Towards Deploying Optimistic Quantum Fourier Transforms: An Architecture-Algorithm Co-Design Study
Pith reviewed 2026-05-19 16:01 UTC · model grok-4.3
The pith
A hot-zone architecture lets the Optimistic Quantum Fourier Transform reach half its serial latency with roughly 500 extra logical ancillae and 128-qubit peak parallelism.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
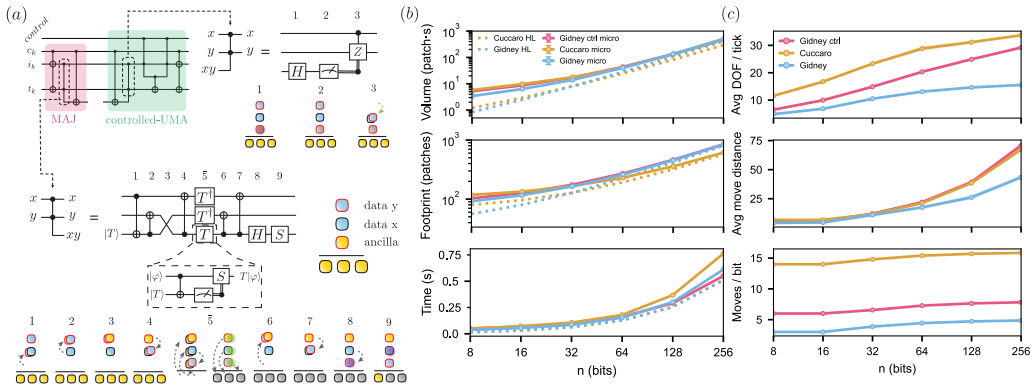
The Optimistic Quantum Fourier Transform structure benefits from phase-gradient resources and small blocks that reward mobility and parallelism. In the hot-zone model with catalytic phase-gradient addition and heuristic micro-scheduling of adders, two zones reproduce serial latency, four zones cut runtime by about half, and more zones approach constant-time execution. For 256- to 2048-bit sizes, half-time performance converges on about 500 additional logical ancillae and a peak parallelism of 128 logical qubits, while endianness mismatches are fixed by cyclic swaps and alternating reflections.
What carries the argument
The hot-zone architecture that decouples data storage from processing and routes mobile resource packages (magic-state factories, bridge qubits, and phase-gradient registers) to stationary data regions.
If this is right
- Two hot zones reproduce serial-QFT latency.
- Four hot zones roughly halve runtime.
- Further hot zones approach constant-time execution at rising resource cost.
- Gidney and Cuccaro adders show comparable space-time volume yet differ in required parallelism.
- Endianness mismatches are resolved by cyclic phase-gradient swaps and alternating QFT reflections.
Where Pith is reading between the lines
- The same mobility strategy could apply to other phase-estimation or period-finding primitives.
- Reaction-limited behavior may push neutral-atom control systems toward faster feedback loops.
- Resource estimates that stabilize across bit widths imply the approach scales without sudden jumps in overhead.
- Adaptations of the hot-zone idea might suit ion-trap or superconducting platforms with suitable routing.
Load-bearing premise
The surface-code fault-tolerant execution model together with the heuristic micro-scheduling of ripple-carry adders and catalytic phase-gradient addition accurately captures the dominant space-time costs on reconfigurable neutral-atom hardware.
What would settle it
A detailed resource simulation or hardware run on neutral-atom arrays that measures whether the ancilla count and parallelism needed to reach half serial QFT latency match the predicted 500 ancillae and 128 qubits.
