ISM:Self-Improving Strategy Memory for Continual Mathematical Reasoning
Pith reviewed 2026-07-01 06:38 UTC · model grok-4.3
The pith
A self-evolving bank of verified strategy schemas lets a frozen LLM outperform baselines in continual math reasoning with far fewer stored entries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
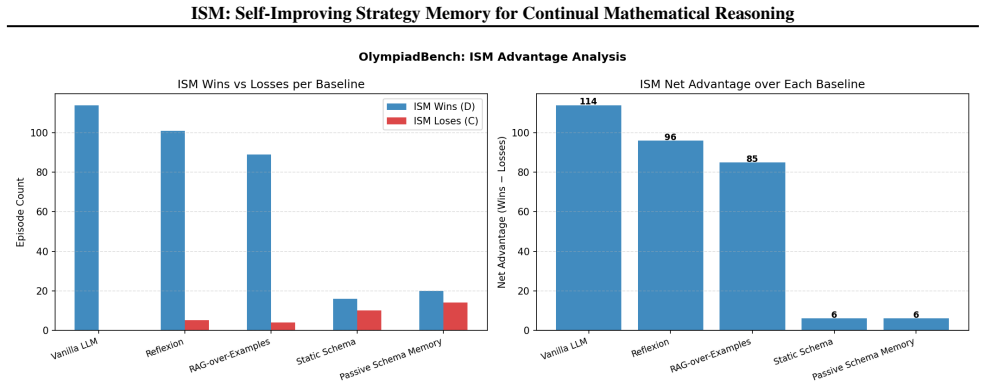
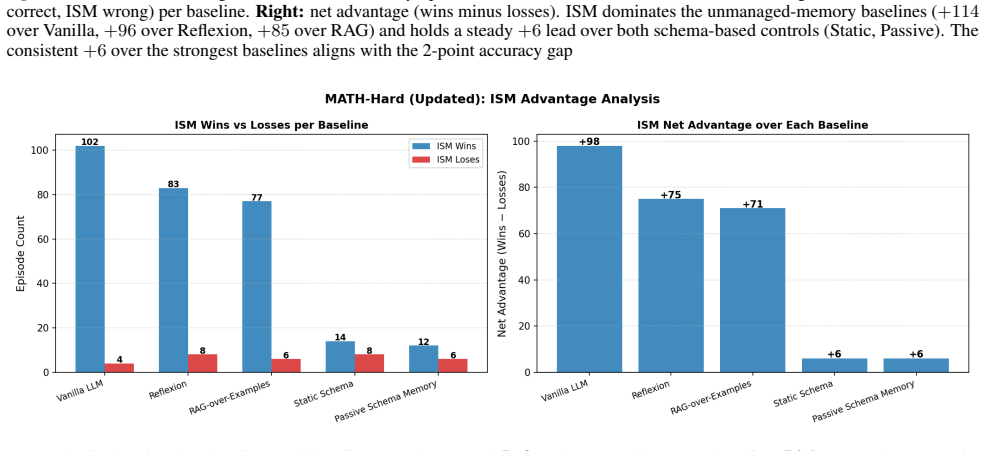
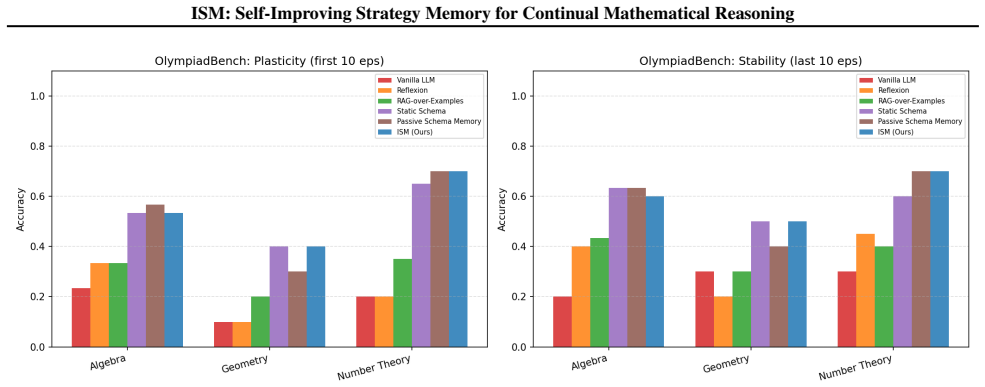
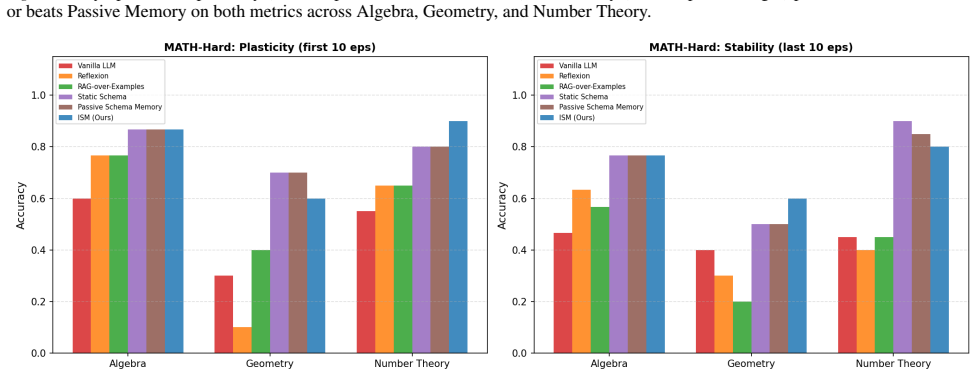
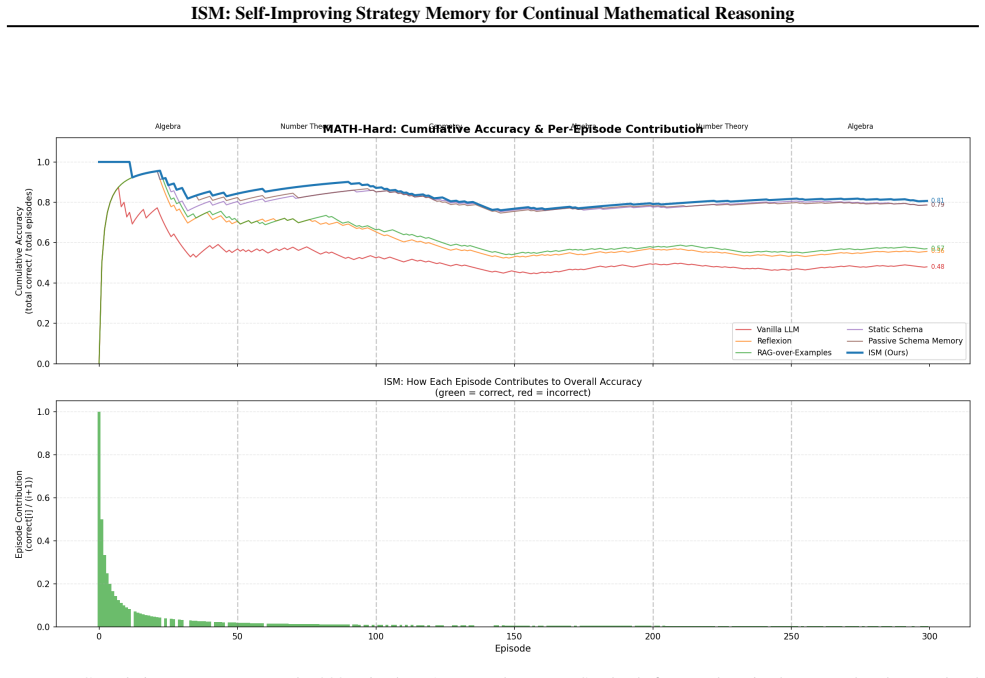
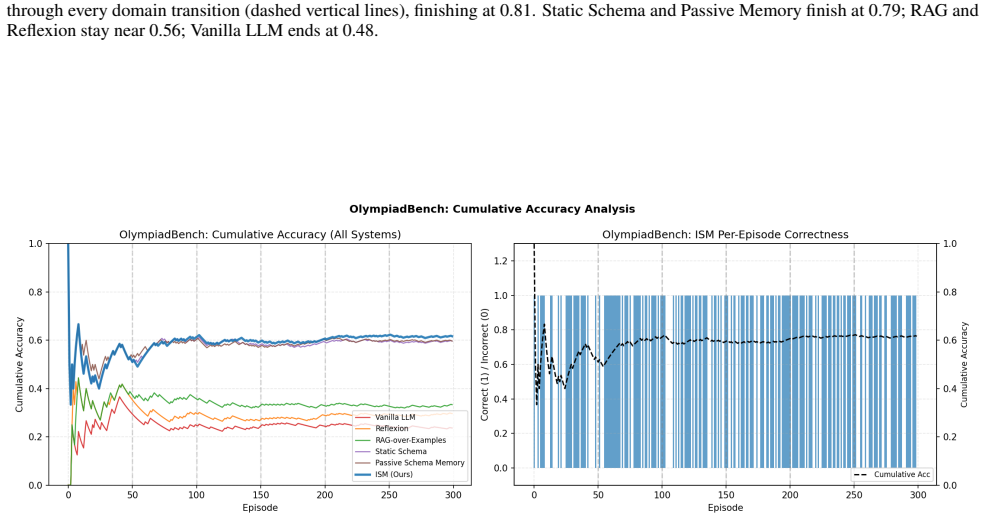
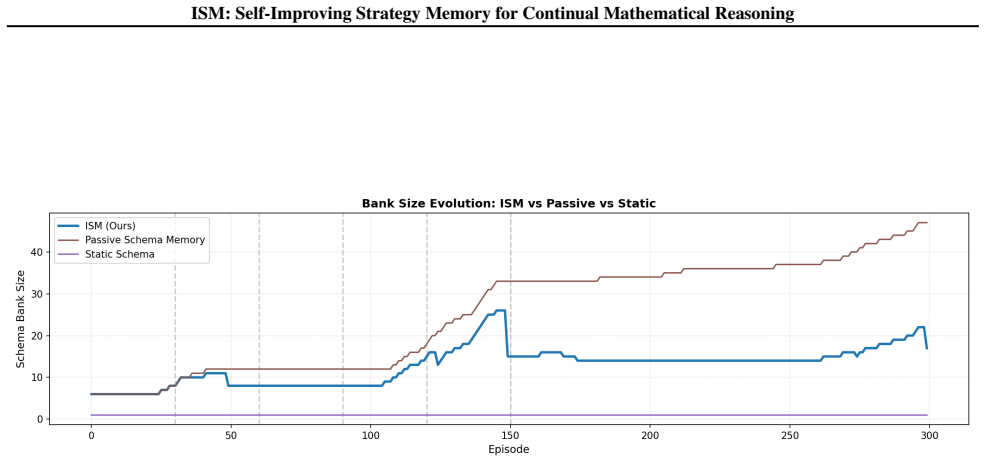
