Multimodal Knowledge Edit-Scoped Generalization for Online Recursive MLLM Editing
Pith reviewed 2026-07-03 13:50 UTC · model grok-4.3
The pith
ScopeEdit decomposes each MLLM edit into a local absorption branch and an evidence-gated generalization branch to control semantic boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that reframing online MLLM editing as explicit control of each edit's propagation boundary, achieved by ScopeEdit's decomposition into a modality-local absorption branch and an evidence-gated shared generalization branch that operate in orthogonal low-rank spaces with Sherman-Morrison recursions, produces consistent gains in in-scope cross-modal transfer while preserving out-of-scope locality, edit reliability, stability, and constant overhead across benchmarks, backbones, and real-world VLKEB streams.
What carries the argument
ScopeEdit, the scope-aware editor that splits every update into a modality-local absorption branch and an evidence-gated shared generalization branch performing scope-separated writes in orthogonal low-rank spaces maintained by Sherman-Morrison recursions.
If this is right
- Each edit can be absorbed locally while cross-modal variants receive the update only when evidence alignment passes the gate.
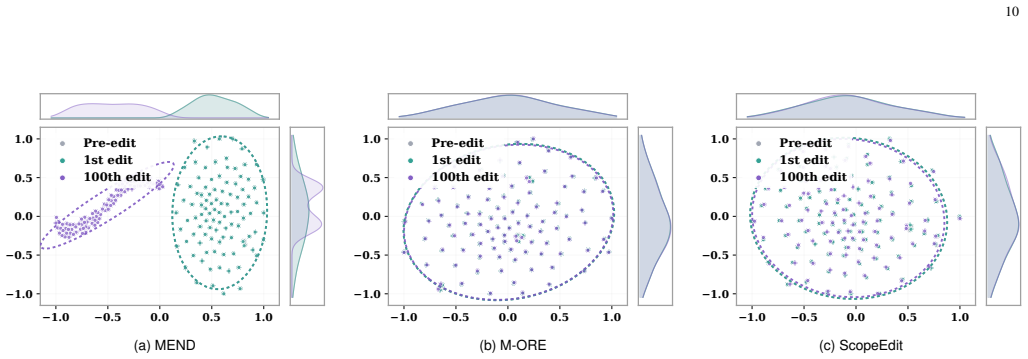
- Out-of-scope leakage remains low even after hundreds of sequential edits because the two branches write in separate low-rank spaces.
- Per-edit runtime and memory stay constant because preconditioners are updated recursively rather than recomputed.
- The same decomposition applies across different MLLM architectures and to real-world vision-language knowledge editing benchmarks.
- Edit reliability and long-horizon stability are retained while the scope trade-off improves.
Where Pith is reading between the lines
- The same branch separation could be tested on non-multimodal continual editing tasks if a suitable evidence-alignment signal is defined for text-only or image-only streams.
- If deeper semantic layers consistently host edit-related activity, future editors might locate the write space directly from activation maps rather than relying on fixed low-rank choices.
- The evidence gate offers a concrete mechanism that could be combined with retrieval-augmented editing pipelines to decide when external context should influence scope.
- Long-horizon stability under ScopeEdit suggests the method may reduce the frequency of full model resets in deployed multimodal systems that receive ongoing corrections.
Load-bearing premise
That alignment of visual and textual evidence can be measured reliably enough to gate cross-modal propagation without creating new instabilities or missing valid transfers.
What would settle it
An experiment on the same long-horizon edit streams and MLLM backbones in which ScopeEdit produces no measurable improvement in the in-scope transfer versus out-of-scope leakage trade-off compared with prior editors that lack the gated branch.