Figures



read the original abstract
We present an architecture-algorithm co-design study of the Optimistic Quantum Fourier Transform (OQFT) under a surface-code fault-tolerant execution model for reconfigurable neutral-atom hardware. Analyzing the OQFT structure, particularly its reliance on phase-gradient resources and small-scale blocks, highlights architectural requirements for resource mobility and parallel execution. Guided by that, we introduce a hot-zone architecture that decouples data storage from processing and dynamically routes mobile resource packages (magic-state factories, bridge qubits, and phase-gradient registers) to stationary data regions. To expose dominant costs, we route rotation insertions via catalytic phase-gradient addition and heuristically micro-schedule ripple-carry adders to patch-level moves. Under this model, leading Gidney~\cite{Gidney2018halvingcostof} and Cuccaro~\cite{cuccaro2004} adders have similar space-time volume but require different levels of parallelism. At the algorithm level, the five-layer OQFT shows a tunable parallelism/latency trade-off: two hot zones match serial-QFT latency, four hot zones roughly halve runtime, and additional hot zones asymptotically approach constant-time execution at substantial resource cost. Across 256-2048-bit instances, the requirements for half-time performance converge to about 500 additional logical ancillae and a peak parallelism of 128 logical qubits. We also identify broader algorithm-architecture bottlenecks, including endianness mismatches between phase-gradient and data registers, addressed via cyclic phase-gradient swaps and alternating QFT reflections. Scoped to surface codes and cultivation-only magic-state factories, our analysis identifies reaction-limited operation and parallelism demand as primary drivers of resource estimation and establishes a generalizable foundation for primitive-based architectural studies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an architecture-algorithm co-design study of the Optimistic Quantum Fourier Transform (OQFT) under a surface-code fault-tolerant execution model for reconfigurable neutral-atom hardware. It introduces a hot-zone architecture that decouples data storage from processing and dynamically routes mobile resource packages, employs heuristic micro-scheduling of ripple-carry adders to patch-level moves together with catalytic phase-gradient addition, and reports that across 256-2048-bit instances the requirements for half-time performance converge to approximately 500 additional logical ancillae and a peak parallelism of 128 logical qubits. The work also examines tunable parallelism/latency trade-offs with varying numbers of hot zones and identifies algorithm-architecture bottlenecks such as endianness mismatches addressed via cyclic swaps and alternating reflections.
Significance. If the heuristic scheduling and surface-code execution model accurately capture dominant costs, the results provide concrete resource estimates and architectural guidelines for deploying OQFT on neutral-atom platforms, highlighting the value of dynamic routing and parallelism. The observed convergence of ancilla and parallelism requirements across bit sizes, together with the explicit use of Gidney (2018) and Cuccaro (2004) adder constructions, supplies a useful foundation for primitive-based studies in quantum architecture co-design.
major comments (3)
- [Abstract and resource-estimation analysis] Abstract and resource-estimation analysis: the headline quantitative claim that half-time OQFT performance converges to ~500 logical ancillae and 128-qubit peak parallelism rests on the heuristic micro-scheduling of ripple-carry adders to patch-level moves and catalytic phase-gradient addition. No validation against exact schedulers, exhaustive enumeration, or sensitivity analysis to move-overhead or reaction-latency assumptions is provided, so systematic under-counting would directly scale the reported figures.
- [Hot-zone architecture and execution-model section] Hot-zone architecture and execution-model section: the surface-code fault-tolerant model with cultivation-only factories is stated as the basis for routing and parallelism analysis, yet the paper supplies only summarized details of the assumed execution model; without an explicit derivation or error budget for reaction-limited operation, the support for the exact ancilla and parallelism numbers remains limited.
- [Five-layer OQFT and hot-zone trade-off discussion] Five-layer OQFT and hot-zone trade-off discussion: the statements that two hot zones match serial-QFT latency and four hot zones roughly halve runtime are central to the tunable-parallelism claim, but lack accompanying equations, tables, or latency calculations that would allow independent verification of the scaling with number of hot zones.
minor comments (2)
- [Figure 1 or equivalent architecture diagram] Notation for mobile resource packages (magic-state factories, bridge qubits, phase-gradient registers) could be introduced more explicitly in the first figure or diagram to improve readability for readers unfamiliar with the hot-zone routing.
- [Endianness-mismatch subsection] The discussion of endianness mismatches and cyclic phase-gradient swaps would benefit from a short pseudocode or timing diagram illustrating the alternating QFT reflections.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We have carefully considered each major comment and provide point-by-point responses below. Where appropriate, we have revised the manuscript to improve clarity and provide additional supporting details.
read point-by-point responses
-
Referee: [Abstract and resource-estimation analysis] Abstract and resource-estimation analysis: the headline quantitative claim that half-time OQFT performance converges to ~500 logical ancillae and 128-qubit peak parallelism rests on the heuristic micro-scheduling of ripple-carry adders to patch-level moves and catalytic phase-gradient addition. No validation against exact schedulers, exhaustive enumeration, or sensitivity analysis to move-overhead or reaction-latency assumptions is provided, so systematic under-counting would directly scale the reported figures.
