The Shape of Wisdom: Decision Trajectories in Language Models
Pith reviewed 2026-06-28 17:16 UTC · model grok-4.3
The pith
Language models reach most correct answers through unstable trajectories across layers rather than stable ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
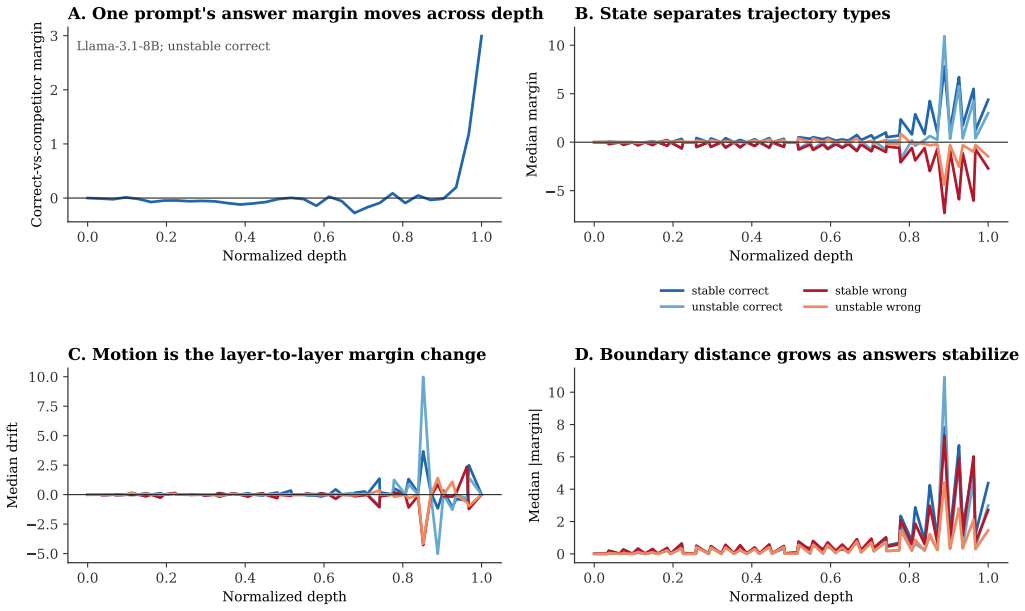
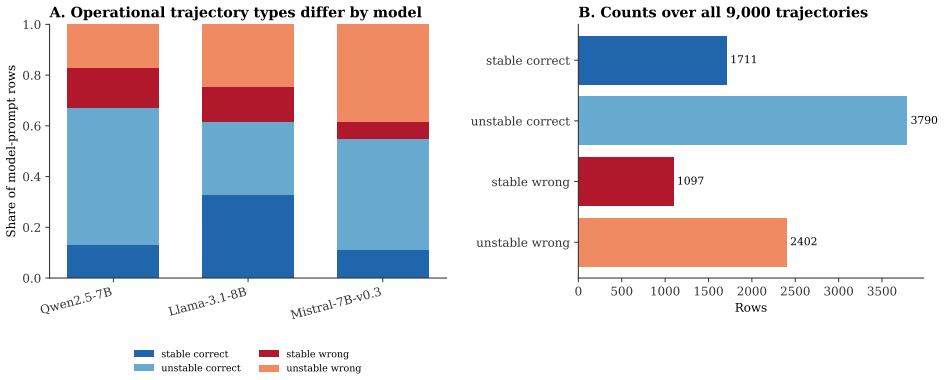
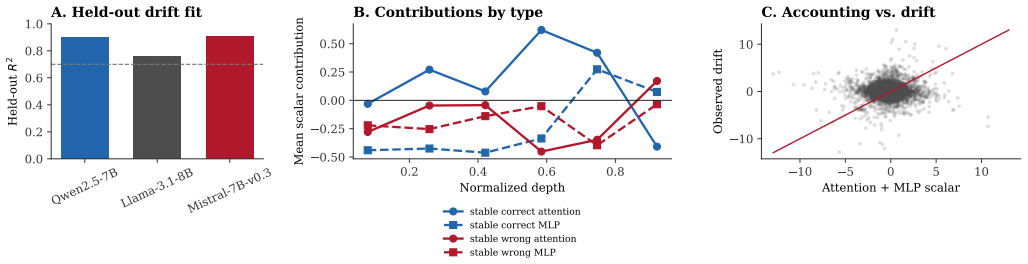
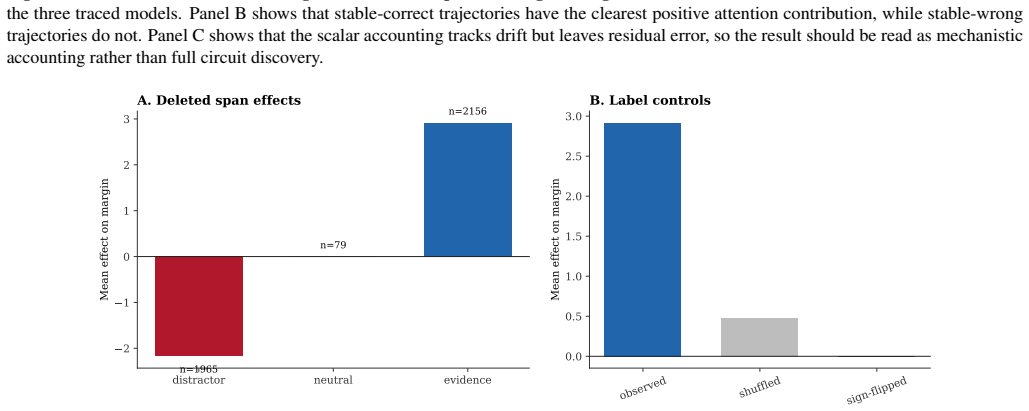
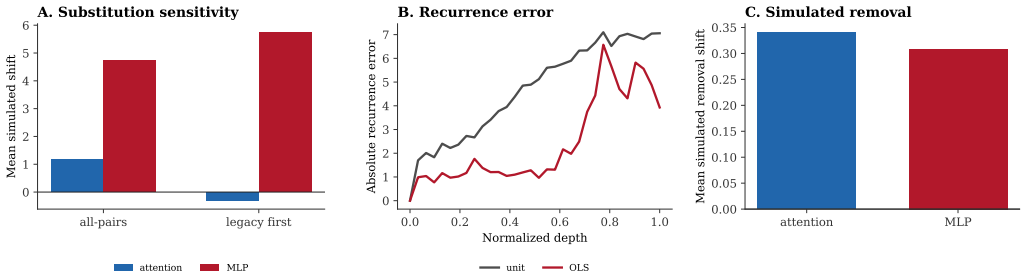
Across 9,000 trajectories in Qwen2.5-7B-Instruct, Llama-3.1-8B-Instruct, and Mistral-7B-Instruct-v0.3 on MMLU, correctness and stability diverge, with unstable-correct being the dominant category. In stable-correct trajectories the average attention scalar aligns with the correct answer while the average MLP scalar does not. Removing answer-supporting spans decreases the margin and removing distractor-like spans increases it. This yields a practical way to classify answers as settled, fragile, or moved by specific sources.
What carries the argument
The three quantities used to describe each decision trajectory: current answer margin, next-layer change in margin, and distance from a decision flip.
If this is right
- Correct answers are frequently not stable across model depth.
- Attention contributes positively to correct margins in stable cases while MLPs do not.
- Text spans supporting the answer increase the margin when present.
- Models can be correct without the decision being firmly settled early in the network.
Where Pith is reading between the lines
- These trajectories might identify cases where the model is relying on shallow patterns rather than deep reasoning.
- Similar tracking could apply to other benchmarks to compare model robustness.
- Targeting attention adjustments might increase the proportion of stable-correct trajectories.
- Layer-wise margin tracking offers a lightweight alternative to full mechanistic interpretability for decision analysis.
Load-bearing premise
The current answer margin, its next-layer change, and the distance to a decision flip together capture the essential dynamics of the model's answer selection process.
