DocAtlas: Multilingual Document Understanding Across 80+ Languages
Pith reviewed 2026-05-22 09:47 UTC · model grok-4.3
The pith
Direct Preference Optimization using rendering-derived annotations adapts document models to 82 languages with accuracy gains and no base-language degradation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
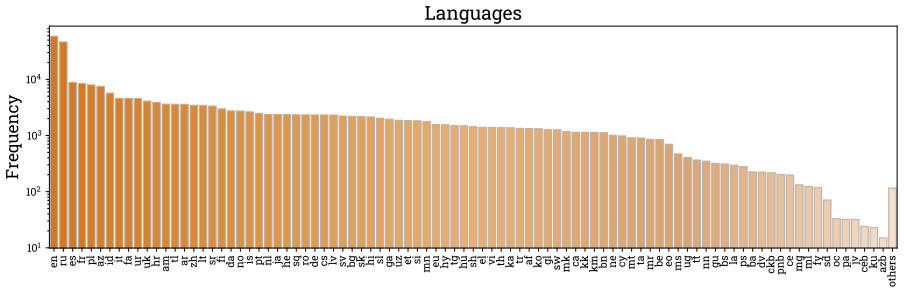
DocAtlas constructs OCR datasets and benchmarks across 82 languages and 9 tasks via dual pipelines of differential rendering from native DOCX files and synthetic LaTeX generation for right-to-left scripts, yielding unified DocTag annotations for layout, text, and component types without learned models. Direct Preference Optimization that treats these rendering-derived labels as the positive signal achieves stable adaptation, producing +1.9% in-domain and +1.8% out-of-domain accuracy improvements with no measurable degradation on base languages, whereas supervised fine-tuning degrades out-of-domain performance by up to 21%. The best resulting model improves 1.7% over the strongest baseline.
What carries the argument
Dual rendering pipelines that generate precise structural annotations in DocTag format from native and synthetic documents, used as reliable positive signals in Direct Preference Optimization for multilingual adaptation.
If this is right
- Multilingual adaptation improves accuracy both inside and outside the training distribution.
- Base-language performance remains unchanged after adaptation.
- The method avoids the large out-of-domain drops produced by supervised fine-tuning.
- The resulting models outperform prior state-of-the-art baselines on the new benchmarks.
Where Pith is reading between the lines
- The same rendering-plus-DPO pipeline could be tested on additional document formats such as PDF or HTML to broaden coverage.
- The approach may support iterative improvement by feeding model outputs back into the rendering loop for self-refinement.
- Similar preference signals derived from rendering could be explored for other layout-sensitive tasks like table extraction or form understanding.
Load-bearing premise
Differential rendering of native documents and synthetic LaTeX generation produce precise structural annotations that serve as reliable ground truth for DPO without introducing systematic errors in layout or component typing.
What would settle it
A test set of additional low-resource languages where the DPO-adapted model shows out-of-domain degradation comparable to supervised fine-tuning would falsify the stability claim.
Figures













read the original abstract
Multilingual document understanding remains limited for low-resource languages due to scarce training data and model-based annotation pipelines that perpetuate existing biases. We introduce DocAtlas, a framework that constructs high-fidelity OCR datasets and benchmarks covering 82 languages and 9 evaluation tasks. Our dual pipelines, differential rendering of native DOCX documents and synthetic LaTeX-based generation for right-to-left scripts produce precise structural annotations in a unified DocTag format encoding layout, text, and component types, without learned models for core annotation. Evaluating 16 state-of-the-art models reveals persistent gaps in low-resource scripts. We show that Direct Preference Optimization (DPO) using rendering-derived ground truth as positive signal achieves stable multilingual adaptation, improving both in-domain (+1.9%) and out-of-domain (+1.8%) accuracy without measurable base-language degradation, where supervised fine-tuning degrades out-of-domain performance by up to 21%. Our best variant, DocAtlas-DeepSeek, improves +1.7% over the strongest baseline. Code is available at https://github.com/ahmedheakl/DocAtlas .
