How Do LLMs Cite? A Mechanistic Interpretation of Attribution in Retrieval-Augmented Generation
Pith reviewed 2026-06-30 11:09 UTC · model grok-4.3
The pith
LLMs rely on a distributed ensemble of attention heads and MLP layers to decide on inline citations in RAG outputs, allowing targeted interventions to correct most citation mistakes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
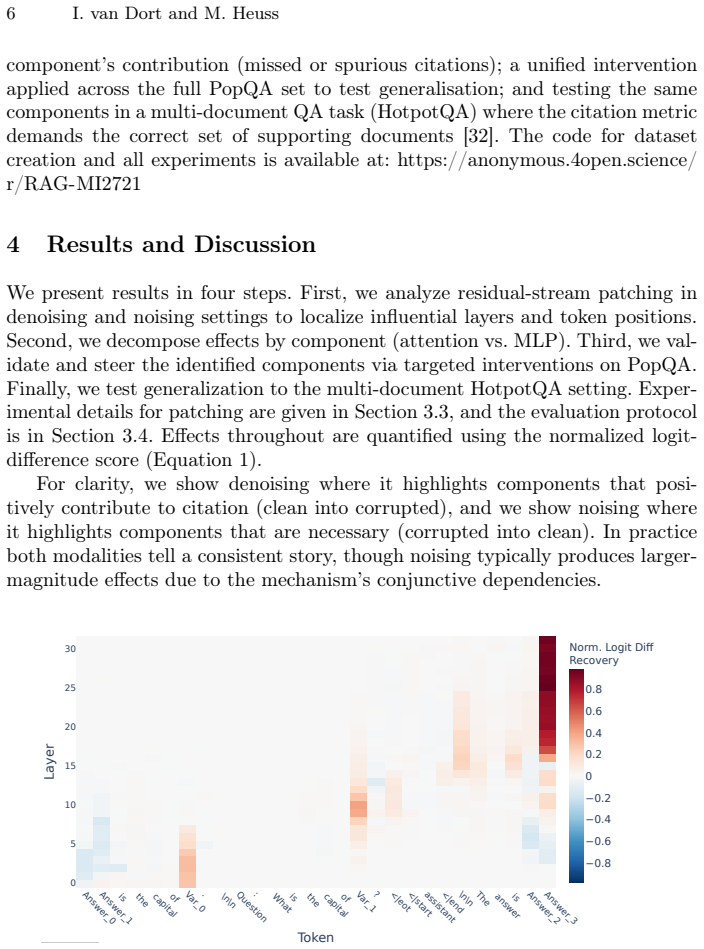
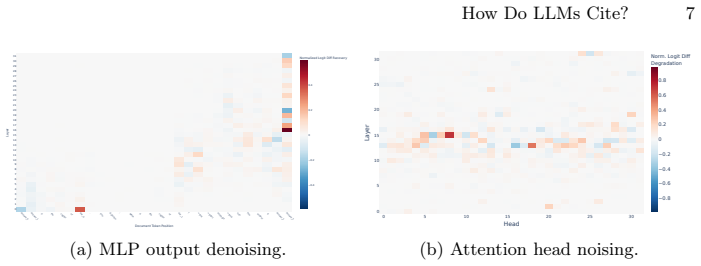
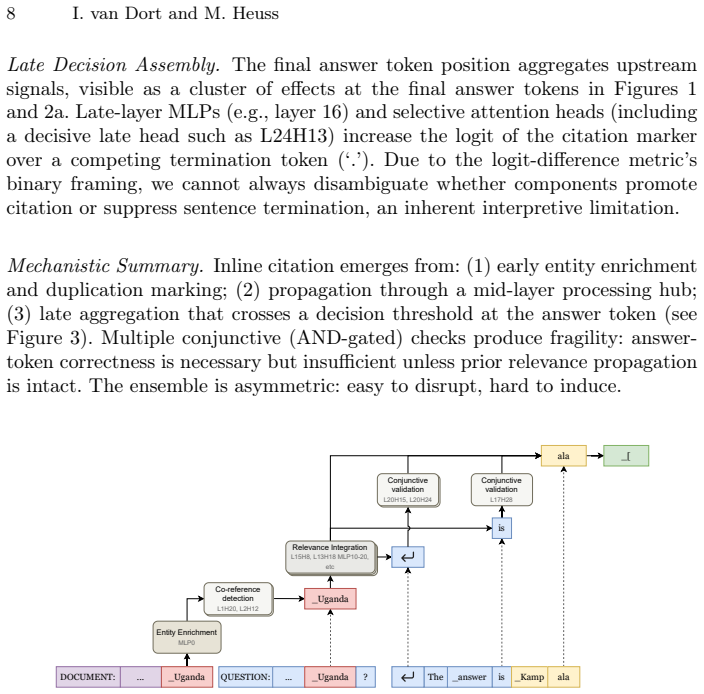
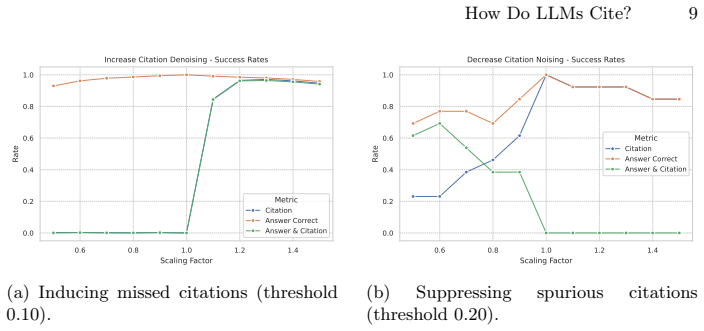
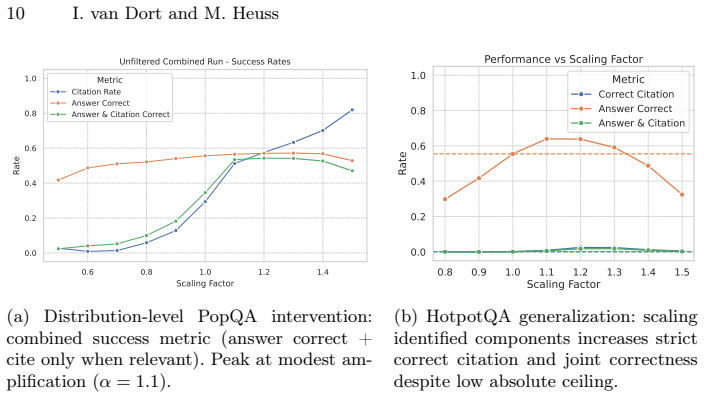
The central claim is that citation attribution in retrieval-augmented generation emerges from a distributed, multi-stage attributional ensemble of attention heads and MLP layers rather than any single localized component. By using activation patching to map this ensemble in Llama-3.1-8B-Instruct on PopQA, the work shows that selectively amplifying or attenuating these components repairs over 90% of missed citations and eliminates 69% of spurious ones without harming answer accuracy, and produces similar directional effects on HotpotQA.
What carries the argument
An attributional ensemble consisting of multiple attention heads and MLP layers that collectively govern the decision to attach an inline citation to an answer.
If this is right
- The mechanism for citation is distributed rather than localized in one part of the model.
- Targeted editing of these components can substantially improve citation faithfulness in RAG systems.
- The same components influence citation behavior across different datasets like PopQA and HotpotQA.
- Apparent citation use may not reflect the model's actual internal attribution process.
Where Pith is reading between the lines
- Post-hoc editing of the ensemble could be used to enhance citation accuracy in deployed models.
- Similar mechanistic approaches might reveal how LLMs handle other forms of attribution or source grounding.
- The disconnect implies that users should not rely solely on inline citations for verifying model outputs.
Load-bearing premise
Activation patching on the identified heads and MLPs directly isolates the causal drivers of citation decisions rather than just changing generation behavior in unrelated ways.
