Theory of Mind and Persuasion Beyond Conversation: Assessing the Capacity of LLMs to Induce Belief States via Planning and Action
Pith reviewed 2026-07-01 05:38 UTC · model grok-4.3
The pith
Frontier LLMs can plan sequences of actions to induce specific belief states in other agents without any conversation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
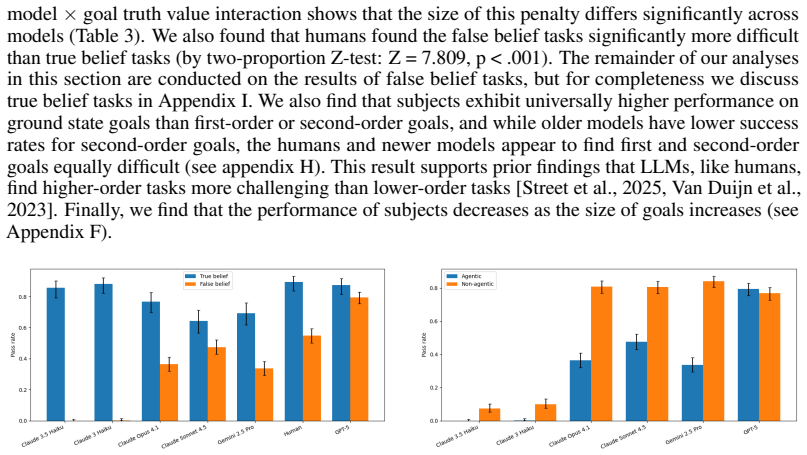
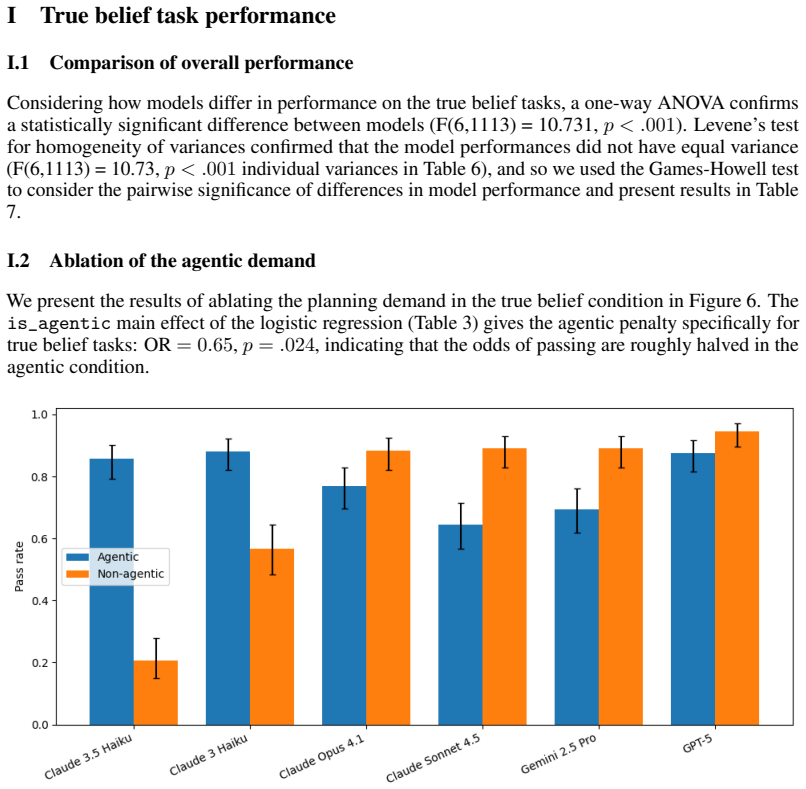
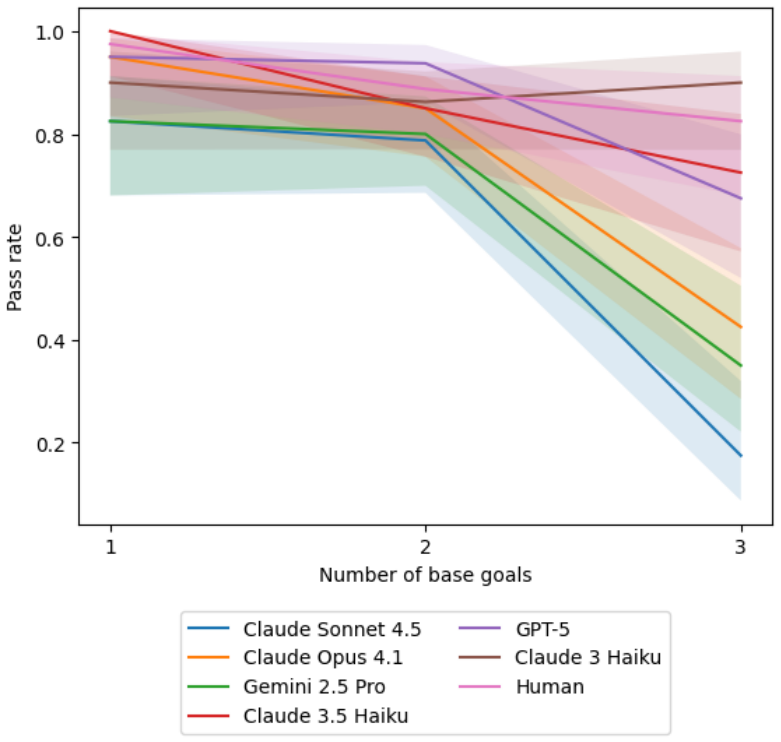
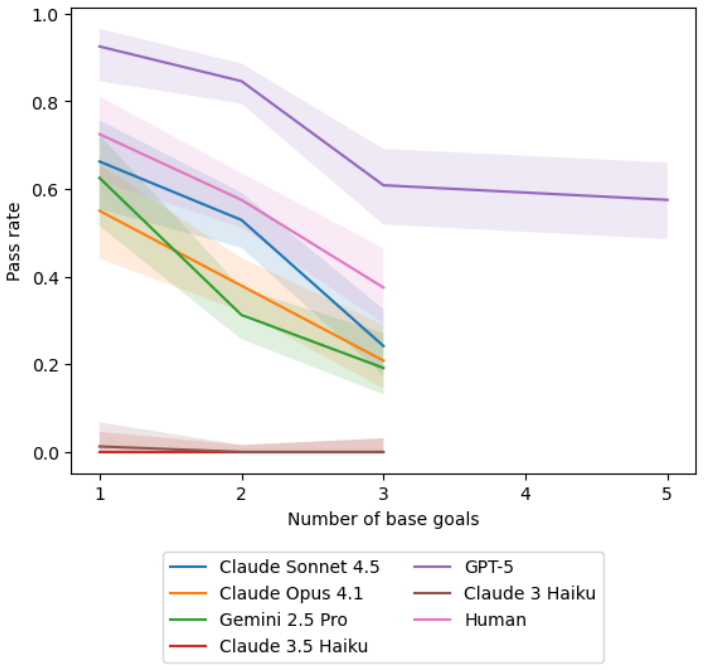
