WHU-Infra3D: A Full-stack Multi-modal Dataset and Benchmark for 3D Roadside Infrastructure Inventory
Pith reviewed 2026-06-28 06:57 UTC · model grok-4.3
The pith
WHU-Infra3D supplies aligned panoramic images, LiDAR scans, and 181k status annotations across 53.8 km to support automated roadside infrastructure health assessment.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
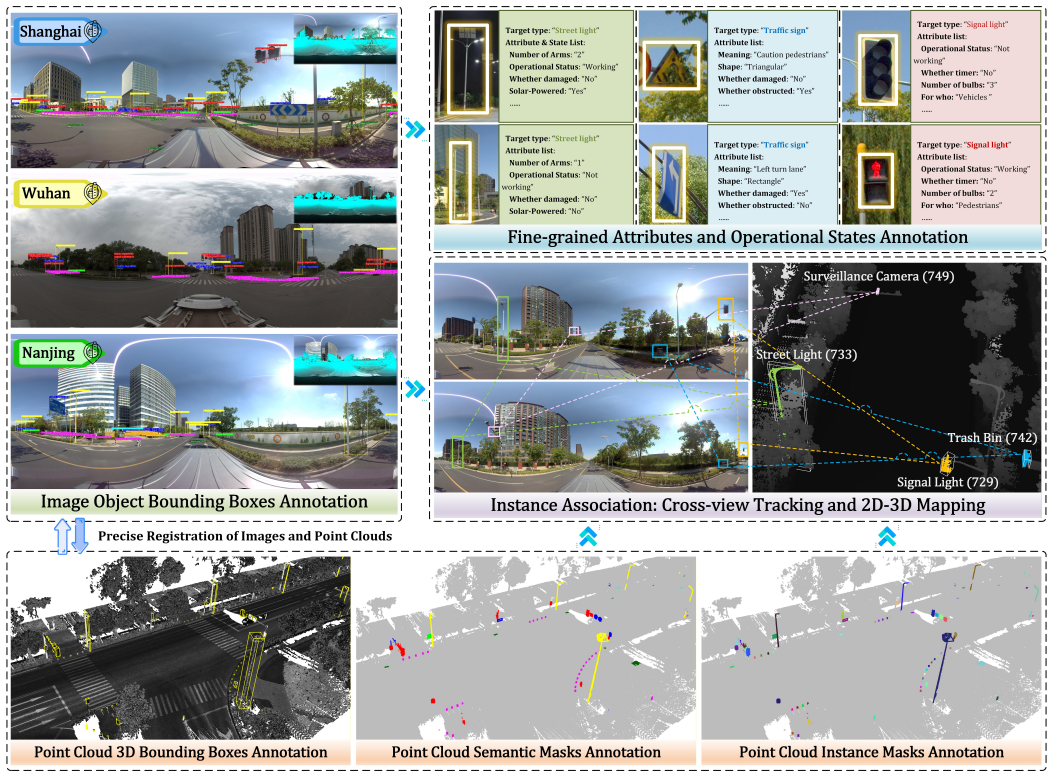
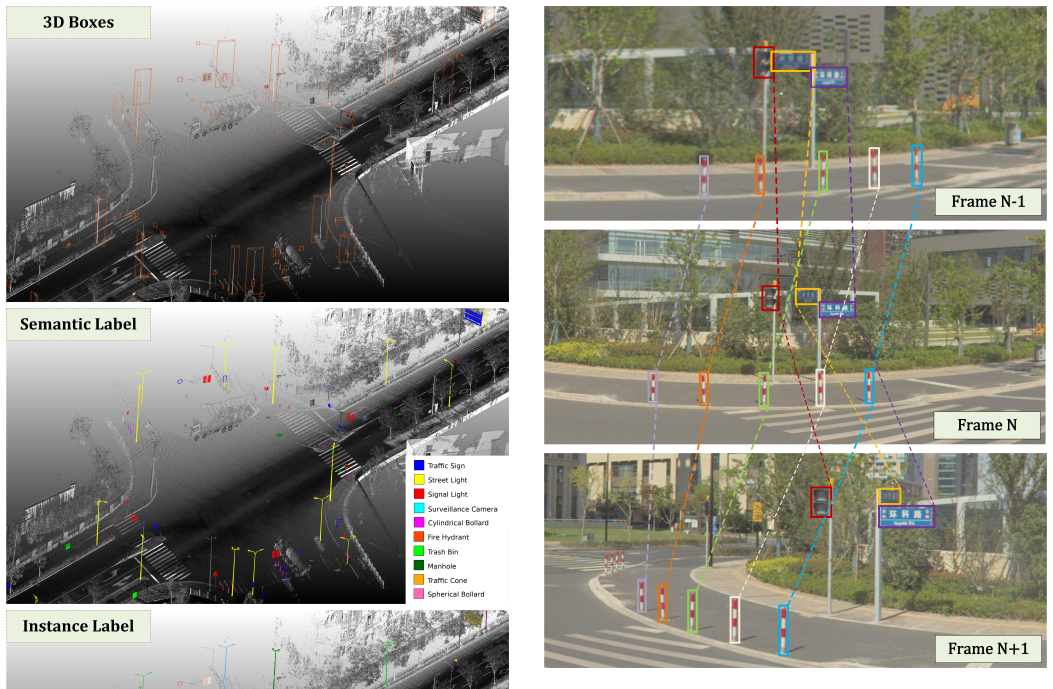
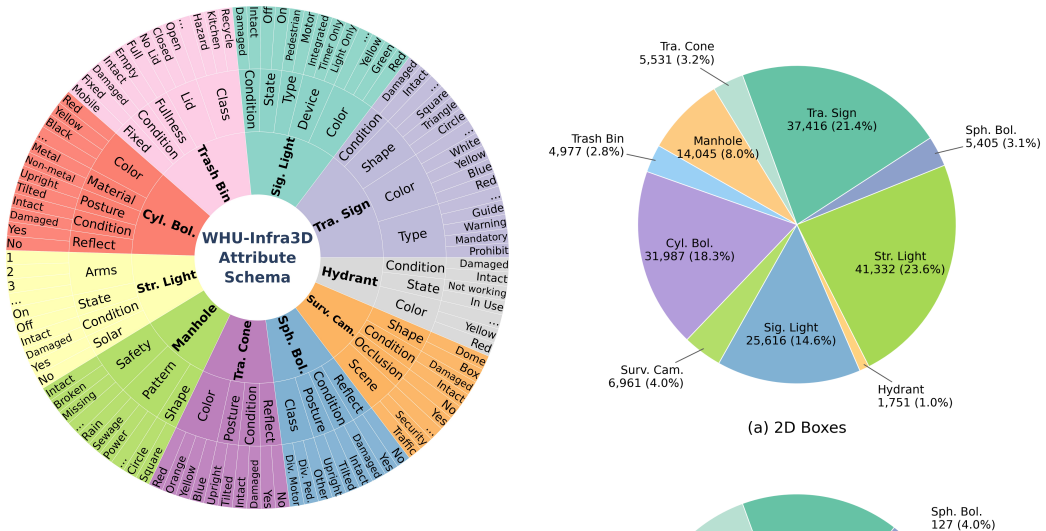
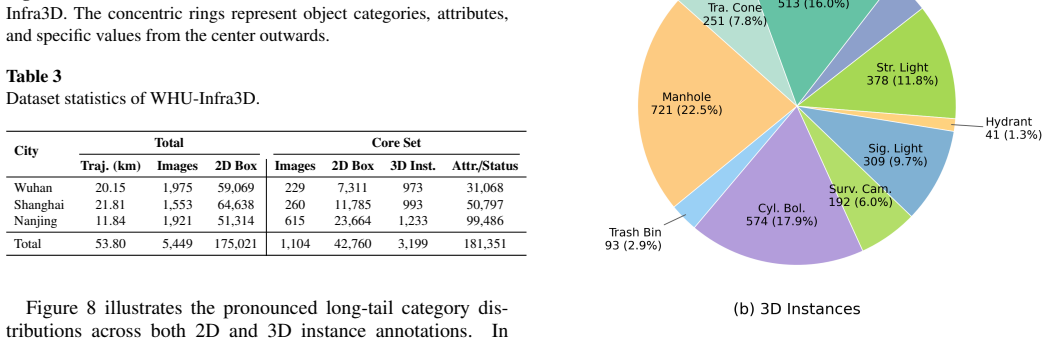
WHU-Infra3D integrates panoramic imagery and LiDAR point clouds with rigorous 2D-3D instance association and cross-frame tracking, supplying over 181k attribute and status annotations on more than 175k multi-view 2D boxes and thousands of 3D instances to serve as a benchmark for 3D roadside infrastructure inventory and operational health assessment.
What carries the argument
Rigorous 2D-3D instance association combined with cross-frame tracking that connects multi-view 2D bounding boxes to 3D infrastructure objects and their status labels.
If this is right
- Baselines can be run on 2D detection, 2D cross-view matching, 3D geo-identification, 3D point cloud segmentation, and attribute recognition.