What would settle it
A new experiment where patching the same components on a different model or dataset fails to correct citation errors while leaving answer accuracy unchanged would show that the ensemble is not the general causal mechanism.
Figures
read the original abstract
Retrieval-Augmented Generation (RAG) aims to enhance the trustworthiness of Large Language Models (LLMs) by grounding their outputs in external documents, often using inline citations for verifiability. However, the faithfulness of these citations -- whether the model genuinely uses a source to generate an answer -- remains a critical, unverified assumption. This paper offers the first mechanistic account of how a large language model decides whether to attach an inline citation while answering a factoid question. Using the Llama-3.1-8B-Instruct model in a controlled experimental environment based on the PopQA dataset, we employ an activation patching approach. We map the underlying mechanism responsible for citation, discovering that it is not a single, localized component but a distributed, multi-stage "attributional ensemble" of attention heads and MLP layers. We show that amplifying or attenuating only those critical heads and MLPs repairs over 90% of missed citations and eliminates 69% of spurious ones on PopQA without harming answer accuracy. Although gains on the multi-document HotpotQA benchmark are modest, the same component set still moves citation rates in the intended direction, indicating that the underlying mechanism is not dataset-specific. The results reveal a potential disconnect between the model's apparent reasoning and its internal computational pathway, suggesting that inline citations can create a false sense of security.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to deliver the first mechanistic account of inline citation decisions in RAG by applying activation patching to Llama-3.1-8B-Instruct on PopQA. It identifies a distributed 'attributional ensemble' of attention heads and MLPs whose amplification or attenuation repairs >90% of missed citations and eliminates 69% of spurious ones while preserving answer accuracy; the same components produce directional improvements on HotpotQA, suggesting the mechanism is not dataset-specific and revealing a potential disconnect between surface citations and internal attribution.
Significance. If the interventions isolate attribution computation rather than generic citation formatting, the work would be significant for mechanistic interpretability of RAG faithfulness. It supplies concrete, cross-dataset intervention results on a public model and highlights that citation behavior can be edited without accuracy loss, which could inform targeted reliability improvements. The distributed 'ensemble' finding challenges assumptions of localized citation circuitry.
major comments (3)
- [Abstract, §4] Abstract and §4 (PopQA results): the reported 90% repair and 69% elimination rates are presented without error bars, without the precise head-selection procedure, and without an ablation of the patching protocol itself. These quantities are load-bearing for the central claim yet lack the statistical and methodological detail needed for verification.
- [§3, §5] §3 (activation-patching protocol) and §5 (discussion of mechanism): no experiment holds generated answer content fixed while varying only source-grounding evidence. Preservation of answer accuracy therefore does not rule out effects on a generic 'emit citation token' policy or downstream formatting circuitry rather than on attribution verification.
- [§4.3] §4.3 (HotpotQA transfer): the claim that the component set 'moves citation rates in the intended direction' and is 'not dataset-specific' rests on modest, directional changes without reported effect sizes, statistical tests, or a quantitative comparison to PopQA. This weakens the generalization argument.
minor comments (2)
- [§3] Notation for the 'attributional ensemble' is introduced without a formal definition or pseudocode; a concise algorithmic description would improve reproducibility.
- [Figures 3-5] Figure captions and axis labels in the patching results should explicitly state the number of runs and whether shaded regions represent standard error or standard deviation.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed comments. We address each major comment point by point below, indicating planned revisions to the manuscript where appropriate.
read point-by-point responses
-
Referee: [Abstract, §4] Abstract and §4 (PopQA results): the reported 90% repair and 69% elimination rates are presented without error bars, without the precise head-selection procedure, and without an ablation of the patching protocol itself. These quantities are load-bearing for the central claim yet lack the statistical and methodological detail needed for verification.
