DeWorldSG: Depth-Aware 3D Semantic Scene Graph Generation via World-Model Priors
Pith reviewed 2026-07-02 14:04 UTC · model grok-4.3
The pith
DeWorldSG builds 3D scene graphs by turning depth data into probabilistic Gaussian object nodes and refining relations with world-model priors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
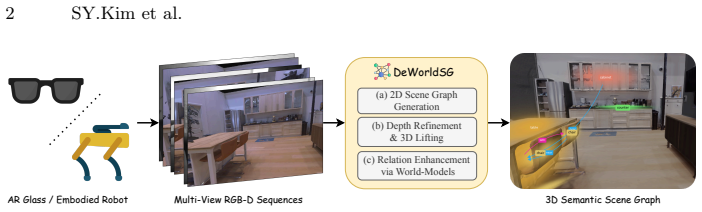
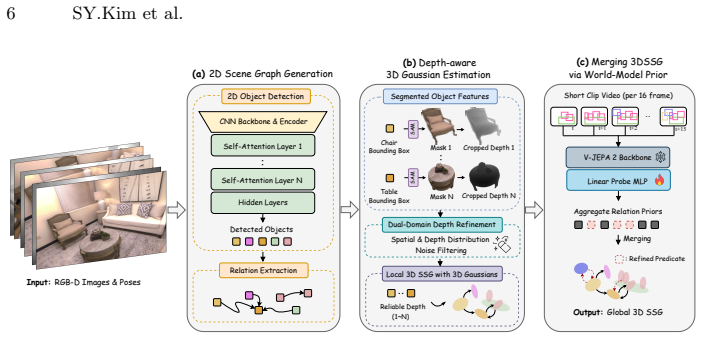
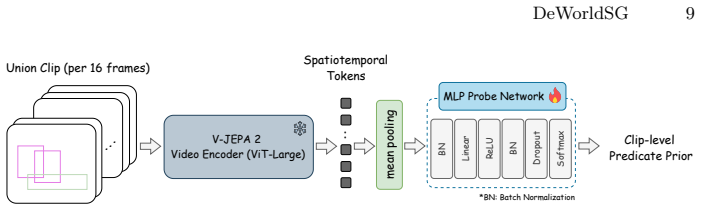
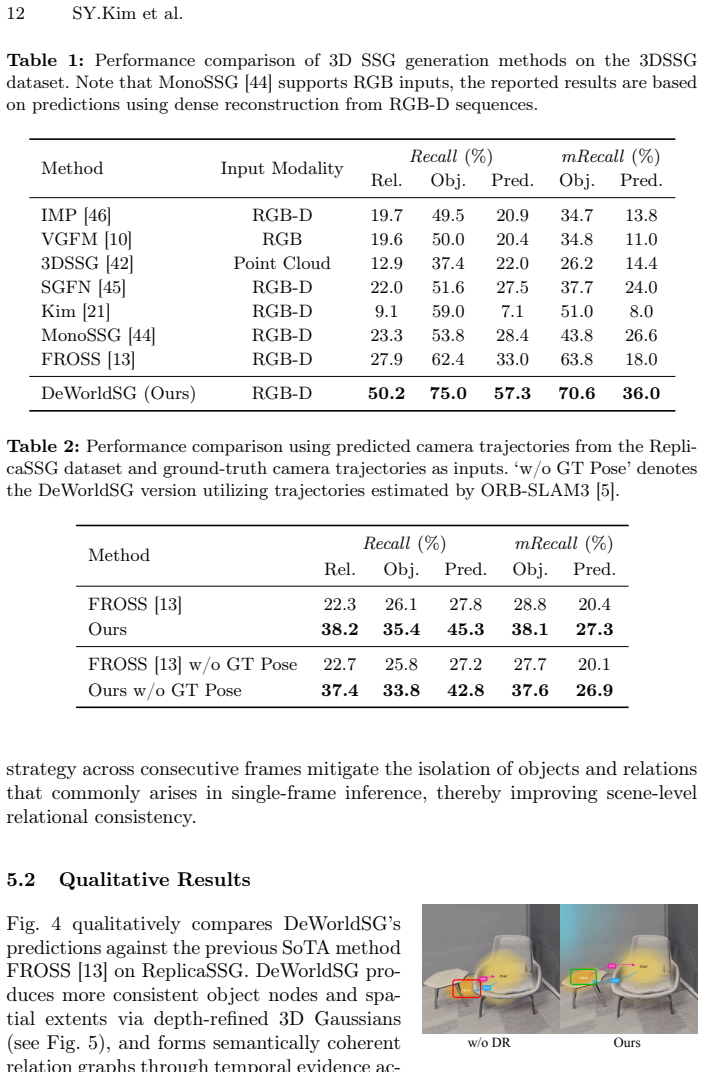
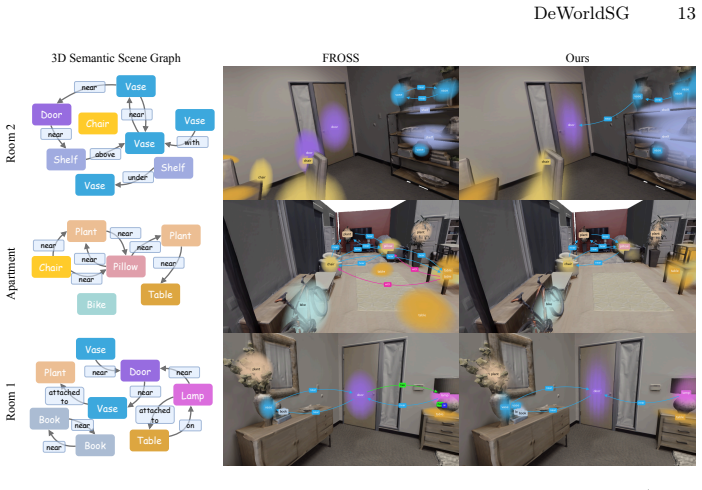
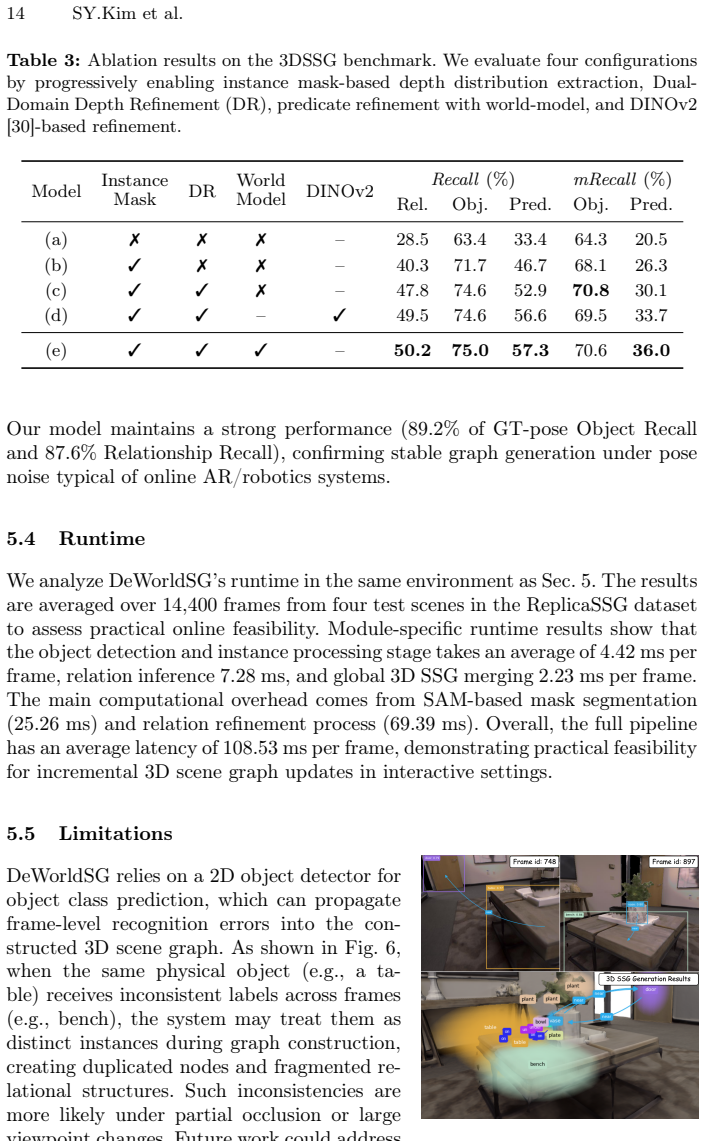
DeWorldSG estimates instance-level geometric 3D Gaussian distributions through depth-guided filtering and represents each object as a probabilistic 3D node rather than a single projected point. It aggregates spatiotemporal evidence across object pairs and refines relations using contextual priors derived from a world model. Experiments on the 3DSSG and ReplicaSSG datasets demonstrate state-of-the-art performance in both object and predicate prediction while producing temporally consistent scene structures, with triplet recall improved by 77.4 percent and predicate recall by 23.2 percent over prior approaches.
What carries the argument
Instance-level 3D Gaussian distributions as probabilistic object nodes, paired with spatiotemporal evidence aggregation across frames and world-model contextual priors for relation refinement.
If this is right