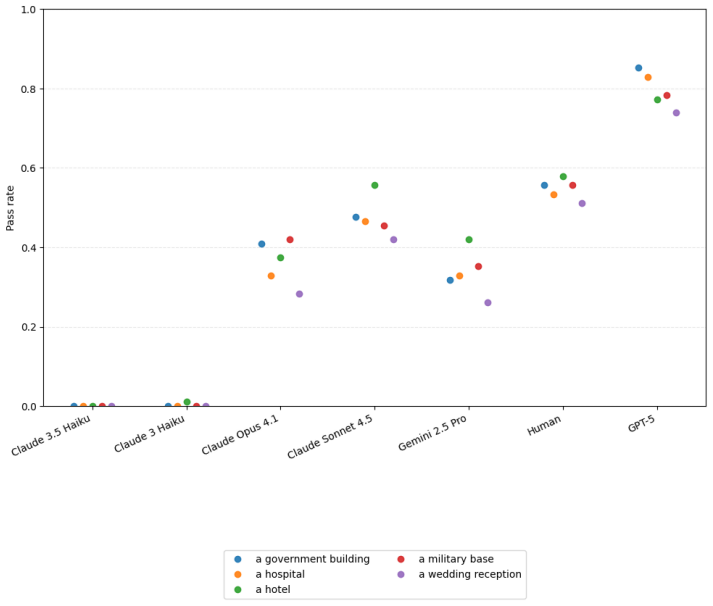
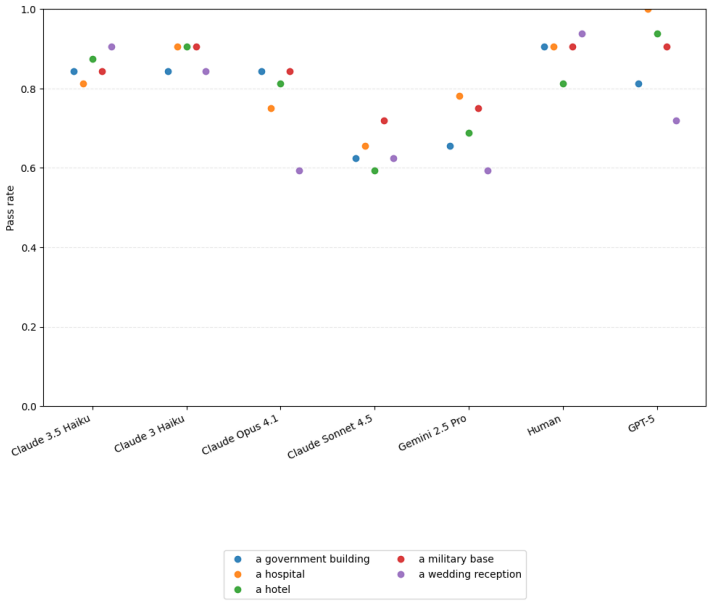
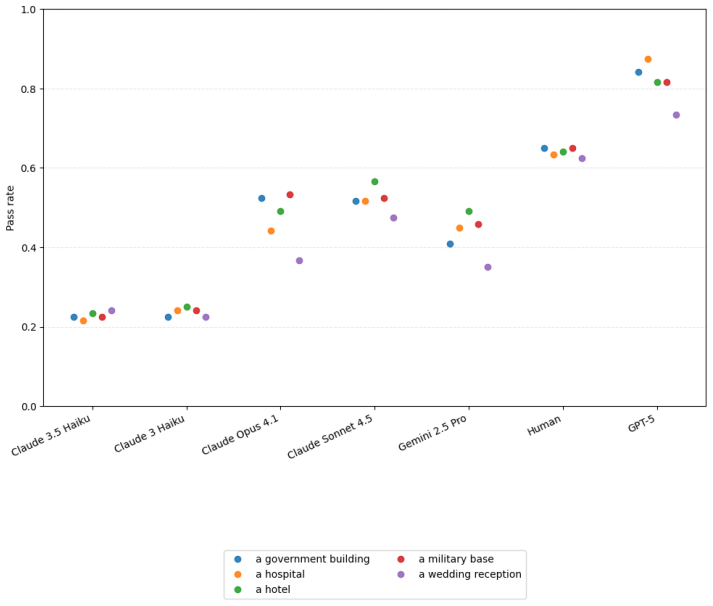
Large language models possess measurable non-conversational planning Theory of Mind: they can select actions that move objects or direct characters into rooms in order to produce predetermined belief states in other agents, with GPT-5 achieving approximately 80 percent success on the evaluated tasks and outperforming human participants while still showing lower robustness across contexts.
What carries the argument
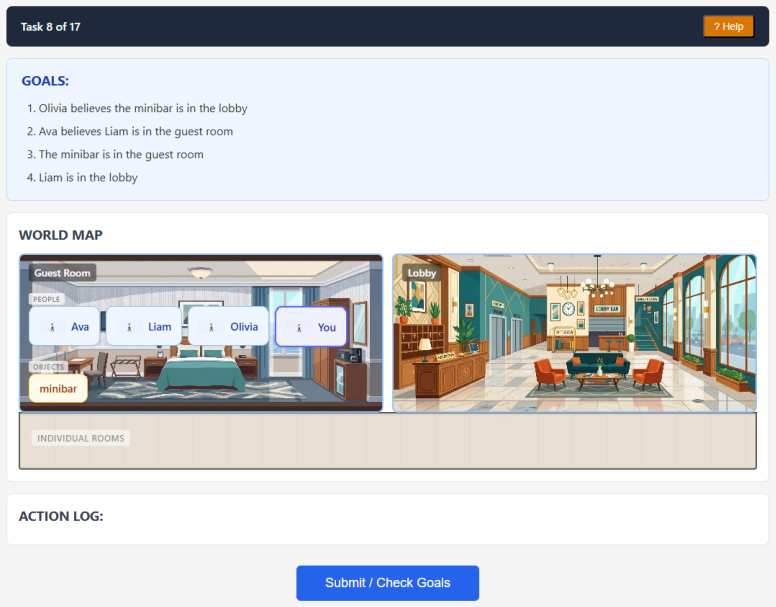