Authors: We agree that the reported rates require additional statistical and methodological detail for full verifiability. In the revised manuscript we will add error bars computed across multiple random seeds to the 90% and 69% figures in both the abstract and §4. We will also expand the description of the head- and layer-selection procedure with explicit metrics, thresholds, and selection criteria. Finally, we will include an ablation comparing the full patching protocol against random-component and layer-only baselines. These additions will be incorporated into §4. revision: yes
-
Referee: [§3, §5] §3 (activation-patching protocol) and §5 (discussion of mechanism): no experiment holds generated answer content fixed while varying only source-grounding evidence. Preservation of answer accuracy therefore does not rule out effects on a generic 'emit citation token' policy or downstream formatting circuitry rather than on attribution verification.
Authors: The activation-patching protocol holds the input prompt (question plus retrieved documents) fixed and intervenes only on internal activations of the identified components. This design isolates changes to attribution computation while the evidence remains constant. We will revise §3 to emphasize this isolation and expand §5 to discuss why a fully fixed-answer-content experiment is difficult in autoregressive generation, where citation decisions are entangled with content production. We maintain that the component-specific nature of the interventions supports attribution rather than generic formatting, but we acknowledge the referee's point on the limits of the current controls. revision: partial
-
Referee: [§4.3] §4.3 (HotpotQA transfer): the claim that the component set 'moves citation rates in the intended direction' and is 'not dataset-specific' rests on modest, directional changes without reported effect sizes, statistical tests, or a quantitative comparison to PopQA. This weakens the generalization argument.
Authors: We agree that quantitative details would strengthen the generalization claim. In the revision we will report effect sizes for the observed citation-rate changes on HotpotQA, include statistical tests (e.g., paired t-tests with p-values), and add a direct quantitative comparison (percentage-point deltas and confidence intervals) between the PopQA and HotpotQA results. These additions will appear in §4.3. revision: yes
Circularity Check
No significant circularity; experimental results rely on external benchmarks and interventions
full rationale
The paper reports an activation-patching study on Llama-3.1-8B-Instruct using the external PopQA and HotpotQA benchmarks. Critical heads and MLPs are identified via patching experiments and then intervened upon to measure changes in citation rates while preserving answer accuracy. No equations, self-definitional loops, fitted parameters renamed as predictions, or load-bearing self-citations appear in the abstract or described method. The derivation chain consists of empirical measurements on held-out data rather than any reduction of outputs to the inputs by construction. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Activation patching on attention heads and MLPs isolates the causal pathway for citation decisions rather than downstream generation effects.
invented entities (1)
-
attributional ensemble
no independent evidence
Reference graph
Works this paper leans on
-
[1]
https://doi.org/10.48550/ arXiv.2311.01463, http://arxiv.org/abs/2311.01463, arXiv:2311.01463 [cs]
Ahmad, M.A., Yaramis, I., Roy, T.D.: Creating Trustworthy LLMs: Dealing with Hallucinations in Healthcare AI (Sep 2023). https://doi.org/10.48550/ arXiv.2311.01463, http://arxiv.org/abs/2311.01463, arXiv:2311.01463 [cs]
-
[2]
Bohnet, B., Tran, V.Q., Verga, P., Aharoni, R., Andor, D., Soares, L.B., Ciaramita, M., Eisenstein, J., Ganchev, K., Herzig, J., Hui, K., Kwiatkowski, T., Ma, J., Ni, J., Saralegui, L.S., Schuster, T., Cohen, W.W., Collins, M., Das, D., Metzler, D., Petrov, S., Webster, K.: Attributed Question Answering: Evaluation and Modeling for Attributed Large Lan- g...
