Knowledge Graph-Driven Expert-Level Reasoning for Neuroscience
Pith reviewed 2026-06-30 11:32 UTC · model grok-4.3
The pith
Structured knowledge from one neuroscience textbook distilled into a KG can fine-tune a small LM to surpass large LLMs on expert reasoning tasks while using far fewer parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
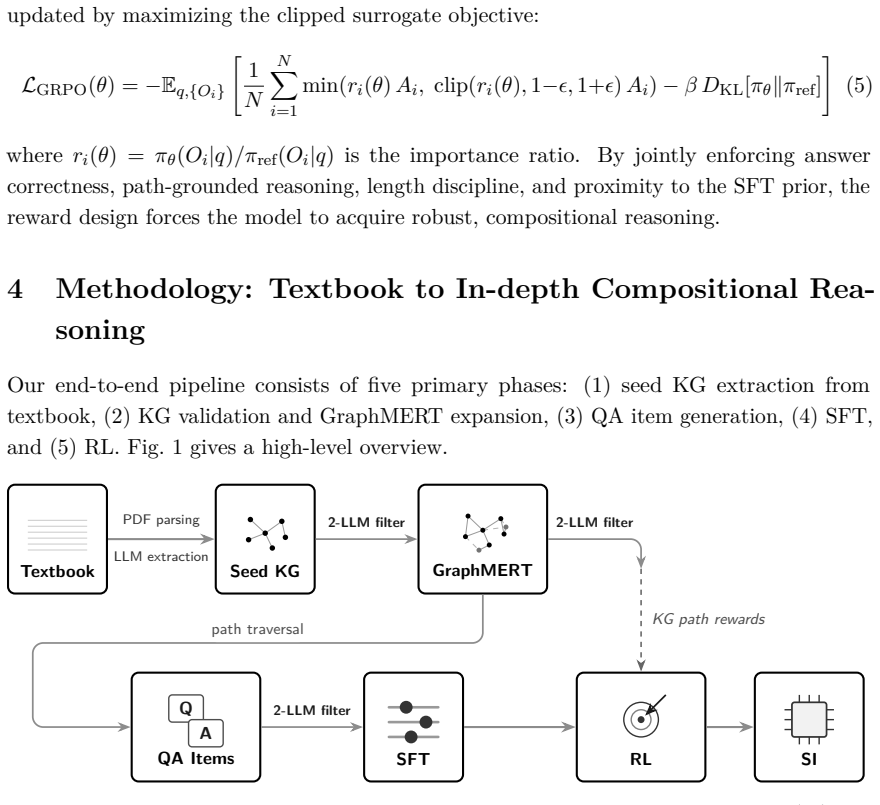
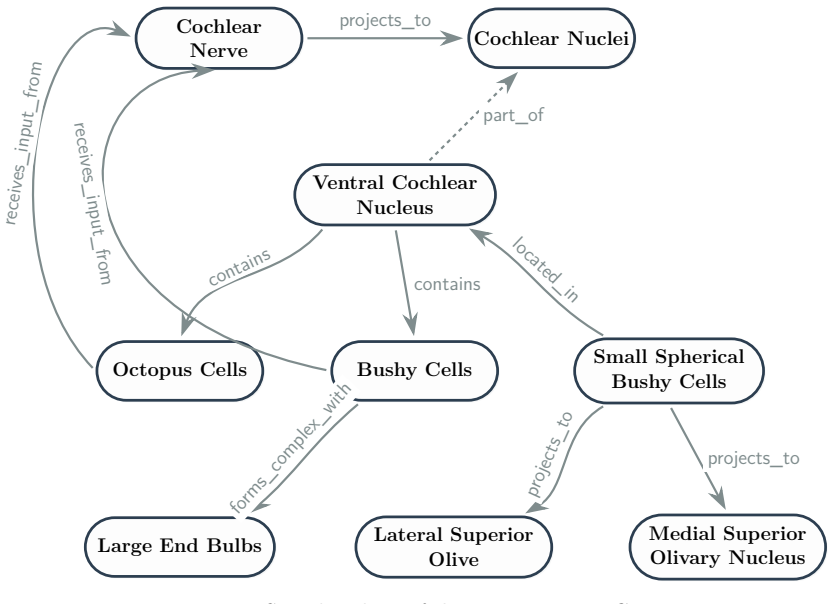
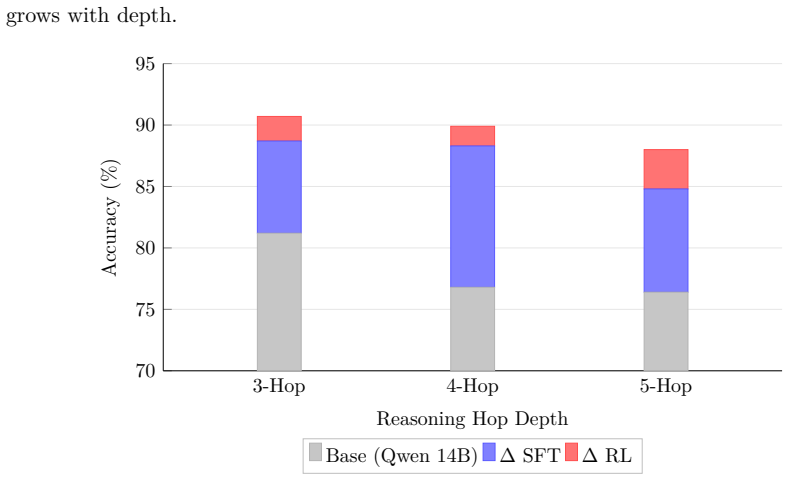
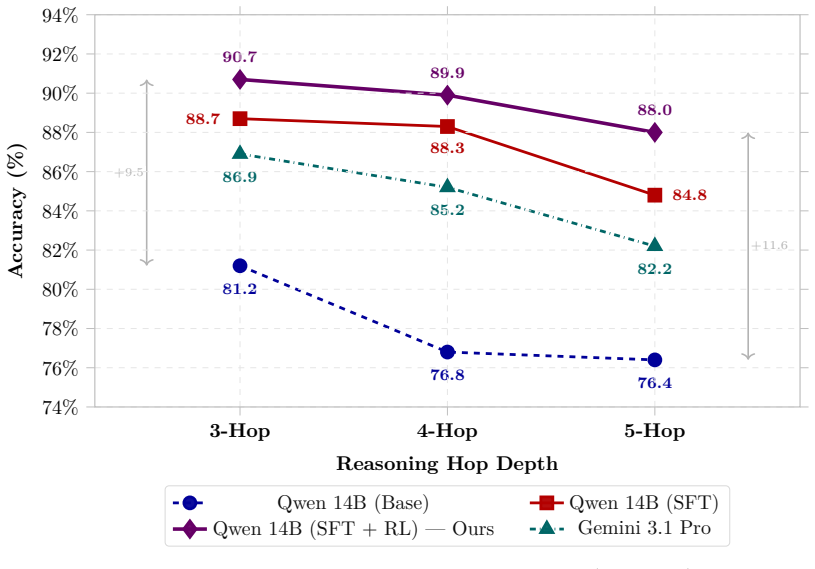
The central hypothesis is that structured knowledge, when distilled into a high-quality KG and converted into KG-grounded question-answer supervision, is sufficient to produce expert-level reasoning through a fine-tuned LM that surpasses large language models in accuracy, while employing orders of magnitude fewer parameters. The authors construct a textbook-derived KG via a dual-LLM validation pipeline, expand it with a masked LM trained on the KG topology, generate multi-hop QA items including reasoning traces, fine-tune an LM exclusively on KG-derived supervision, and apply reinforcement learning using path-derived KG signals as implicit reward models.
What carries the argument
A textbook-derived knowledge graph built and validated by a dual-LLM pipeline, then used to generate multi-hop QA supervision and path-based rewards for fine-tuning and reinforcement learning.
If this is right
- Deep mechanistic neuroscience understanding can be induced in a model without reliance on large heterogeneous web-scale corpora.
- A KG-based synthetic neuroscience curriculum can be generated for self-quizzing on the textbook material.
- The fine-tuned LM and the curriculum are released for further use at the provided GitHub location.
- The approach demonstrates that expert-level reasoning in a domain can arise from structured knowledge in one authoritative source.