- Current models exhibit measurable performance drops across cities.
- Current models are weaker on long-tailed defective status classes.
- The annotations directly support diagnosis of operational health for urban assets.
Where Pith is reading between the lines
- Cities could use models trained on the dataset to rank maintenance priorities by automatically flagging defects.
- The 2D-3D links could support time-series tracking of individual assets across repeated surveys.
- Adding more cities or sensor types would test whether the observed domain gaps shrink.
Load-bearing premise
The data collected from three cities and the annotation process produce representative samples of real infrastructure conditions with accurate 2D-3D links that apply beyond the collection sites.
What would settle it
Models trained on WHU-Infra3D showing no improvement over prior datasets when tested on maintenance records or new cities would falsify the claim that the added alignments and status labels advance operational assessment.
Figures




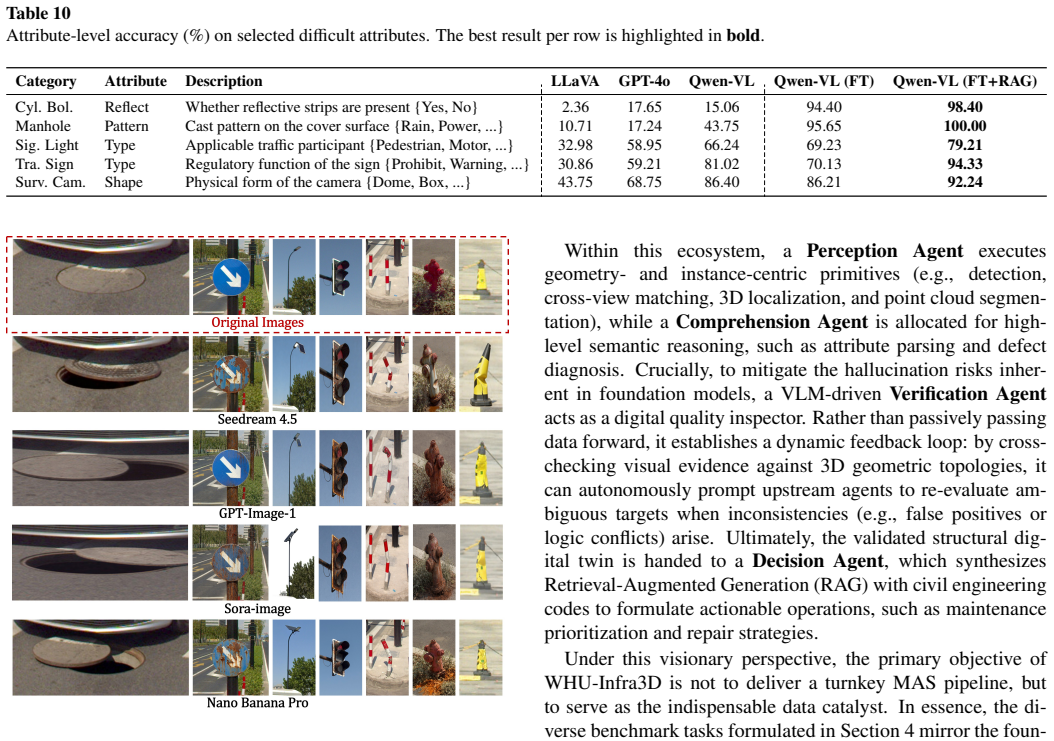
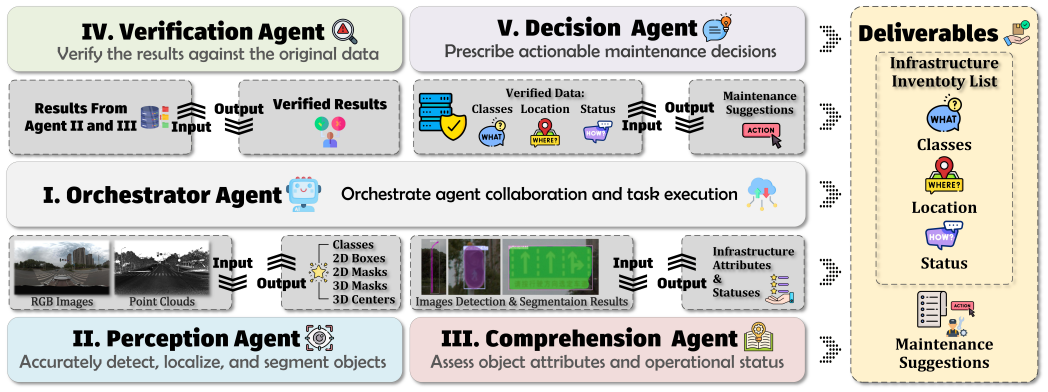
read the original abstract
The paradigm of digital twin cities is shifting from coarse visual mapping toward more precise and actionable digitization of urban assets. However, existing datasets predominantly focus on coarse visual perception, lacking the strict multi-modal alignment and attribute and status diagnosis required for automated infrastructure maintenance. To bridge this gap, we introduce WHU-Infra3D, a large-scale, multi-modal benchmark dataset dedicated to roadside infrastructure inventory. Covering 53.8 km across three cities, WHU-Infra3D uniquely integrates panoramic imagery and LiDAR point clouds with rigorous 2D-3D instance association and cross-frame tracking. Comprising over 175k multi-view 2D bounding boxes alongside thousands of 3D infrastructure instances, the dataset provides over 181k detailed attribute and status annotations (e.g., rust, occlusion) to empower operational health assessment. We establish comprehensive baselines across five core tasks: 2D detection, 2D cross-view matching, 3D geo-identification, 3D point cloud segmentation, and attribute recognition. Extensive evaluations expose significant cross-city domain gaps and inherent vulnerabilities of current models on long-tailed defective statuses, establishing WHU-Infra3D as an essential testbed for advancing scalable, AI-driven urban infrastructure inventory and lifecycle management. The WHU-Infra3D dataset is available at https://github.com/WHU-USI3DV/WHU-Infra3D.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces WHU-Infra3D, a large-scale multi-modal dataset for 3D roadside infrastructure inventory covering 53.8 km across three cities. It integrates panoramic imagery and LiDAR point clouds with claimed rigorous 2D-3D instance association and cross-frame tracking, providing over 175k multi-view 2D bounding boxes, thousands of 3D instances, and over 181k attribute/status annotations (e.g., rust, occlusion). Baselines are reported for five tasks (2D detection, 2D cross-view matching, 3D geo-identification, 3D point cloud segmentation, attribute recognition) that expose cross-city domain gaps and model vulnerabilities on long-tailed defective statuses. The dataset is released via GitHub.