What would settle it
A replication study on the same or similar models and dataset that finds the stable-correct group to be the largest or shows no consistent directional difference between attention and MLP scalars in stable cases.
Figures
read the original abstract
Language models do not simply choose an answer at the output layer. In a 9,000-trajectory MMLU study across Qwen2.5-7B-Instruct, Llama-3.1-8B-Instruct, and Mistral-7B-Instruct-v0.3, the score of the answer moves across depth in structured ways. We describe each trajectory with three quantities: the current answer margin, the next-layer change in that margin, and the distance from a decision flip. The main empirical picture is that correctness and stability are different: the largest group is unstable-correct, not stable-correct. A traced subset then asks what moves the margin. In stable-correct cases, the average attention scalar points in the correct direction, while the average MLP scalar does not; span deletion shows that removing answer-supporting text hurts the margin and removing distractor-like text helps it. The result is not a full circuit explanation. It is a reproducible way to see which answers are settled, which remain fragile, and which measured sources move them.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an empirical analysis of 9,000 decision trajectories on MMLU across Qwen2.5-7B-Instruct, Llama-3.1-8B-Instruct, and Mistral-7B-Instruct-v0.3. Each trajectory is summarized by three scalars: current answer margin (final-token logit difference), next-layer change in that margin, and distance to a decision flip. The central finding is that correctness and stability are distinct, with the largest group being unstable-correct rather than stable-correct. In a traced subset of stable-correct cases, average attention scalars align with the correct direction while average MLP scalars do not; span-deletion experiments further show that removing answer-supporting text decreases the margin and removing distractor text increases it.
