DreamForge-World 0.1 Preview: A Low-Compute Real-Time Controllable World Model
Pith reviewed 2026-06-30 07:29 UTC · model grok-4.3
The pith
A low-compute adaptation of an open autoregressive video model adds a residual action pathway to support live keyboard and mouse control at 14-15 FPS on one RTX 4090.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DreamForge-World 0.1 Preview adapts the LongLive 1 autoregressive video stack, itself derived from Wan2.1-T2V-1.3B, with a residual action pathway to deliver live keyboard and mouse control, multimodal initialization, mid-stream reprompting, dual-view operation, and minute-scale interactive rollouts at native 480p resolution, reaching up to 14 to 15 FPS on a single RTX 4090 with a low memory footprint through targeted adaptation of open video backbones.
What carries the argument
residual action pathway added to an autoregressive video generation stack to condition outputs on live user inputs
If this is right
- Live keyboard and mouse inputs can steer the generated world in real time during rollout.
- Multimodal initialization and mid-stream reprompting allow flexible changes to the simulation without restarting.
- Dual-view operation and minute-scale sessions become feasible at interactive frame rates on consumer hardware.
- Low memory footprint and 480p native resolution make the system practical for single-GPU setups.
- Cost-efficiency comes from leveraging existing open video backbones rather than new large-scale training.
Where Pith is reading between the lines
- Similar residual pathways could be tested on other open video models to check how widely the adaptation pattern applies.
- The combination of reprompting and dual views may support new interaction patterns in simulation or game-prototyping settings.
- If frame rates hold under varied conditions, the method could extend to slightly higher resolutions while remaining real-time.
- The low-compute route suggests a path for broader experimentation with world models outside specialized labs.
Load-bearing premise
Targeted adaptation runs on open video backbones with a residual action pathway are sufficient to deliver the claimed interactive capabilities and runtime performance without major unstated degradation or additional hardware requirements.
What would settle it
A direct measurement on an RTX 4090 showing whether the system sustains 14-15 FPS with responsive live keyboard and mouse control, functional multimodal initialization, and no major quality loss across a full minute-scale rollout would confirm or refute the performance claims.
Figures




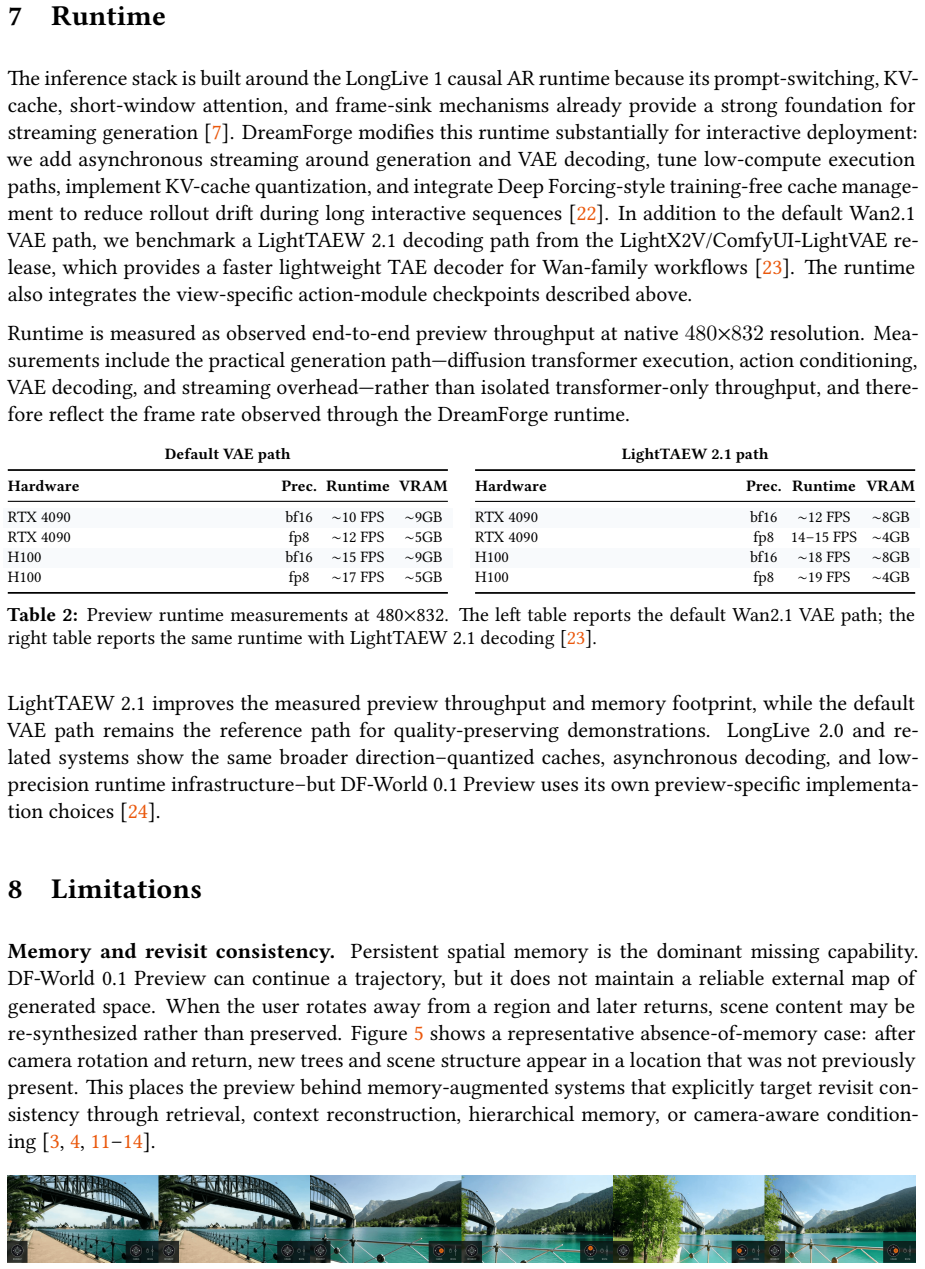


read the original abstract