Authors: We agree that the resource estimates depend on the heuristic micro-scheduling, which was designed to highlight the primary bottlenecks in the hot-zone architecture rather than to provide optimal schedules. Exact schedulers or exhaustive enumeration are computationally infeasible for the instance sizes considered (256-2048 bits). To address this, we have added a sensitivity analysis to variations in move-overhead and reaction latency in the revised manuscript, showing that the convergence to approximately 500 ancillae and 128-qubit parallelism remains robust within reasonable parameter ranges. We also include results from a simplified greedy scheduler for smaller instances to provide bounds on potential discrepancies. revision: yes
-
Referee: [Hot-zone architecture and execution-model section] Hot-zone architecture and execution-model section: the surface-code fault-tolerant model with cultivation-only factories is stated as the basis for routing and parallelism analysis, yet the paper supplies only summarized details of the assumed execution model; without an explicit derivation or error budget for reaction-limited operation, the support for the exact ancilla and parallelism numbers remains limited.
Authors: We have expanded the relevant section to include a more explicit derivation of the reaction-limited operation under the surface-code model with cultivation-only factories. This now incorporates a detailed error budget that justifies the assumptions used for ancilla counts and parallelism requirements. These additions provide greater transparency and allow readers to better assess the support for the reported figures. revision: yes
-
Referee: [Five-layer OQFT and hot-zone trade-off discussion] Five-layer OQFT and hot-zone trade-off discussion: the statements that two hot zones match serial-QFT latency and four hot zones roughly halve runtime are central to the tunable-parallelism claim, but lack accompanying equations, tables, or latency calculations that would allow independent verification of the scaling with number of hot zones.
Authors: We acknowledge the need for explicit supporting material. In the revised version, we have included a new subsection with equations for the latency scaling as a function of the number of hot zones, along with a table that tabulates the computed latencies for 2, 4, and higher numbers of zones across the bit sizes considered. This enables independent verification of the claims that two hot zones match serial-QFT latency and four hot zones approximately halve the runtime. revision: yes
Circularity Check
No significant circularity; resource counts derive from external adders and modeling choices
full rationale
The paper's central quantitative claims (convergence to ~500 ancillae and 128-qubit parallelism for half-time OQFT) are obtained by applying the described hot-zone routing, catalytic phase-gradient addition, and heuristic patch-level scheduling to the OQFT structure under a standard surface-code model. These steps invoke external constructions (Gidney 2018, Cuccaro 2004) whose details lie outside the present work; no equation or claim reduces the reported numbers to parameters fitted or defined by the authors themselves. The analysis therefore remains self-contained against external benchmarks and does not exhibit self-definitional, fitted-input, or self-citation-load-bearing circularity.
Axiom & Free-Parameter Ledger
free parameters (2)
- number of hot zones
- peak parallelism level
axioms (2)
- domain assumption Surface-code fault-tolerant execution model applies directly to reconfigurable neutral-atom hardware
- ad hoc to paper Heuristic micro-scheduling of ripple-carry adders to patch-level moves captures dominant costs
Reference graph
Works this paper leans on
-
[1]
Halving the cost of quantum addition,
C. Gidney, “Halving the cost of quantum addition,”Quantum, vol. 2, p. 74, Jun. 2018. [Online]. Available: https://doi.org/10.22331/q-201 8-06-18-74
-
[2]
A new quantum ripple-carry addition circuit