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DocAtlas, a framework for constructing high-fidelity OCR datasets and benchmarks covering 82 languages and 9 evaluation tasks. It employs dual annotation pipelines—differential rendering of native DOCX documents and synthetic LaTeX generation for right-to-left scripts—to produce structural annotations in a unified DocTag format encoding layout, text, and component types without learned models. Evaluation of 16 state-of-the-art models reveals persistent gaps in low-resource scripts. The central empirical result is that Direct Preference Optimization (DPO) using rendering-derived ground truth as the positive signal yields stable multilingual adaptation, with +1.9% in-domain and +1.8% out-of-domain accuracy gains and no measurable base-language degradation, while supervised fine-tuning degrades out-of-domain performance by up to 21%. The best variant (DocAtlas-DeepSeek) improves +1.7% over the strongest baseline. Code is released at the provided GitHub link.
Significance. If the annotation pipeline produces unbiased ground truth, the work provides a scalable, model-free method for creating multilingual document datasets that could reduce annotation biases in low-resource languages. The contrast between DPO's stable adaptation and SFT's degradation is a potentially useful empirical finding for multilingual fine-tuning strategies. Releasing code supports reproducibility, though the absence of statistical details limits immediate impact assessment.
major comments (2)
- [Abstract / Results] Abstract and results section: the headline DPO improvements (+1.9% in-domain, +1.8% OOD) and the claim of 'no measurable base-language degradation' are reported without error bars, statistical significance tests, details on data splits, or exhaustive baseline comparisons. This weakens the central adaptation claim, as the reported gains rest on limited visible evidence and could be sensitive to evaluation choices.
- [Annotation Pipelines] Annotation pipeline description: the assertion that differential DOCX rendering and synthetic LaTeX 'produce precise structural annotations' in DocTag format without introducing systematic errors is load-bearing for the DPO positive-signal construction. No error-rate quantification, human validation of annotations, or analysis of failure modes for low-resource/RTL scripts is referenced, leaving open the possibility that DPO gains reflect annotation artifacts rather than genuine adaptation.
minor comments (2)
- [Methods] Clarify the exact definition and schema of the DocTag format (e.g., how component types and layout elements are encoded) to aid reproducibility.
- [Experiments] The evaluation of 16 models would benefit from an explicit table listing all baselines, their training regimes, and per-language or per-task breakdowns rather than aggregate percentages.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We have carefully considered the major comments and provide point-by-point responses below. Where appropriate, we will revise the manuscript to incorporate additional details and validations as suggested.
read point-by-point responses
-
Referee: Abstract and results section: the headline DPO improvements (+1.9% in-domain, +1.8% OOD) and the claim of 'no measurable base-language degradation' are reported without error bars, statistical significance tests, details on data splits, or exhaustive baseline comparisons. This weakens the central adaptation claim, as the reported gains rest on limited visible evidence and could be sensitive to evaluation choices.
Authors: We agree with the referee that the central empirical claims would benefit from greater statistical transparency. In the revised manuscript, we will add error bars derived from repeated evaluations across different random seeds for the reported accuracy gains. We will also include results from statistical significance testing (such as McNemar's test or paired t-tests where applicable) to evaluate the improvements. Furthermore, we will provide detailed descriptions of the data splits used for in-domain and out-of-domain assessments and include additional baseline models and ablation studies to make the comparisons more exhaustive. These changes will address the concern regarding the robustness of the adaptation results. revision: yes
-
Referee: Annotation pipeline description: the assertion that differential DOCX rendering and synthetic LaTeX 'produce precise structural annotations' in DocTag format without introducing systematic errors is load-bearing for the DPO positive-signal construction. No error-rate quantification, human validation of annotations, or analysis of failure modes for low-resource/RTL scripts is referenced, leaving open the possibility that DPO gains reflect annotation artifacts rather than genuine adaptation.