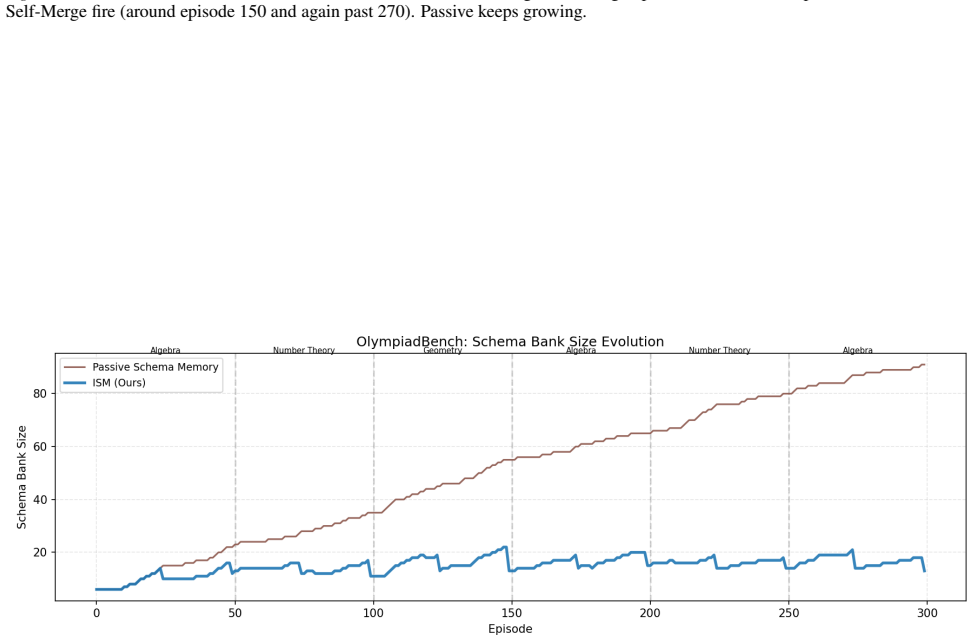
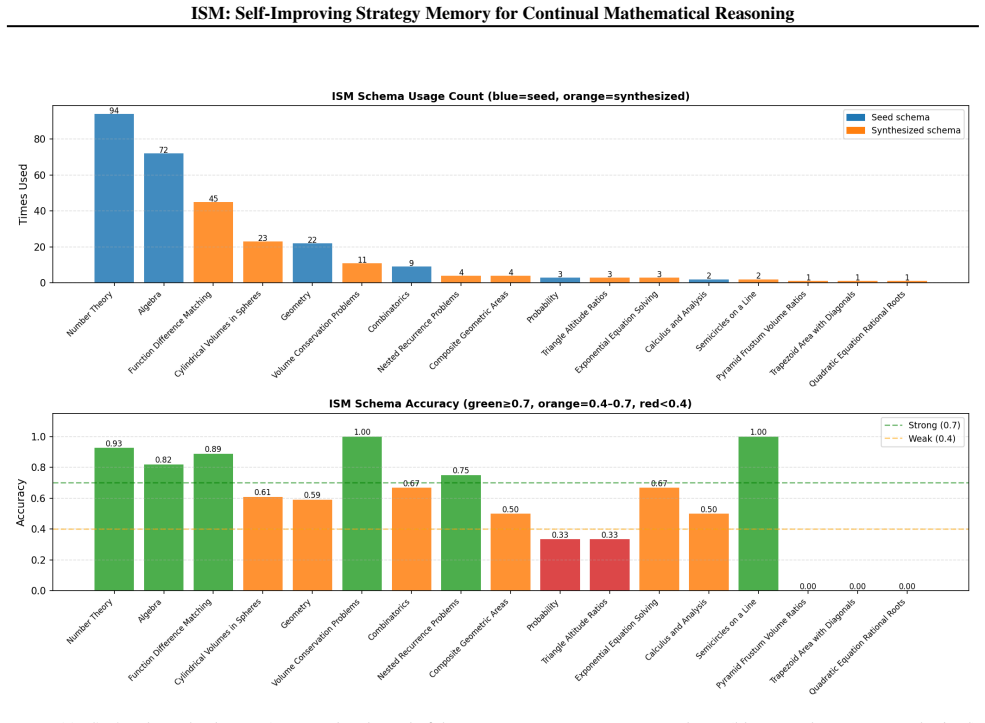
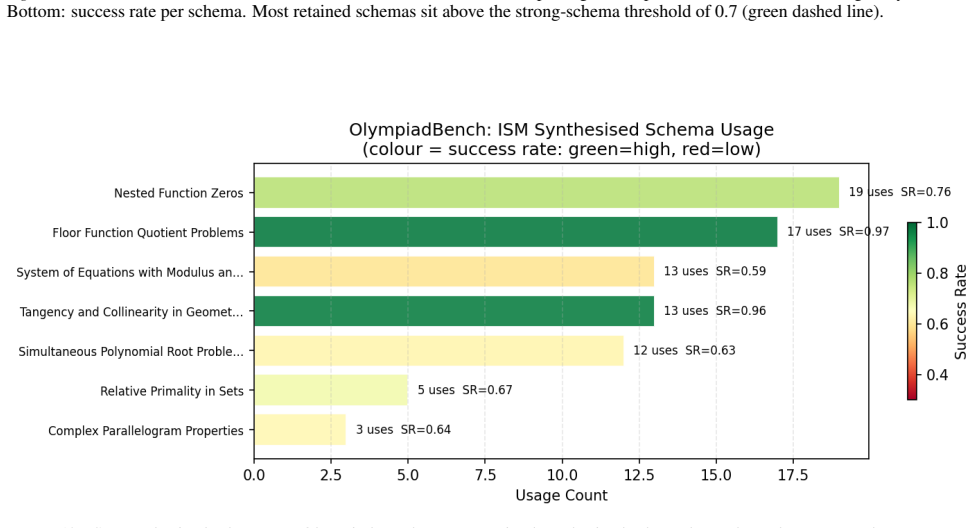
ISM maintains a compact, self-refined bank of strategy schemas learned from both successful and failed episodes, with symbolic tools that check intermediate steps and certify