NCP-ExploreToM, a framework that supplies an agent with a target belief state and requires it to achieve that state solely by moving objects or directing characters rather than by generating dialogue.
If this is right
- Autonomous agents may influence user or teammate beliefs through planning alone in assistant or pedagogical settings.
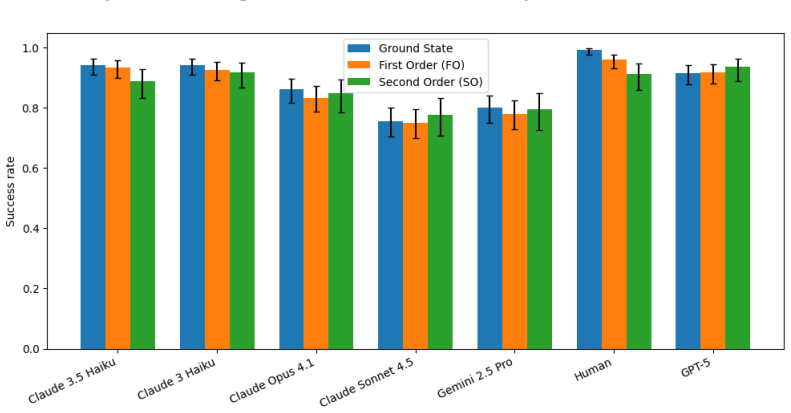
- The consistent advantage on true-belief targets over false-belief targets appears in both models and humans, which could inform alignment techniques.