Authors: The annotation pipelines are constructed to be deterministic and free of learned components to minimize bias introduction. Differential rendering from DOCX files directly captures the structural elements, and the LaTeX-based approach for RTL scripts ensures accurate text and layout rendering through standard compilation. Nevertheless, we recognize the value of explicit validation. We will revise the manuscript to include an analysis of annotation quality, featuring error rates computed against human-annotated samples for a diverse set of languages including low-resource and RTL scripts. We will also provide a discussion of potential failure modes and how the pipelines handle them. The open-sourced code will facilitate community verification of these aspects. revision: yes
Circularity Check
No circularity: empirical results rest on external benchmarks and independent rendering pipeline.
full rationale
The manuscript introduces DocAtlas as a data-construction framework using differential DOCX rendering and synthetic LaTeX generation to produce DocTag annotations, then reports empirical accuracy numbers for 16 models plus DPO adaptation. No equations, fitted parameters, or first-principles derivations appear; the reported +1.9 % / +1.8 % gains and the contrast with SFT are direct experimental comparisons against external baselines rather than quantities defined in terms of the same data or self-citations. The ground-truth pipeline is presented as an external, non-learned process, so the central claims do not reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Differential rendering of native DOCX documents produces precise structural annotations without learned models
- domain assumption Synthetic LaTeX generation accurately captures right-to-left script layout and component types
invented entities (1)
-
DocTag format
no independent evidence
Reference graph
Works this paper leans on
-
[1]
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model
General OCR Theory: Towards OCR-2.0 via a Unified End-to-end Model , author=. arXiv preprint arXiv:2409.01704 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
olmOCR: Unlocking Trillions of Tokens in PDFs with Vision Language Models , author=. arXiv preprint arXiv:2502.18443 , year=
-
[3]
arXiv preprint arXiv:2506.05218 , year=
MonkeyOCR: Document Parsing with a Structure-Recognition-Relation Triplet Paradigm , author=. arXiv preprint arXiv:2506.05218 , year=
- [4]
-
[5]
DeepSeek-OCR: Contexts Optical Compression
Deepseek-ocr: Contexts optical compression , author=. arXiv preprint arXiv:2510.18234 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
International Conference on Learning Representations , volume=
Nougat: Neural optical understanding for academic documents , author=. International Conference on Learning Representations , volume=
-
[7]
arXiv preprint arXiv:2408.09869 , year=
Docling technical report , author=. arXiv preprint arXiv:2408.09869 , year=
-
[8]
Granite Docling: A 258M-Parameter Multimodal VLM for Document Understanding , author=
-
[9]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
SmolDocling: An ultra-compact vision-language model for end-to-end multi-modal document conversion , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[10]
Marker: Fast and Accurate PDF to Markdown Converter , author=
-
[11]
MinerU: An Open-Source Solution for Precise Document Content Extraction
MinerU: An Open-Source Solution for Precise Document Content Extraction , author=. arXiv preprint arXiv:2409.18839 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
5: A decoupled vision-language model for efficient high-resolution document parsing , author=
Mineru2. 5: A decoupled vision-language model for efficient high-resolution document parsing , author=. The 64th Annual Meeting of the Association for Computational Linguistics--Industry Track , year=
-
[13]
dots.ocr: Multilingual Document Layout Parsing in a Single Vision-Language Model , author=
-
[14]
Dolphin: Document Image Parsing via Heterogeneous Anchor Prompting , author=. Proceedings of the 65th Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[15]
Nanonets-OCR2: A model for transforming documents into structured markdown with intelligent content recognition and semantic tagging , author=
-
[16]
Mathpix OCR API , author=
-
[17]
Pix2Text: An Open-Source Tool for Recognizing Layouts, Tables, Math Formulas, and Text in Images , author=
-
[18]
OCRFlux: Mastering Complex Layouts and Seamless Page Merging , author=
-
[19]
Unstructured: Open-Source Pre-Processing Tools for Unstructured Data , author=
-
[20]
OpenParse: Visually-Driven Document Parser for LLM Ingestion , author=
-
[21]
PaddleOCR-VL: Boosting Multilingual Document Parsing via a 0.9B Ultra-Compact Vision-Language Model , author=. 2025 , note=
work page 2025
-
[22]
PaddleOCR 3.0 Technical Report