Figures
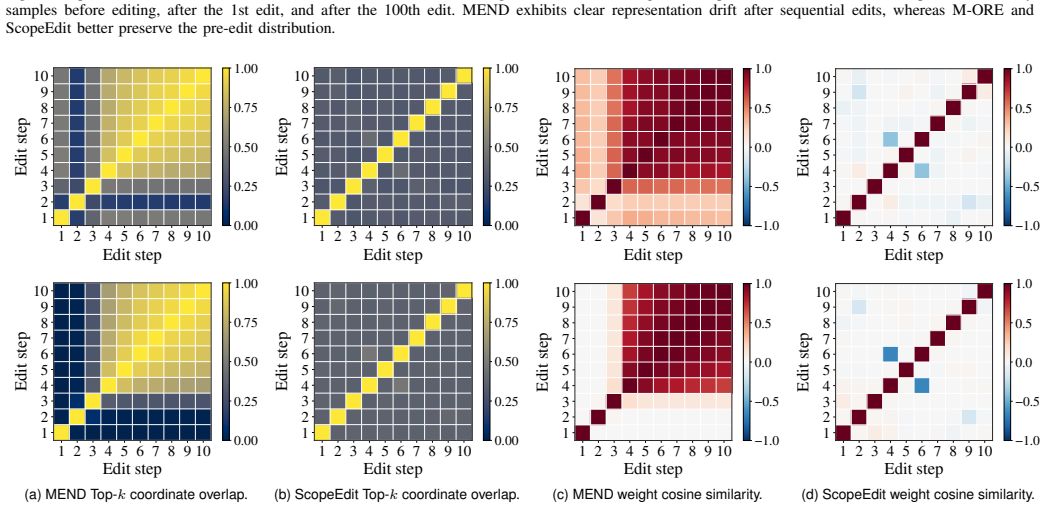
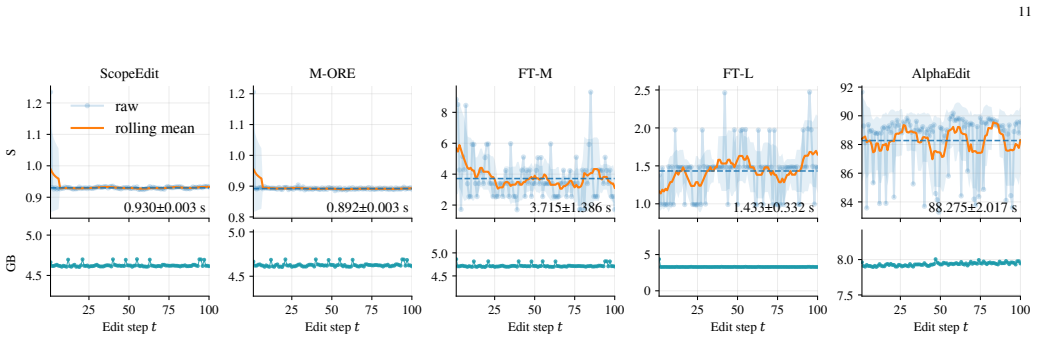
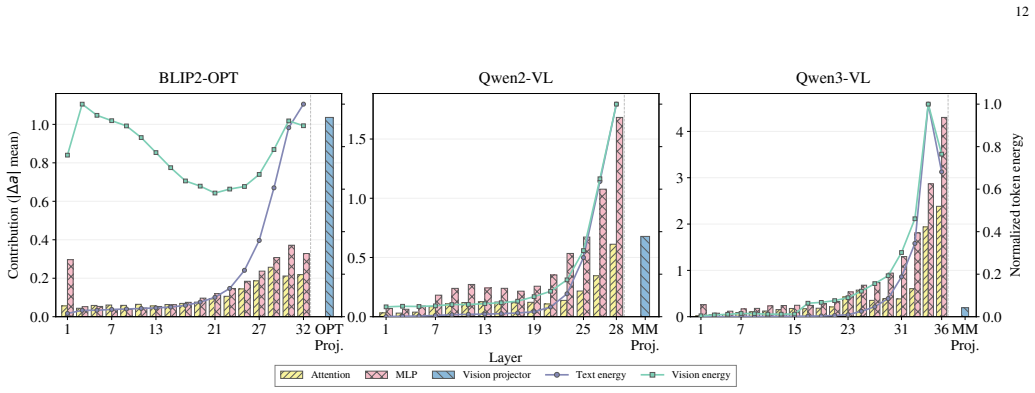
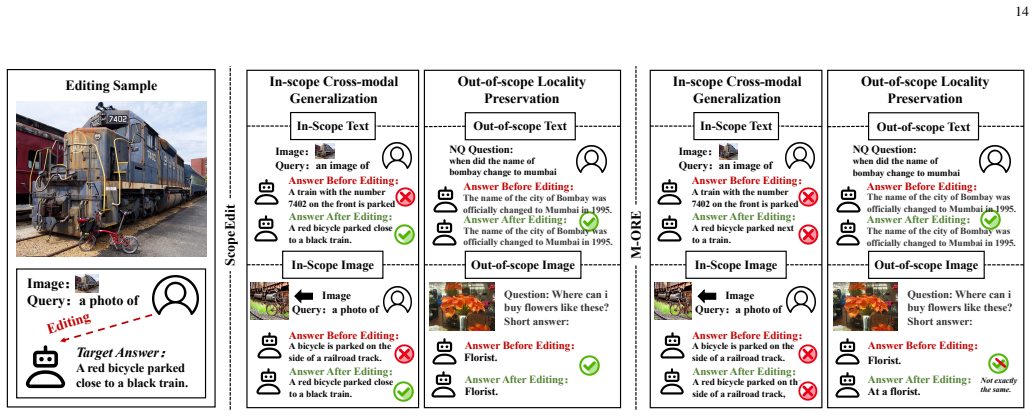
read the original abstract
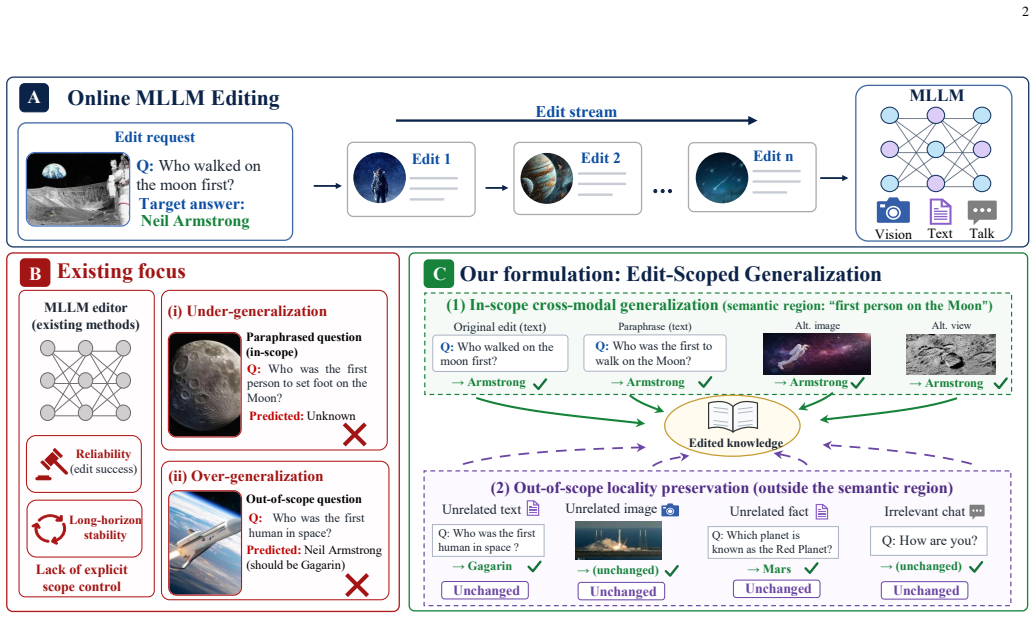
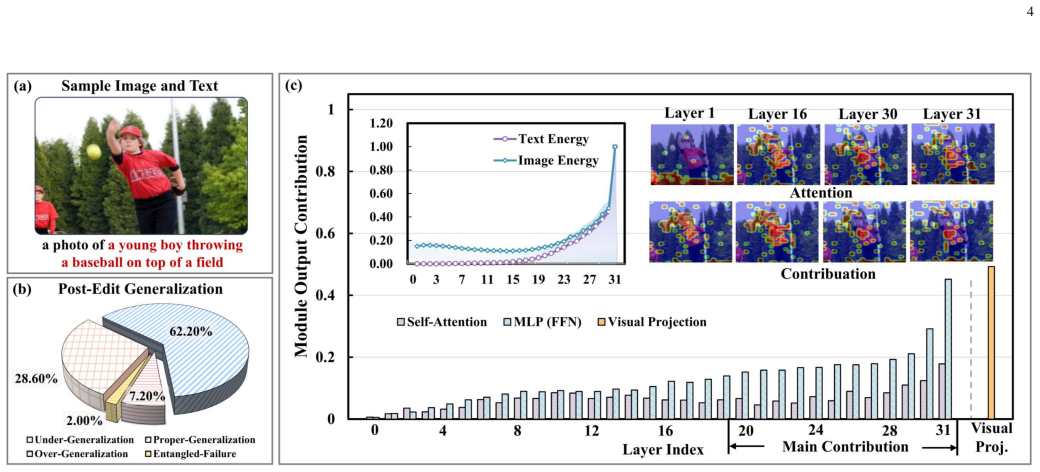
Online multimodal knowledge editing requires injecting a continual stream of visual-textual corrections into multimodal large language models (MLLMs) with bounded overhead and minimal disruption to unrelated behaviors. Existing editors mainly emphasize edit reliability and long-horizon stability, but rarely control the semantic boundary of each edit. Our pilot analyses of post-edit behaviors and internal neuronal activities reveal a scope gap behind reliable edits: instance-level success neither guarantees transfer to valid cross-modal variants nor prevents leakage to unrelated inputs, while edit-related cross-modal responses concentrate in deeper semantic layers. Therefore, we formulate Edit-Scoped Generalization, reframing online MLLM editing from merely correcting an instance to controlling the propagation boundary of each edit. To this end, we propose ScopeEdit, a scope-aware online editor that decomposes each update into a modality-local absorption branch and an evidence-gated shared generalization branch. The local branch supports stable edit absorption, whereas the shared branch enables cross-modal propagation only when visual and textual evidence are sufficiently aligned. Both branches perform scope-separated write geometries in orthogonal low-rank spaces and maintain branch-wise preconditioners via Sherman--Morrison recursions, yielding constant per-edit overhead. Extensive experiments across diverse benchmarks, long-horizon edit streams, MLLM backbones, real-world VLKEB scenarios, and complex vision-language architectures show that ScopeEdit consistently improves the trade-off between in-scope cross-modal transfer and out-of-scope locality, while preserving edit reliability, stability and online efficiency. Our code is available at https://github.com/lab-klc/ScopeEdit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper identifies a 'scope gap' in existing online MLLM editors where instance-level edits succeed but fail to generalize appropriately to cross-modal variants or leak to unrelated inputs. It formulates Edit-Scoped Generalization and proposes ScopeEdit, which decomposes each update into a modality-local absorption branch and an evidence-gated shared generalization branch. Both branches use orthogonal low-rank updates maintained via Sherman-Morrison recursions for constant per-edit overhead. Extensive experiments across benchmarks, long-horizon streams, multiple MLLM backbones, and VLKEB scenarios are claimed to show improved in-scope cross-modal transfer versus out-of-scope locality while preserving reliability, stability, and efficiency. Code is released.