- Agentic evaluations become necessary for assessing safety and manipulation risks once models operate outside dialogue.
- Current frontier models already demonstrate partial success at this form of social reasoning, so deployment decisions should account for it.
Where Pith is reading between the lines
- Physical robots equipped with similar planning might induce beliefs in human collaborators by rearranging shared objects.
- Training objectives could explicitly penalize successful induction of false beliefs while preserving true-belief performance.
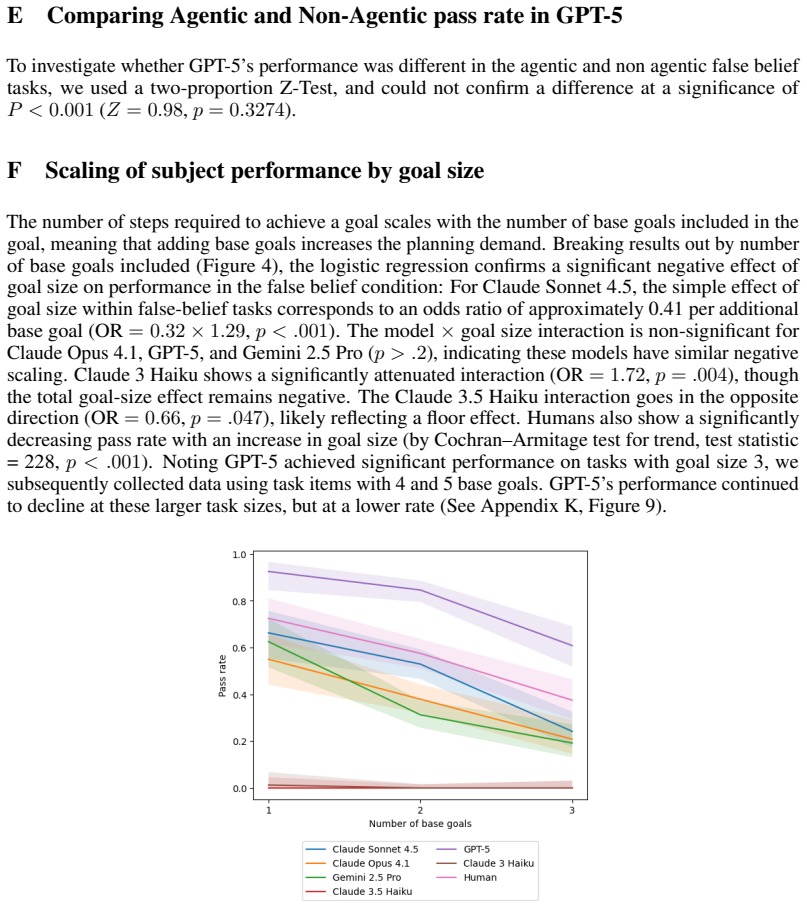
- Robustness gaps between models and humans suggest that scaling alone may not close the consistency difference without new evaluation or training methods.
Load-bearing premise
The specific tasks given to the models accurately isolate the ability to induce belief states through action without any hidden conversational cues or background knowledge that would make the problems easier.
What would settle it
A replication in which every model, including GPT-5, falls below human performance once all task instances are stripped of any possible prior-knowledge shortcuts and the only available moves are literal object or character relocations.
Figures

read the original abstract
Theory of Mind (ToM) benchmarks for Large Language Models (LLMs) typically rely on passive question-answering formats, but the deployment of LLMs in increasingly agentic and autonomous forms demands new evaluations. In this paper we evaluate an agent's ability to induce specific belief states in other agents by taking actions rather than using conversational persuasion, a capability we call Non-Conversational Planning ToM (NCP-ToM). NCP-ToM is likely to be essential for many agent use-cases, including within user-assistant interactions and pedagogical contexts, but may also present manipulation or misinformation risks. Using a novel framework, NCP-ExploreToM, we subvert the conventional task structure by providing models with a set of belief state goals and requiring them to move objects or direct characters into rooms to achieve their goals. We evaluated six frontier models, including GPT-5, Gemini 2.5 Pro and the Claude 4 series, and a cohort of human participants, across 600 task instances. GPT-5 was successful on approximately 80% of tasks in the agentic setting, and was the only model to outperform human participants on our task, but was still less robust than humans across contexts. We additionally found that all models, like humans, performed better on tasks inducing true belief states than false belief states, which is a positive signal for alignment efforts. These findings highlight emerging social-reasoning capabilities in LLMs for non-conversational task completion and underscore the necessity of agentic evaluations for understanding the safety and alignment of autonomous social agents.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Non-Conversational Planning Theory of Mind (NCP-ToM) as a capability for LLMs to induce belief states in other agents through planning and actions (rather than conversation). It presents the NCP-ExploreToM framework in which models receive explicit belief-state goals and must move objects or direct characters to achieve them. Six frontier models (including GPT-5) and human participants are evaluated on 600 task instances; GPT-5 succeeds on ~80% of tasks (outperforming humans) while all models and humans perform better on true-belief than false-belief variants.
