Rank-Then-Act: Reward-Free Control from Frame-Order Progress
Pith reviewed 2026-07-03 17:40 UTC · model grok-4.3
The pith
A vision-language model trained on shuffled video frames supplies rank-correlation rewards sufficient to learn control policies without environment rewards.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
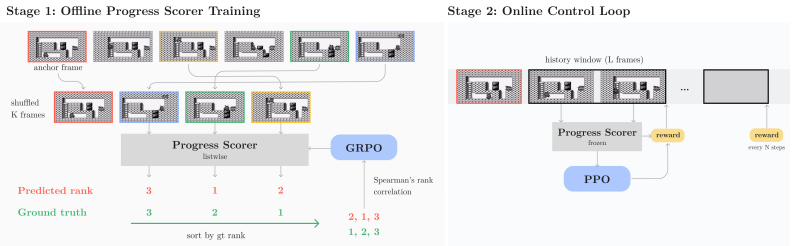
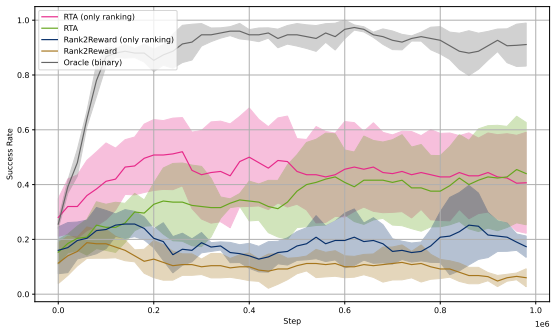
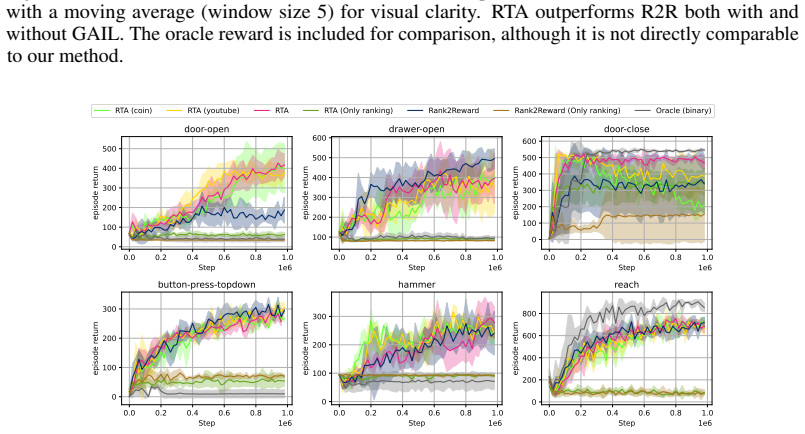
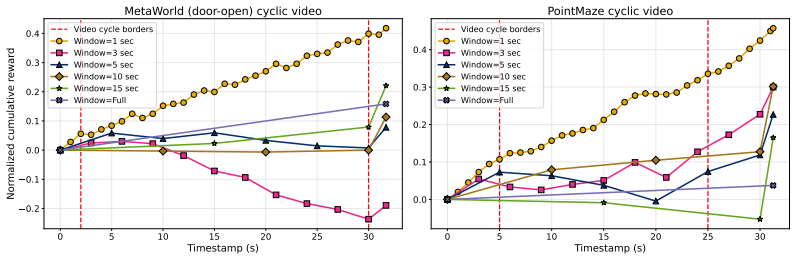
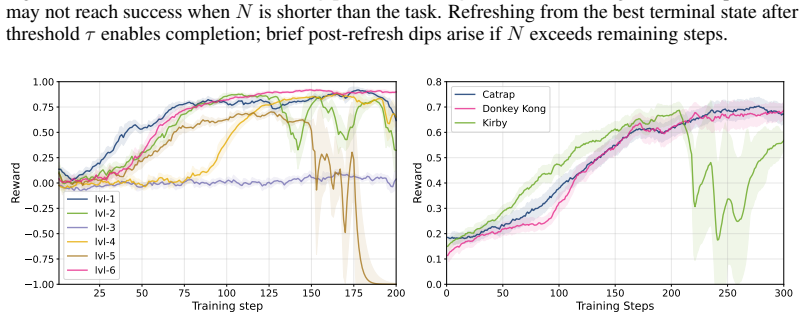
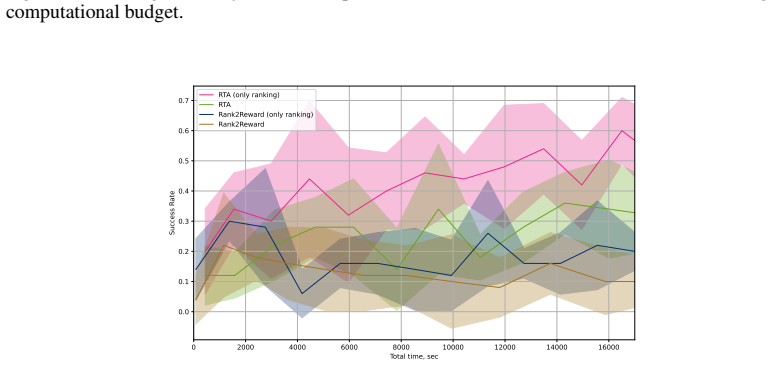
Training a vision-language model with Group Relative Policy Optimization over shuffled frame sequences creates an ordinal progress scorer; feeding the Spearman rank correlation between its predictions and true frame times into reinforcement learning then yields effective policies from video demonstrations without environment rewards, matching or exceeding prior video-based methods on PyBoy, PointMaze, and MetaWorld while enabling cross-task reuse of one scorer.
What carries the argument
The Spearman rank correlation between the VLM's predicted progress rankings and the true temporal indices of frames inside each interaction window, used as the reward signal.
If this is right
- Policies can be trained without access to or design of any environment reward function.
- One progress scorer pretrained on videos transfers to new tasks and environments without retraining.
- The correlation reward remains bounded and scale-invariant, avoiding calibration issues common in direct score-based rewards.
- The same framework applies to both discrete control benchmarks and continuous control tasks with comparable or better results than earlier video reward methods.
Where Pith is reading between the lines
- Similar ordinal video supervision could extend to sequential problems outside robotic control where reward specification is costly.
- Testing the progress scorer on videos recorded under varied lighting or camera motion would reveal how much the method depends on clean visual semantics.
- The approach might combine with other forms of weak supervision such as language instructions to further reduce demonstration requirements.
Load-bearing premise
The Group Relative Policy Optimization objective on shuffled sequences forces the vision-language model to recover temporal order from visual semantics rather than from any trivial time cues in the frames.
What would settle it
A controlled test in which the VLM achieves high accuracy on ordering shuffled held-out sequences yet the resulting correlation-based rewards produce no policy improvement during reinforcement learning, or in which replacing visual frames with time-stamped but visually identical frames still yields high GRPO performance.