- Scene graphs become temporally consistent across video frames instead of fluctuating per frame.
- Object and relation predictions improve together on RGB-D benchmarks.
- The graphs become usable for tasks that require stable 3D spatial understanding over time.
Where Pith is reading between the lines
- The Gaussian node representation could be tested directly on consumer depth cameras with lower precision to check robustness.
- World-model priors might transfer to other incomplete 3D observation settings such as monocular video with estimated depth.
- Longer video sequences could expose whether the aggregation step saturates or continues to add value.
Load-bearing premise
Depth sensor readings are accurate and complete enough to form reliable 3D Gaussian distributions for each object instance without major noise or occlusion problems.
What would settle it
Measure triplet and predicate recall on the same datasets after adding realistic depth sensor noise or heavy occlusions to the input sequences; if gains over baselines disappear the central claim does not hold.
Figures
read the original abstract
We present DeWorldSG, a novel framework that generates spatio-temporally robust 3D Semantic Scene Graphs from RGB-D sequences. Existing methods often struggle to construct reliable 3D scene graphs due to unstable 3D object representations and missing relations caused by frame-wise inference. DeWorldSG addresses these issues by estimating instance-level geometric 3D Gaussian distributions through depth-guided filtering and representing each object as a probabilistic 3D node rather than a single projected point. To mitigate relational sparsity from frame-wise inference, our framework further aggregates spatiotemporal evidence across object pairs and refines relations using contextual priors derived from a world model (V-JEPA 2). Experiments on the 3DSSG and ReplicaSSG datasets demonstrate state-of-the-art (SoTA) performance in both object and predicate prediction, while producing temporally consistent scene structures. In particular, our method improves triplet recall by 77.4% and predicate recall by 23.2% over prior SoTA approaches, making it suitable for robotic manipulation and AR applications. Our code and models are open-sourced.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DeWorldSG for generating spatio-temporally robust 3D semantic scene graphs from RGB-D sequences. It estimates instance-level geometric 3D Gaussian distributions via depth-guided filtering to represent each object as a probabilistic 3D node (rather than a projected point), aggregates spatiotemporal evidence across object pairs to address relational sparsity, and refines relations using contextual priors from the V-JEPA 2 world model. Experiments on the 3DSSG and ReplicaSSG datasets claim state-of-the-art results, including 77.4% improvement in triplet recall and 23.2% in predicate recall over prior approaches, with temporally consistent structures; code and models are open-sourced.