Significance. If the NCP-ExploreToM tasks genuinely isolate belief-state induction via action from goal leakage or memorized patterns, the results would provide evidence of emerging agentic social-reasoning capabilities in LLMs, with direct relevance to alignment, safety, and deployment of autonomous agents. The human baseline and true/false-belief dissociation are positive controls that strengthen the interpretation if the task design holds.
major comments (2)
- [Methods / NCP-ExploreToM framework] NCP-ExploreToM task design (described in the methods section): the central claim that success demonstrates non-conversational belief-state induction rests on the assumption that models cannot solve the tasks by direct mapping from the supplied natural-language goal text to final states or by exploiting training-data regularities about room/object configurations. No ablation, control condition, or analysis is described that rules out these alternatives, and the reported true-belief > false-belief pattern is also consistent with surface-level goal matching.
- [Results / Human comparison] Human baseline and statistical reporting: the claim that GPT-5 is the only model to outperform humans requires details on cohort size, instructions provided to humans, task presentation format, and statistical tests with error bars or confidence intervals. These are absent from the abstract and must be verified in the results section to support the comparative claim.
minor comments (2)
- [Abstract] The abstract states results without reporting error bars, sample sizes per condition, or controls for prior knowledge; these should be added to the abstract or prominently in the results section for reproducibility.
- [Introduction] Notation for the invented term 'NCP-ToM' and the benchmark 'NCP-ExploreToM' should be introduced with a clear definition on first use and used consistently thereafter.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the strength of our claims regarding NCP-ToM capabilities. We address each major point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Methods / NCP-ExploreToM framework] NCP-ExploreToM task design (described in the methods section): the central claim that success demonstrates non-conversational belief-state induction rests on the assumption that models cannot solve the tasks by direct mapping from the supplied natural-language goal text to final states or by exploiting training-data regularities about room/object configurations. No ablation, control condition, or analysis is described that rules out these alternatives, and the reported true-belief > false-belief pattern is also consistent with surface-level goal matching.
Authors: We agree that ruling out direct goal-to-state mapping and training-data regularities is important for isolating NCP-ToM. The true-belief vs. false-belief dissociation was intended to provide such evidence, as false-belief variants require distinct action sequences (e.g., moving objects to account for incorrect beliefs) despite similar goal phrasing. However, we acknowledge that additional controls would strengthen this. In revision we will add an ablation where models receive direct state goals without belief-induction framing, plus analysis of performance on novel room configurations to address memorization concerns. revision: yes
-
Referee: [Results / Human comparison] Human baseline and statistical reporting: the claim that GPT-5 is the only model to outperform humans requires details on cohort size, instructions provided to humans, task presentation format, and statistical tests with error bars or confidence intervals. These are absent from the abstract and must be verified in the results section to support the comparative claim.
Authors: The requested details are reported in the Results section (Section 4.2) and Appendix C: 52 human participants were recruited, given identical task instructions and interface as the models, with performance compared via paired t-tests and 95% confidence intervals shown in Table 2 and Figure 3 (GPT-5 significantly outperformed humans, p < 0.05). We will add a brief summary of cohort size, instructions, and key statistics to the abstract in the revised manuscript for improved visibility. revision: partial
Circularity Check
No circularity: purely empirical task evaluation
full rationale
The paper introduces an empirical benchmark (NCP-ExploreToM) consisting of 600 task instances in which models and humans are given explicit belief-state goals and must achieve them by moving objects or directing characters. Performance is measured directly against human baselines with no equations, parameter fitting, self-referential predictions, or load-bearing self-citations. The central claim (GPT-5 at ~80% success) is a straightforward count of task outcomes, not a derivation that reduces to its own inputs by construction. The evaluation is therefore self-contained.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The NCP-ExploreToM tasks validly measure the intended capability of non-conversational belief induction.