Figures

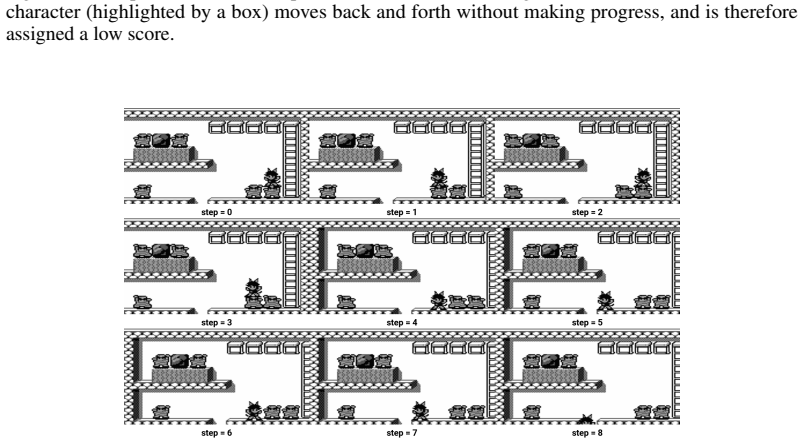

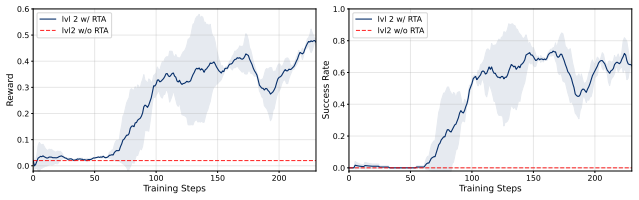
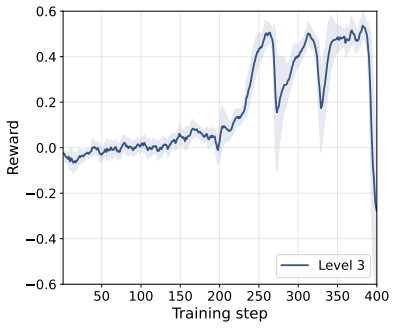
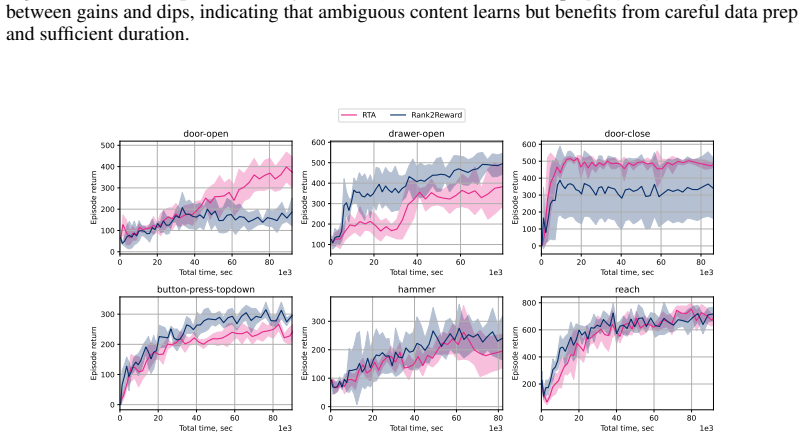
read the original abstract
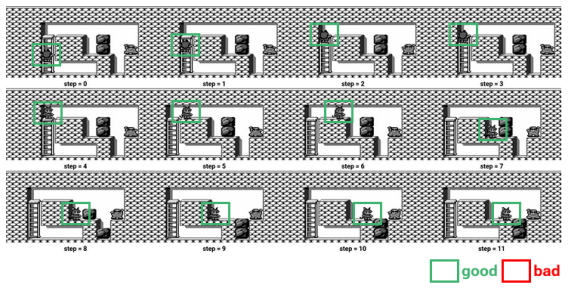
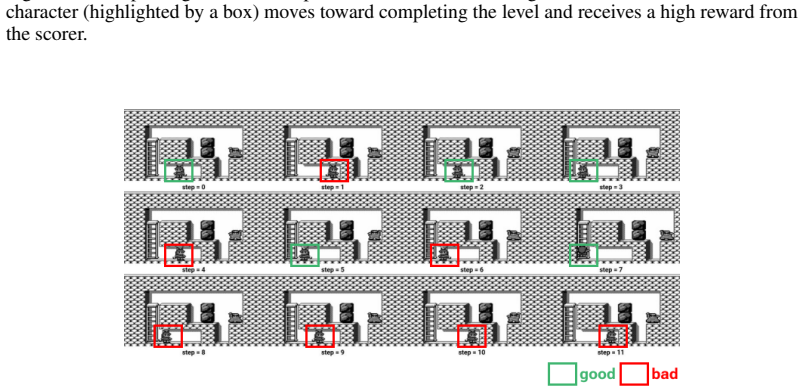
We introduce Rank-Then-Act (RTA), a framework for learning control policies from expert video demonstrations without environment rewards. RTA trains a Vision-Language Model (VLM) offline as a progress-based ordinal scorer, using a Group Relative Policy Optimization (GRPO) objective over shuffled frame sequences, which forces the model to recover temporal ordering from visual semantics rather than trivial time cues. Importantly, instead of using the scorer directly as a scalar reward model, we propose a correlation-based reward function for reinforcement learning: at each interaction window, we compute the Spearman rank correlation between predicted progress rankings and true temporal indices, yielding a bounded, scale-invariant learning signal. This design decouples reward learning from absolute calibration and enables stable transfer across tasks and environments. We evaluate RTA on discrete control benchmarks (PyBoy: Catrap, Kirby) and continuous control tasks (PointMaze, MetaWorld). RTA consistently matches or outperforms prior video-based reward learning methods and rank-based baselines, while demonstrating strong cross-task reuse of a single pretrained progress scorer. Our results suggest that correlation-structured supervision over video-derived ordinal signals is sufficient for policy learning, offering a scalable alternative to explicit reward design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Rank-Then-Act (RTA), a reward-free framework for learning control policies from expert video demonstrations. A VLM is trained offline via Group Relative Policy Optimization (GRPO) on shuffled frame sequences to produce a progress-based ordinal scorer. This scorer is not used directly as a reward; instead, at each interaction window the Spearman rank correlation between the predicted progress rankings and the true temporal indices supplies a bounded, scale-invariant reward signal for RL. The method is evaluated on discrete control benchmarks (PyBoy: Catrap, Kirby) and continuous control tasks (PointMaze, MetaWorld), with claims of consistent outperformance over prior video-based reward learning methods and rank-based baselines, plus strong cross-task reuse of a single pretrained scorer.