Significance. If the empirical results hold, the work addresses a practically important limitation in multimodal knowledge editing by explicitly controlling edit propagation boundaries rather than only optimizing reliability and stability. The decomposition into local and gated shared branches with orthogonal low-rank geometry and recursive preconditioners is internally consistent with the constant-overhead goal. Credit is due for the public code release and the breadth of reported experiments across architectures and real-world scenarios.
minor comments (3)
- The abstract states that edit-related responses concentrate in deeper semantic layers, but the precise layer indices or activation statistics used to motivate the shared-branch design are not referenced; adding a pointer to the relevant figure or table would strengthen the motivation.
- Notation for the evidence-alignment gate (e.g., the threshold or similarity measure deciding when the shared branch activates) should be introduced with an equation number in the method section for reproducibility.
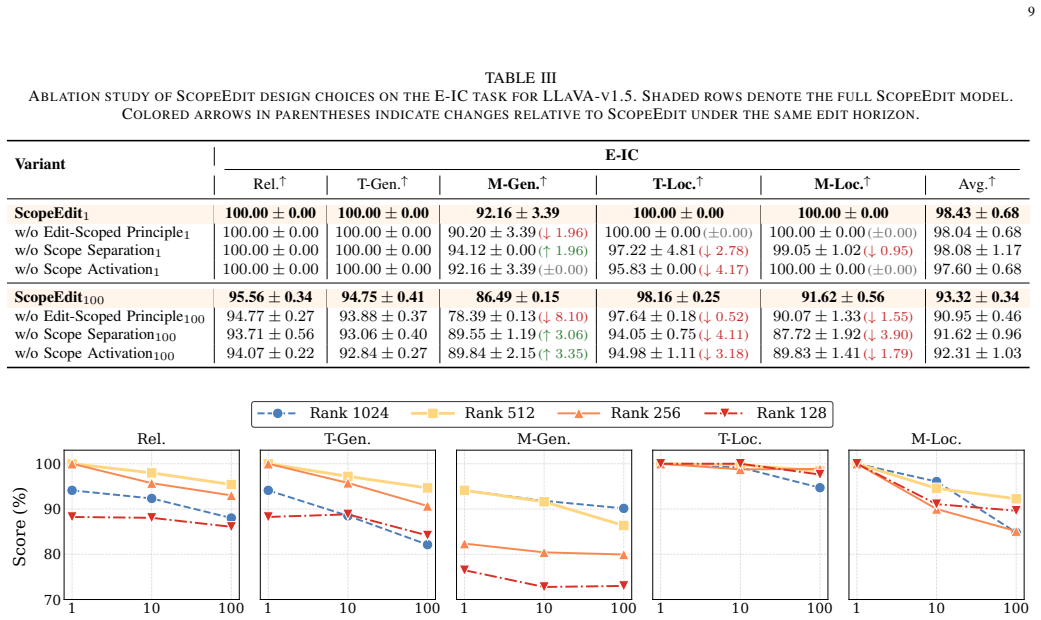
- Table captions or legends should explicitly define the 'in-scope transfer' and 'out-of-scope locality' metrics used to quantify the claimed trade-off improvement.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of our work on addressing the scope gap in online MLLM editing via Edit-Scoped Generalization and ScopeEdit. The recommendation for minor revision is noted, and we appreciate the recognition of the decomposition into modality-local and evidence-gated branches with orthogonal low-rank updates and recursive maintenance for efficiency.