S. A. Cuccaro, T. G. Draper, S. A. Kutin, and D. P. Moulton, “A new quantum ripple-carry addition circuit,” 2004. [Online]. Available: https://arxiv.org/abs/quant-ph/0410184
work page internal anchor Pith review Pith/arXiv arXiv 2004
-
[3]
Time-optimal quantum computation
A. G. Fowler, “Time-optimal quantum computation,” 2013. [Online]. Available: https://arxiv.org/abs/1210.4626
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[4]
Quantum block lookahead adders and the wait for magic states,
C. Gidney, “Quantum block lookahead adders and the wait for magic states,” 2020. [Online]. Available: https://arxiv.org/abs/2012.01624
-
[5]
Magic state cultivation: growing T states as cheap as CNOT gates
C. Gidney, N. Shutty, and C. Jones, “Magic state cultivation: growing t states as cheap as cnot gates,” 2024. [Online]. Available: https://arxiv.org/abs/2409.17595
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
Efficient magic state cultivation onRP 2,
Z.-H. Chen, M.-C. Chen, C.-Y . Lu, and J.-W. Pan, “Efficient magic state cultivation onRP 2,” 2025. [Online]. Available: https: //arxiv.org/abs/2503.18657
-
[7]
Sahay, et al.,Fold-transversal surface code cultivation (2026), arXiv:2509.05212 [quant-ph]
K. Sahay, P.-K. Tsai, K. Chang, Q. Su, T. B. Smith, S. Singh, and S. Puri, “Fold-transversal surface code cultivation,” 2025. [Online]. Available: https://arxiv.org/abs/2509.05212
-
[8]
Magic tricycles: Efficient magic state generation with finite block-length quantum LDPC codes
V . Menon, J. P. Bonilla-Ataides, R. Mehta, A. Gu, D. B. Tan, and M. D. Lukin, “Magic tricycles: Efficient magic state generation with finite block-length quantum ldpc codes,” 2025. [Online]. Available: https://arxiv.org/abs/2508.10714
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
D. Litinski and N. Nickerson, “Active volume: An architecture for efficient fault-tolerant quantum computers with limited non-local connections,” 2022. [Online]. Available: https://arxiv.org/abs/2211.154 65
work page 2022
-
[10]
Constant- overhead fault-tolerant quantum computation with reconfigurable atom arrays,
Q. Xu, J. P. B. Ataides, C. A. Pattison, N. Raveendran, D. Bluvstein, J. Wurtz, B. Vasic, M. D. Lukin, L. Jiang, and H. Zhou, “Constant- overhead fault-tolerant quantum computation with reconfigurable atom arrays,” 2023. [Online]. Available: https://arxiv.org/abs/2308.08648
-
[11]
Resource analysis of low- overhead transversal architectures for reconfigurable atom arrays,
H. Zhou, C. Duckering, C. Zhao, D. Bluvstein, M. Cain, A. Kubica, S.-T. Wang, and M. D. Lukin, “Resource analysis of low- overhead transversal architectures for reconfigurable atom arrays,” in Proceedings of the 52nd Annual International Symposium on Computer Architecture, ser. ISCA ’25. New York, NY , USA: Association for Computing Machinery, 2025, p. 14...
-
[12]
How to factor 2048 bit RSA integers with less than a million noisy qubits
C. Gidney, “How to factor 2048 bit rsa integers with less than a million noisy qubits,” 2025. [Online]. Available: https: //arxiv.org/abs/2505.15917
work page internal anchor Pith review Pith/arXiv arXiv 2048
-
[13]
Shor's algorithm is possible with as few as 10,000 reconfigurable atomic qubits
M. Cain, Q. Xu, R. King, L. R. B. Picard, H. Levine, M. Endres, J. Preskill, H.-Y . Huang, and D. Bluvstein, “Shor’s algorithm is possible with as few as 10,000 reconfigurable atomic qubits,” 2026. [Online]. Available: https://arxiv.org/abs/2603.28627
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
R. Babbush, A. Zalcman, C. Gidney, M. Broughton, T. Khattar, H. Neven, T. Bergamaschi, J. Drake, and D. Boneh, “Securing elliptic curve cryptocurrencies against quantum vulnerabilities: Resource estimates and mitigations,” 2026. [Online]. Available: https://arxiv.org/ abs/2603.28846
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[15]
Magic State Distillation: Not as Costly as You Think,
D. Litinski, “Magic State Distillation: Not as Costly as You Think,”Quantum, vol. 3, p. 205, Dec. 2019. [Online]. Available: https://doi.org/10.22331/q-2019-12-02-205