Significance. If the central claim holds, the work demonstrates that correlation-structured supervision derived from video-derived ordinal signals can suffice for policy learning, providing a scalable alternative to explicit reward design. The decoupling of reward learning from absolute calibration via Spearman correlation is a potentially useful design choice for transfer.
major comments (2)
- [Abstract] Abstract: the claim that GRPO over shuffled frame sequences 'forces the model to recover temporal ordering from visual semantics rather than trivial time cues' is load-bearing for the transferability of the correlation reward, yet no mechanism is described that would provably eliminate consistent low-level signals (e.g., frame compression patterns, lighting gradients, or motion blur statistics) that survive shuffling. If such cues remain, high GRPO scores can be achieved without learning transferable ordinal semantics.
- [Abstract] Abstract: the assertion of 'consistent outperformance' on the listed benchmarks supplies no quantitative results, error bars, ablation details, or verification of the central claim, rendering the empirical support unassessable from the provided text.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. We respond to each major comment below and indicate where revisions will be made.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that GRPO over shuffled frame sequences 'forces the model to recover temporal ordering from visual semantics rather than trivial time cues' is load-bearing for the transferability of the correlation reward, yet no mechanism is described that would provably eliminate consistent low-level signals (e.g., frame compression patterns, lighting gradients, or motion blur statistics) that survive shuffling. If such cues remain, high GRPO scores can be achieved without learning transferable ordinal semantics.
Authors: We acknowledge the validity of this observation. The abstract phrasing asserts a stronger guarantee than the GRPO objective and shuffling procedure can formally deliver, as low-level persistent cues are not provably ruled out. We will revise the abstract to use more cautious language (e.g., 'encourages the model to recover temporal ordering primarily from visual semantics') and will add a short paragraph in the discussion or limitations section noting this possibility while pointing to the observed cross-task transfer as empirical evidence of practical utility. No additional experiments are feasible within the revision timeline. revision: partial
-
Referee: [Abstract] Abstract: the assertion of 'consistent outperformance' on the listed benchmarks supplies no quantitative results, error bars, ablation details, or verification of the central claim, rendering the empirical support unassessable from the provided text.
