates along a small number of stable and effective directions rather than exploring the high-dimensional parameter space indisc...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.