Qwen-RobotManip Technical Report: Alignment Unlocks Scale for Robotic Manipulation Foundation Models
Pith reviewed 2026-06-27 01:06 UTC · model grok-4.3
The pith
A unified alignment framework across representation, motion, and behavioral dimensions enables coherent large-scale training of robotic manipulation foundation models on heterogeneous data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
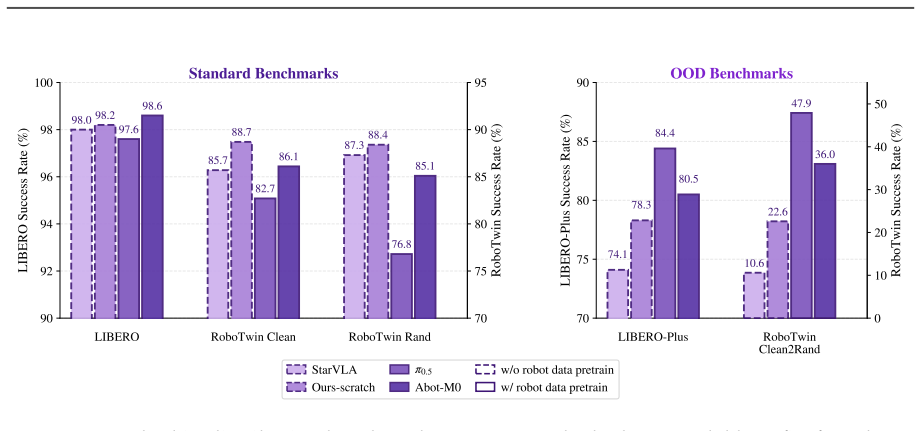
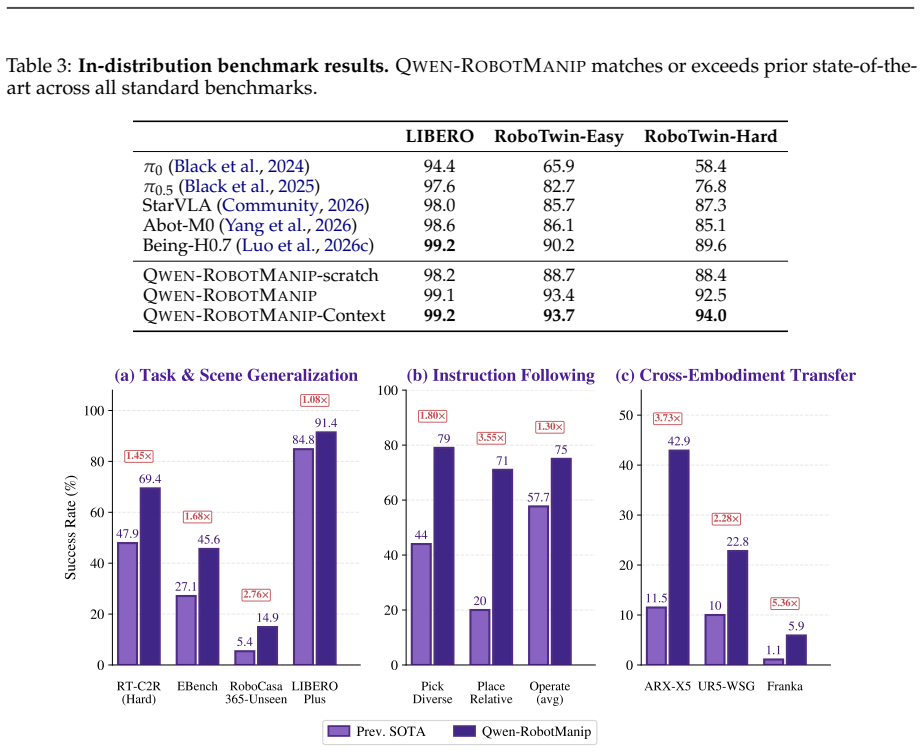
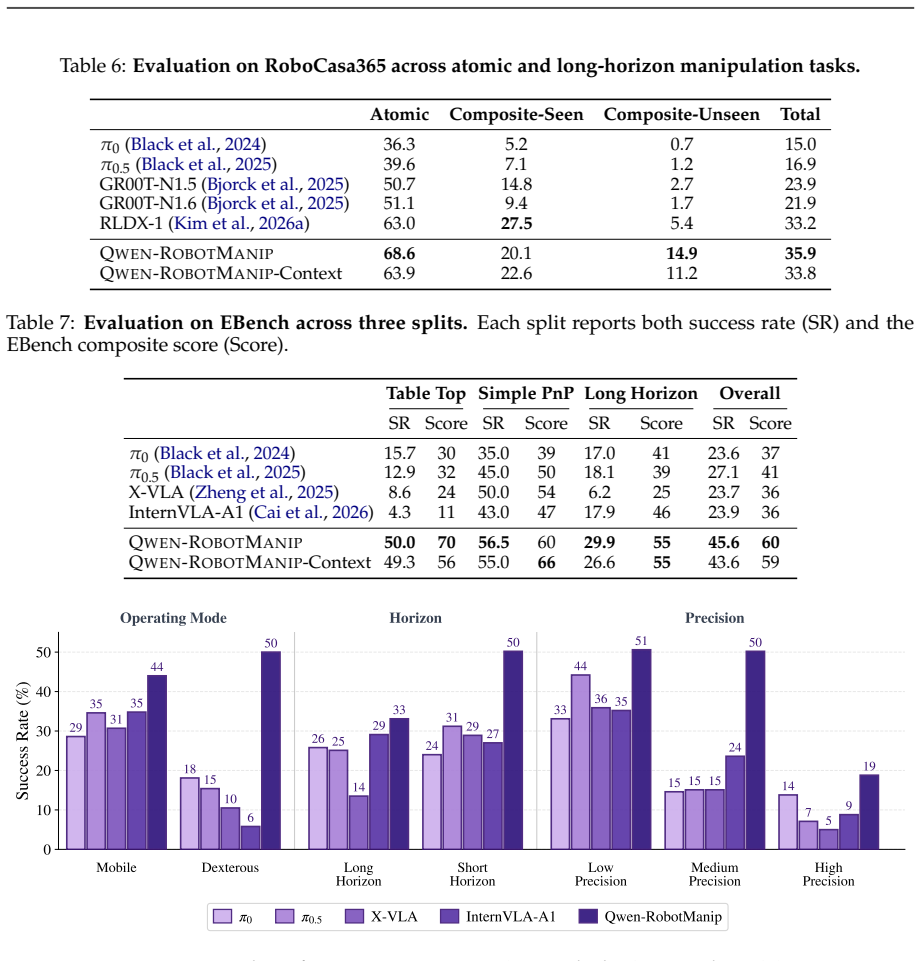
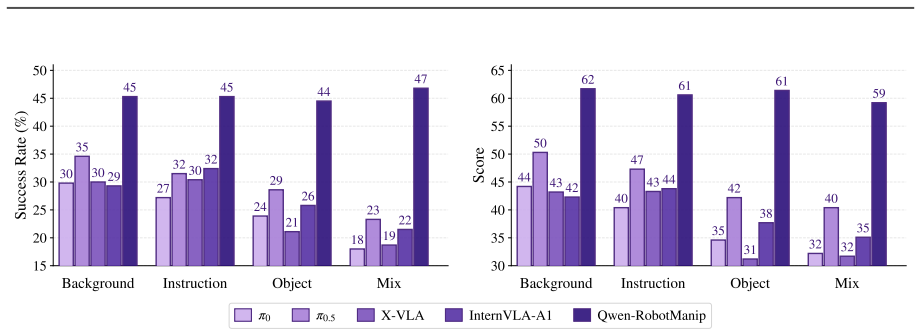