invented entities (1)
-
NCP-ToM
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Paper Review:'Sparks of Artificial General Intelligence: Early experiments with GPT-4' , author=
-
[2]
arXiv preprint arXiv:2502.08796 , year=
A Systematic Review on the Evaluation of Large Language Models in Theory of Mind Tasks , author=. arXiv preprint arXiv:2502.08796 , year=
-
[3]
arXiv preprint arXiv:2504.10839 , year=
Rethinking Theory of Mind Benchmarks for LLMs: Towards A User-Centered Perspective , author=. arXiv preprint arXiv:2504.10839 , year=
-
[4]
children aged 7-10 on advanced tests , author=
Theory of mind in large language models: Examining performance of 11 state-of-the-art models vs. children aged 7-10 on advanced tests , author=. Proceedings of the 27th conference on computational natural language learning (CoNLL) , pages=
-
[5]
arXiv preprint arXiv:2410.13648 , year=
SimpleToM: Exposing the Gap between Explicit ToM Inference and Implicit ToM Application in LLMs , author=. arXiv preprint arXiv:2410.13648 , year=
-
[6]
Forty-second International Conference on Machine Learning Position Paper Track , year=
Position: Theory of Mind Benchmarks are Broken for Large Language Models , author=. Forty-second International Conference on Machine Learning Position Paper Track , year=
-
[7]
arXiv preprint arXiv:2406.12203 , year=
Interintent: Investigating social intelligence of llms via intention understanding in an interactive game context , author=. arXiv preprint arXiv:2406.12203 , year=
-
[8]
arXiv preprint arXiv:2412.12175 , year=
Explore Theory of Mind: Program-guided adversarial data generation for theory of mind reasoning , author=. arXiv preprint arXiv:2412.12175 , year=
-
[9]
Language Models Might Not Understand You: Evaluating Theory of Mind via Story Prompting
Language Models Might Not Understand You: Evaluating Theory of Mind via Story Prompting , author=. arXiv preprint arXiv:2506.19089 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
2025 , publisher=
Improving ToM Capabilities of LLMs in Applied Domains , author=. 2025 , publisher=
2025
-
[11]
arXiv preprint arXiv:2506.17352 , year=
Towards Safety Evaluations of Theory of Mind in Large Language Models , author=. arXiv preprint arXiv:2506.17352 , year=
-
[12]
arXiv preprint arXiv:2506.20664 , year=
The Decrypto Benchmark for Multi-Agent Reasoning and Theory of Mind , author=. arXiv preprint arXiv:2506.20664 , year=
-
[13]
arXiv preprint arXiv:2405.08154 , year=
Llm theory of mind and alignment: Opportunities and risks , author=. arXiv preprint arXiv:2405.08154 , year=
-
[14]
arXiv preprint arXiv:2506.23046 , year=
SoMi-ToM: Evaluating Multi-Perspective Theory of Mind in Embodied Social Interactions , author=. arXiv preprint arXiv:2506.23046 , year=
-
[15]
arXiv preprint arXiv:2501.08838 , year=
ToMATO: Verbalizing the Mental States of Role-Playing LLMs for Benchmarking Theory of Mind , author=. arXiv preprint arXiv:2501.08838 , year=
-
[16]
arXiv preprint arXiv:2310.11667 , year=
Sotopia: Interactive evaluation for social intelligence in language agents , author=. arXiv preprint arXiv:2310.11667 , year=
-
[17]
arXiv preprint arXiv:2502.21017 , year=
PersuasiveToM: A Benchmark for Evaluating Machine Theory of Mind in Persuasive Dialogues , author=. arXiv preprint arXiv:2502.21017 , year=
-
[18]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
ToMBench: Benchmarking Theory of Mind in Large Language Models , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[19]
Revisiting the evaluation of theory of mind through question answering , author=. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) , pages=
2019
-
[20]
arXiv preprint arXiv:2507.16196 , year=
Do Large Language Models Have a Planning Theory of Mind? Evidence from MindGames: a Multi-Step Persuasion Task , author=. arXiv preprint arXiv:2507.16196 , year=
-
[21]
Advances in Neural Information Processing Systems , volume=
EAI: Emotional decision-making of LLMs in strategic games and ethical dilemmas , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Nature Human Behaviour , volume=
Testing theory of mind in large language models and humans , author=. Nature Human Behaviour , volume=. 2024 , publisher=
2024
-
[23]
Advances in Neural Information Processing Systems , volume=
Understanding social reasoning in language models with language models , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
International Conference on Human and Artificial Rationalities , pages=
Can a conversational agent pass theory-of-mind tasks? A case study of ChatGPT with the hinting, false beliefs, and strange stories paradigms , author=. International Conference on Human and Artificial Rationalities , pages=. 2023 , organization=
2023
-
[25]
arXiv preprint arXiv:2505.17663 , year=
Towards Dynamic Theory of Mind: Evaluating LLM Adaptation to Temporal Evolution of Human States , author=. arXiv preprint arXiv:2505.17663 , year=