Authors: The abstract is intentionally concise; all quantitative results (means, standard deviations across seeds, and ablations) appear in the experimental section, tables, and figures of the full manuscript. To improve standalone readability we will revise the abstract to include one or two key quantitative highlights (e.g., average improvement margins) subject to length limits. revision: yes
Circularity Check
No significant circularity; derivation uses external ground-truth indices and offline GRPO training on separate expert videos
full rationale
The paper trains a VLM progress scorer offline via GRPO on shuffled expert video frames, then defines the RL reward as Spearman correlation between the scorer's output ranks and the true temporal indices of the agent's current interaction window. The true indices are external to the model and supplied by the environment interaction log; the scorer parameters are fitted on a disjoint set of demonstration sequences. No equation reduces a claimed prediction to its own fitted values by construction, no self-citation chain is invoked to justify uniqueness or an ansatz, and the correlation reward is not a renaming of the training objective. The central claim therefore rests on the empirical transfer properties of the learned scorer rather than on definitional equivalence.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The VLM can be trained to recover temporal order from visual semantics using GRPO on shuffled sequences
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang 0028, Shijie Wang 0007, Jun Tang 0008, Humen Zhong, Yuanzhi Zhu, Ming-Hsuan Yang 0001, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang 0003, Haiyang Xu 0001, and Junyang Li...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923 2025
-
[2]
George Bredis, Stanislav Dereka, Viacheslav Sinii, Ruslan Rakhimov, and Daniil Gavrilov. Enhancing vision-language model training with reinforcement learning in synthetic worlds for real-world success.CoRR, abs/2508.04280, 2025. doi: 10.48550/arxiv.2508.04280. URL https://doi.org/10.48550/arxiv.2508.04280
-
[3]
Brown, Wonjoon Goo, Prabhat Nagarajan, and Scott Niekum
Daniel S. Brown, Wonjoon Goo, Prabhat Nagarajan, and Scott Niekum. Extrapolating beyond suboptimal demonstrations via inverse reinforcement learning from observations.ICML, pages 783–792, 2019. URLhttp://proceedings.mlr.press/v97/brown19a.html
2019
-
[4]
Brown, Wonjoon Goo, and Scott Niekum
Daniel S. Brown, Wonjoon Goo, and Scott Niekum. Better-than-demonstrator imitation learning via automatically-ranked demonstrations.CoRL, pages 330–359, 2019. URL http://procee dings.mlr.press/v100/brown20a.html
2019
-
[5]
On the statistical efficiency of reward-free exploration in non-linear rl
Jinglin Chen, Aditya Modi, Akshay Krishnamurthy, Nan Jiang, and Alekh Agarwal. On the statistical efficiency of reward-free exploration in non-linear rl. In S. Koyejo, S. Mo- hamed, A. Agarwal, D. Belgrave, K. Cho, and A. Oh, editors,Advances in Neural Information Processing Systems, volume 35, pages 20960–20973. Curran Associates, Inc., 2022. URL https:/...
2022
-
[6]
Offline reinforcement learning for llm multi-step reasoning
Kevin Chen, Marco F. Cusumano-Towner, Brody Huval, Aleksei Petrenko, Jackson Hamburger, Vladlen Koltun, and Philipp Kr¨ahenb¨uhl. Reinforcement learning for long-horizon interactive llm agents.CoRR, abs/2502.01600, 2025. doi: 10.48550/arxiv.2502.01600. URL https: //doi.org/10.48550/arxiv.2502.01600