Circularity Check
No significant circularity; empirical engineering contribution without reduction to inputs
full rationale
The paper introduces ScopeEdit as a scope-aware editor via explicit design choices: decomposition into modality-local absorption and evidence-gated shared generalization branches, orthogonal low-rank spaces, and Sherman-Morrison recursions for preconditioners. These are presented as constructions to achieve constant overhead and scope separation, not as derivations from prior fitted quantities or self-citations. No equations or steps reduce by construction to the target claims (e.g., no fitted parameters renamed as predictions, no uniqueness theorems imported from self-citations). Central claims rest on experimental results across benchmarks, architectures, and scenarios, which are independent of any internal reduction. This matches the default expectation of a non-circular empirical method.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Edit-related cross-modal responses concentrate in deeper semantic layers
invented entities (1)
-
ScopeEdit
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LLaMA: Open and Efficient Foundation Language Models
H. Touvron, T. Lavril, G. Izacard, X. Martinet, M.-A. Lachaux, T. Lacroix, B. Rozi `ere, N. Goyal, E. Hambro, F. Azharet al., “Llama: Open and efficient foundation language models,”arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
A Survey of Large Language Models
W. X. Zhao, K. Zhou, J. Li, T. Tang, X. Wang, Y . Hou, Y . Min, B. Zhang, J. Zhang, Z. Donget al., “A survey of large language models,”arXiv preprint arXiv:2303.18223, vol. 1, no. 2, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,
J. Li, D. Li, S. Savarese, and S. Hoi, “Blip-2: Bootstrapping language- image pre-training with frozen image encoders and large language models,” inProceedings of the International conference on machine learning (ICML), 2023, pp. 19 730–19 742
2023
-
[4]
Video-llava: Learning united visual representation by alignment before projection,
B. Lin, Y . Ye, B. Zhu, J. Cui, M. Ning, P. Jin, and L. Yuan, “Video-llava: Learning united visual representation by alignment before projection,” inProceedings of the 2024 conference on empirical methods in natural language processing (EMNLP), 2024, pp. 5971–5984
2024
-
[5]
Moe-llava: Mixture of experts for large vision- language models,
B. Lin, Z. Tang, Y . Ye, J. Huang, J. Zhang, Y . Pang, P. Jin, M. Ning, J. Luo, and L. Yuan, “Moe-llava: Mixture of experts for large vision- language models,”IEEE Transactions on Multimedia, 2026
2026
-
[6]
Vision-controllable language model for image-guided story ending generation,
D. Xue, S. Qian, and C. Xu, “Vision-controllable language model for image-guided story ending generation,”IEEE Transactions on Multime- dia, 2026
2026
-
[7]
When large multimodal models confront evolving knowledge: Challenges and explorations,
K. Jiang, Y . Du, Y . Ding, Y . Ren, N. Jiang, Z. Gao, Z. Zheng, L. Liu, B. Li, and Q. Li, “When large multimodal models confront evolving knowledge: Challenges and explorations,” inProceedings of the International Conference on Learning Representations (ICLR), 2026
2026
-
[8]
Vlbiasbench: A comprehensive benchmark for evaluating bias in large vision-language model,
S. Wang, X. Cao, J. Zhang, Z. Yuan, S. Shan, X. Chen, and W. Gao, “Vlbiasbench: A comprehensive benchmark for evaluating bias in large vision-language model,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[9]
Locating and editing factual associations in gpt,
K. Meng, D. Bau, A. Andonian, and Y . Belinkov, “Locating and editing factual associations in gpt,” inProceedings of the Advances in neural information processing systems (NeurIPS), 2022, pp. 17 359–17 372
2022
-
[10]
Alphaedit: Null-space constrained knowledge editing for language models,
J. Fang, H. Jiang, K. Wang, Y . Ma, J. Shi, X. Wang, X. He, and T.-S. Chua, “Alphaedit: Null-space constrained knowledge editing for language models,” inProceedings of the International Conference on Learning Representations (ICLR), 2025
2025
-
[11]
Attribution analysis meets model editing: Advancing knowledge correction in vision language models with visedit,
Q. Chen, T. Zhang, C. Wang, X. He, D. Wang, and T. Liu, “Attribution analysis meets model editing: Advancing knowledge correction in vision language models with visedit,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2025, pp. 2168–2176
2025
-
[12]
Lifelong knowledge editing for vision language models with low-rank mixture-of- experts,
Q. Chen, C. Wang, D. Wang, T. Zhang, W. Li, and X. He, “Lifelong knowledge editing for vision language models with low-rank mixture-of- experts,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2025, pp. 9455–9466
2025
-
[13]
Can we edit multimodal large language models?