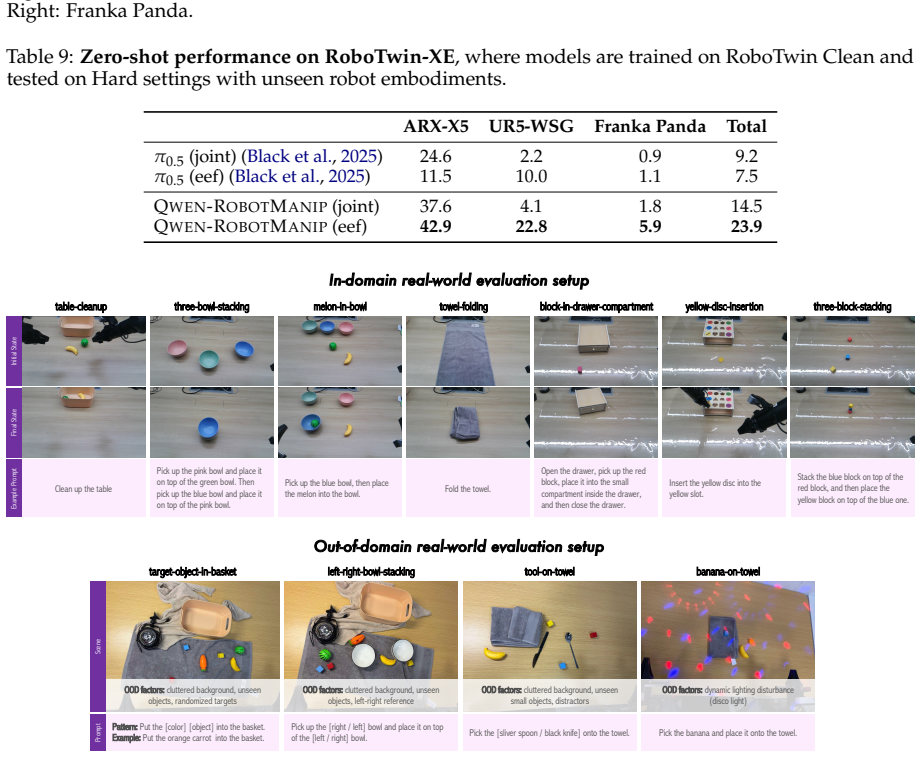
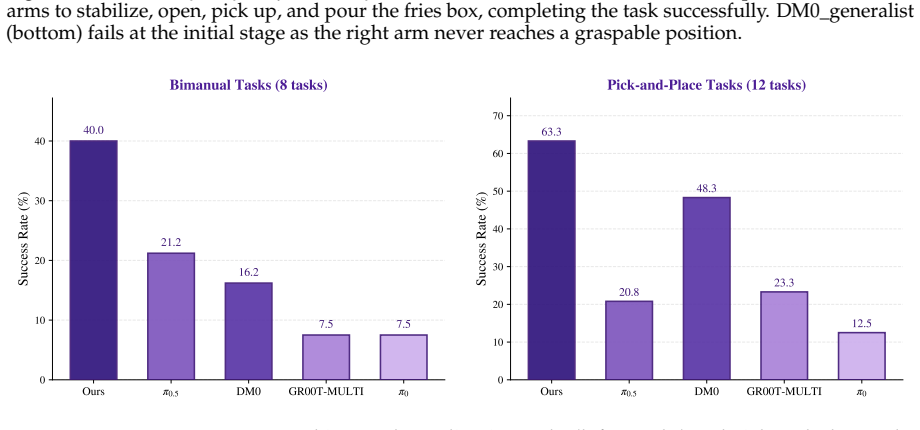
Qwen-RobotManip shows that aligning heterogeneous manipulation data in representation, motion, and behavioral dimensions unlocks the ability to train at a scale previously unsustainable, producing a model with emergent abilities including zero-shot instruction following, robustness to perturbations, reactive error recovery, and cross-embodiment transfer, as demonstrated on OOD settings like RoboCasa365 and LIBERO-Plus where it outperforms state-of-the-art models.