-
[7]
Gymnasium robotics, 2024
Rodrigo de Lazcano, Kallinteris Andreas, Jun Jet Tai, Seungjae Ryan Lee, and Jordan Terry. Gymnasium robotics, 2024. URL http://github.com/Farama-Foundation/Gymnasiu m-Robotics
2024
-
[8]
A new era of intelligence with gemini 3., 2025
Google. A new era of intelligence with gemini 3., 2025. URL https://deepmind.google/ models/gemini/pro/
2025
-
[9]
Zee- shan Zia, and Quoc-Huy Tran
Sanjay Haresh, Sateesh Kumar, Huseyin Coskun, Shahram Najam Syed, Andrey Konin, M. Zee- shan Zia, and Quoc-Huy Tran. Learning by aligning videos in time.CVPR, pages 5548–5558, June 2021. doi: 10.1109/cvpr46437.2021.00550. URL https://doi.org/10.1109/cvpr46 437.2021.00550
-
[10]
Generative adversarial imitation learning
Jonathan Ho and Stefano Ermon. Generative adversarial imitation learning. InProceedings of the 30th International Conference on Neural Information Processing Systems, NIPS’16, page 4572–4580, Red Hook, NY , USA, 2016. Curran Associates Inc. ISBN 9781510838819
2016
-
[11]
LoRA: Low-rank adaptation of large language models
Edward J Hu, yelong shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. In International Conference on Learning Representations, 2022. URL https://openreview.n et/forum?id=nZeVKeeFYf9
2022
-
[12]
Imitation learning from a single temporally misaligned video
William Huey, Huaxiaoyue Wang, Anne Wu, Yoav Artzi, and Sanjiban Choudhury. Imitation learning from a single temporally misaligned video. InForty-second International Conference on Machine Learning, 2025. URLhttps://openreview.net/forum?id=YV05KZt7v2
2025
-
[13]
Kuo-Han Hung, Pang-Chi Lo, Jia-Fong Yeh, Han-Yuan Hsu, Yi-Ting Chen, and Winston H. Hsu. Victor: Learning hierarchical vision-instruction correlation rewards for long-horizon manipulation.CoRR, abs/2405.16545, 2024. doi: 10.48550/arxiv.2405.16545. URL https://doi.org/10.48550/arxiv.2405.16545. 10
-
[14]
Reward-free exploration for reinforcement learning
Chi Jin, Akshay Krishnamurthy, Max Simchowitz, and Tiancheng Yu. Reward-free exploration for reinforcement learning. In Hal Daum ´e III and Aarti Singh, editors,Proceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 4870–4879. PMLR, 13–18 Jul 2020. URL https://proceedings. mlr.pre...
2020
-
[15]
Adaptive reward-free exploration
Emilie Kaufmann, Pierre M ´enard, Omar Darwiche Domingues, Anders Jonsson, Edouard Leurent, and Michal Valko. Adaptive reward-free exploration. In Vitaly Feldman, Katrina Ligett, and Sivan Sabato, editors,Proceedings of the 32nd International Conference on Algorithmic Learning Theory, volume 132 ofProceedings of Machine Learning Research, pages 865–891. P...
2021
-
[16]
Vision language models are in-context value learners
Yecheng Jason Ma, Joey Hejna, Chuyuan Fu, Dhruv Shah, Jacky Liang, Zhuo Xu, Sean Kirmani, Peng Xu, Danny Driess, Ted Xiao, Osbert Bastani, Dinesh Jayaraman, Wenhao Yu, Tingnan Zhang, Dorsa Sadigh, and Fei Xia. Vision language models are in-context value learners. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://open...
2025
-
[17]
Zentner, Ryan Julian, J K Terry, Isaac Woungang, Nariman Farsad, and Pablo Samuel Castro
Reginald McLean, Evangelos Chatzaroulas, Luc McCutcheon, Frank R ¨oder, Tianhe Yu, Zhan- peng He, K.R. Zentner, Ryan Julian, J K Terry, Isaac Woungang, Nariman Farsad, and Pablo Samuel Castro. Meta-world+: An improved, standardized, RL benchmark. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Bench- marks Track,...