Where Pith is reading between the lines
- If the method works, it could be tested on other single-textbook domains such as medicine or physics to check whether the efficiency gains transfer.
- The KG could serve as an explicit, auditable source for verifying the model's reasoning steps beyond accuracy scores alone.
- Updating the KG with new textbook editions might allow incremental improvement of the fine-tuned model without full retraining.
- The dual-LLM pipeline itself might be replaced by human validation in smaller domains to reduce any risk of validation errors propagating.
Load-bearing premise
The dual-LLM validation pipeline produces a high-quality KG that faithfully captures the textbook's mechanistic content without significant omissions or errors that would prevent genuine expert-level reasoning.
What would settle it
A test showing the fine-tuned model does not outperform large LLMs on held-out multi-hop neuroscience questions requiring mechanistic understanding drawn directly from the textbook, or evidence that KG errors produce systematically incorrect reasoning traces.
Figures

read the original abstract
Knowledge graph (KG) is an abstraction that can be extracted from text corpora and used for in-depth reasoning. Prior work has leveraged KGs to fine-tune language models (LMs), enabling domain-specific superintelligence. In this work, we explore whether KG-driven in-depth reasoning capabilities can emerge in neuroscience using only information contained within a single authoritative textbook. The central hypothesis is that structured knowledge, when distilled into a high-quality KG and converted into KG-grounded question-answer (QA) supervision, is sufficient to produce expert-level reasoning through a fine-tuned LM that surpasses large language models (LLMs) in accuracy, while employing orders of magnitude fewer parameters. We construct a textbook-derived KG via a dual-LLM validation pipeline, expand it with a masked LM trained on the KG topology, generate multi-hop QA items, which include QA pairs and reasoning traces, to fine-tune an LM exclusively on KG-derived supervision, and apply reinforcement learning using path-derived KG signals as implicit reward models. Our results demonstrate that deep, mechanistic neuroscience understanding can be induced in the model without reliance on large, heterogeneous web-scale corpora. The KG-based synthetic neuroscience curriculum that readers can quiz themselves on, and the fine-tuned LM, are available at the following GitHub location: https://kg-bottom-up-superintelligence.github.io/neuro-bench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that structured knowledge from a single neuroscience textbook, distilled into a high-quality KG via a dual-LLM validation pipeline, expanded with a masked LM, converted into multi-hop QA supervision with reasoning traces, and used to fine-tune an LM with reinforcement learning driven by path-derived KG signals as implicit rewards, is sufficient to induce expert-level mechanistic reasoning that surpasses LLMs in accuracy while using orders of magnitude fewer parameters, without reliance on web-scale corpora. The KG-based curriculum and fine-tuned model are released publicly.
Significance. If the central hypothesis is supported by rigorous quantitative evaluation, this would be significant for demonstrating that high-quality, domain-specific structured knowledge can enable compact models to achieve deep expert-level reasoning in specialized scientific fields. It offers a controlled, bottom-up alternative to large-scale pretraining and includes reproducible artifacts via GitHub, which strengthens its potential impact on AI for science.
major comments (3)
- [Abstract] Abstract: the assertion that the fine-tuned model 'surpasses large language models (LLMs) in accuracy' is presented without any quantitative metrics, baselines, error bars, comparison methodology, or results tables, leaving the central performance claim without supporting evidence.
- [Abstract] Abstract: the dual-LLM validation pipeline is described as producing a high-quality KG that faithfully captures textbook content, yet no quantitative checks (textbook section coverage, relation error rates, or expert agreement scores) are reported; this is load-bearing for the expert-level reasoning claim.
- [Abstract] Abstract: reinforcement learning uses path-derived KG signals as implicit reward models generated from the identical KG that supplied the training QA pairs, creating a potential circularity where measured improvements may be artifacts of the construction process rather than independent generalization.
minor comments (1)
- [Abstract] Abstract: the phrase 'orders of magnitude fewer parameters' is used without specifying the parameter counts of the fine-tuned model or the LLMs used for comparison.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments. We address each major comment below with clarifications and indicate planned revisions to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the fine-tuned model 'surpasses large language models (LLMs) in accuracy' is presented without any quantitative metrics, baselines, error bars, comparison methodology, or results tables, leaving the central performance claim without supporting evidence.