answers. Without updating model parameters, ISM outperforms passive, retrieval, and reflection baselines on MATH-Hard and OlympiadBench, using 64% and 86% fewer schemas respectively than the strongest passive baseline. These results show that small, actively maintained, and verified strategy memories can support reliable continual mathematical reasoning under strict episodic isolation.
What carries the argument
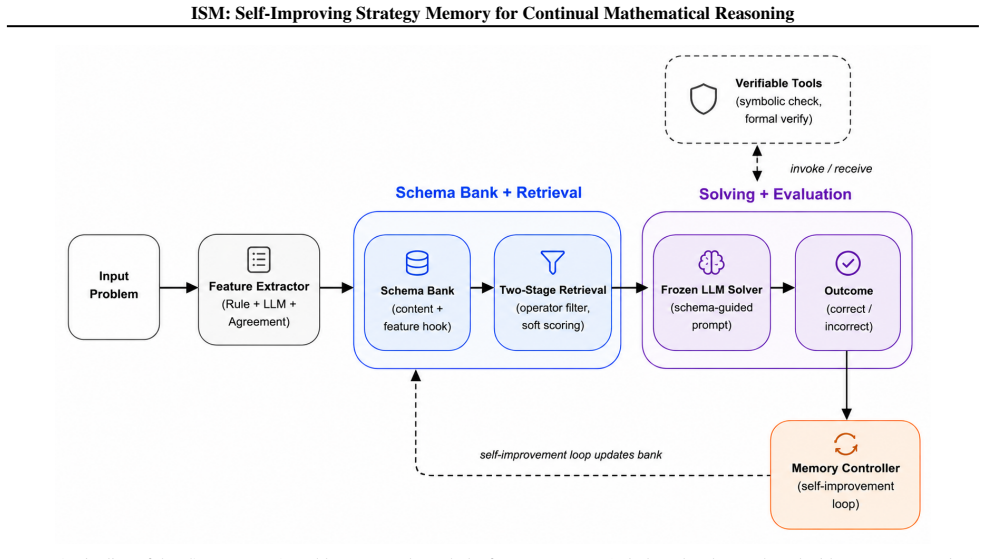
Intelligent Schema Memory (ISM), a self-evolving memory-augmented system that builds and refines a bank of verified strategy schemas from episode outcomes.