What carries the argument
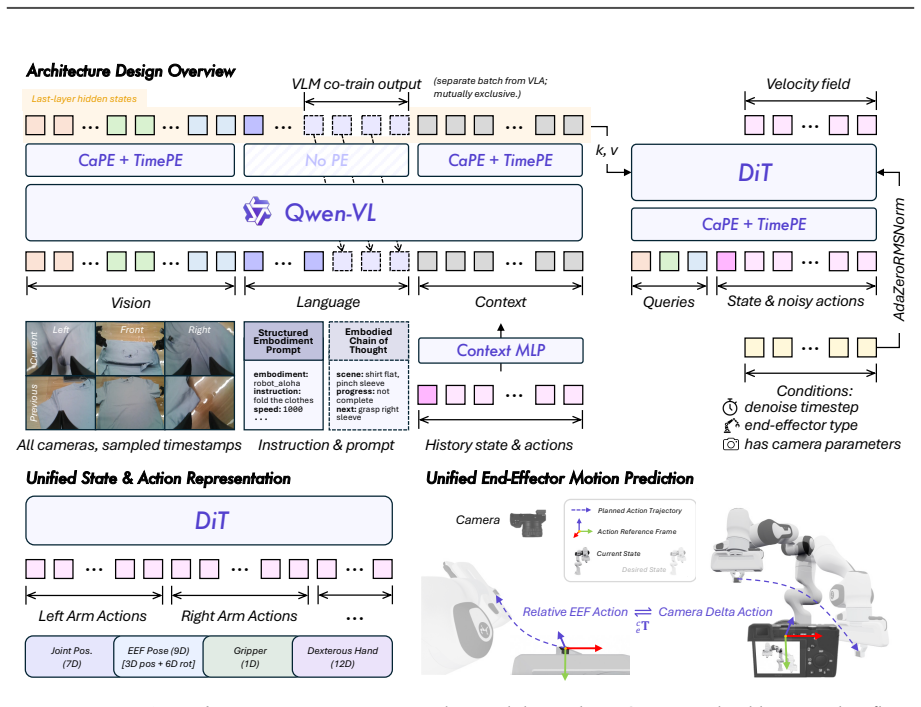
The unified alignment framework across the representation, motion, and behavioral dimensions of manipulation, which harmonizes data for coherent large-scale training.
If this is right
- The model sustains training on ~38,100 hours of pretraining data from open sources without conflicts.
- It exhibits zero-shot instruction following and cross-embodiment transfer.
- It ranks first in RoboChallenge with a 20% relative improvement.
- It is validated on real-robot platforms including AgileX ALOHA, Franka, UR, and ARX.
Where Pith is reading between the lines
- Similar alignment approaches might enable scaling in other embodied AI tasks beyond manipulation.
- Standard benchmarks may need replacement with more challenging OOD tests to measure true generalization.
- Cross-embodiment transfer could reduce the need for embodiment-specific data collection.
Load-bearing premise
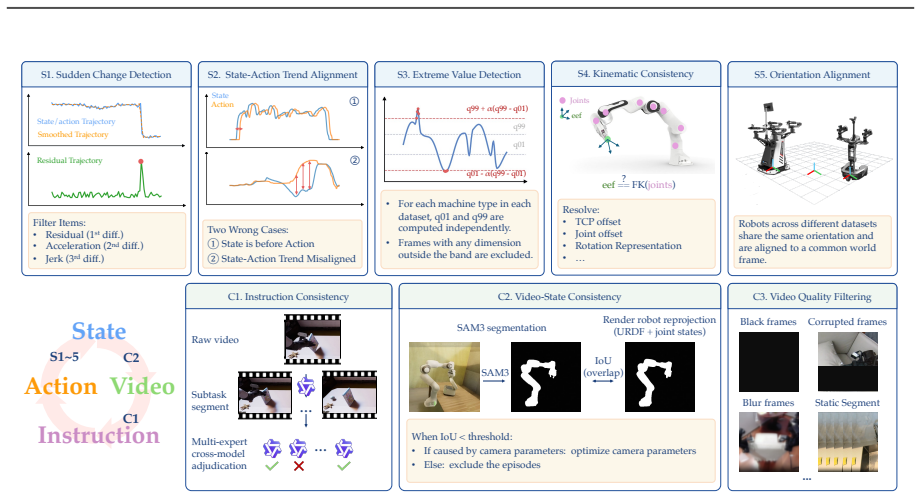
The human-to-robot synthesis pipeline and rigorous curation pipeline convert egocentric hand demonstrations into accurate robot trajectories and harmonize heterogeneous datasets without introducing systematic errors or biases.
What would settle it
A failure to outperform prior models like π0.5 on the OOD benchmarks RoboCasa365 and LIBERO-Plus, or absence of the reported generalization capabilities in real-robot experiments.