We present DreamForge-World 0.1 Preview, a preview foundational world model for real-time interactive world simulation. The system adapts the LongLive 1 autoregressive video stack, itself derived from Wan2.1-T2V-1.3B, with a residual action pathway inspired by the Matrix-Game family. DreamForge-World 0.1 Preview focuses on a complementary axis to frontier-scale world simulators: low-compute adaptation, consumer-GPU runtime, and broad interactive capability coverage. It supports live keyboard and mouse control, multimodal initialization, mid-stream reprompting, dual-view operation, and minute-scale interactive rollouts at native 480p resolution, reaching up to 14 to 15 FPS FPS on a single RTX 4090 with a low memory footprint. By leveraging open video backbones and applying targeted adaptation runs, we build the preview system with high cost-efficiency. DF-World 0.1 Preview is not yet a memory-complete or frontier-quality world simulator, but demonstrates a practical low-compute route toward real-time controllable world-model previews on consumer GPUs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents DreamForge-World 0.1 Preview as a low-compute adaptation of the LongLive 1 autoregressive video stack (derived from Wan2.1-T2V-1.3B) with an added residual action pathway. It claims support for live keyboard and mouse control, multimodal initialization, mid-stream reprompting, dual-view operation, and minute-scale interactive rollouts at native 480p resolution, achieving up to 14-15 FPS on a single RTX 4090 with low memory footprint, while qualifying that the system is neither memory-complete nor frontier-quality.
Significance. If the claimed interactive features and runtime performance hold, the work would illustrate a practical, cost-efficient route to real-time controllable world models on consumer hardware by adapting open video backbones, providing a complementary axis to frontier-scale simulators. The scoped preview framing and explicit qualifications are noted strengths, but the absence of any empirical support reduces immediate significance.
major comments (1)
- [Abstract] Abstract: The manuscript states concrete performance metrics (14-15 FPS at 480p on RTX 4090) and interactive capabilities without supplying any experiments, quantitative metrics, error analysis, ablation studies, or verification details to support these claims.
minor comments (1)
- [Abstract] Abstract: The phrase 'reaching up to 14 to 15 FPS FPS' contains a duplicated 'FPS'.
Simulated Author's Rebuttal
We thank the referee for the constructive review and for recognizing the potential complementary value of a low-compute adaptation approach. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The manuscript states concrete performance metrics (14-15 FPS at 480p on RTX 4090) and interactive capabilities without supplying any experiments, quantitative metrics, error analysis, ablation studies, or verification details to support these claims.