Significance. If the central performance claims are substantiated, the probabilistic 3D node representation and world-model priors could meaningfully improve robustness and temporal consistency in 3D scene graphs, with direct relevance to robotic manipulation and AR. The open-sourcing of code strengthens reproducibility.
major comments (2)
- [Method (depth-guided filtering and probabilistic node construction)] The method's core step of estimating instance-level 3D Gaussian distributions through depth-guided filtering lacks any explicit noise model, depth completion procedure, or ablation on realistic RGB-D artifacts (holes, specular reflections, partial occlusions). This directly undermines the stability of the covariance parameters and the claim that probabilistic nodes are more reliable than point projections.
- [Experiments and results] The reported gains (77.4% triplet recall, 23.2% predicate recall) are presented without accompanying experimental controls, error bars, dataset splits, or ablation studies on the depth component. Because the spatiotemporal aggregation and V-JEPA 2 priors operate downstream, they cannot compensate for upstream geometric errors; this renders the quantitative claims unevaluable from the given text.
minor comments (1)
- [Abstract] The abstract states improvements 'over prior SoTA approaches' without naming the specific baselines; adding this would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the need for greater methodological rigor and experimental transparency. We will revise the manuscript to incorporate explicit noise modeling, artifact ablations, error bars, and dataset details as outlined below.
read point-by-point responses
-
Referee: [Method (depth-guided filtering and probabilistic node construction)] The method's core step of estimating instance-level 3D Gaussian distributions through depth-guided filtering lacks any explicit noise model, depth completion procedure, or ablation on realistic RGB-D artifacts (holes, specular reflections, partial occlusions). This directly undermines the stability of the covariance parameters and the claim that probabilistic nodes are more reliable than point projections.
Authors: We agree that the current description does not include an explicit sensor noise model or targeted ablations on common RGB-D artifacts. In the revision we will add a depth noise model (Gaussian perturbation scaled by distance and sensor variance) and a new ablation section that injects synthetic holes, specular noise, and partial occlusions into the input depth maps, reporting the resulting covariance stability and downstream triplet recall. This will directly support the claim that probabilistic nodes improve reliability over point projections. revision: yes
-
Referee: [Experiments and results] The reported gains (77.4% triplet recall, 23.2% predicate recall) are presented without accompanying experimental controls, error bars, dataset splits, or ablation studies on the depth component. Because the spatiotemporal aggregation and V-JEPA 2 priors operate downstream, they cannot compensate for upstream geometric errors; this renders the quantitative claims unevaluable from the given text.
Authors: We acknowledge the absence of error bars, explicit split descriptions, and isolated depth-component ablations. The revised manuscript will report mean and standard deviation over three random seeds, specify the exact 3DSSG and ReplicaSSG train/validation/test partitions used, and add an ablation that replaces the 3D Gaussian nodes with point projections while keeping all other modules fixed. These additions will allow readers to evaluate the upstream geometric contribution independently of the downstream aggregation and world-model priors. revision: yes
Circularity Check