Figures









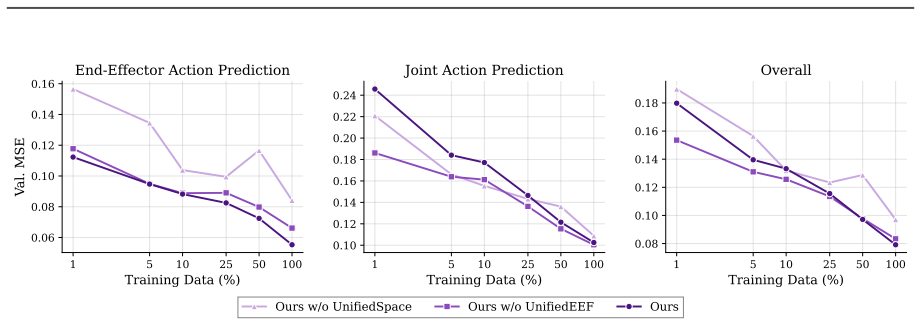
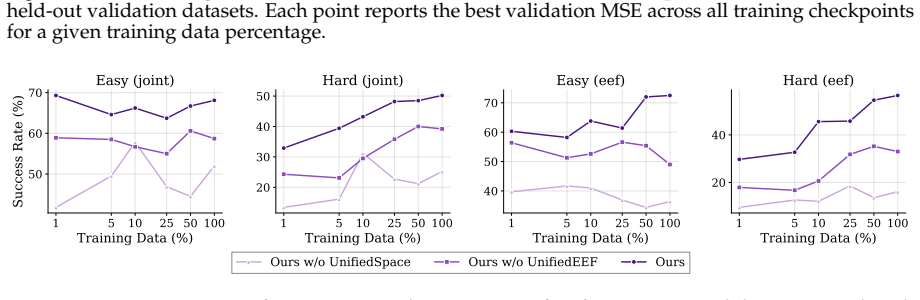
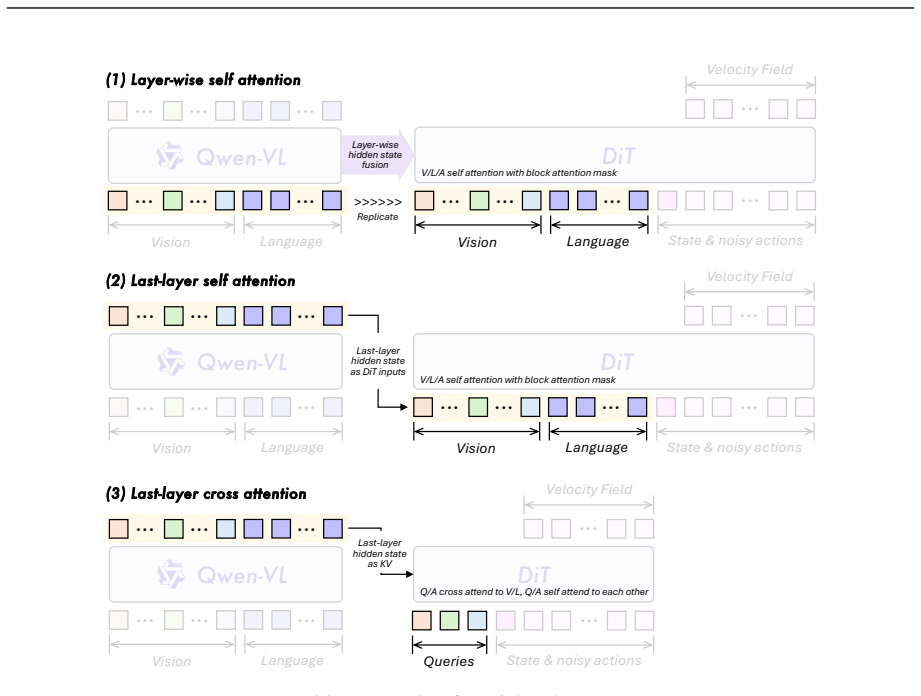
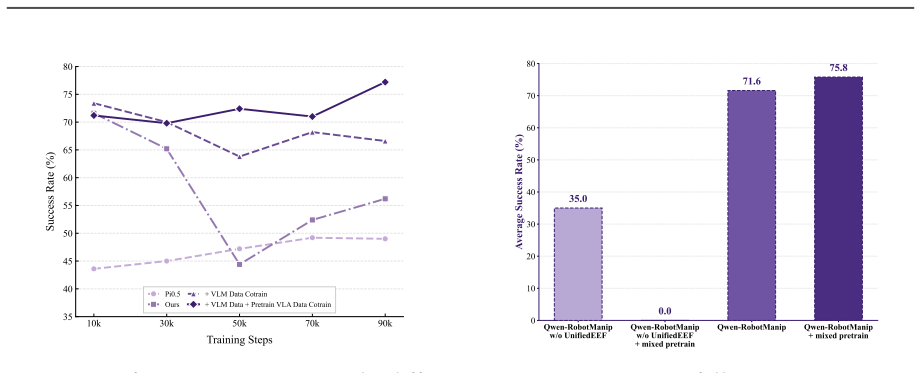
read the original abstract
Foundation models in language and multimodality achieve strong generalization by aligning heterogeneous data under a unified formulation and training at scale. In this report, we investigate whether this scaling recipe can be applied to robotic manipulation to achieve genuine generalization. This is challenging because, unlike text, manipulation data is heterogeneous by nature, expensive to collect, and narrow in diversity, making alignment and scale simultaneously difficult. We present Qwen-RobotManip, a generalizable Vision-Language-Action foundation model built on Qwen-VL. Qwen-RobotManip introduces a unified alignment framework across the representation, motion, and behavioral dimensions of manipulation, making large-scale multi-source training coherent rather than conflicting. This alignment capability in turn enables Qwen-RobotManip to absorb manipulation data at a scale that prior training regimes could not sustain. A human-to-robot synthesis pipeline converts egocentric hand demonstrations into robot trajectories across 15 platforms, and a rigorous curation pipeline harmonizes heterogeneous datasets. Using only open-source datasets and human videos without proprietary data collection, Qwen-RobotManip constructs a ~38,100-hour pretraining corpus and exhibits emergent generalization capabilities, including zero-shot instruction following, robustness to perturbations, reactive error recovery, and cross-embodiment transfer. We find that standard benchmarks fail to capture pretraining quality and instead adopt OOD settings including RoboCasa365, LIBERO-Plus, EBench, RoboTwin-Clean2Rand, RoboTwin-IF, and RoboTwin-XE. Qwen-RobotManip substantially outperforms prior state-of-the-art models, including $\pi$0.5, across all OOD settings, ranks 1st in RoboChallenge with a 20% relative improvement, and is validated on real-robot platforms including AgileX ALOHA, Franka, UR, and ARX.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents Qwen-RobotManip, a vision-language-action foundation model built on Qwen-VL. It introduces a unified alignment framework across representation, motion, and behavioral dimensions of manipulation to enable coherent large-scale multi-source training. A human-to-robot synthesis pipeline converts egocentric hand demonstrations into robot trajectories across 15 platforms, and a curation pipeline harmonizes heterogeneous open-source datasets into a ~38,100-hour pretraining corpus. The model exhibits emergent generalization on OOD benchmarks (RoboCasa365, LIBERO-Plus, EBench, RoboTwin variants) and real-robot platforms (AgileX ALOHA, Franka, UR, ARX), outperforming prior SOTA including π0.5, with 1st place in RoboChallenge.
Significance. If the synthesis and curation pipelines are validated to produce accurate, unbiased trajectories, the result would be significant: it would show that alignment techniques can resolve data heterogeneity in robotics, enabling scale and emergent capabilities (zero-shot following, perturbation robustness, error recovery, cross-embodiment transfer) that prior regimes could not sustain. This would provide concrete evidence that manipulation foundation models can follow scaling laws analogous to language models when trained on harmonized multi-source data.
major comments (2)