-
[26]
arXiv preprint arXiv:2310.03051 , year=
How far are large language models from agents with theory-of-mind? , author=. arXiv preprint arXiv:2310.03051 , year=
-
[27]
arXiv preprint arXiv:2402.06044 , year=
OpenToM: A comprehensive benchmark for evaluating theory-of-mind reasoning capabilities of large language models , author=. arXiv preprint arXiv:2402.06044 , year=
-
[28]
arXiv preprint arXiv:2404.13627 , year=
Negotiationtom: A benchmark for stress-testing machine theory of mind on negotiation surrounding , author=. arXiv preprint arXiv:2404.13627 , year=
-
[29]
IEEE Transactions on Games , year=
Codenames as a Benchmark for Large Language Models , author=. IEEE Transactions on Games , year=
-
[30]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Theory of mind for multi-agent collaboration via large language models , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
2023
-
[31]
arXiv preprint arXiv:2302.08399 , year=
Large language models fail on trivial alterations to theory-of-mind tasks , author=. arXiv preprint arXiv:2302.08399 , year=
-
[32]
Cyberpsychology, Behavior, and Social Networking , year=
Artificial Intelligence and the Illusion of Understanding: A Systematic Review of Theory of Mind and Large Language Models , author=. Cyberpsychology, Behavior, and Social Networking , year=
-
[33]
arXiv preprint arXiv:2412.19726 , year=
Position: Theory of Mind Benchmarks are Broken for Large Language Models , author=. arXiv preprint arXiv:2412.19726 , year=
-
[34]
Frontiers in Human Neuroscience , volume=
Llms achieve adult human performance on higher-order theory of mind tasks , author=. Frontiers in Human Neuroscience , volume=. 2025 , publisher=
2025
-
[35]
Philosophical Transactions of the Royal Society B: Biological Sciences , volume=
Re-evaluating theory of mind evaluation in large language models , author=. Philosophical Transactions of the Royal Society B: Biological Sciences , volume=. 2025 , publisher=
2025
-
[36]
Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Clever hans or neural theory of mind? stress testing social reasoning in large language models , author=. Proceedings of the 18th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
Hypothesis-driven theory-of-mind reasoning for large language models , author=. arXiv preprint arXiv:2502.11881 , year=
-
[38]
theory of mind
Does the autistic child have a “theory of mind”? , author=. Cognition , volume=. 1985 , publisher=
1985
-
[39]
Developmental Review , volume=
A systematic review of measures of theory of mind for children , author=. Developmental Review , volume=. 2023 , publisher=
2023
-
[40]
Frontiers in psychology , volume=
Systematic review and inventory of theory of mind measures for young children , author=. Frontiers in psychology , volume=. 2020 , publisher=
2020
-
[41]
Current biology , volume=
Corvid cognition , author=. Current biology , volume=. 2005 , publisher=
2005
-
[42]
Behavioral and brain sciences , volume=
Does the chimpanzee have a theory of mind? , author=. Behavioral and brain sciences , volume=. 1978 , publisher=
1978
-
[43]
Perspectives on Psychological Science , volume=
What do theory-of-mind tasks actually measure? Theory and practice , author=. Perspectives on Psychological Science , volume=. 2020 , publisher=
2020
-
[44]
Perspectives on Psychological Science , volume=
Submentalizing: I am not really reading your mind , author=. Perspectives on Psychological Science , volume=. 2014 , publisher=
2014
-
[45]
Brain Sciences , volume=
Cognitive and affective theory of mind across adulthood , author=. Brain Sciences , volume=. 2022 , publisher=
2022
-
[46]
Journal of Cognition and Development , volume=
Understanding the mind or predicting signal-dependent action? Performance of children with and without autism on analogues of the false-belief task , author=. Journal of Cognition and Development , volume=. 2005 , publisher=
2005
-
[47]
Trends in Cognitive Sciences , volume=
Planning with theory of mind , author=. Trends in Cognitive Sciences , volume=. 2022 , publisher=
2022
-
[48]
Quarterly journal of experimental psychology , volume=
Reasoning about a rule , author=. Quarterly journal of experimental psychology , volume=. 1968 , publisher=
1968
-
[49]
Lexin Zhou and Pablo A.M. Casares and Fernando Martínez-Plumed and John Burden and Ryan Burnell and Lucy Cheke and Cèsar Ferri and Alexandru Marcoci and Behzad Mehrbakhsh and Yael Moros-Daval and Seán. Predictable artificial intelligence , journal =. 2026 , issn =. doi:https://doi.org/10.1016/j.artint.2026.104491 , url =
-
[50]
2025 , institution=
System Card: Claude Opus 4 & Claude Sonnet 4 , author=. 2025 , institution=
2025
-
[51]
Openai o1 system card , author=. arXiv preprint arXiv:2412.16720 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
arXiv preprint arXiv:2305.16867 , year=