PaddleOCR 3.0 Technical Report , author=. arXiv preprint arXiv:2507.05595 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
Ocean-OCR: Towards General OCR Application via a Vision-Language Model , author=. arXiv preprint arXiv:2501.15558 , year=
-
[24]
arXiv preprint arXiv:2509.01215 , year=
POINTS-Reader: Distillation-Free Adaptation of Vision-Language Models for Document Conversion , author=. arXiv preprint arXiv:2509.01215 , year=
-
[25]
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year=
DocVQA: A Dataset for VQA on Document Images , author=. IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) , year=
-
[26]
2019 International Conference on Document Analysis and Recognition Workshops (ICDARW) , volume=
FUNSD: A Dataset for Form Understanding in Noisy Scanned Documents , author=. 2019 International Conference on Document Analysis and Recognition Workshops (ICDARW) , volume=. 2019 , organization=. doi:10.1109/ICDARW.2019.10029 , note=
-
[27]
2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR) , volume=
ICDAR2017 Robust Reading Challenge on Multi-Lingual Scene Text Detection and Script Identification - RRC-MLT , author=. 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR) , volume=. 2017 , organization=
work page 2017
-
[28]
Findings of the Association for Computational Linguistics: ACL 2022 , pages=
XFUND: A Benchmark Dataset for Multilingual Visually Rich Form Understanding , author=. Findings of the Association for Computational Linguistics: ACL 2022 , pages=. 2022 , doi=
work page 2022
-
[29]
2019 International Conference on Document Analysis and Recognition (ICDAR) , pages=
PubLayNet: Largest Dataset Ever for Document Layout Analysis , author=. 2019 International Conference on Document Analysis and Recognition (ICDAR) , pages=. 2019 , organization=. doi:10.1109/ICDAR.2019.00166 , note=
-
[30]
arXiv preprint arXiv:2206.01062 , year=
DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis , author=. arXiv preprint arXiv:2206.01062 , year=
-
[31]
OCRBench: On the Hidden Mystery of OCR in Large Multimodal Models
OCRBench: On the Hidden Mystery of OCR in Large Multimodal Models , author=. arXiv preprint arXiv:2305.07895 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
ICDAR 2019 Robust Reading Challenge on Multi-Lingual Scene Text Detection and Recognition - RRC-MLT-2019 , author=. arXiv preprint arXiv:1907.00945 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2019
-
[33]
LayoutLM: Pre-training of Text and Layout for Document Image Understanding , author=. Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining , pages=. 2020 , doi=
work page 2020
-
[34]
arXiv preprint arXiv:2012.14740 , year=
LayoutLMv2: Multi-modal Pre-training for Visually-Rich Document Understanding , author=. arXiv preprint arXiv:2012.14740 , year=
-
[35]
LayoutParser: A Unified Toolkit for Deep Learning Based Document Image Analysis , author=. Document Analysis and Recognition--ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 5--10, 2021, Proceedings, Part I 16 , pages=. 2021 , organization=. doi:10.1007/978-3-030-86549-8_9 , note=
-
[36]
arXiv preprint arXiv:2103.15992 , year=
A Multiplexed Network for End-to-End, Multilingual OCR , author=. arXiv preprint arXiv:2103.15992 , year=
-
[37]
arXiv preprint arXiv:2410.16153 , year=
Pangea: A Fully Open Multilingual Multimodal LLM for 39 Languages , author=. arXiv preprint arXiv:2410.16153 , year=
-
[38]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
TrOCR: Transformer-based Optical Character Recognition with Pre-trained Models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=. 2023 , note=
work page 2023
-
[39]
arXiv preprint arXiv:2104.08836 , year=
LayoutXLM: Multimodal Pre-training for Multilingual Visually-Rich Document Understanding , author=. arXiv preprint arXiv:2104.08836 , year=
-
[40]
arXiv preprint arXiv:2412.17787 , year=
Cross-Lingual Text-Rich Visual Comprehension: An Information Theory Perspective , author=. arXiv preprint arXiv:2412.17787 , year=
-
[41]
SynthTIGER: Synthetic Text Image GEneratoR Towards Better Text Recognition Models , author=. Document Analysis and Recognition--ICDAR 2021: 16th International Conference, Lausanne, Switzerland, September 5--10, 2021, Proceedings, Part III 16 , pages=. 2021 , organization=. doi:10.1007/978-3-030-86337-1_8 , note=
-
[42]
A Synthetic Recipe for OCR , author=. ICASSP 2020 - 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) , pages=. 2020 , organization=
work page 2020
-
[43]
arXiv preprint arXiv:2103.08236 , year=
Generating Synthetic Handwritten Historical Documents With OCR Constrained GANs , author=. arXiv preprint arXiv:2103.08236 , year=
-
[44]
DocCreator: A New Software for Creating Synthetic Ground-Truthed Document Images , author=. Journal of Imaging , volume=. 2017 , publisher=
work page 2017
-
[45]
TextRecognitionDataGenerator , author=
-