- [Abstract / synthesis pipeline description] Abstract and methods description of the human-to-robot synthesis pipeline: the claim that the pipeline 'converts egocentric hand demonstrations into accurate robot trajectories across 15 platforms' is load-bearing for the central claim of coherent scaling and OOD generalization, yet no quantitative validation (trajectory error metrics, kinematic fidelity comparisons, or conversion success rates) is provided; without this, systematic mismatches could render the 38,100-hour corpus invalid and undermine attribution of performance gains to the alignment framework rather than pipeline artifacts.
- [Abstract / curation pipeline description] Abstract and curation pipeline description: the statement that the 'rigorous curation pipeline harmonizes heterogeneous datasets' lacks details on conflict-resolution methods, bias audits, or distribution-shift measurements (e.g., motion or embodiment artifacts); this is required to establish that training is 'coherent rather than conflicting' and that reported gains on RoboCasa365 and LIBERO-Plus are not artifacts of selective filtering.
minor comments (1)
- The 20% relative improvement and 1st-place RoboChallenge ranking should include the exact baseline model, metric, and task definition in the main text or a dedicated table for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the synthesis and curation pipelines. We address the two major comments point by point below and commit to revisions that strengthen the manuscript without altering its core claims.
read point-by-point responses
-
Referee: [Abstract / synthesis pipeline description] Abstract and methods description of the human-to-robot synthesis pipeline: the claim that the pipeline 'converts egocentric hand demonstrations into accurate robot trajectories across 15 platforms' is load-bearing for the central claim of coherent scaling and OOD generalization, yet no quantitative validation (trajectory error metrics, kinematic fidelity comparisons, or conversion success rates) is provided; without this, systematic mismatches could render the 38,100-hour corpus invalid and undermine attribution of performance gains to the alignment framework rather than pipeline artifacts.
Authors: We agree that explicit quantitative validation of the synthesis pipeline is essential to support the load-bearing claim and to enable clear attribution of gains to the alignment framework. The full manuscript describes the pipeline architecture and its application across 15 platforms in the methods, but we did not include aggregated error metrics or success rates in the abstract or a dedicated validation subsection. In the revised manuscript we will add a new subsection reporting trajectory-level metrics (mean joint-position error, end-effector deviation, and per-platform conversion success rates) obtained from held-out validation sets, along with kinematic fidelity comparisons against ground-truth robot executions. These additions will directly address the concern about potential systematic mismatches. revision: yes
-
Referee: [Abstract / curation pipeline description] Abstract and curation pipeline description: the statement that the 'rigorous curation pipeline harmonizes heterogeneous datasets' lacks details on conflict-resolution methods, bias audits, or distribution-shift measurements (e.g., motion or embodiment artifacts); this is required to establish that training is 'coherent rather than conflicting' and that reported gains on RoboCasa365 and LIBERO-Plus are not artifacts of selective filtering.