If this is right
- Small actively maintained strategy memories can support reliable continual mathematical reasoning under strict episodic isolation.
- Schemas refined from both successes and failures improve efficiency over methods that store only successful traces.
- Performance gains hold without any updates to the base model parameters.
- Symbolic verification enables the memory to self-refine across episodes.
Where Pith is reading between the lines
- External verified memory could serve as an alternative to parameter updates for specialized reasoning tasks.
- The approach may extend to other domains where intermediate steps admit reliable symbolic checking.
- Increasing the diversity of verification tools or the scale of the schema bank could widen the performance gap.
Load-bearing premise
Symbolic tools can accurately check intermediate reasoning steps and certify answers for the mathematical problems encountered.
What would settle it
A benchmark run in which the symbolic verifier misclassifies a substantial fraction of correct or incorrect steps, causing the memory to retain flawed schemas and drop below baseline accuracy on MATH-Hard or OlympiadBench.
Figures
read the original abstract
We propose Intelligent Schema Memory (ISM), a self-evolving memory-augmented system that improves mathematical reasoning for a frozen LLM under continual learning with hard episodic resets. ISM maintains a compact, self-refined bank of strategy schemas learned from both successful and failed episodes, with symbolic tools that check intermediate steps and certify answers.Without updating model parameters, ISM outperforms passive, retrieval, and reflection baselines on MATH-Hard and OlympiadBench, using 64% and 86% fewer schemas respectively than the strongest passive baseline. These results show that small, actively maintained, and verified strategy memories can support reliable continual mathematical reasoning under strict episodic isolation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Intelligent Schema Memory (ISM), a memory-augmented system for continual mathematical reasoning with a frozen LLM under hard episodic resets. ISM maintains a compact, self-refined bank of strategy schemas extracted from both successful and failed episodes; symbolic tools verify intermediate steps and certify final answers. Without parameter updates, ISM outperforms passive, retrieval, and reflection baselines on MATH-Hard and OlympiadBench while using 64% and 86% fewer schemas than the strongest passive baseline.
Significance. If the symbolic verification is reliable and the experimental comparisons are sound, the result would demonstrate that small, actively curated and verified strategy memories can support reliable continual reasoning in LLMs under strict episodic isolation, offering a parameter-free alternative to fine-tuning for mathematical domains.
major comments (3)
- [Methods] The central performance claims rest on the assumption that symbolic tools correctly certify intermediate steps and final answers on MATH-Hard and OlympiadBench. The manuscript provides no error analysis, coverage statistics, or manual validation of these tools for problem types such as inequalities, geometry, or non-algebraic proofs where symbolic checkers have known limitations (Methods section on symbolic verification).
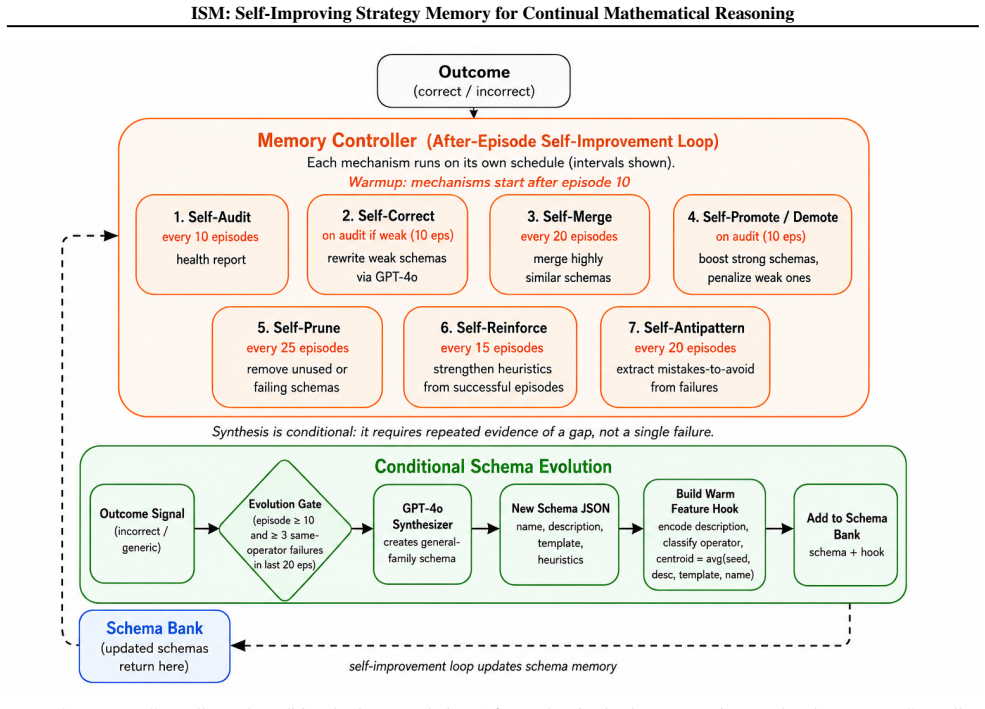