-
[3]
Reasoning Models Don't Always Say What They Think
Chen,Y.,Benton,J.,Radhakrishnan,A.,Uesato,J.,Denison,C.,Schulman, J., Somani, A., Hase, P., Wagner, M., Roger, F., Mikulik, V., Bowman, S.R., Leike, J., Kaplan, J., Perez, E.: Reasoning Models Don’t Always Say What They Think (May 2025). https://doi.org/10.48550/arXiv.2505.05410, http://arxiv.org/abs/2505.05410, arXiv:2505.05410 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.05410 2025
-
[4]
https://doi.org/10.48550/ arXiv.2409.00729, http://arxiv.org/abs/2409.00729, arXiv:2409.00729 [cs]
Cohen-Wang, B., Shah, H., Georgiev, K., Madry, A.: ContextCite: Attribut- ing Model Generation to Context (Sep 2024). https://doi.org/10.48550/ arXiv.2409.00729, http://arxiv.org/abs/2409.00729, arXiv:2409.00729 [cs]
-
[5]
Gao,T.,Yen,H.,Yu,J.,Chen,D.:EnablingLargeLanguageModelstoGen- erateTextwithCitations.In:Bouamor,H.,Pino,J.,Bali,K.(eds.)Proceed- ingsofthe2023ConferenceonEmpiricalMethodsinNaturalLanguagePro- cessing. pp. 6465–6488. Association for Computational Linguistics, Singa- pore (Dec 2023). https://doi.org/10.18653/v1/2023.emnlp-main.398, https: //aclanthology.org...
-
[6]
Retrieval-Augmented Generation for Large Language Models: A Survey
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., Dai, Y., Sun, J., Wang, M., Wang, H.: Retrieval-Augmented Generation for Large Language Models: A Survey (Mar 2024). https://doi.org/10.48550/arXiv.2312.10997, http://arxiv.org/abs/2312.10997, arXiv:2312.10997 version: 5
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2312.10997 2024
-
[7]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., Yang, A., Fan, A., Goyal, A., Hartshorn, A., Yang, A., Mitra, A., Sravankumar, A., Korenev, A.,Hinsvark,A.,Rao,A.,Zhang,A.,Rodriguez,A.,Gregerson,A.,Spataru, A., Roziere, B., Biron, B., Tang, B., Chern, B., Caucheteux, C., Nayak...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783 2024
-
[8]
(eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics
Jacovi, A., Goldberg, Y.: Towards Faithfully Interpretable NLP Systems: How Should We Define and Evaluate Faithfulness? In: Jurafsky, D., Chai, J., Schluter, N., Tetreault, J. (eds.) Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. pp. 4198–4205. Association forComputationalLinguistics,Online(Jul2020).https://doi.or...
2020
-
[9]
Learning and individual differences103, 102274 (2023)
Kasneci, E., Seßler, K., Küchemann, S., Bannert, M., Dementieva, D., Fis- cher, F., Gasser, U., Groh, G., Günnemann, S., Hüllermeier, E., et al.: Chat- gpt for good? on opportunities and challenges of large language models for education. Learning and individual differences103, 102274 (2023)
2023
-
[10]
AMIA Annual Symposium Proceedings2006, 469–473 (2006), https://www.ncbi.nlm.nih
Lee, M., Cimino, J., Zhu, H.R., Sable, C., Shanker, V., Ely, J., Yu, H.: Be- yond Information Retrieval—Medical Question Answering. AMIA Annual Symposium Proceedings2006, 469–473 (2006), https://www.ncbi.nlm.nih. 16 I. van Dort and M. Heuss gov/pmc/articles/PMC1839371/
2006
-
[11]
In: Advances in Neural Information Processing Systems
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.t., Rocktäschel, T., Riedel, S., Kiela, D.: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks. In: Advances in Neural Information Processing Systems. vol. 33, pp. 9459–9474. Curran Associates, Inc. (2020), https://proceedings.neurips.cc/ ...