Authors: We concur that additional transparency on the curation pipeline is required to demonstrate coherence and to rule out selective-filtering artifacts. The manuscript currently summarizes the harmonization steps at a high level but omits explicit conflict-resolution rules, bias-audit protocols, and pre-/post-curation distribution-shift statistics. In revision we will expand the methods section with (i) the priority and merging rules used for overlapping demonstrations, (ii) the bias-audit criteria applied to embodiment and motion statistics, and (iii) quantitative measurements of distribution shift (e.g., Wasserstein distances on velocity histograms and embodiment coverage) before and after curation. These details will allow readers to assess whether the reported OOD gains arise from coherent multi-source training. revision: yes
Circularity Check
No circularity: empirical training report with external OOD evaluation
full rationale
The paper is a technical report describing an empirical training process for Qwen-RobotManip: it introduces a unified alignment framework, applies human-to-robot synthesis and curation pipelines to open-source data, constructs a ~38,100-hour corpus, and reports performance on external OOD benchmarks (RoboCasa365, LIBERO-Plus, EBench, RoboTwin variants, RoboChallenge). No equations, first-principles derivations, or predictions appear in the abstract or described content. No step reduces a claimed result to a fitted parameter or self-citation by construction; the central claims rest on observed generalization rather than definitional equivalence or internal fitting. This is the normal case of a self-contained empirical study.
Axiom & Free-Parameter Ledger
Forward citations
Cited by 2 Pith papers
-
Supervise What Survives: Geometry-Guided VLA Adaptation from Synthetic Robot Videos
GRA extracts 2D waypoints from synthetic videos to supervise VLA vision while restricting action training to real data, outperforming pseudo-action baselines on real-robot tasks.
-
Learning Action Priors for Cross-embodiment Robot Manipulation
A two-stage framework pretrains an action module with temporal motion priors from unconditioned trajectories using flow-matching, then transfers it to VLA training via decoder reuse and distillation, yielding better p...
Reference graph
Works this paper leans on
-
[1]
AgiBot-World-Contributors. AgiBot World Colosseo: A large-scale manipulation platform for scalable and intelligent embodied systems.arXiv preprint arXiv:2503.06669,
-
[2]
Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631,
-
[3]
GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
Johan Bjorck, Fernando Castaneda, Linxi Fan, Dieter Fox, et al. GR00T N1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
-
[4]
π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
-
[5]
Junhao Cai, Zetao Cai, Jiafei Cao, Yilun Chen, Zeyu He, Lei Jiang, Hang Li, Hengjie Li, Yang Li, Yufei Liu, et al. Internvla-a1: Unifying understanding, generation and action for robotic manipulation.arXiv preprint arXiv:2601.02456,
-
[6]
URLhttps://arxiv.org/abs/2511.16719. Justin Carpentier, Guilhem Saurel, Gabriele Buondonno, Joseph Mirabel, Florent Lamiraux, Olivier Stasse, and Nicolas Mansard. The Pinocchio C++ library: A fast and flexible implementation of rigid body dynamics algorithms and their analytical derivatives. InIEEE/SICE International Symposium on System Integration (SII),...
-
[7]
Toward embodiment equivariant vision-language-action policy.arXiv preprint arXiv:2509.14630, 2025a
Anzhe Chen, Yifei Yang, Zhenjie Zhu, Kechun Xu, Zhongxiang Zhou, Rong Xiong, and Yue Wang. Toward embodiment equivariant vision-language-action policy.arXiv preprint arXiv:2509.14630, 2025a. Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data gene...
-
[8]
StarVLA Community. Starvla: A lego-like codebase for vision-language-action model developing.arXiv preprint arXiv:2604.05014,
-
[9]
Vision transformers need registers
39 Timothée Darcet, Maxime Oquab, Julien Mairal, and Piotr Bojanowski. Vision transformers need registers. In B. Kim, Y. Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y. Sun (eds.),International Conference on Learning Representations, volume 2024, pp. 2632–2652,
2024
-
[10]
URL https://proceedings.iclr.cc/ paper_files/paper/2024/file/0b408293619f725fd30162af057e531a-Paper-Conference.pdf. Matt Deitke, Christopher Clark, Sangho Lee, Rohun Tripathi, Yue Yang, Jae Sung Park, Mohammadreza Salehi, Niklas Muennighoff, Kyle Lo, Luca Soldaini, Jiasen Lu, Taira Anderson, Erin Bransom, Kiana Ehsani, Huong Ngo, Yen-Sung Chen, Ajay Patel...