No circularity detected; framework description contains no equations or derivations
full rationale
The provided abstract and manuscript summary describe a pipeline that estimates 3D Gaussian distributions via depth-guided filtering, aggregates spatiotemporal evidence, and refines relations with V-JEPA 2 priors, then reports empirical gains on 3DSSG and ReplicaSSG. No equations, parameter fits, or derivation steps appear in the text. Consequently none of the enumerated circularity patterns (self-definitional, fitted-input-called-prediction, self-citation load-bearing, etc.) can be exhibited by direct quotation. The central claims remain externally falsifiable through the stated dataset experiments and are not shown to reduce to their own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption V-JEPA 2 supplies contextual priors that improve relation prediction on the target datasets
- domain assumption Depth data from RGB-D sensors is accurate enough to support instance-level 3D Gaussian estimation
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Assran, M., Bardes, A., Fan, D., Garrido, Q., Howes, R., Muckley, M., Rizvi, A., Roberts, C., Sinha, K., Zholus, A., et al.: V-jepa 2: Self-supervised video models enable understanding, prediction and planning. arXiv preprint arXiv:2506.09985 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Bardes, A., Garrido, Q., Ponce, J., Chen, X., Rabbat, M., LeCun, Y., Assran, M., Ballas, N.: V-jepa: Latent video prediction for visual representation learning (2023) 16 SY.Kim et al
2023
-
[3]
arXiv preprint arXiv:2410.23968 (2024)
Booker, M., Byrd, G., Kemp, B., Schmidt, A., Rivera, C.: Embodiedrag: Dy- namic 3d scene graph retrieval for efficient and scalable robot task planning. arXiv preprint arXiv:2410.23968 (2024)
-
[4]
Articulated 3D scene graphs for open-world mobile manipulation.arXiv preprint arXiv:2602.16356, 2026
Büchner, M., Röfer, A., Engelbracht, T., Welschehold, T., Bauer, Z., Blum, H., Pollefeys, M., Valada, A.: Articulated 3d scene graphs for open-world mobile ma- nipulation. arXiv preprint arXiv:2602.16356 (2026)
-
[5]
IEEE transactions on robotics37(6), 1874–1890 (2021)
Campos, C., Elvira, R., Rodríguez, J.J.G., Montiel, J.M., Tardós, J.D.: Orb-slam3: An accurate open-source library for visual, visual–inertial, and multimap slam. IEEE transactions on robotics37(6), 1874–1890 (2021)
2021
-
[6]
Chen, D., Shukor, M., Moutakanni, T., Chung, W., Yu, J., Kasarla, T., Bolourchi, A., LeCun, Y., Fung, P.: Vl-jepa: Joint embedding predictive architecture for vision-language. arXiv preprint arXiv:2512.10942 (2025)
-
[7]
In: 14th International Conference on Information Fusion
Crouse, D.F., Willett, P., Pattipati, K., Svensson, L.: A look at gaussian mixture reduction algorithms. In: 14th International Conference on Information Fusion. pp. 1–8. IEEE (2011)
2011
-
[8]
arXiv preprint arXiv:2504.00844 (2025)
Elskhawy, A., Li, M., Navab, N., Busam, B.: Prism-0: A predicate-rich scene graph generation framework for zero-shot open-vocabulary tasks. arXiv preprint arXiv:2504.00844 (2025)
-
[9]
In: 2025IEEE-RAS24thInternationalConferenceonHumanoidRobots(Humanoids)
Engelbracht, T., Zurbrügg, R., Pollefeys, M., Blum, H., Bauer, Z.: Spotlight: Robotic scene understanding through interaction and affordance detection. In: 2025IEEE-RAS24thInternationalConferenceonHumanoidRobots(Humanoids). pp. 1–8. IEEE (2025)
2025
-
[10]
In: Asian Conference on Computer Vision
Gay, P., Stuart, J., Del Bue, A.: Visual graphs from motion (vgfm): Scene un- derstanding with object geometry reasoning. In: Asian Conference on Computer Vision. pp. 330–346. Springer (2018)
2018
-
[11]
In: International conference on machine learning
Gilmer, J., Schoenholz, S.S., Riley, P.F., Vinyals, O., Dahl, G.E.: Neural message passing for quantum chemistry. In: International conference on machine learning. pp. 1263–1272. Pmlr (2017)