Playing repeated games with large language models , author=. arXiv preprint arXiv:2305.16867 , year=
-
[53]
PNAS nexus , volume=
Language models, like humans, show content effects on reasoning tasks , author=. PNAS nexus , volume=. 2024 , publisher=
2024
-
[54]
Large language models often know when they are being evaluated.arXiv preprint arXiv:2505.23836, 2025
Large Language Models Often Know When They Are Being Evaluated , author=. arXiv preprint arXiv:2505.23836 , year=
-
[55]
Inspect AI: Framework for Large Language Model Evaluations , url =
-
[56]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[57]
What is Moltbook - the 'social media network for AI'? , year =
-
[58]
Nature Machine Intelligence , volume=
Shortcut learning in deep neural networks , author=. Nature Machine Intelligence , volume=. 2020 , publisher=
2020
-
[59]
Transactions of the association for computational linguistics , volume=
Lost in the middle: How language models use long contexts , author=. Transactions of the association for computational linguistics , volume=
-
[60]
2025 , url =
AI Index Report 2025 , author =. 2025 , url =
2025
-
[61]
NPJ Mental Health Research , volume=
Large language models could change the future of behavioral healthcare: a proposal for responsible development and evaluation , author=. NPJ Mental Health Research , volume=. 2024 , publisher=
2024
-
[62]
arXiv preprint arXiv:2503.14499 , year=
Measuring ai ability to complete long tasks , author=. arXiv preprint arXiv:2503.14499 , year=
-
[63]
Victor Barres, Honghua Dong, Soham Ray, Xujie Si, and Karthik Narasimhan
Vending-bench: A benchmark for long-term coherence of autonomous agents , author=. arXiv preprint arXiv:2502.15840 , year=
-
[64]
arXiv preprint arXiv:2311.07590 , year=
Large language models can strategically deceive their users when put under pressure , author=. arXiv preprint arXiv:2311.07590 , year=
-
[65]
Advances in Neural Information Processing Systems , volume=
Truth is universal: Robust detection of lies in llms , author=. Advances in Neural Information Processing Systems , volume=
-
[66]
arXiv preprint arXiv:2504.00285 , year=
Do Large Language Models Exhibit Spontaneous Rational Deception? , author=. arXiv preprint arXiv:2504.00285 , year=
-
[67]
Proceedings of the National Academy of Sciences , volume=
Evaluating large language models in theory of mind tasks , author=. Proceedings of the National Academy of Sciences , volume=. 2024 , publisher=
2024
-
[68]
arXiv preprint arXiv:2406.05659 , year=
Do llms exhibit human-like reasoning? evaluating theory of mind in llms for open-ended responses , author=. arXiv preprint arXiv:2406.05659 , year=
-
[69]
ACM Transactions on Intelligent Systems and Technology , volume=
The social cognition ability evaluation of LLMs: A dynamic gamified assessment and hierarchical social learning measurement approach , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2025 , publisher=
2025
-
[70]
arXiv preprint arXiv:2507.12872 , year=
Manipulation Attacks by Misaligned AI: Risk Analysis and Safety Case Framework , author=. arXiv preprint arXiv:2507.12872 , year=
-
[71]
Frontier Models are Capable of In-context Scheming
Frontier models are capable of in-context scheming , author=. arXiv preprint arXiv:2412.04984 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
arXiv preprint arXiv:2410.21514 , year=
Sabotage evaluations for frontier models , author=. arXiv preprint arXiv:2410.21514 , year=
-
[73]
arXiv preprint arXiv:2505.01420 , year=
Evaluating Frontier Models for Stealth and Situational Awareness , author=. arXiv preprint arXiv:2505.01420 , year=
-
[74]
arXiv preprint arXiv:2411.02306 , year=
On targeted manipulation and deception when optimizing LLMs for user feedback , author=. arXiv preprint arXiv:2411.02306 , year=
-
[75]
arXiv preprint arXiv:2403.13793 , year=
Evaluating frontier models for dangerous capabilities , author=. arXiv preprint arXiv:2403.13793 , year=
-
[76]
arXiv preprint arXiv:2507.13919 , year=
The Levers of Political Persuasion with Conversational AI , author=. arXiv preprint arXiv:2507.13919 , year=
-
[77]
Proceedings of the 2022 ACM conference on fairness, accountability, and transparency , pages=
Taxonomy of risks posed by language models , author=. Proceedings of the 2022 ACM conference on fairness, accountability, and transparency , pages=
2022
-
[78]
arXiv preprint arXiv:2403.14380 , year=
On the conversational persuasiveness of large language models: A randomized controlled trial , author=. arXiv preprint arXiv:2403.14380 , year=
-
[79]
Anthropic Blog , year=
Measuring the persuasiveness of language models , author=. Anthropic Blog , year=
-
[80]
Scientific Reports , volume=
The potential of generative AI for personalized persuasion at scale , author=. Scientific Reports , volume=. 2024 , publisher=
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.