-
[16]
E. Gouzien, D. Ruiz, F.-M. Le Regent, J. Guillaud, and N. Sangouard, “Performance analysis of a repetition cat code architecture: Computing 256-bit elliptic curve logarithm in 9 hours with 126133 cat qubits,” Physical Review Letters, vol. 131, no. 4, Jul. 2023. [Online]. Available: http://dx.doi.org/10.1103/PhysRevLett.131.040602
-
[17]
P. Webster, L. Berent, O. Chandra, E. T. Hockings, N. Baspin, F. Thomsen, S. C. Smith, and L. Z. Cohen, “The pinnacle architecture: Reducing the cost of breaking rsa-2048 to 100 000 physical qubits using quantum ldpc codes,” 2026. [Online]. Available: https://arxiv.org/abs/2602.11457
work page internal anchor Pith review Pith/arXiv arXiv 2048
-
[18]
A log-depth in-place quantum fourier transform that rarely needs ancillas,
G. D. Kahanamoku-Meyer, J. Blue, T. Bergamaschi, C. Gidney, and I. L. Chuang, “A log-depth in-place quantum fourier transform that rarely needs ancillas,” 2025. [Online]. Available: https://arxiv.org/abs/ 2505.00701
-
[19]
Approximate encoded permutations and piecewise quantum adders
C. Gidney, “Approximate encoded permutations and piecewise quantum adders,” 2019. [Online]. Available: https://arxiv.org/abs/1905.08488
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[20]
Fast quantum integer multiplication with zero ancillas,
G. D. Kahanamoku-Meyer and N. Y . Yao, “Fast quantum integer multiplication with zero ancillas,” 2024. [Online]. Available: https: //arxiv.org/abs/2403.18006
-
[21]
Spacetime- efficient and hardware-compatible complex quantum logic units in qldpc codes,
W. Yang, J. Chadwick, M. H. Teo, J. Viszlai, and F. Chong, “Spacetime- efficient and hardware-compatible complex quantum logic units in qldpc codes,” 2026. [Online]. Available: https://arxiv.org/abs/2602.14273
-
[22]
Fast and parallelizable logical computation with homological product codes,
Q. Xu, H. Zhou, G. Zheng, D. Bluvstein, J. P. B. Ataides, M. D. Lukin, and L. Jiang, “Fast and parallelizable logical computation with homological product codes,” 2024. [Online]. Available: https://arxiv.org/abs/2407.18490
-
[23]
Batched high-rate logical operations for quantum ldpc codes,
Q. Xu, H. Zhou, D. Bluvstein, M. Cain, M. Kalinowski, J. Preskill, M. D. Lukin, and N. Maskara, “Batched high-rate logical operations for quantum ldpc codes,” 2025. [Online]. Available: https://arxiv.org/ab s/2510.06159
-
[24]
Correlated decoding of logical algorithms with transversal gates,
M. Cain, C. Zhao, H. Zhou, N. Meister, J. P. B. Ataides, A. Jaffe, D. Bluvstein, and M. D. Lukin, “Correlated decoding of logical algorithms with transversal gates,” 2025. [Online]. Available: https://arxiv.org/abs/2403.03272
-
[25]
Expressing and analyzing quantum algorithms with qualtran,
M. P. Harrigan, T. Khattar, C. Yuan, A. Peduri, N. Yosri, F. D. Malone, R. Babbush, and N. C. Rubin, “Expressing and analyzing quantum algorithms with qualtran,” 2024. [Online]. Available: https://arxiv.org/abs/2409.04643
-
[26]
An approximate fourier transform useful in quantum factoring,
D. Coppersmith, “An approximate fourier transform useful in quantum factoring,” 2002. [Online]. Available: https://arxiv.org/abs/quant-ph/02 01067
work page 2002
-
[27]
Logic synthesis for fault-tolerant quantum computers,
N. C. Jones, “Logic synthesis for fault-tolerant quantum computers,”
-
[28]
Logic Synthesis for Fault-Tolerant Quantum Computers
[Online]. Available: https://arxiv.org/abs/1310.7290
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Approximate quantum fourier transform,
C. Gidney, “Approximate quantum fourier transform,” https://algassert. com/post/1620, 2017, accessed: 2026-03-11
work page 2017
-
[30]
Approximate quantum fourier transform,
Quantumlib and Qualtran Contributors, “Approximate quantum fourier transform,” 2025, source code implementation in the Qualtran library. [Online]. Available: https://github.com/quantumlib/Qualtran/blob/main /qualtran/bloqs/qft/approximate qft.py
work page 2025
-
[31]