2024
-
[11]
Danny Driess, Jost Tobias Springenberg, Brian Ichter, Lili Yu, Adrian Li-Bell, Karl Pertsch, Allen Z Ren, Homer Walke, Quan Vuong, Lucy Xiaoyang Shi, et al. Knowledge insulating vision-language-action models: Train fast, run fast, generalize better.arXiv preprint arXiv:2505.23705,
-
[12]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models. arXiv:2407.21783,
-
[13]
Molmoact2: Action reasoning models for real-world deployment
Haoquan Fang, Jiafei Duan, Donovan Clay, Sam Wang, Shuo Liu, Weikai Huang, Xiang Fan, Wei-Chuan Tsai, Shirui Chen, Yi Ru Wang, et al. Molmoact2: Action reasoning models for real-world deployment. arXiv preprint arXiv:2605.02881,
-
[14]
Senyu Fei, Siyin Wang, Junhao Shi, Zihao Dai, Jikun Cai, Pengfang Qian, Li Ji, Xinzhe He, Shiduo Zhang, Zhaoye Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626,
-
[15]
Procvlm: Learning procedure-grounded progress rewards for robotic manipulation.CoRR, abs/2605.08774,
Youhe Feng, Hansen Shi, Haoyang Li, Xinlei Guo, Yang Wang, Chengyang Zhang, Jinkai Zhang, Xiaohan Zhang, Jie Tang, and Jing Zhang. Procvlm: Learning procedure-grounded progress rewards for robotic manipulation.CoRR, abs/2605.08774,
-
[16]
Galaxea open-world dataset and G0 dual-system VLA model.arXiv preprint arXiv:2509.00576,
Galaxea AI. Galaxea open-world dataset and G0 dual-system VLA model.arXiv preprint arXiv:2509.00576,
-
[17]
Ryan Hoque, Peide Huang, David J Yoon, Mouli Sivapurapu, and Jian Zhang. Egodex: Learning dexterous manipulation from large-scale egocentric video.arXiv preprint arXiv:2505.11709,
-
[18]
Rldx-1 technical report.arXiv preprint arXiv:2605.03269, 2026a
Dongyoung Kim, Huiwon Jang, Myungkyu Koo, Suhyeok Jang, Taeyoung Kim, Beomjun Kim, Byungjun Yoon, Changsung Jang, Daewon Choi, Dongsu Han, et al. Rldx-1 technical report.arXiv preprint arXiv:2605.03269, 2026a. Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi...
-
[19]
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645,
-
[20]
Moo Jin Kim, Yihuai Gao, Tsung-Yi Lin, Yen-Chen Lin, Yunhao Ge, Grace Lam, Percy Liang, Shuran Song, Ming-Yu Liu, Chelsea Finn, et al. Cosmos policy: Fine-tuning video models for visuomotor control and planning.arXiv preprint arXiv:2601.16163, 2026b. Xin Kong, Shikun Liu, Xiaoyang Lyu, Marwan Taher, Xiaojuan Qi, and Andrew J. Davison. EscherNet: A generat...
-
[21]
URL https:// internrobotics.github.io/EBench-doc/. Zixing Lei, Changxing Liu, Yichen Xiong, Minhao Xiong, Yuanzhuo Ding, Zhipeng Zhang, Weixin Li, and Siheng Chen. Towards long-horizon embodied agents with tool-aligned vision-language-action models.arXiv preprint arXiv:2605.13119,
-
[22]
Marion Lepert, Jiaying Fang, and Jeannette Bohg. Masquerade: Learning from in-the-wild human videos using data-editing.arXiv preprint arXiv:2508.09976, 2025a. Marion Lepert, Jiaying Fang, and Jeannette Bohg. Phantom: Training robots without robots using only human videos.arXiv preprint arXiv:2503.00779, 2025b. Hao Li, Ziqin Wang, Zi-Han Ding, Shuai Yang, ...
-
[23]
Qixiu Li, Yu Deng, Yaobo Liang, Lin Luo, Lei Zhou, Chengtang Yao, Lingqi Zeng, Zhiyuan Feng, Huizhi Liang, Sicheng Xu, et al. Scalable vision-language-action model pretraining for robotic manipulation with real-life human activity videos.arXiv preprint arXiv:2510.21571, 2025a. Ruilong Li, Brent Yi, Junchen Liu, Hang Gao, Yi Ma, and Angjoo Kanazawa. Camera...
-
[24]
Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
Haotong Lin, Sili Chen, Junhao Liew, Donny Y Chen, Zhenyu Li, Guang Shi, Jiashi Feng, and Bingyi Kang. Depth anything 3: Recovering the visual space from any views.arXiv preprint arXiv:2511.10647,
-
[25]
Bo Liu, Yifeng Zhu, Chongkai Gao, Yihao Feng, Qiang Liu, Yuke Zhu, and Peter Stone. Libero: Bench- marking knowledge transfer for lifelong robot learning.arXiv preprint arXiv:2306.03310,
-
[26]
Hao Luo, Yicheng Feng, Wanpeng Zhang, Sipeng Zheng, Ye Wang, Haoqi Yuan, Jiazheng Liu, Chaoyi Xu, Qin Jin, and Zongqing Lu. Being-h0: vision-language-action pretraining from large-scale human videos.arXiv preprint arXiv:2507.15597,
-
[27]
Joint-aligned latent action: Towards scalable vla pretraining in the wild
Hao Luo, Ye Wang, Wanpeng Zhang, Haoqi Yuan, Yicheng Feng, Haiweng Xu, Sipeng Zheng, and Zongqing Lu. Joint-aligned latent action: Towards scalable vla pretraining in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 35047–35058, 2026a. Hao Luo, Ye Wang, Wanpeng Zhang, Sipeng Zheng, Ziheng Xi, Chaoyi Xu, Ha...