S. Cheng, B. Tian, Q. Liu, X. Chen, Y . Wang, H. Chen, and N. Zhang, “Can we edit multimodal large language models?” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023, pp. 13 877–13 888
2023
-
[14]
Principled multimodal representation learning,
X. Liu, X. Xia, S.-K. Ng, and T.-S. Chua, “Principled multimodal representation learning,”IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[15]
Modality-Decoupled Online Recursive Editing
S. Li, Y . Zhang, F. Liu, and J. Li, “Modality-decoupled online recursive editing,”arXiv preprint arXiv:2605.20273, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Dualedit: Dual editing for knowledge updating in vision-language models,
Z. Shi, B. Wang, C. Si, Y . Wu, J. Kim, and H. Pfister, “Dualedit: Dual editing for knowledge updating in vision-language models,” in Proceedings of the Second Conference on Language Modeling (COLM), 2025
2025
-
[17]
Can we continually edit language models? on the knowledge attenuation in sequential model editing,
Q. Li and X. Chu, “Can we continually edit language models? on the knowledge attenuation in sequential model editing,” inFindings of the Association for Computational Linguistics (ACL), 2024, pp. 5438–5455
2024
-
[18]
VLKEB: A large vision-language model knowledge editing bench- mark,
H. Huang, H. Zhong, T. Yu, Q. Liu, S. Wu, L. Wang, and T. Tan, “VLKEB: A large vision-language model knowledge editing bench- mark,” inAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024
2024
-
[19]
Can knowledge be transferred from unimodal to multi- modal? investigating the transitivity of multimodal knowledge editing,
L. Fang, X. Wang, D. Wang, Z. Wu, Y . Guo, H. Zhu, Z. Zhang, and G. Liu, “Can knowledge be transferred from unimodal to multi- modal? investigating the transitivity of multimodal knowledge editing,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2482–2490
2025
-
[20]
Mmke- bench: A multimodal editing benchmark for diverse visual knowledge,
Y . Du, K. Jiang, Z. Gao, C. Shi, Z. Zheng, S. Qi, and Q. Li, “Mmke- bench: A multimodal editing benchmark for diverse visual knowledge,” inThe Thirteenth International Conference on Learning Representa- tions(ICLR), 2025
2025
-
[21]
MC-MKE: A fine-grained multimodal knowledge editing benchmark emphasizing modality consistency,
J. Zhang, H. Zhang, X. Yin, B. Huang, X. Zhang, X. Hu, and X. Wan, “MC-MKE: A fine-grained multimodal knowledge editing benchmark emphasizing modality consistency,” inFindings of the Association for Computational Linguistics(ACL), 2025, pp. 17 430–17 445
2025
-
[22]
Memeic: A step toward continual and compositional knowl- edge editing,
J. Seong, J. Park, W. Liermann, H. Choi, Y . Nam, H. Kim, S. Lim, and N. Lee, “Memeic: A step toward continual and compositional knowl- edge editing,” inProceedings of the Advances in neural information processing systems (NeurIPS), vol. 38, 2025, pp. 129 205–129 242
2025
-
[23]
Exploring and evaluat- ing multimodal knowledge reasoning consistency of multimodal large language models,
B. Jia, J. Zhang, H. Zhang, and X. Wan, “Exploring and evaluat- ing multimodal knowledge reasoning consistency of multimodal large language models,” inFindings of the Association for Computational Linguistics(EMNLP), 2025, pp. 11 966–11 981
2025
-
[24]
M2Edit: Locate and edit multi-granularity knowledge in multimodal large language model,
Y . Zhou, P. Cao, Y . Chen, Q. Liu, D. Sui, X. Chen, K. Liu, and J. Zhao, “M2Edit: Locate and edit multi-granularity knowledge in multimodal large language model,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(EMNLP), 2025, pp. 29 029–29 042
2025
-
[25]
V-SEAM: Visual semantic editing and attention modulating for causal interpretability of vision-language models,
Q. Wang, J. Hu, and M. Jiang, “V-SEAM: Visual semantic editing and attention modulating for causal interpretability of vision-language models,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(EMNLP), 2025, pp. 17 396–17 420
2025
-
[26]
Dsca: Dynamic subspace concept alignment for lifelong vlm editing,
G. Das and S. Jena, “Dsca: Dynamic subspace concept alignment for lifelong vlm editing,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2026, pp. 40 772– 40 781
2026
-
[27]
Insight over sight: Exploring the vision-knowledge conflicts in multimodal LLMs,
X. Liu, W. Wang, Y . Yuan, J.-t. Huang, Q. Liu, P. He, and Z. Tu, “Insight over sight: Exploring the vision-knowledge conflicts in multimodal LLMs,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 17 825–17 846
2025
-
[28]
Is cognition consistent with perception? assessing and mitigating multimodal knowledge conflicts in document understanding,
Z. Shao, F. Gao, Z. Zhu, C. Luo, H. Xing, Z. Yu, Q. Zheng, M. Yan, and J. Bu, “Is cognition consistent with perception? assessing and mitigating multimodal knowledge conflicts in document understanding,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(EMNLP), 2025, pp. 30 923–30 944