2020
-
[12]
https://doi.org/10.48550/arXiv.2505.16415, http://arxiv.org/ abs/2505.16415, arXiv:2505.16415 [cs]
Li, R., Chen, C., Hu, Y., Gao, Y., Wang, X., Yilmaz, E.: Attribut- ing Response to Context: A Jensen-Shannon Divergence Driven Mecha- nistic Study of Context Attribution in Retrieval-Augmented Generation (May 2025). https://doi.org/10.48550/arXiv.2505.16415, http://arxiv.org/ abs/2505.16415, arXiv:2505.16415 [cs]
-
[13]
https://doi.org/10.48550/arXiv.2304.09848, http:// arxiv.org/abs/2304.09848, arXiv:2304.09848 [cs]
Liu,N.F.,Zhang,T.,Liang,P.:EvaluatingVerifiabilityinGenerativeSearch Engines (Oct 2023). https://doi.org/10.48550/arXiv.2304.09848, http:// arxiv.org/abs/2304.09848, arXiv:2304.09848 [cs]
-
[15]
https://doi.org/10.48550/arXiv.2405.20362, http: //arxiv.org/abs/2405.20362, arXiv:2405.20362 [cs]
Magesh, V., Surani, F., Dahl, M., Suzgun, M., Manning, C.D., Ho, D.E.: Hallucination-Free? Assessing the Reliability of Leading AI Legal Re- search Tools (May 2024). https://doi.org/10.48550/arXiv.2405.20362, http: //arxiv.org/abs/2405.20362, arXiv:2405.20362 [cs]
-
[16]
In: Rogers, A., Boyd- Graber, J., Okazaki, N
Mallen, A., Asai, A., Zhong, V., Das, R., Khashabi, D., Hajishirzi, H.: When Not to Trust Language Models: Investigating Effectiveness of Parametric and Non-Parametric Memories. In: Rogers, A., Boyd- Graber, J., Okazaki, N. (eds.) Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa- pers). pp. 9802–98...
-
[17]
Reuters (Jun 2023), https://www.reuters.com/legal/ new-york-lawyers-sanctioned-using-fake-chatgpt-cases-legal-brief-2023-06-22/
Merken, S.: New York lawyers sanctioned for using fake ChatGPT cases in legal brief. Reuters (Jun 2023), https://www.reuters.com/legal/ new-york-lawyers-sanctioned-using-fake-chatgpt-cases-legal-brief-2023-06-22/
2023
-
[18]
Miller, T., Howe, P., Sonenberg, L.: Explainable AI: beware of inmates run- ning the asylum or: How I learnt to stop worrying and love the social and be- havioural sciences. CoRRabs/1712.00547(2017), http://arxiv.org/abs/ 1712.00547
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[19]
Annals of Internal Medicine (Jun 2025)
Modi, N.D., Menz, B.D., Awaty, A.A., Alex, C.A., Logan, J.M., McKinnon, R.A., Rowland, A., Bacchi, S., Gradon, K., Sorich, M.J., Hopkins, A.M.: Assessing the System-Instruction Vulnerabilities of Large Language Mod- els to Malicious Conversion Into Health Disinformation Chatbots. Annals of Internal Medicine (Jun 2025). https://doi.org/10.7326/ANNALS-24-03...
-
[20]
Muller, B., Wieting, J., Clark, J., Kwiatkowski, T., Ruder, S., Soares, L., Aharoni, R., Herzig, J., Wang, X.: Evaluating and Modeling Attribution for How Do LLMs Cite? 17 Cross-LingualQuestionAnswering.In:Bouamor,H.,Pino,J.,Bali,K.(eds.) Proceedings of the 2023 Conference on Empirical Methods in Natural Lan- guage Processing. pp. 144–157. Association for...