[46]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Omnidocbench: Benchmarking diverse pdf document parsing with comprehensive annotations , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[47]
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[48]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[49]
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
AAAI Conference on Artificial Intelligence , year=
Docling: An Efficient Open-Source Toolkit for AI-driven Document Conversion , author=. AAAI Conference on Artificial Intelligence , year=
-
[51]
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[52]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[53]
Nanonets-OCR-S: A model for transforming documents into structured markdown with intelligent content recognition and semantic tagging , author=
- [54]
-
[55]
European conference on computer vision , pages=
Image-based table recognition: data, model, and evaluation , author=. European conference on computer vision , pages=. 2020 , organization=
work page 2020
-
[56]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Readoc: A unified benchmark for realistic document structured extraction , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[57]
Docbank: A bench- mark dataset for document layout analysis
Docbank: A benchmark dataset for document layout analysis , author=. arXiv preprint arXiv:2006.01038 , year=
-
[58]
arXiv preprint arXiv:2210.05391 , year=
Pp-structurev2: A stronger document analysis system , author=. arXiv preprint arXiv:2210.05391 , year=
-
[59]
European Conference on Computer Vision , pages=
Ocr-free document understanding transformer , author=. European Conference on Computer Vision , pages=. 2022 , organization=
work page 2022
-
[60]
International Conference on Machine Learning , pages=
Pix2struct: Screenshot parsing as pretraining for visual language understanding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[61]
Proceedings of the national academy of sciences , volume=
Overcoming catastrophic forgetting in neural networks , author=. Proceedings of the national academy of sciences , volume=. 2017 , publisher=
work page 2017
- [62]
-
[63]
IEEE Transactions on Audio, Speech and Language Processing , year=
An empirical study of catastrophic forgetting in large language models during continual fine-tuning , author=. IEEE Transactions on Audio, Speech and Language Processing , year=
-
[64]
arXiv preprint arXiv:2507.06761 , year=
Finetuning Vision-Language Models as OCR Systems for Low-Resource Languages: A Case Study of Manchu , author=. arXiv preprint arXiv:2507.06761 , year=
-
[65]
European Conference on Computer Vision , pages=
Task grouping for multilingual text recognition , author=. European Conference on Computer Vision , pages=. 2022 , organization=
work page 2022
-
[66]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Kitab-bench: A comprehensive multi-domain benchmark for arabic ocr and document understanding , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[67]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[68]
How to Teach Large Multimodal Models New Skills
How to Teach Large Multimodal Models New Skills , author=. arXiv preprint arXiv:2510.08564 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [69]
-
[70]
2024 , howpublished =
work page 2024
-
[71]
FastText.zip: Compressing text classification models
Fasttext. zip: Compressing text classification models , author=. arXiv preprint arXiv:1612.03651 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[72]
Proceedings of the 30th ACM international conference on multimedia , pages=
Layoutlmv3: Pre-training for document ai with unified text and image masking , author=. Proceedings of the 30th ACM international conference on multimedia , pages=
-
[73]
Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
CCNet: Extracting high quality monolingual datasets from web crawl data , author=. Proceedings of the Twelfth Language Resources and Evaluation Conference , pages=
-
[74]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Deep residual learning for image recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[75]
IEEE Transactions on Big Data , year=
The faiss library , author=. IEEE Transactions on Big Data , year=
-
[76]
Common Crawl: Data collection and use cases for NLP , author=. HPLT & NLPL Winter School on Large-Scale Language Modeling and Neural Machine Translation with Web Data, February , volume=
-
[77]
Advances in Neural Information Processing Systems , volume=
WordScape: a Pipeline to extract multilingual, visually rich Documents with Layout Annotations from Web Crawl Data , author=. Advances in Neural Information Processing Systems , volume=
-
[78]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
From chaotic ocr words to coherent document: A fine-to-coarse zoom-out network for complex-layout document image translation , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.