2017
-
[12]
In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA)
Gu, Q., Kuwajerwala, A., Morin, S., Jatavallabhula, K.M., Sen, B., Agarwal, A., Rivera, C., Paul, W., Ellis, K., Chellappa, R., et al.: Conceptgraphs: Open- vocabulary 3d scene graphs for perception and planning. In: 2024 IEEE Inter- national Conference on Robotics and Automation (ICRA). pp. 5021–5028. IEEE (2024)
2024
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Hou, H.Y., Lee, C.Y., Sonogashira, M., Kawanishi, Y.: Fross: Faster-than-real-time online 3d semantic scene graph generation from rgb-d images. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 28818–28827 (2025)
2025
-
[14]
arXiv preprint arXiv:2506.05217 (2025)
Hu, W., Wen, X., Li, X., Wang, G.: Dsg-world: Learning a 3d gaussian world model from dual state videos. arXiv preprint arXiv:2506.05217 (2025)
-
[15]
Advances in Neural In- formation Processing Systems (2025)
Huang, Z., Wu, X., Zhong, F., Zhao, H., Nießner, M., Lasenby, J.: Litereality: graphics-ready 3d scene reconstruction from rgb-d scans. Advances in Neural In- formation Processing Systems (2025)
2025
-
[16]
Proceedings of Robotics: Science and Systems (2022)
Hughes, N., Chang, Y., Carlone, L.: Hydra: A real-time spatial perception system for 3d scene graph construction and optimization. Proceedings of Robotics: Science and Systems (2022)
2022
-
[17]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Im, J., Nam, J., Park, N., Lee, H., Park, S.: Egtr: Extracting graph from trans- former for scene graph generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 24229–24238 (2024)
2024
-
[18]
Dexterous world models.arXiv preprint arXiv:2512.17907, 2025
Kim, B., Kim, T., Lee, J., Joo, H.: Dexterous world models. arXiv preprint arXiv:2512.17907 (2025) DeWorldSG 17
-
[19]
arXiv preprint arXiv:2602.02974 (2026)
Kim, S.Y., Kim, D., Cho, W., Song, H., Kang, S., Woo, W.: Scenelinker: Compo- sitional 3d scene generation via semantic scene graph from rgb sequences. arXiv preprint arXiv:2602.02974 (2026)
-
[20]
In: Adjunct Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology
Kim, S., Kim, D., Son, T., Woo, W.: Realitycrafter: User-guided editable 3d scene generation from a single image in mixed reality. In: Adjunct Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. pp. 1– 3 (2025)
2025
-
[21]
Kim, U.H.,Park, J.M.,Song,T.J.,Kim, J.H.:3-dscenegraph: Asparseandseman- ticrepresentationofphysicalenvironmentsforintelligentagents.IEEEtransactions on cybernetics50(12), 4921–4933 (2019)
2019
-
[22]
Semi-Supervised Classification with Graph Convolutional Networks
Kipf, T.N., Welling, M.: Semi-supervised classification with graph convolutional networks. arXiv preprint arXiv:1609.02907 (2016)
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[23]
International journal of computer vision123(1), 32–73 (2017)
Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. International journal of computer vision123(1), 32–73 (2017)
2017
-
[24]
2, 2022-06-27
LeCun, Y., et al.: A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27. Open Review62(1), 1–62 (2022)
2022
-
[25]
In: Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology
Lee, J., Aleotti, F., Mazala, D., Garcia-Hernando, G., Vicente, S., Johnston, O.J., Kraus-Liang, I., Powierza, J., Shin, D., Froehlich, J.E., et al.: Imaginatear: Ai- assisted in-situ authoring in augmented reality. In: Proceedings of the 38th Annual ACM Symposium on User Interface Software and Technology. pp. 1–21 (2025)
2025
-
[26]
IEEE Transactions on Visualization and Computer Graphics (2025)
Liu, J., Zhang, R., Butaslac, I., Sawabe, T., Fujimoto, Y., Kanbara, M., Kato, H.: Everywherear: A visual authoring system for creating adaptive ar game scenes. IEEE Transactions on Visualization and Computer Graphics (2025)