-
[21]
Nanda, N., Bloom, J.: TransformerLens (2022), https://github.com/ TransformerLensOrg/TransformerLens
2022
-
[22]
https://doi.org/10.48550/ arXiv.2405.17980, http://arxiv.org/abs/2405.17980, arXiv:2405.17980 [cs]
Phukan, A., Somasundaram, S., Saxena, A., Goswami, K., Srinivasan, B.V.: Peering into the Mind of Language Models: An Approach for Attribution in Contextual Question Answering (May 2024). https://doi.org/10.48550/ arXiv.2405.17980, http://arxiv.org/abs/2405.17980, arXiv:2405.17980 [cs]
-
[23]
Sensitivity, Performance, Robustness: Deconstructing the Effect of Sociodemographic Prompting
Qi, J., Sarti, G., Fernández, R., Bisazza, A.: Model Internals-based An- swer Attribution for Trustworthy Retrieval-Augmented Generation. In: Pro- ceedings of the 2024 Conference on Empirical Methods in Natural Lan- guage Processing. pp. 6037–6053 (2024). https://doi.org/10.18653/v1/2024. emnlp-main.347, http://arxiv.org/abs/2406.13663, arXiv:2406.13663 [cs]
-
[24]
In: Proceedings of the 32nd ACM Conference on User Modeling, Adaptation and Personalization
Sadeghi, M., Pöttgen, D., Ebel, P., Vogelsang, A.: Explaining the unex- plainable: The impact of misleading explanations on trust in unreliable predictions for hardly assessable tasks. In: Proceedings of the 32nd ACM Conference on User Modeling, Adaptation and Personalization. pp. 36–46 (2024)
2024
-
[25]
In: Proceedings of the Second International Symposium on Trustworthy Autonomous Systems
Seabrooke,T.,Schneiders,E.,Dowthwaite,L.,Krook,J.,Leesakul,N.,Clos, J., Maior, H., Fischer, J.: A survey of lay people’s willingness to generate le- gal advice using large language models (llms). In: Proceedings of the Second International Symposium on Trustworthy Autonomous Systems. pp. 1–5 (2024)
2024
-
[26]
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models
Tonmoy, S.M.T.I., Zaman, S.M.M., Jain, V., Rani, A., Rawte, V., Chadha, A., Das, A.: A Comprehensive Survey of Hallucination Mitigation Tech- niques in Large Language Models (Jan 2024). https://doi.org/10.48550/ arXiv.2401.01313, http://arxiv.org/abs/2401.01313, arXiv:2401.01313 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Turpin, M., Michael, J., Perez, E., Bowman, S.: Language Models Don’t Al- ways Say What They Think: Unfaithful Explanations in Chain-of-Thought Prompting. Advances in Neural Information Processing Systems36, 74952– 74965 (Dec 2023), https://proceedings.neurips.cc/paper_files/paper/2023/ hash/ed3fea9033a80fea1376299fa7863f4a-Abstract-Conference.html
2023
-
[28]
Meng, C., Choi, K., Song, J., and Ermon, S
Wallat, J., Heuss, M., Rijke, M.d., Anand, A.: Correctness is not Faith- fulness in RAG Attributions (Dec 2024). https://doi.org/10.48550/arXiv. 2412.18004, http://arxiv.org/abs/2412.18004, arXiv:2412.18004 [cs]
work page internal anchor Pith review doi:10.48550/arxiv 2024
-
[29]
Interpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small
Wang, K., Variengien, A., Conmy, A., Shlegeris, B., Steinhardt, J.: In- terpretability in the Wild: a Circuit for Indirect Object Identification in GPT-2 small (Nov 2022). https://doi.org/10.48550/arXiv.2211.00593, http://arxiv.org/abs/2211.00593, arXiv:2211.00593 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2211.00593 2022
-
[30]
Winninger, T., Addad, B., Kapusta, K.: Using Mechanistic Interpretabil- ity to Craft Adversarial Attacks against Large Language Models (May 2025). https://doi.org/10.48550/arXiv.2503.06269, http://arxiv.org/abs/ 2503.06269, arXiv:2503.06269 [cs] 18 I. van Dort and M. Heuss
-
[31]
Health Care Science2(4), 255–263 (2023)
Yang, R., Tan, T.F., Lu, W., Thirunavukarasu, A.J., Ting, D.S.W., Liu, N.: Large language models in health care: Development, applications, and challenges. Health Care Science2(4), 255–263 (2023)
2023
-
[32]
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering
Yang, Z., Qi, P., Zhang, S., Bengio, Y., Cohen, W.W., Salakhutdinov, R., Manning, C.D.: HotpotQA: A Dataset for Diverse, Explainable Multi- hop Question Answering (Sep 2018). https://doi.org/10.48550/arXiv.1809. 09600, http://arxiv.org/abs/1809.09600, arXiv:1809.09600 [cs]
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1809 2018
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.