Low-overhead constructions for the fault-tolerant toffoli gate,
C. Jones, “Low-overhead constructions for the fault-tolerant toffoli gate,”Phys. Rev. A, vol. 87, p. 022328, Feb 2013. [Online]. Available: https://link.aps.org/doi/10.1103/PhysRevA.87.022328
-
[32]
A tweezer array with 6,100 highly coherent atomic qubits,
H. J. Manetsch, G. Nomura, E. Bataille, X. Lv, K. H. Leung, and M. Endres, “A tweezer array with 6,100 highly coherent atomic qubits,” Nature, vol. 647, no. 8088, p. 60–67, 2025. [Online]. Available: http://dx.doi.org/10.1038/s41586-025-09641-4
-
[33]
Fast neutral-atom transport and transfer between optical tweezers,
C. Cicali, M. Calzavara, E. Cuestas, T. Calarco, R. Zeier, and F. Motzoi, “Fast neutral-atom transport and transfer between optical tweezers,” Phys. Rev. Appl., vol. 24, p. 024070, Aug 2025. [Online]. Available: https://link.aps.org/doi/10.1103/7r3w-8m61
-
[34]
Supercharged two- dimensional tweezer array with more than 1000 atomic qubits,
L. Pause, L. Sturm, M. Mittenb ¨uhler, S. Amann, T. Preuschoff, D. Sch ¨affner, M. Schlosser, and G. Birkl, “Supercharged two- dimensional tweezer array with more than 1000 atomic qubits,” Optica, vol. 11, no. 2, p. 222, Feb. 2024. [Online]. Available: http://dx.doi.org/10.1364/OPTICA.513551
-
[35]
A quantum processor based on coherent transport of entangled atom arrays,
D. Bluvstein, H. Levine, G. Semeghini, T. T. Wang, S. Ebadi, M. Kalinowski, A. Keesling, N. Maskara, H. Pichler, M. Greiner, V . Vuleti´c, and M. D. Lukin, “A quantum processor based on coherent transport of entangled atom arrays,”Nature, vol. 604, no. 7906, p. 451–456, Apr. 2022. [Online]. Available: http: //dx.doi.org/10.1038/s41586-022-04592-6
-
[36]
S. Anand, C. E. Bradley, R. White, V . Ramesh, K. Singh, and H. Bernien, “A dual-species rydberg array,”Nature Physics, vol. 20, no. 11, p. 1744–1750, Sep. 2024. [Online]. Available: http://dx.doi.org/10.1038/s41567-024-02638-2
-
[37]
On exact space-depth trade-offs in multi-controlled toffoli decomposition,
S. Dutta, S. Wang, A. Baksi, A. Chattopadhyay, and S. Maitra, “On exact space-depth trade-offs in multi-controlled toffoli decomposition,”
-
[38]
Available: https://arxiv.org/abs/2502.01433
[Online]. Available: https://arxiv.org/abs/2502.01433
-
[39]
A linear-size quantum circuit for addition with no ancillary qubits,
Y . Takahashi and N. Kunihiro, “A linear-size quantum circuit for addition with no ancillary qubits,”Quant. Inf. Comput., vol. 5, no. 6, pp. 440–448, 2005
work page 2005
-
[40]
Flexible layout of surface code computations using AutoCCZ states
C. Gidney and A. G. Fowler, “Flexible layout of surface code computations using autoccz states,” 2019. [Online]. Available: https: //arxiv.org/abs/1905.08916
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[41]
C. Gidney, “Windowed quantum arithmetic,” 2019. [Online]. Available: https://arxiv.org/abs/1905.07682
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[42]
How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits,
C. Gidney and M. Eker ˚a, “How to factor 2048 bit RSA integers in 8 hours using 20 million noisy qubits,”Quantum, vol. 5, p. 433, Apr
work page 2048
-
[43]
How to factor 2048 bit rsa integers in 8 hours using 20 million noisy qubits.Quantum, 5:433, 2021
[Online]. Available: https://doi.org/10.22331/q-2021-04-15-433
-
[44]
How to compute a 256-bit elliptic curve private key with only 50 million toffoli gates,
D. Litinski, “How to compute a 256-bit elliptic curve private key with only 50 million toffoli gates,” 2023. [Online]. Available: https://arxiv.org/abs/2306.08585
-
[45]
Log- ical quantum processor based on reconfigurable atom arrays.Nature, 626(7997):58–65, 2024
D. Bluvstein, S. J. Evered, A. A. Geim, S. H. Li, H. Zhou, T. Manovitz, S. Ebadi, M. Cain, M. Kalinowski, D. Hangleiter, J. P. Bonilla Ataides, N. Maskara, I. Cong, X. Gao, P. Sales Rodriguez, T. Karolyshyn, G. Semeghini, M. J. Gullans, M. Greiner, V . Vuleti ´c, and M. D. Lukin, “Logical quantum processor based on reconfigurable atom arrays,” Nature, vol...