Authors: The abstract summarizes the central hypothesis at a high level. The full manuscript reports quantitative evaluations, including accuracy comparisons against larger LLMs, baselines, error bars, and results tables in the experimental sections. To address the concern, we will revise the abstract to incorporate key performance metrics and a brief description of the evaluation methodology. revision: yes
-
Referee: [Abstract] Abstract: the dual-LLM validation pipeline is described as producing a high-quality KG that faithfully captures textbook content, yet no quantitative checks (textbook section coverage, relation error rates, or expert agreement scores) are reported; this is load-bearing for the expert-level reasoning claim.
Authors: We agree that explicit quantitative validation metrics strengthen the claims. The methods section describes the dual-LLM pipeline in detail, but the abstract does not summarize coverage, error rates, or agreement scores. We will revise the abstract to include a concise summary of these validation statistics. revision: yes
-
Referee: [Abstract] Abstract: reinforcement learning uses path-derived KG signals as implicit reward models generated from the identical KG that supplied the training QA pairs, creating a potential circularity where measured improvements may be artifacts of the construction process rather than independent generalization.
Authors: We acknowledge the potential for circularity when both supervision and rewards derive from the same KG. The RL component encourages generation of valid reasoning paths on novel queries, while evaluation uses held-out questions and external benchmarks to measure generalization. We will revise the manuscript to explicitly clarify this distinction and detail the held-out evaluation protocol. revision: partial
Circularity Check
RL rewards and QA supervision both derived from identical KG reduce performance to training artifacts
specific steps
-
fitted input called prediction
[Abstract]
"generate multi-hop QA items, which include QA pairs and reasoning traces, to fine-tune an LM exclusively on KG-derived supervision, and apply reinforcement learning using path-derived KG signals as implicit reward models"
The QA pairs/reasoning traces used for supervised fine-tuning and the path-derived signals used as RL rewards are generated from the identical textbook-derived KG. Performance on tasks derived from this KG is therefore aligned by construction with the training distribution, reducing the 'expert-level reasoning' result to an artifact of the data-generation pipeline rather than an independent outcome.
full rationale
The derivation chain constructs a KG from the textbook, generates QA supervision and reasoning traces from it for fine-tuning, then applies RL with path-derived signals from the same KG as implicit rewards. This makes measured accuracy on KG-grounded tasks a direct consequence of the shared construction process rather than independent emergence of expert reasoning. The central claim of surpassing LLMs with far fewer parameters therefore rests on evaluation that is not separated from the input KG topology. No other circular steps (self-citation chains, ansatz smuggling, or uniqueness theorems) appear in the provided text.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A single authoritative textbook contains sufficient structured knowledge to induce expert-level neuroscience reasoning
- domain assumption Dual-LLM validation produces a faithful KG without material omissions or hallucinations
Reference graph
Works this paper leans on
-
[1]
Claude Opus 4.5 System Card Technical Report
Anthropic. “Claude Opus 4.5 System Card Technical Report.” 2025
2025
-
[2]
Jinze Bai, Shuai Bai, Yunfei Chu, et al. “Qwen Technical Report.”arXiv preprint arXiv:2309.16609, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
GraphMERT: Effi- cient and scalable distillation of reliable knowledge graphs from unstructured data
Margarita Belova, Jiaxin Xiao, Shikhar Tuli, and Niraj K. Jha. “GraphMERT: Effi- cient and scalable distillation of reliable knowledge graphs from unstructured data.” Transactions on Machine Learning Research, 21 Feb. 2026
2026
-
[4]
Curriculum learning
Yoshua Bengio, Jérôme Louradour, Ronan Collobert, et al. “Curriculum learning.” Proceedings of the International Conference on Machine Learning, pp. 41–48, 2009
2009
-
[5]
Translating embeddings for modeling multi-relational data