2025
-
[18]
Efros, and Trevor Darrell
Deepak Pathak, Pulkit Agrawal, Alexei A. Efros, and Trevor Darrell. Curiosity-driven explo- ration by self-supervised prediction. InProceedings of the 34th International Conference on Machine Learning - Volume 70, ICML’17, page 2778–2787. JMLR.org, 2017
2017
-
[19]
Vision- language models are zero-shot reward models for reinforcement learning
Juan Rocamonde, Victoriano Montesinos, Elvis Nava, Ethan Perez, and David Lindner. Vision- language models are zero-shot reward models for reinforcement learning. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.n et/forum?id=N0I2RtD8je
2024
-
[20]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.CoRR, abs/1707.06347, 2017. URL http://dblp.uni-tri er.de/db/journals/corr/corr1707.html#SchulmanWDRK17
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[22]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.CoRR, abs/2402.03300, 2024. doi: 10.48550/arxiv.2402.03300. URL https://doi.org/10.48550/arxiv.2402.03300
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2402.03300 2024
-
[23]
Coin: A large-scale dataset for comprehensive instructional video analysis
Yansong Tang, Dajun Ding, Yongming Rao, Yu Zheng, Danyang Zhang, Lili Zhao, Jiwen Lu, and Jie Zhou. Coin: A large-scale dataset for comprehensive instructional video analysis. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2019
2019
-
[24]
Generative adversarial imitation from observa- tion
Faraz Torabi, Garrett Warnell, and Peter Stone. Generative adversarial imitation from observa- tion. InImitation, Intent, and Interaction (I3) Workshop at ICML 2019, June 2019
2019
-
[25]
Time your rewards: Learning temporally consistent rewards from a single video demonstration
Huaxiaoyue Wang, William Huey, Anne Wu, Yoav Artzi, and Sanjiban Choudhury. Time your rewards: Learning temporally consistent rewards from a single video demonstration. In CoRL 2024 Workshop on Whole-body Control and Bimanual Manipulation: Applications in Humanoids and Beyond, 2024. URLhttps://openreview.net/forum?id=gsgkiuv9BS
2024
-
[26]
Rank2reward: Learning shaped reward functions from passive video.ICRA, 2024
Daniel Yang, Davin Tjia, Jacob Berg, Dima Damen, Pulkit Agrawal, and Abhishek Gupta. Rank2reward: Learning shaped reward functions from passive video.ICRA, 2024. 11
2024
-
[27]
Mastering visual continuous control: Improved data-augmented reinforcement learning, 2021
Denis Yarats, Rob Fergus, Alessandro Lazaric, and Lerrel Pinto. Mastering visual continuous control: Improved data-augmented reinforcement learning, 2021. URL https://arxiv.org/ abs/2107.09645
-
[28]
Xirl: Cross-embodiment inverse reinforcement learning.Conference on Robot Learning (CoRL), 2021
Kevin Zakka, Andy Zeng, Pete Florence, Jonathan Tompson, Jeannette Bohg, and Debidatta Dwibedi. Xirl: Cross-embodiment inverse reinforcement learning.Conference on Robot Learning (CoRL), 2021
2021
-
[29]
Shaopeng Zhai, Qi Zhang, Tianyi Zhang, Fuxian Huang, Haoran Zhang, Ming Zhou, Shengzhe Zhang, Litao Liu, Sixu Lin, and Jiangmiao Pang. A vision-language-action-critic model for robotic real-world reinforcement learning.CoRR, abs/2509.15937, 2025. doi: 10.48550/arxiv.2 509.15937. URLhttps://doi.org/10.48550/arxiv.2509.15937
-
[30]
Yuexiang Zhai, Hao Bai, Zipeng Lin, Jiayi Pan 0002, Shengbang Tong, Yifei Zhou, Alane Suhr, Saining Xie, Yann LeCun, Yi Ma 0001, and Sergey Levine. Fine-tuning large vision-language models as decision-making agents via reinforcement learning.CoRR, abs/2405.10292, 2024. doi: 10.48550/arxiv.2405.10292. URLhttps://doi.org/10.48550/arxiv.2405.10292
-
[31]
VideoGameBench: Can Vision-Language Models complete popular video games?
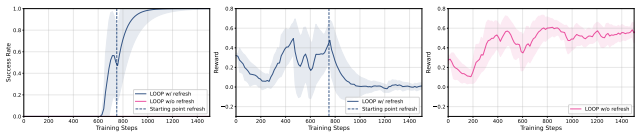
Alex L. Zhang, Thomas L. Griffiths, Karthik R. Narasimhan, and Ofir Press. Videogamebench: Can vision-language models complete popular video games?, 2025. URL https://arxiv.or g/abs/2505.18134. 12 0 200 400 600 800 1000 1200 1400 Training Steps 0.0 0.2 0.4 0.6 0.8 1.0Success Rate LOOP w/ refresh LOOP w/o refresh Starting point refresh 0 200 400 600 800 10...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.