-
[46]
Probing the kitaev honeycomb model on a neutral-atom quantum computer,
S. J. Evered, M. Kalinowski, A. A. Geim, T. Manovitz, D. Bluvstein, S. H. Li, N. Maskara, H. Zhou, S. Ebadi, M. Xu, J. Campo, M. Cain, S. Ostermann, S. F. Yelin, S. Sachdev, M. Greiner, V . Vuleti ´c, and M. D. Lukin, “Probing the kitaev honeycomb model on a neutral-atom quantum computer,”Nature, vol. 645, no. 8080, p. 341–347, 2025. [Online]. Available: ...
-
[47]
Ai-enabled parallel assembly of thousands of defect-free neutral atom arrays,
R. Lin, H.-S. Zhong, Y . Li, Z.-R. Zhao, L.-T. Zheng, T.-R. Hu, H.-M. Wu, Z. Wu, W.-J. Ma, Y . Gao, Y .-K. Zhu, Z.-F. Su, W.-L. Ouyang, Y .-C. Zhang, J. Rui, M.-C. Chen, C.-Y . Lu, and J.-W. Pan, “Ai-enabled parallel assembly of thousands of defect-free neutral atom arrays,”Physical Review Letters, vol. 135, no. 6, Aug. 2025. [Online]. Available: http://d...
-
[48]
Data set, figure-generation script, and validation animations for
P. L. S. Lopes, “Data set, figure-generation script, and validation animations for ”Deploying Optimistic Quantum Fourier Transforms: An Architecture-Algorithm Co-Design Study”,” 2026. [Online]. Available: https://doi.org/10.5281/zenodo.20028120
-
[49]
C. Gidney, “How to eat magic states,” Talk presented at the APS Global Summit 2026, 2026, slides available online. [Online]. Available: https://docs.google.com/presentation/d/1b0r3pKWi3 Bu64Rc5Ojc 9eV jWyZPWRP3-UBnqNdJB0
work page 2026
-
[50]
An algorithm for path connections and its applications,
C. Y . Lee, “An algorithm for path connections and its applications,” IRE Trans. Electron. Comput., vol. 10, pp. 346–365, 1961. [Online]. Available: https://api.semanticscholar.org/CorpusID:40700386
work page 1961
-
[51]
C. Mead and L. Conway,Introduction to VLSI Systems. Reading, MA: Addison-Wesley, 1980
work page 1980
-
[52]
A regular layout for parallel adders,
R. P. Brent and H. T. Kung, “A regular layout for parallel adders,”IEEE Transactions on Computers, vol. C-31, no. 3, pp. 260–264, Mar. 1982
work page 1982
-
[53]
A fault-tolerant neutral-atom architecture for universal quantum computation,
D. Bluvstein, A. A. Geim, S. H. Li, S. J. Evered, J. P. Bonilla Ataides, G. Baranes, A. Gu, T. Manovitz, M. Xu, M. Kalinowski, S. Majidy, C. Kokail, N. Maskara, E. C. Trapp, L. M. Stewart, S. Hollerith, H. Zhou, M. J. Gullans, S. F. Yelin, M. Greiner, V . Vuleti´c, M. Cain, and M. D. Lukin, “A fault-tolerant neutral-atom architecture for universal quantum...
-
[54]
Continuous operation of a coherent 3,000- qubit system,
N.-C. Chiu, E. C. Trapp, J. Guo, M. H. Abobeih, L. M. Stewart, S. Hollerith, P. L. Stroganov, M. Kalinowski, A. A. Geim, S. J. Evered, S. H. Li, X. Lyu, L. M. Peters, D. Bluvstein, T. T. Wang, M. Greiner, V . Vuleti´c, and M. D. Lukin, “Continuous operation of a coherent 3,000- qubit system,”Nature, vol. 646, no. 8087, p. 1075–1080, Sep. 2025. [Online]. A...
-
[55]
Transversal star architecture for megaquop-scale quantum simulation with neutral atoms,
R. Ismail, I.-C. Chen, C. Zhao, R. Weiss, F. Liu, H. Zhou, S.-T. Wang, A. Sornborger, and M. Kornja ˇca, “Transversal star architecture for megaquop-scale quantum simulation with neutral atoms,” 2025. [Online]. Available: https://arxiv.org/abs/2509.18294
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.