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, et al. “Translating embeddings for modeling multi-relational data.”Advances in Neural Information Processing Systems, 26, 2013
2013
-
[6]
COMET: Commonsense Transformers for Automatic Knowledge Graph Construction
Antoine Bosselut, Hannah Rashkin, Maarten Sap, et al. “COMET: Commonsense trans- formers for automatic knowledge graph construction.”arXiv preprint arXiv:1906.05317, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[7]
Oxford University Press, 2014
Nick Bostrom.Superintelligence: Paths, Dangers, Strategies. Oxford University Press, 2014
2014
-
[8]
Language models are few-shot learners
Tom Brown, Benjamin Mann, Nick Ryder, et al. “Language models are few-shot learners.”Advances in Neural Information Processing Systems, 33:1877–1901, 2020
1901
-
[9]
Collin Burns, Pavel Izmailov, Jan Hendrik Kirchner, et al. “Weak-to-strong gen- eralization: Eliciting strong capabilities with weak supervision.”arXiv preprint arXiv:2312.09390, 2023
-
[10]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosar, Mohammad Bavarian, et al. “Training verifiers to solve math word problems.”arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[11]
Bottom-up domain-specific superintelligence: A reliable knowledge graph is what we need
Bhishma Dedhia, Yuval Kansal, and Niraj K. Jha. “Bottom-up domain-specific superintelligence: A reliable knowledge graph is what we need.”arXiv preprint arXiv:2507.13966, 2025
-
[12]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI. “DeepSeek-R1: Incentivizing reasoning capability in LLMs via reinforce- ment learning.”arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Fodor.The Language of Thought
Jerry A. Fodor.The Language of Thought. Harvard University Press, 1975. 23
1975
-
[14]
Scaling laws for reward model overop- timization
Leo Gao, John Schulman, and Jacob Hilton. “Scaling laws for reward model overop- timization.”Proceedings of the International Conference on Machine Learning, pp. 10835–10866, 2023
2023
-
[15]
Neurosymbolic AI: The 3rd wave
Artur d’Avila Garcez and Luís C. Lamb. “Neurosymbolic AI: The 3rd wave.”Artificial Intelligence Review, 56(11):12387–12406, 2023
2023
-
[16]
Lei Huang, Weijiang Yu, Weitao Ma, et al. “A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.”arXiv preprint arXiv:2311.05232, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Survey of hallucination in natural language generation
Ziwei Ji, Nayeon Lee, Rita Frieske, et al. “Survey of hallucination in natural language generation.”ACM Computing Surveys, 55(12):1–38, 2023
2023
-
[18]
Prototype theory and compositionality
Hans Kamp and Barbara Partee. “Prototype theory and compositionality.”Cognition, 57(2):129–191, 1995
1995
-
[19]
Kandel, James H
Eric R. Kandel, James H. Schwartz, Thomas M. Jessell, Steven A. Siegelbaum, and A. J. Hudspeth.Principles of Neural Science, Fifth Edition. McGraw-Hill, 2013
2013
-
[20]
Knowledge graphs are implicit reward models: Path- derived signals enable compositional reasoning
Yuval Kansal and Niraj K. Jha. “Knowledge graphs are implicit reward models: Path- derived signals enable compositional reasoning.”arXiv preprint arXiv:2601.15160, 2026
-
[21]
Semi-Supervised Classification with Graph Convolutional Networks
Thomas N. Kipf and Max Welling. “Semi-supervised classification with graph convolu- tional networks.”arXiv preprint arXiv:1609.02907, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[22]
Hunter Lightman, Vineet Kosar, William Saunders, et al. “Let’s verify step by step.” arXiv preprint arXiv:2305.20050, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
Hello GPT-4o. System Card and Technical Overview
OpenAI. “Hello GPT-4o. System Card and Technical Overview.” https://openai.com/index/hello-gpt-4o/, 2024
2024
-
[24]
Training language models to follow instructions with human feedback
Long Ouyang, Jeffrey Wu, Xu Jiang, et al. “Training language models to follow instructions with human feedback.”Advances in Neural Information Processing Systems, 35:27730–27744, 2022
2022
-
[25]
Unifying large language models and knowledgegraphs: Aroadmap
Shirui Pan, Linhao Luo, Yufei Wang, et al. “Unifying large language models and knowledgegraphs: Aroadmap.”IEEE Transactions on Knowledge and Data Engineering, 2023
2023
-
[26]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, et al. “Direct preference optimization: Your language model is secretly a reward model.”Advances in Neural Information Processing Systems, 36, 2023. 24
