On Training Flexible Robots using Deep Reinforcement Learning
Pith reviewed 2026-05-25 12:30 UTC · model grok-4.3
The pith
Deep reinforcement learning learns efficient and robust policies for flexible robots performing complex tasks at varying flexibility levels.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
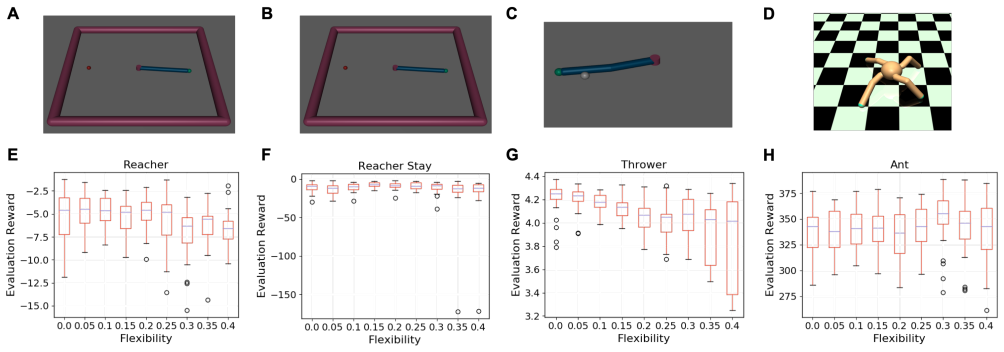
Deep reinforcement learning using policy search methods is successfully able to learn efficient and robust policies for complex tasks at various degrees of flexibility. Deep Deterministic Policy Gradients in particular works but shows sensitivity to the choice of sensors, where adding more informative sensors does not necessarily make the task easier to learn.
What carries the argument
Deep Deterministic Policy Gradients (DDPG) for policy search in simulated flexible robot environments.
If this is right
- Flexible robots can be controlled for complex tasks without first constructing explicit dynamical models.
- The same DRL approach handles multiple levels of robot flexibility while producing robust behavior under uncertainty.
- Sensor choice must be evaluated carefully because additional sensors can sometimes hinder rather than help learning.
- Policy search via DRL offers an alternative to model-based control when safety requirements and environmental uncertainties are high.
Where Pith is reading between the lines
- The method could extend to other soft or deformable robot platforms where traditional modeling breaks down.
- Real-world validation would require addressing the simulation-to-hardware gap explicitly.
- Comparing DDPG against other DRL algorithms on the same flexible-robot benchmarks could reveal which methods are least sensitive to sensor choice.
Load-bearing premise
The simulation environments used accurately represent the dynamics and uncertainties of real flexible robot hardware.
What would settle it
Transferring the learned policies to physical flexible robot hardware and measuring whether task success rates and robustness match the simulation results.
Figures



read the original abstract
The use of robotics in controlled environments has flourished over the last several decades and training robots to perform tasks using control strategies developed from dynamical models of their hardware have proven very effective. However, in many real-world settings, the uncertainties of the environment, the safety requirements and generalized capabilities that are expected of robots make rigid industrial robots unsuitable. This created great research interest into developing control strategies for flexible robot hardware for which building dynamical models are challenging. In this paper, inspired by the success of deep reinforcement learning (DRL) in other areas, we systematically study the efficacy of policy search methods using DRL in training flexible robots. Our results indicate that DRL is successfully able to learn efficient and robust policies for complex tasks at various degrees of flexibility. We also note that DRL using Deep Deterministic Policy Gradients can be sensitive to the choice of sensors and adding more informative sensors does not necessarily make the task easier to learn.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that deep reinforcement learning (DRL), specifically Deep Deterministic Policy Gradients (DDPG), can successfully learn efficient and robust policies for complex tasks on flexible robots across varying degrees of flexibility. It is based on simulation experiments and additionally observes that DDPG performance is sensitive to sensor choice, with more informative sensors not necessarily simplifying learning.
Significance. If the simulation results hold and the policies transfer, the work would provide empirical support for DRL as an alternative to model-based control in flexible robotics, where building accurate dynamical models is difficult due to uncertainties. The sensor-sensitivity observation could offer practical guidance for sensor selection in policy learning.
major comments (2)
- [Abstract] Abstract: The central claim that 'DRL is successfully able to learn efficient and robust policies for complex tasks at various degrees of flexibility' is stated without any quantitative metrics, baselines, success rates, statistical details, or ablation studies, preventing assessment of the evidence strength.
- [Introduction] Introduction: The text emphasizes real-world uncertainties, safety requirements, and modeling difficulties for flexible hardware as motivation, yet all reported results (learning curves, sensor ablation, task success) are generated in simulation with no comparison of simulator dynamics to physical measurements or validation on real hardware.
minor comments (2)
- [Abstract] The abstract and title could explicitly state that the study is simulation-only to align reader expectations with the reported experiments.