Authors: We agree that the manuscript, as currently written, reports specific runtime metrics and capabilities in the abstract without a supporting experimental section, ablations, or verification protocol. This is a limitation of the present preview framing. The numbers reflect direct wall-clock measurements obtained while running the adapted LongLive 1 stack plus residual action pathway on an RTX 4090 at 480p; the interactive features are those implemented and exercised in the system. Because the work is scoped as a low-cost adaptation preview rather than a full empirical study, we did not conduct the broader quantitative evaluations the referee correctly notes are missing. In a revised version we will (1) move the concrete performance claims out of the abstract into a new “Runtime Characteristics” subsection that explicitly describes the measurement setup and hardware, (2) add explicit language that these figures are illustrative of the current implementation rather than benchmarked results, and (3) include additional qualitative rollout examples. Full ablations and error analysis remain outside the intended scope of this preview release. revision: partial
Circularity Check
No circularity: high-level system description with no derivations or self-referential claims
full rationale
The manuscript is a preview-level system summary describing an adaptation of an existing video backbone (Wan2.1-T2V-1.3B via LongLive 1) plus a residual action pathway. It lists supported features and measured runtime numbers while explicitly qualifying scope and limitations. No equations, fitted parameters, predictions, or derivation chains appear anywhere in the provided text. No self-citations are load-bearing; the cited inspirations are external. All patterns (self-definitional, fitted-input-called-prediction, uniqueness-imported, etc.) are absent, so the derivation chain is empty and the circularity score is 0.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
David Ha and Jürgen Schmidhuber. World Models. arXiv:1803.10122, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Genie: Generative Interactive Environments,
Jake Bruce, Michael Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, Yusuf Aytar, Sarah Bechtle, Fer- yal Behbahani, Stephanie Chan, Nicolas Heess, Lucy Gonzalez, Simon Osindero, Sherjil Ozair, Scott Reed, Jingwei Zhang, Konrad Zolna, Jeff Clune, Nando de Freitas, Satinder ...
-
[3]
Genie 2: A large-scale foundation world model
Google DeepMind. Genie 2: A large-scale foundation world model. Technical announcement,
-
[4]
deepmind.google/blog/genie-2-a-large-scale-foundation-world-model
-
[5]
Genie 3: A new frontier for world models
Google DeepMind. Genie 3: A new frontier for world models. Technical announcement, 2025. deepmind.google/blog/genie-3-a-new-frontier-for-world-models
2025
-
[6]
Diffusion Models Are Real-Time Game Engines
Dani Valevski et al. Diffusion Models Are Real-Time Game Engines. arXiv:2408.14837, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan Team. Wan: Open and Advanced Large-Scale Video Generative Models. arXiv:2503.20314,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Code and models: github.com/Wan-Video/Wan2.1
-
[10]
LongLive: Real-time Interactive Long Video Generation
LongLive Team. LongLive-1.3B model release materials. Hugging Face paper page, 2025. hugging- face.co/papers/2509.22622
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Matrix-game: Interactive world foundation model,
Yifan Zhang et al. Matrix-Game: Interactive World Foundation Model. arXiv:2506.18701, 2025
-
[12]
Matrix-game 2.0: An open-source real-time and streaming interactive world model
Xianglong He, Chunli Peng, Zexiang Liu, Boyang Wang, Yifan Zhang, Qi Cui, Fei Kang, Biao Jiang, Mengyin An, Yangyang Ren, Baixin Xu, Hao-Xiang Guo, Kaixiong Gong, Cyrus Wu, Wei Li, Xuchen Song, Yang Liu, Eric Li, and Yahui Zhou. Matrix-Game 2.0: An Open-Source, Real-Time, and Streaming Interactive World Model. arXiv:2508.13009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Zile Wang, Zexiang Liu, Jaixing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, Yidan Xietian, Jiangbo Pei, Liang Hu, Boyi Jiang, Hua Xue, Zidong Wang, Haofeng Sun, Wei Li, Wanli Ouyang, Xianglong He, Yang Liu, Yangguang Li, and Yahui Zhou. Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-H...