- [Section 3.2] The description of how schemas are extracted and refined from failed episodes is insufficient to assess whether invalid strategies can enter the memory bank. No explicit criteria, filtering thresholds, or examples of failure-to-schema conversion are supplied (Section 3.2 on self-refinement).
- [Results] Table reporting the main results does not include variance across runs, statistical significance tests, or ablation on the contribution of the verification step versus the memory mechanism alone, making it difficult to attribute gains specifically to ISM (Results section, main comparison table).
minor comments (2)
- [Abstract] The abstract states performance numbers but omits any mention of the number of episodes, the exact baselines, or the size of the schema bank; these details should appear in the abstract for clarity.
- [Section 3] Notation for schema representation and the episodic reset mechanism is introduced without a dedicated figure or pseudocode, complicating reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify key aspects of our work. We address each major comment point by point below, indicating revisions where the manuscript will be updated to incorporate the feedback.
read point-by-point responses
-
Referee: [Methods] The central performance claims rest on the assumption that symbolic tools correctly certify intermediate steps and final answers on MATH-Hard and OlympiadBench. The manuscript provides no error analysis, coverage statistics, or manual validation of these tools for problem types such as inequalities, geometry, or non-algebraic proofs where symbolic checkers have known limitations (Methods section on symbolic verification).
Authors: We agree that explicit validation of the symbolic tools strengthens the claims. The tools rely on SymPy for algebraic and arithmetic verification, with final answers cross-checked against ground truth. In the revision, we will add an appendix reporting coverage statistics across MATH-Hard and OlympiadBench, known error rates for supported problem types, and a discussion of limitations for geometry and inequality problems. This will clarify the scope of reliable verification. revision: yes
-
Referee: [Section 3.2] The description of how schemas are extracted and refined from failed episodes is insufficient to assess whether invalid strategies can enter the memory bank. No explicit criteria, filtering thresholds, or examples of failure-to-schema conversion are supplied (Section 3.2 on self-refinement).
Authors: We appreciate this observation. Schema extraction from failed episodes occurs only after partial symbolic verification succeeds on intermediate steps but the final answer fails, using a minimum verified-step threshold and a confidence filter to exclude low-quality traces. We will revise Section 3.2 to include the explicit criteria, filtering thresholds, and two concrete examples of failure-to-schema conversion, demonstrating how invalid strategies are filtered before storage. revision: yes
-
Referee: [Results] Table reporting the main results does not include variance across runs, statistical significance tests, or ablation on the contribution of the verification step versus the memory mechanism alone, making it difficult to attribute gains specifically to ISM (Results section, main comparison table).