Significance. If the three-quantity partition is robust, the work supplies a reproducible empirical method for identifying settled versus fragile answers inside language models and for isolating the directional contributions of attention versus MLP layers. This is a modest but concrete step toward trajectory-level interpretability; the absence of a full circuit explanation is explicitly acknowledged.
major comments (2)
- [Trajectory characterization and results sections] The claim that the largest group is unstable-correct rests entirely on partitioning trajectories with the three scalars (current margin, next-layer delta, distance to flip). The manuscript provides no validation that these scalars are sufficient to capture key dynamics; non-monotonic margin trajectories, per-head attention variation, or intermediate-token contributions could produce different classifications. This directly affects both the group-size result and the subsequent attention-vs-MLP comparison.
- [Traced-subset analysis] The attention/MLP directional finding and the span-deletion results are reported only on the subset already classified by the same three-quantity partition. Any misclassification therefore propagates to the mechanistic claims.
minor comments (2)
- [Abstract] The abstract states the headline findings and study size but supplies no numerical values, error bars, exclusion criteria, or verification steps for the reported group sizes or scalar averages.
- [Methods] Notation for the three quantities (margin, next-layer change, flip distance) is introduced without explicit equations or pseudocode, making exact reproduction difficult from the text alone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate where revisions will be made to strengthen the validation of our trajectory partitioning.
read point-by-point responses
-
Referee: [Trajectory characterization and results sections] The claim that the largest group is unstable-correct rests entirely on partitioning trajectories with the three scalars (current margin, next-layer delta, distance to flip). The manuscript provides no validation that these scalars are sufficient to capture key dynamics; non-monotonic margin trajectories, per-head attention variation, or intermediate-token contributions could produce different classifications. This directly affects both the group-size result and the subsequent attention-vs-MLP comparison.
Authors: We acknowledge that the three scalars constitute a simplified partition and that the manuscript does not include explicit checks against non-monotonic margin trajectories, per-head attention variation, or intermediate-token effects. These scalars were selected because they directly quantify the evolution of the answer margin, which is the central object of the stability analysis. In revision we will add a supplementary quantification of non-monotonic trajectories across the 9,000-trajectory corpus and report their effect on the reported group sizes; this constitutes a partial revision because the core empirical picture remains anchored to the proposed scalars. revision: partial
-
Referee: [Traced-subset analysis] The attention/MLP directional finding and the span-deletion results are reported only on the subset already classified by the same three-quantity partition. Any misclassification therefore propagates to the mechanistic claims.
Authors: We agree that the traced-subset analyses inherit any classification limitations of the three-scalar partition. The span-deletion experiments provide an independent probe of directional contributions, but we will revise the text to state explicitly that the attention-versus-MLP and span-deletion results are conditional on the stable-correct classification and to discuss the implications of potential misclassification. This is a partial revision. revision: partial
Circularity Check
No circularity; empirical measurements of defined quantities
full rationale
The paper defines three scalar quantities directly from model logits (current answer margin, next-layer change in margin, distance to decision flip) and uses them to partition observed trajectories into empirical categories such as unstable-correct. No derivations, fitted parameters renamed as predictions, self-citation load-bearing premises, or ansatzes are present. The central claim follows from direct computation on the 9,000-trajectory dataset rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Measuring Massive Multitask Language Understanding , author=. International Conference on Learning Representations , year=
-
[6]
Advances in Neural Information Processing Systems , year=
Locating and Editing Factual Associations in GPT , author=. Advances in Neural Information Processing Systems , year=
-
[7]
International Conference on Learning Representations , year=
Interpretability in the Wild: A Circuit for Indirect Object Identification in GPT-2 Small , author=. International Conference on Learning Representations , year=
-
[8]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year=
Transformer Feed-Forward Layers Build Predictions by Promoting Concepts in the Vocabulary Space , author=. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing , year=
2022
-
[9]
AI at Meta . The llama 3 herd of models. arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Nora Belrose, Zach Furman, Logan Smith, Danny Halawi, Igor Ostrovsky, Lev McKinney, Stella Biderman, and Jacob Steinhardt. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space
Mor Geva, Avi Caciularu, Kevin Ro Wang, and Yoav Goldberg. Transformer feed-forward layers build predictions by promoting concepts in the vocabulary space. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, 2022
2022
-
[12]
Measuring Massive Multitask Language Understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. International Conference on Learning Representations, 2021. arXiv:2009.03300
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[13]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lelio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothee Lacroix, and William El Sayed. Mistral 7b. arXiv preprint arXiv:2...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[14]
Locating and editing factual associations in gpt
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt. In Advances in Neural Information Processing Systems, 2022
2022
-
[15]
Qwen Team . Qwen2.5 technical report. arXiv preprint arXiv:2412.15115, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[16]
Interpretability in the wild: A circuit for indirect object identification in gpt-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: A circuit for indirect object identification in gpt-2 small. In International Conference on Learning Representations, 2023
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.