2025
-
[29]
Knowledge neurons in pretrained transformers,
D. Dai, L. Dong, Y . Hao, Z. Sui, B. Chang, and F. Wei, “Knowledge neurons in pretrained transformers,” inProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (ACL), 2022, pp. 8493–8502
2022
-
[30]
Editable neural networks,
A. Sinitsin, V . Plokhotnyuk, D. V . Pyrkin, S. Popov, and A. Babenko, “Editable neural networks,” inProceedings of the International Confer- ence on Learning Representations (ICLR), 2020
2020
- [31]
-
[32]
Transformer-patcher: One mistake worth one neuron,
Z. Huang, Y . Shen, X. Zhang, J. Zhou, W. Rong, and Z. Xiong, “Transformer-patcher: One mistake worth one neuron,” inProceedings of the International Conference on Learning Representations (ICLR), 2023
2023
-
[33]
Neighboring perturba- tions of knowledge editing on large language models,
J.-Y . Ma, Z.-H. Ling, N. Zhang, and J.-C. Gu, “Neighboring perturba- tions of knowledge editing on large language models,” inProceedings of the 41st International Conference on Machine Learning(ICML), vol. 235, 2024, pp. 33 839–33 854
2024
-
[34]
Uncovering over- fitting in large language model editing,
M. Zhang, X. Ye, Q. Liu, S. Wu, P. Ren, and Z. Chen, “Uncovering over- fitting in large language model editing,” inProceedings of the Thirteenth International Conference on Learning Representations(ICLR), 2025. 16
2025
-
[35]
Revealing and mitigating over-attention in knowledge editing,
P. Wang, Z. Tang, K. Zhou, J. Li, Q. Zhu, and M. Zhang, “Revealing and mitigating over-attention in knowledge editing,” inProceedings of the Thirteenth International Conference on Learning Representa- tions(ICLR), 2025, pp. 20 922–20 948
2025
-
[36]
Parameter-aware contrastive knowledge editing: Tracing and rectifying based on critical transmission paths,
S. Zhai, Y . Meng, Y . Zhang, and G. Qi, “Parameter-aware contrastive knowledge editing: Tracing and rectifying based on critical transmission paths,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 28 189–28 200
2025
-
[37]
CaKE: Circuit-aware editing enables generalizable knowledge learn- ers,
Y . Yao, J. Fang, J.-C. Gu, N. Zhang, S. Deng, H. Chen, and N. Peng, “CaKE: Circuit-aware editing enables generalizable knowledge learn- ers,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(EMNLP), 2025, pp. 11 366–11 382
2025
-
[38]
Mass-editing memory in a transformer,
K. Meng, A. S. Sharma, A. J. Andonian, Y . Belinkov, and D. Bau, “Mass-editing memory in a transformer,” inProceedings of the Interna- tional Conference on Learning Representations (ICLR), 2023
2023
-
[39]
Deltaedit: Enhancing sequential editing in large language models by controlling superimposed noise,
D. Cao, Y . Cai, R. Guo, X. He, and G. Liu, “Deltaedit: Enhancing sequential editing in large language models by controlling superimposed noise,”arXiv preprint arXiv:2505.07899, 2025
-
[40]
Editing factual knowledge in language models,
N. De Cao, W. Aziz, and I. Titov, “Editing factual knowledge in language models,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021
2021
-
[41]
Fast model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. Finn, and C. D. Manning, “Fast model editing at scale,” inProceedings of the International Conference on Learning Representations (ICLR), 2022
2022
-
[42]
SAKE: Steering activations for knowledge editing,
M. Scialanga, T. Laugel, V . Grari, and M. Detyniecki, “SAKE: Steering activations for knowledge editing,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 15 966–15 978
2025
-
[43]
Knowledge editing through chain-of-thought,
C. Wang, W. Su, Q. Ai, Y . Tang, and Y . Liu, “Knowledge editing through chain-of-thought,” inProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(EMNLP), 2025, pp. 10 673– 10 693
2025
-
[44]
Can we edit factual knowledge by in-context learning?
C. Zheng, L. Li, Q. Dong, Y . Fan, Z. Wu, J. Xu, and B. Chang, “Can we edit factual knowledge by in-context learning?” inProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023, pp. 4862–4876
2023
-
[45]
Memory- based model editing at scale,
E. Mitchell, C. Lin, A. Bosselut, C. D. Manning, and C. Finn, “Memory- based model editing at scale,” inProceedings of the International Conference on Machine Learning (ICML), 2022, pp. 15 817–15 831
2022
-
[46]
Aging with GRACE: lifelong model editing with discrete key- value adaptors,
T. Hartvigsen, S. Sankaranarayanan, H. Palangi, Y . Kim, and M. Ghas- semi, “Aging with GRACE: lifelong model editing with discrete key- value adaptors,” inProceedings of the Advances in neural information processing systems (NeurIPS), 2023
2023
-
[47]
MELO: enhancing model editing with neuron-indexed dynamic lora,
L. Yu, Q. Chen, J. Zhou, and L. He, “MELO: enhancing model editing with neuron-indexed dynamic lora,” inProceedings of the AAAI Conference on Artificial Intelligence (AAAI), 2024, pp. 19 449–19 457
2024
-
[48]