- Consider including a brief description of the specific tasks, flexibility parameters, and sensor configurations to make the sensor-sensitivity observation more concrete and reproducible.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We provide point-by-point responses below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'DRL is successfully able to learn efficient and robust policies for complex tasks at various degrees of flexibility' is stated without any quantitative metrics, baselines, success rates, statistical details, or ablation studies, preventing assessment of the evidence strength.
Authors: We agree that the abstract would benefit from quantitative support for the central claim. We have revised the abstract to include key metrics such as task success rates across flexibility levels, learning performance indicators, and the sensor sensitivity finding. revision: yes
-
Referee: [Introduction] Introduction: The text emphasizes real-world uncertainties, safety requirements, and modeling difficulties for flexible hardware as motivation, yet all reported results (learning curves, sensor ablation, task success) are generated in simulation with no comparison of simulator dynamics to physical measurements or validation on real hardware.
Authors: The manuscript presents a simulation study to evaluate DRL applicability for flexible robot control. The introduction motivates the approach using real-world considerations, but the experiments isolate variables in simulation. We have added explicit discussion of this scope limitation and the need for future sim-to-real work. revision: partial
Circularity Check
No circularity: empirical simulation study with independent experimental results
full rationale
The paper reports results from DRL training runs in simulation environments for flexible robot tasks. No derivations, equations, or parameter-fitting steps are present that could reduce reported success metrics to quantities defined by the paper's own inputs. All performance claims (learning curves, task success rates, sensor ablation) are generated from independent simulation rollouts rather than by algebraic identity or self-referential fitting. Self-citations, if any, are not load-bearing for any central claim. This is a standard empirical ML robotics study whose validity rests on simulation fidelity (an external assumption), not on internal definitional circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The simulated robot dynamics and task rewards are sufficiently representative of real hardware for policy transfer.
- standard math Markov Decision Process formulation holds for the robot control tasks.
Reference graph
Works this paper leans on
-
[1]
Soft robotics: a bioinspired evolution in robotics,
S. Kim, C. Laschi, and B. Trimmer, “Soft robotics: a bioinspired evolution in robotics,” Trends in biotechnology , vol. 31, no. 5, pp. 287–294, 2013
work page 2013
-
[2]
Design, fabrication and control of soft robots,
D. Rus and M. T. Tolley, “Design, fabrication and control of soft robots,” Nature, vol. 521, no. 7553, p. 467, 2015
work page 2015
-
[3]
Dynamic analysis of flexible manip- ulators, a literature review,
S. K. Dwivedy and P. Eberhard, “Dynamic analysis of flexible manip- ulators, a literature review,” Mechanism and machine theory , vol. 41, no. 7, pp. 749–777, 2006
work page 2006
-
[4]
Control of flexible manipulators: A survey,
M. Benosman and G. Le Vey, “Control of flexible manipulators: A survey,” Robotica, vol. 22, no. 5, pp. 533–545, 2004
work page 2004
-
[5]
M. O. Tokhi and A. K. Azad, Flexible robot manipulators: modelling, simulation and control . Iet, 2008, vol. 68
work page 2008
-
[6]
Review of control and sensor system of flexible manipulator,
C. T. Kiang, A. Spowage, and C. K. Yoong, “Review of control and sensor system of flexible manipulator,” Journal of Intelligent & Robotic Systems, vol. 77, no. 1, pp. 187–213, 2015
work page 2015
-
[7]
Deep reinforcement learning that matters,
P. Henderson, R. Islam, P. Bachman, J. Pineau, D. Precup, and D. Meger, “Deep reinforcement learning that matters,” in Thirty- Second AAAI Conference on Artificial Intelligence , 2018
work page 2018
-
[8]
A survey on policy search for robotics,
M. P. Deisenroth, G. Neumann, J. Peters, et al., “A survey on policy search for robotics,” Foundations and Trends R⃝ in Robotics , vol. 2, no. 1–2, pp. 1–142, 2013
work page 2013
-
[9]
Reinforcement learning in robotics: A survey,
J. Kober, J. A. Bagnell, and J. Peters, “Reinforcement learning in robotics: A survey,” The International Journal of Robotics Research , vol. 32, no. 11, pp. 1238–1274, 2013
work page 2013
-
[10]
Skillful control under uncertainty via direct reinforce- ment learning,
V . Gullapalli, “Skillful control under uncertainty via direct reinforce- ment learning,” Robotics and autonomous systems , vol. 15, no. 4, pp. 237–246, 1995
work page 1995
-
[11]
Learning to control a low-cost manipulator using data-efficient reinforcement learning,