2025
-
[27]
arXiv:2407.17140 [cs.CV] https://arxiv.org/abs/2407.17140 Paul C
Lv, W., Zhao, Y., Chang, Q., Huang, K., Wang, G., Liu, Y.: Rt-detrv2: Improved baseline with bag-of-freebies for real-time detection transformer. arXiv preprint arXiv:2407.17140 (2024)
-
[28]
Robotic Intelligence and Automation43(1), 12–22 (2023)
Miao, R., Jia, Q., Sun, F.: Long-term robot manipulation task planning with scene graph and semantic knowledge. Robotic Intelligence and Automation43(1), 12–22 (2023)
2023
-
[29]
IEEE Transactions on Image Processing33, 671–681 (2024)
Murrugarra-Llerena, J., Kirsten, L.N., Zeni, L.F., Jung, C.R.: Probabilistic intersection-over-union for training and evaluation of oriented object detectors. IEEE Transactions on Image Processing33, 671–681 (2024)
2024
-
[30]
DINOv2: Learning Robust Visual Features without Supervision
Oquab, M., Darcet, T., Moutakanni, T., Vo, H., Szafraniec, M., Khalidov, V., Fernandez, P., Haziza, D., Massa, F., El-Nouby, A., et al.: Dinov2: Learning robust visual features without supervision. arXiv preprint arXiv:2304.07193 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
International Journal of Computer Assisted Radiology and Surgery19(5), 791–799 (2024)
Özsoy, E., Czempiel, T., Örnek, E.P., Eck, U., Tombari, F., Navab, N.: Holistic or domain modeling: a semantic scene graph approach. International Journal of Computer Assisted Radiology and Surgery19(5), 791–799 (2024)
2024
-
[32]
arXiv preprint arXiv:2411.10509 (2024)
Pham,Q.P.,Nguyen,K.T.,Ngo,L.C.,Do,T.,Song,D.,Hy,T.S.:Tesgnn:Temporal equivariantscenegraphneuralnetworksforefficientandrobustmulti-view3dscene understanding. arXiv preprint arXiv:2411.10509 (2024)
-
[33]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[34]
The International Journal of Robotics Research40(12-14), 1510–1546 (2021) 18 SY.Kim et al
Rosinol,A.,Violette,A.,Abate,M.,Hughes,N.,Chang,Y.,Shi,J.,Gupta,A.,Car- lone, L.: Kimera: From slam to spatial perception with 3d dynamic scene graphs. The International Journal of Robotics Research40(12-14), 1510–1546 (2021) 18 SY.Kim et al
2021
-
[35]
arXiv preprint arXiv:2412.14480 (2024)
Saxena, S., Buchanan, B., Paxton, C., Liu, P., Chen, B., Vaskevicius, N., Palmieri, L., Francis, J., Kroemer, O.: Grapheqa: Using 3d semantic scene graphs for real- time embodied question answering. arXiv preprint arXiv:2412.14480 (2024)
-
[36]
In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision
Singh, K.P., Salvador, J., Weihs, L., Kembhavi, A.: Scene graph contrastive learn- ing for embodied navigation. In: Proceedings of the IEEE/CVF International Con- ference on Computer Vision. pp. 10884–10894 (2023)
2023
-
[37]
IEEE Transactions on Knowledge and Data Engineering36(11), 6962–6976 (2024)
Song, Y., Sun, P., Liu, H., Li, Z., Song, W., Xiao, Y., Zhou, X.: Scene-driven multimodal knowledge graph construction for embodied ai. IEEE Transactions on Knowledge and Data Engineering36(11), 6962–6976 (2024)
2024
-
[38]
The Replica Dataset: A Digital Replica of Indoor Spaces
Straub, J., Whelan, T., Ma, L., Chen, Y., Wijmans, E., Green, S., Engel, J.J., Mur-Artal, R., Ren, C., Verma, S., et al.: The replica dataset: A digital replica of indoor spaces. arXiv preprint arXiv:1906.05797 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1906
-
[39]
In: 2020 IEEE Inter- nationalSymposiumonMixedandAugmentedRealityAdjunct(ISMAR-Adjunct)
Tahara, T., Seno, T., Narita, G., Ishikawa, T.: Retargetable ar: Context-aware augmented reality in indoor scenes based on 3d scene graph. In: 2020 IEEE Inter- nationalSymposiumonMixedandAugmentedRealityAdjunct(ISMAR-Adjunct). pp. 249–255. IEEE (2020)
2020
-
[40]
In: 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)