2023
-
[27]
Neuro-symbolic artificial intelligence: Current trends
Md Kamruzzaman Sarker, Luís C Lamb, and Pascal Hitzler. “Neuro-symbolic artificial intelligence: Current trends.”arXiv preprint arXiv:2105.05330, 2021
-
[28]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. “Proximal policy optimization algorithms.”arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[29]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, et al. “DeepSeekMath: Pushing the limits of mathematical reasoning in open language models.”arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[30]
Sample more to think less: Group filtered policy optimization for concise reasoning
V. Shrivastava, et al. “Sample more to think less: Group filtered policy optimization for concise reasoning.”arXiv preprint arXiv:2508.09726, 2025
-
[31]
Large language models encode clinical knowledge
Karan Singhal, Shekoofeh Azizi, Tao Tu, et al. “Large language models encode clinical knowledge.”Nature, 620(7972):172–180, 2023
2023
-
[32]
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Charlie Snell, Jaehoon Lee, Kelvin Xu, et al. “Scaling LLM test-time compute optimally can be more effective than scaling model parameters.”arXiv preprint arXiv:2408.03314, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[33]
Galactica: A Large Language Model for Science
Ross Taylor, Marcin Kardas, Guillem Cucurull, et al. “Galactica: A large language model for science.”arXiv preprint arXiv:2211.09085, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[34]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, et al. “Llama 2: Open foundation and fine-tuned chat models.”arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
KEPLER: A unified model for knowledge embedding and pre-trained language representation
Xiaozhi Wang, Tianyu Gao, Zhaocheng Zhu, et al. “KEPLER: A unified model for knowledge embedding and pre-trained language representation.”Transactions of the Association for Computational Linguistics, 9:176–194, 2021
2021
-
[36]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, et al. “Chain-of-thought prompting elicits reasoning in large language models.”Advances in Neural Information Processing Systems, 35:24824–24837, 2022
2022
-
[37]
Hallucination is Inevitable: An Innate Limitation of Large Language Models
Ziwei Xu, Sanjay Jain, and Mohan Kankanhalli. “Hallucination is inevitable: An innate limitation of large language models.”arXiv preprint arXiv:2401.11817, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[38]
Tree of thoughts: Deliberate problem solving with large language models
Shunyu Yao, Dian Yu, Jeffrey Zhao, et al. “Tree of thoughts: Deliberate problem solving with large language models.”Advances in Neural Information Processing Systems, 36, 2024
2024
-
[39]
A comprehensive survey on automatic knowledge graph construction
Y. Zhong, et al. “A comprehensive survey on automatic knowledge graph construction.” ACM Computing Surveys, 2023. 25
2023
-
[40]
Knowledge graphs meet multi-modal learning: A comprehensive survey
Peiyi Wang, Yifan Song, Chenyang Zhao, et al. “Knowledge graphs meet multi-modal learning: A comprehensive survey.”arXiv preprint arXiv:2305.10660, 2023
-
[41]
Continual lifelong learning with neural networks: A review
German I. Parisi, Ronald Kemker, Jose L. Part, et al. “Continual lifelong learning with neural networks: A review.”Neural Networks, 113:54–71, 2019
2019
-
[42]
Representation learning on graphs: Methods and applications
William L. Hamilton, Rex Ying, and Jure Leskovec. “Representation learning on graphs: Methods and applications.”IEEE Data Engineering Bulletin, 40(3):52–74, 2017
2017
-
[43]
Niklas Muennighoff, et al. “s1: Simple test-time scaling.”arXiv preprint arXiv:2501.19393, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[44]
LoRA: Low-Rank Adaptation of Large Language Models
Edward J. Hu, Yelong Shen, Phillip Walber, et al. “LoRA: Low-rank adaptation of large language models.”arXiv preprint arXiv:2106.09685, 2021. A Knowledge Graph Extraction Prompt The system prompt presented next is used verbatim for all text unit extraction calls during Phase1. Theplaceholder {relation_list}ispopulatedatruntimewiththeJSON-serialized closed...
work page internal anchor Pith review Pith/arXiv arXiv 2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.