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[14]
WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling
Wenqiang Sun, Haiyu Zhang, Haoyuan Wang, Junta Wu, Zehan Wang, Zhenwei Wang, Yunhong Wang, Jun Zhang, Tengfei Wang, and Chunchao Guo. WorldPlay: Towards Long-Term Geometric Consistency for Real-Time Interactive World Modeling. arXiv:2512.14614, 2025. Project page: 3d- models.hunyuan.tencent.com/world
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Infinite-World: Long-Horizon Interactive World Generation,
Ruiqi Wu, Xuanhua He, Meng Cheng, Tianyu Yang, Yong Zhang, Zhuoliang Kang, Xunliang Cai, Xiaoming Wei, Chunle Guo, Chongyi Li, and Ming-Ming Cheng. Infinite-World: Scaling Interac- tive World Models to 1000-Frame Horizons via Pose-Free Hierarchical Memory. arXiv:2602.02393, 2026
-
[16]
DreamX-World 1.0: A General-Purpose Interactive World Model
DreamX Team. DreamX-World 1.0: A General-Purpose Interactive World Model. arXiv:2606.16993, 2026
-
[17]
Advancing Open-source World Models
Robbyant Team. LingBot-World: Advancing Open-source World Models. arXiv:2601.20540, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[18]
MAGI-1: Autoregressive Video Generation at Scale
Sand.ai Team. MAGI-1: Autoregressive Video Generation at Scale. arXiv:2505.13211, 2025. Code: github.com/SandAI-org/MAGI-1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[19]
Rolling Forcing: Autoregressive Long Video Diffusion in Real Time
Kunhao Liu, Wenbo Hu, Jiale Xu, Ying Shan, and Shijian Lu. Rolling Forcing: Autoregressive Long Video Diffusion in Real Time. arXiv:2509.25161, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Ca2-vdm: Efficient autore- gressive video diffusion model with causal generation and cache sharing,
Kaifeng Gao, Jiaxin Shi, Hanwang Zhang, Chunping Wang, Jun Xiao, and Long Chen. Ca2- VDM: Efficient Autoregressive Video Diffusion Model with Causal Generation and Cache Sharing. arXiv:2411.16375, 2024. Code: github.com/Dawn-LX/CausalCache-VDM
-
[21]
NitroGen: An Open Foundation Model for Generalist Gaming Agents
Loic Magne, Anas Awadalla, Guanzhi Wang, Yinzhen Xu, Joshua Belofsky, Fengyuan Hu, Joohwan Kim, Ludwig Schmidt, Georgia Gkioxari, Jan Kautz, Yisong Yue, Yejin Choi, Yuke Zhu, and Linxi Fan. NitroGen: An Open Foundation Model for Generalist Gaming Agents. arXiv:2601.02427, 2026
-
[22]
Gamegen-x: Interactive open-world game video generation
Haoxuan Che, Xuanhua He, Quande Liu, Cheng Jin, and Hao Chen. GameGen-X: Interactive Open-world Game Video Generation. arXiv:2411.00769, 2024
-
[23]
Depth Anything 3: Recovering the Visual Space from Any Views
Haotong Lin, Sili Chen, Junhao Liew, Donny Y. Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth Anything 3: Recovering the Visual Space from Any Views. arXiv:2511.10647, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
Deep Forcing: Training-Free Long Video Generation with Deep Sink and Participative Compression
Jung Yi, Wooseok Jang, Paul Hyunbin Cho, Jisu Nam, Heeji Yoon, and Seungryong Kim. Deep Forcing: Training-Free Long Video Generation with Deep Sink and Participative Compression. arXiv:2512.05081, 2025. 9
-
[25]
ComfyUI-LightV AE: High-Performance V AE Custom Nodes for LightX2V, includ- ing LightV AE and LightTAE models
ModelTC. ComfyUI-LightV AE: High-Performance V AE Custom Nodes for LightX2V, includ- ing LightV AE and LightTAE models. GitHub repository, 2026. github.com/ModelTC/ComfyUI- LightV AE
2026
-
[26]
LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
Yukang Chen, Luozhou Wang, Wei Huang, Shuai Yang, Bohan Zhang, Yicheng Xiao, Ruihang Chu, Weian Mao, Qixin Hu, Shaoteng Liu, Yuyang Zhao, Huizi Mao, Ying-Cong Chen, Enze Xie, Xiao- juan Qi, Song Han. LongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation. arXiv:2605.18739, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
BiWM: Advancing Open-Source Interactive Video World Models with Bidirectional Autoregression
Shaohao Rui, Xiaofeng Mao, Zhanyu Zhang, Peijia Lin, Yansong Zhu, Yibo Zhang, Haibin Wan, and Weijie Ma. BiWM: Advancing Open-Source Interactive Video World Models with Bidirec- tional Autoregression. arXiv:2606.10135, 2026. 10
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.