Tateno, K., Tombari, F., Navab, N.: Real-time and scalable incremental segmen- tation on dense slam. In: 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). pp. 4465–4472. IEEE (2015)
2015
-
[41]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Wald, J., Avetisyan, A., Navab, N., Tombari, F., Nießner, M.: Rio: 3d object instance re-localization in changing indoor environments. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 7658–7667 (2019)
2019
-
[42]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wald, J., Dhamo, H., Navab, N., Tombari, F.: Learning 3d semantic scene graphs from 3d indoor reconstructions. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 3961–3970 (2020)
2020
-
[43]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wang, Z., Cheng, B., Zhao, L., Xu, D., Tang, Y., Sheng, L.: Vl-sat: Visual-linguistic semantics assisted training for 3d semantic scene graph prediction in point cloud. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 21560–21569 (2023)
2023
-
[44]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Wu, S.C., Tateno, K., Navab, N., Tombari, F.: Incremental 3d semantic scene graph prediction from rgb sequences. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 5064–5074 (2023)
2023
-
[45]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wu, S.C., Wald, J., Tateno, K., Navab, N., Tombari, F.: Scenegraphfusion: In- cremental 3d scene graph prediction from rgb-d sequences. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 7515– 7525 (2021)
2021
-
[46]
In: Proceedings of the IEEE conference on computer vision and pat- tern recognition
Xu, D., Zhu, Y., Choy, C.B., Fei-Fei, L.: Scene graph generation by iterative mes- sage passing. In: Proceedings of the IEEE conference on computer vision and pat- tern recognition. pp. 5410–5419 (2017)
2017
-
[47]
IEEE Robotics and Automation Letters (2025)
Yan, Z., Li, S., Wang, Z., Wu, L., Wang, H., Zhu, J., Chen, L., Liu, J.: Dynamic open-vocabulary 3d scene graphs for long-term language-guided mobile manipula- tion. IEEE Robotics and Automation Letters (2025)
2025
-
[48]
arXiv preprint arXiv:2507.12508 (2025)
Yang, Y., Liu, J., Zhang, Z., Zhou, S., Tan, R., Yang, J., Du, Y., Gan, C.: Mind- journey: Test-time scaling with world models for spatial reasoning. arXiv preprint arXiv:2507.12508 (2025)
-
[49]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Yang, Z., Lu, K., Zhang, C., Qi, J., Jiang, H., Ma, R., Yin, S., Xu, Y., Xing, M., Xiao, Z., et al.: Mmgdreamer: Mixed-modality graph for geometry-controllable 3d indoor scene generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 9391–9399 (2025) DeWorldSG 19
2025
-
[50]
In: European Conference on Computer Vision
Zhai, G., Örnek, E.P., Chen, D.Z., Liao, R., Di, Y., Navab, N., Tombari, F., Busam, B.: Echoscene: Indoor scene generation via information echo over scene graph diffu- sion. In: European Conference on Computer Vision. pp. 167–184. Springer (2024)
2024
-
[51]
Advances in Neural Information Processing Systems36, 30026–30038 (2023)
Zhai, G., Örnek, E.P., Wu, S.C., Di, Y., Tombari, F., Navab, N., Busam, B.: Com- monscenes: Generating commonsense 3d indoor scenes with scene graph diffusion. Advances in Neural Information Processing Systems36, 30026–30038 (2023)
2023
-
[52]
arXiv preprint arXiv:2510.23607 (2025)
Zhang, Y., Wu, X., Lao, Y., Wang, C., Tian, Z., Wang, N., Zhao, H.: Concerto: Joint 2d-3d self-supervised learning emerges spatial representations. arXiv preprint arXiv:2510.23607 (2025)
-
[53]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Zhao, Y., Lv, W., Xu, S., Wei, J., Wang, G., Dang, Q., Liu, Y., Chen, J.: Detrs beat yolos on real-time object detection. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 16965–16974 (2024)
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.