-
[28]
Robotwin: Dual-arm robot benchmark with generative digital twins.arXiv preprint arXiv:2501.00062,
Yao Mu, Tianxing Chen, Zan Ding, et al. Robotwin: Dual-arm robot benchmark with generative digital twins.arXiv preprint arXiv:2501.00062,
-
[29]
Gpt-4 technical report.arXiv:2303.08774,
OpenAI. Gpt-4 technical report.arXiv:2303.08774,
-
[30]
Ryan Punamiya, Simar Kareer, Zeyi Liu, Josh Citron, Ri-Zhao Qiu, Xiongyi Cai, Alexey Gavryushin, Jiaqi Chen, Davide Liconti, Lawrence Y Zhu, et al. Egoverse: An egocentric human dataset for robot learning from around the world.arXiv preprint arXiv:2604.07607,
-
[31]
Humanoid policy˜ human policy.arXiv preprint arXiv:2503.13441,
Ri-Zhao Qiu, Shiqi Yang, Xuxin Cheng, Chaitanya Chawla, Jialong Li, Tairan He, Ge Yan, David J Yoon, Ryan Hoque, Lars Paulsen, et al. Humanoid policy˜ human policy.arXiv preprint arXiv:2503.13441,
-
[32]
Embodied hands: Modeling and capturing hands and bodies together.arXiv preprint arXiv:2201.02610,
Javier Romero, Dimitrios Tzionas, and Michael J Black. Embodied hands: Modeling and capturing hands and bodies together.arXiv preprint arXiv:2201.02610,
-
[33]
Gemini: A family of highly capable multimodal models.arXiv:2312.11805,
42 Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, et al. Gemini: A family of highly capable multimodal models.arXiv:2312.11805,
-
[34]
URL https://qwen.ai/blog?id=qwen3.5. Yang Tian, Yuyin Yang, Yiman Xie, Zetao Cai, Xu Shi, Ning Gao, Hangxu Liu, Xuekun Jiang, Zherui Qiu, Feng Yuan, Yaping Li, Ping Wang, Junhao Cai, Jia Zeng, Hao Dong, and Jiangmiao Pang. InternData-A1: Pioneering high-fidelity synthetic data for pre-training generalist policy.arXiv preprint arXiv:2511.16651,
-
[35]
Mujoco: A physics engine for model-based control
Emanuel Todorov, Tom Erez, and Yuval Tassa. Mujoco: A physics engine for model-based control. In 2012 IEEE/RSJ international conference on intelligent robots and systems, pp. 5026–5033. IEEE,
2012
-
[36]
Ye Wang, Sipeng Zheng, Hao Luo, Wanpeng Zhang, Haoqi Yuan, Chaoyi Xu, Haiweng Xu, Yicheng Feng, Mingyang Yu, Zhiyu Kang, et al. Rethinking visual-language-action model scaling: Alignment, mixture, and regularization.arXiv preprint arXiv:2602.09722,
-
[37]
RoboMIND: Benchmark on multi- embodiment intelligence normative data for robot manipulation
Kun Wu, Chengkai Hou, Jiaming Liu, Zhengping Che, et al. RoboMIND: Benchmark on multi- embodiment intelligence normative data for robot manipulation. InRobotics: Science and Systems (RSS), 2025a. Kun Wu et al. RoboMIND 2.0: A multimodal, bimanual mobile manipulation dataset for generalizable embodied intelligence.arXiv preprint arXiv:2512.24653, 2025b. Sh...
-
[38]
Qwen3 technical report.arXiv preprint arXiv:2505.09388,
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388,
-
[39]
Yandan Yang, Shuang Zeng, Tong Lin, Xinyuan Chang, Dekang Qi, Junjin Xiao, Haoyun Liu, Ronghan Chen, Yuzhi Chen, Dongjie Huo, et al. Abot-m0: Vla foundation model for robotic manipulation with action manifold learning.arXiv preprint arXiv:2602.11236,
-
[40]
Capsfusion: Rethinking image-text data at scale
Qiying Yu, Quan Sun, Xiaosong Zhang, Yufeng Cui, Fan Zhang, Yue Cao, Xinlong Wang, and Jingjing Liu. Capsfusion: Rethinking image-text data at scale. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024,
2024
-
[41]
Robopoint: A vision-language model for spatial affordance prediction in robotics
Wentao Yuan, Jiafei Duan, Valts Blukis, Wilbert Pumacay, Ranjay Krishna, Adithyavairavan Murali, Arsalan Mousavian, and Dieter Fox. Robopoint: A vision-language model for spatial affordance prediction in robotics. InConference on Robot Learning, 6-9 November 2024, Munich, Germany,
2024
-
[42]
URL https://github. com/kevinzakka/mink. Michał Zawalski, William Chen, Karl Pertsch, Oier Mees, Chelsea Finn, and Sergey Levine. Robotic control via embodied chain-of-thought reasoning.arXiv preprint arXiv:2407.08693,
-
[43]
Tao Zhang, Song Xia, Ye Wang, and Qin Jin. Easymimic: A low-cost framework for robot imitation learning from human videos.arXiv preprint arXiv:2602.11464, 2026a. Tianyi Zhang, Haonan Duan, Haoran Hao, Yu Qiao, Jifeng Dai, and Zhi Hou. Grounding actions in camera space: Observation-centric vision-language-action policy. InProceedings of the AAAI Conference...
-
[44]
43 Jinliang Zheng, Jianxiong Li, Zhihao Wang, Dongxiu Liu, Xirui Kang, Yuchun Feng, Yinan Zheng, Jiayin Zou, Yilun Chen, Jia Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274,
-
[45]
Ruijie Zheng, Dantong Niu, Yuqi Xie, Jing Wang, Mengda Xu, Yunfan Jiang, Fernando Castañeda, Fengyuan Hu, You Liang Tan, Letian Fu, et al. Egoscale: Scaling dexterous manipulation with diverse egocentric human data.arXiv preprint arXiv:2602.16710,
-
[46]
Enshen Zhou, Jingkun An, Cheng Chi, Yi Han, Shanyu Rong, Chi Zhang, Pengwei Wang, Zhongyuan Wang, Tie-Jun Huang, Lu Sheng, and Shanghang Zhang. Roborefer: Towards spatial referring with reasoning in vision-language models for robotics.CoRR, abs/2506.04308,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.