Authors: We agree these additions improve interpretability. The original experiments used fixed seeds for reproducibility. In the revision, we will rerun with three seeds, report means and standard deviations in the main table, add t-test p-values for key comparisons, and include a new ablation isolating the verification step from the memory mechanism. This will better attribute performance gains to ISM components. revision: yes
Circularity Check
No circularity; empirical system relies on external verification
full rationale
The paper describes an empirical memory-augmented system evaluated on MATH-Hard and OlympiadBench. Performance claims rest on comparisons against baselines using external symbolic tools for step checking and answer certification, plus episodic resets. No equations, predictions, or first-principles derivations are presented that reduce to fitted inputs or self-citations by construction. The central results are experimental outcomes, not algebraic identities or renamed patterns derived from the system's own outputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Symbolic tools can reliably check intermediate steps and certify answers
invented entities (1)
-
Intelligent Schema Memory (ISM)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
2000
-
[2]
Advances in neural information processing systems , volume=
Reflexion: Language agents with verbal reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[3]
Advances in neural information processing systems , volume=
Tree of thoughts: Deliberate problem solving with large language models , author=. Advances in neural information processing systems , volume=
-
[4]
arXiv preprint arXiv:2511.14961 , year=
Knowledge Graphs as Structured Memory for Embedding Spaces: From Training Clusters to Explainable Inference , author=. arXiv preprint arXiv:2511.14961 , year=
-
[5]
ReAct: Synergizing Reasoning and Acting in Language Models
React: Synergizing reasoning and acting in language models , author=. arXiv preprint arXiv:2210.03629 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
2026 , eprint=
Agentic Design Patterns: A System-Theoretic Framework , author=. 2026 , eprint=
2026
-
[7]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[9]
IEEE transactions on pattern analysis and machine intelligence , volume=
A comprehensive survey of continual learning: Theory, method and application , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2024 , publisher=
2024
-
[10]
Computers & operations research , volume=
A hybridization of mathematical programming and dominance-driven enumeration for solving shift-selection and task-sequencing problems , author=. Computers & operations research , volume=. 2010 , publisher=
2010
-
[11]
2026 , eprint=
A Survey of Large Language Models , author=. 2026 , eprint=
2026
-
[12]
2023 , eprint=
Self-Refine: Iterative Refinement with Self-Feedback , author=. 2023 , eprint=
2023
-
[13]
ACM Transactions on Information Systems , volume=
A survey on the memory mechanism of large language model-based agents , author=. ACM Transactions on Information Systems , volume=. 2025 , publisher=
2025
-
[14]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[15]
M. J. Kearns , title =
-
[16]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[17]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[18]
Suppressed for Anonymity , author=
-
[19]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[20]
Titans: Learning to Memorize at Test Time
Titans: Learning to Memorize at Test Time , author=. arXiv preprint arXiv:2501.00663 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Nested Learning: The Illusion of Deep Learning Architectures , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[22]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. arXiv preprint arXiv:2305.16291 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
MemGPT: Towards LLMs as Operating Systems
MemGPT: Towards LLMs as Operating Systems , author=. arXiv preprint arXiv:2310.08560 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[24]
Advances in Neural Information Processing Systems , year=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. Advances in Neural Information Processing Systems , year=
-
[25]
Self-Refine: Iterative Refinement with Self-Feedback
Self-Refine: Iterative Refinement with Self-Feedback , author=. arXiv preprint arXiv:2303.17651 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[26]
Advances in Neural Information Processing Systems , year=
STaR: Bootstrapping Reasoning with Reasoning , author=. Advances in Neural Information Processing Systems , year=
-
[27]
Advances in Neural Information Processing Systems , year=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[28]
Program of Thoughts Prompting: Disentangling Computation from Reasoning for Numerical Reasoning Tasks , author=. arXiv preprint arXiv:2211.12588 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
International Conference on Machine Learning , year=
PAL: Program-Aided Language Models , author=. International Conference on Machine Learning , year=
-
[30]
Let's Verify Step by Step , author=. arXiv preprint arXiv:2305.20050 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring Mathematical Problem Solving with the MATH Dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.