Llms meet multimodal generation and editing: A survey,
Y . He, Z. Liu, J. Chen, Z. Tian, H. Liu, X. Chi, R. Liu, R. Yuan, Y . Xing, W. Wang, J. Dai, Y . Zhang, W. Xue, Q. Liu, Y . Guo, and Q. Chen, “Llms meet multimodal generation and editing: A survey,” arXiv preprint arXiv:2405.19334, 2024
-
[49]
BalancEdit: Dynamically balancing the generality-locality trade-off in multi-modal model editing,
D. Guo, M. Hu, Z. Guan, T. Hartvigsen, and S. Li, “BalancEdit: Dynamically balancing the generality-locality trade-off in multi-modal model editing,” inProceedings of the 42nd International Conference on Machine Learning(ICML), vol. 267, 2025, pp. 20 843–20 857
2025
-
[50]
Visual- oriented fine-grained knowledge editing for multimodal large language models,
Z. Zeng, L. Gu, X. Yang, Z. Duan, Z. Shi, and M. Wang, “Visual- oriented fine-grained knowledge editing for multimodal large language models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2025, pp. 2491–2500
2025
-
[51]
Unlocking efficient, scalable, and continual knowledge editing with basis-level representation fine-tuning,
T. Liu, R. Li, Y . Qi, H. Liu, X. Tang, T. Zheng, Q. Yin, M. Cheng, J. Huan, H. Wang, and J. Gao, “Unlocking efficient, scalable, and continual knowledge editing with basis-level representation fine-tuning,” inProceedings of the Thirteenth International Conference on Learning Representations(ICLR), 2025, pp. 18 939–18 959
2025
-
[52]
Neuron-level sequential editing for large language models,
H. Jiang, J. Fang, T. Zhang, B. Bi, A. Zhang, R. Wang, T. Liang, and X. Wang, “Neuron-level sequential editing for large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 16 678–16 702
2025
-
[53]
MEMORYLLM: Towards self-updatable large language models,
Y . Wang, Y . Gao, X. Chen, H. Jiang, S. Li, J. Yang, Q. Yin, Z. Li, X. Li, B. Yin, J. Shang, and J. Mcauley, “MEMORYLLM: Towards self-updatable large language models,” inProceedings of the 41st In- ternational Conference on Machine Learning(ICML), 2024, pp. 50 453– 50 466
2024
-
[54]
AdaEdit: Advancing continuous knowledge editing for large language models,
Q. Li and X. Chu, “AdaEdit: Advancing continuous knowledge editing for large language models,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (ACL), 2025, pp. 4127– 4149
2025
-
[55]
Lifelong knowledge editing for LLMs with retrieval-augmented con- tinuous prompt learning,
Q. Chen, T. Zhang, X. He, D. Li, C. Wang, L. Huang, and H. Xue’, “Lifelong knowledge editing for LLMs with retrieval-augmented con- tinuous prompt learning,” inProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024, pp. 13 565–13 580
2024
-
[56]
WISE: rethinking the knowledge memory for lifelong model editing of large language models,
P. Wang, Z. Li, N. Zhang, Z. Xu, Y . Yao, Y . Jiang, P. Xie, F. Huang, and H. Chen, “WISE: rethinking the knowledge memory for lifelong model editing of large language models,” inProceedings of the Advances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[57]
Should we really edit language models? on the evaluation of edited language models,
Q. Li, X. Liu, Z. Tang, P. Dong, Z. Li, X. Pan, and X. Chu, “Should we really edit language models? on the evaluation of edited language models,” inProceedings of the 38th International Conference on Neural Information Processing Systems(NeurIPS), 2024
2024
-
[58]
Wik- ibigedit: Understanding the limits of lifelong knowledge editing in llms,
L. Thede, K. Roth, M. Bethge, Z. Akata, and T. Hartvigsen, “Wik- ibigedit: Understanding the limits of lifelong knowledge editing in llms,” inProceedings of the International Conference on Machine Learning (ICML), 2025
2025
-
[59]
Transformer feed-forward layers are key-value memories,
M. Geva, R. Schuster, J. Berant, and O. Levy, “Transformer feed-forward layers are key-value memories,” inProceedings of the 2021 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2021, pp. 5484–5495
2021
-
[60]
Improved baselines with visual instruction tuning,
H. Liu, C. Li, Y . Li, and Y . J. Lee, “Improved baselines with visual instruction tuning,” inProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), 2024, pp. 26 286–26 296
2024
-
[61]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
P. Wang, S. Bai, S. Tan, S. Wang, Z. Fan, J. Bai, K. Chen, X. Liu, J. Wang, W. Ge, Y . Fan, K. Dang, M. Du, X. Ren, R. Men, D. Liu, C. Zhou, J. Zhou, and J. Lin, “Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution,”arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
S. Bai, Y . Cai, R. Chen, K. Chen, X. Chen, Z. Cheng, L. Deng, W. Ding, C. Gao, C. Ge, W. Ge, Z. Guo, Q. Huang, J. Huang, F. Huang, B. Hui, S. Jiang, Z. Li, M. Li, M. Li, K. Li, Z. Lin, J. Lin, X. Liu, J. Liu, C. Liu, Y . Liu, D. Liu, S. Liu, D. Lu, R. Luo, C. Lv, R. Men, L. Meng, X. Ren, X. Ren, S. Song, Y . Sun, J. Tang, J. Tu, J. Wan, P. Wang, P. Wang,...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.