M. P. Deisenroth, C. E. Rasmussen, and D. Fox, “Learning to control a low-cost manipulator using data-efficient reinforcement learning,” 2011
work page 2011
-
[12]
Learning force control policies for compliant manipulation,
M. Kalakrishnan, L. Righetti, P. Pastor, and S. Schaal, “Learning force control policies for compliant manipulation,” in Intelligent Robots and Systems (IROS), 2011 IEEE/RSJ International Conference on . IEEE, 2011, pp. 4639–4644
work page 2011
-
[13]
Biped dynamic walking using reinforcement learning,
H. Benbrahim and J. A. Franklin, “Biped dynamic walking using reinforcement learning,” Robotics and Autonomous Systems , vol. 22, no. 3-4, pp. 283–302, 1997
work page 1997
-
[14]
Fast biped walking with a reflexive controller and real-time policy searching,
T. Geng, B. Porr, and F. W ¨org¨otter, “Fast biped walking with a reflexive controller and real-time policy searching,” in Advances in Neural Information Processing Systems , 2006, pp. 427–434
work page 2006
-
[15]
Learning cpg-based biped locomotion with a policy gradient method: Application to a humanoid robot,
G. Endo, J. Morimoto, T. Matsubara, J. Nakanishi, and G. Cheng, “Learning cpg-based biped locomotion with a policy gradient method: Application to a humanoid robot,” The International Journal of Robotics Research, vol. 27, no. 2, pp. 213–228, 2008
work page 2008
-
[16]
Automated deep reinforcement learning environment for hardware of a modular legged robot,
S. Ha, J. Kim, and K. Yamane, “Automated deep reinforcement learning environment for hardware of a modular legged robot,” in2018 15th International Conference on Ubiquitous Robots (UR) . IEEE, 2018, pp. 348–354
work page 2018
-
[17]
Autonomous inverted helicopter flight via reinforcement learning,
A. Y . Ng, A. Coates, M. Diel, V . Ganapathi, J. Schulte, B. Tse, E. Berger, and E. Liang, “Autonomous inverted helicopter flight via reinforcement learning,” in Experimental Robotics IX. Springer, 2006, pp. 363–372
work page 2006
-
[18]
Adaptive neural network finite-time control for uncertain robotic manipulators,
H. Liu and T. Zhang, “Adaptive neural network finite-time control for uncertain robotic manipulators,” Journal of Intelligent & Robotic Systems, vol. 75, no. 3-4, pp. 363–377, 2014
work page 2014
-
[19]
Z. Chen, T. Zhang, and Z. Li, “Hybrid control scheme consisting of adaptive and optimal controllers for flexible-base flexible-joint space manipulator with uncertain parameters,” in Intelligent Human-Machine Systems and Cybernetics (IHMSC), 2017 9th International Conference on, vol. 1. IEEE, 2017, pp. 341–345
work page 2017
-
[20]
T. Zhang and Z. Li, “Robust-adaptive neural network finite-time control and vibration suppression for flexible-base flexible-joint space manipulator,” in 2018 10th International Conference on Intelligent Human-Machine Systems and Cybernetics (IHMSC) , vol. 1. IEEE, 2018, pp. 224–229
work page 2018
-
[21]
Reduced model based control of two link flexible space robot,
A. Kumar, P. M. Pathak, and N. Sukavanam, “Reduced model based control of two link flexible space robot,” Intelligent control and automation, vol. 2, no. 02, p. 112, 2011
work page 2011
-
[22]
End-to-end training of deep visuomotor policies,
S. Levine, C. Finn, T. Darrell, and P. Abbeel, “End-to-end training of deep visuomotor policies,” The Journal of Machine Learning Research, vol. 17, no. 1, pp. 1334–1373, 2016
work page 2016
-
[23]
Deep Reinforcement Learning for Robotic Manipulation with Asynchronous Off-Policy Updates
S. Gu, E. Holly, T. Lillicrap, and S. Levine, “Deep reinforcement learning for robotic manipulation with asynchronous off-policy updates,” 2017. [Online]. Available: https://arxiv.org/abs/1610.00633
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Continuous control with deep reinforcement learning
T. P. Lillicrap, J. J. Hunt, A. Pritzel, N. Heess, T. Erez, Y . Tassa, D. Silver, and D. Wierstra, “Continuous control with deep reinforce- ment learning,” arXiv preprint arXiv:1509.02971 , 2015
work page internal anchor Pith review Pith/arXiv arXiv 2015
-
[25]
Mujoco: A physics engine for model-based control,
E. Todorov, T. Erez, and Y . Tassa, “Mujoco: A physics engine for model-based control,” in 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems . IEEE, 2012, pp. 5026–5033
work page 2012
-
[26]
I. Caspi, G. Leibovich, G. Novik, and S. Endrawis, “Reinforcement learning coach,” Dec. 2017. [Online]. Available: https://doi.org/10. 5281/zenodo.1134899
work page 2017
-
[27]
infotheory: A c++/python pack- age for multivariate information theoretic analysis,
M. Candadai and E. J. Izquierdo, “infotheory: A c++/python pack- age for multivariate information theoretic analysis,” arXiv preprint arXiv:1907.02339, 2019
-
[28]
Averaged shifted histograms: effective nonparametric density estimators in several dimensions,
D. W. Scott, “Averaged shifted histograms: effective nonparametric density estimators in several dimensions,” The Annals of Statistics , pp. 1024–1040, 1985
work page 1985
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.