Significance. If the 2D-3D associations and status labels prove accurate and representative, the dataset would offer a useful benchmark for infrastructure inventory tasks by supplying scale, multi-modal alignment, and explicit focus on defective conditions that current models struggle with, thereby supporting research on operational health assessment and cross-domain robustness.
major comments (1)
- [Abstract] Abstract: the central claims that the dataset supplies 'rigorous 2D-3D instance association' and 'detailed attribute and status annotations' sufficient to 'empower operational health assessment' and 'expose significant cross-city domain gaps' rest on unverified annotation quality. No annotation protocol, inter-annotator agreement statistics, expert-review sampling rate, or quantitative error analysis for the 3D instance linking step is supplied; without these the distinction between genuine long-tailed defective distributions and annotation bias or association noise cannot be made.
minor comments (1)
- [Abstract] Abstract: the figures 'over 175k multi-view 2D bounding boxes' and 'over 181k detailed attribute and status annotations' are presented without clarifying their exact relationship or overlap; a brief parenthetical or table reference would improve precision.
Simulated Author's Rebuttal
We thank the referee for the constructive comment on annotation transparency. We agree that additional details on the annotation process are needed to support the claims and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claims that the dataset supplies 'rigorous 2D-3D instance association' and 'detailed attribute and status annotations' sufficient to 'empower operational health assessment' and 'expose significant cross-city domain gaps' rest on unverified annotation quality. No annotation protocol, inter-annotator agreement statistics, expert-review sampling rate, or quantitative error analysis for the 3D instance linking step is supplied; without these the distinction between genuine long-tailed defective distributions and annotation bias or association noise cannot be made.
Authors: We acknowledge the referee's point that the current version does not provide sufficient documentation of annotation quality controls. In the revised manuscript we will add a dedicated subsection (likely in Section 3) that describes: (1) the full annotation protocol for 2D boxes, 3D instance linking, and attribute/status labels; (2) inter-annotator agreement statistics (e.g., Cohen's kappa or average IoU on overlapping annotations); (3) the sampling rate and criteria for expert review; and (4) any quantitative error analysis performed on the 3D association step (e.g., manual verification on a held-out subset). These additions will allow readers to better evaluate potential annotation bias versus genuine long-tailed distributions. revision: yes
Circularity Check
No circularity: empirical dataset paper with no derivations or fitted predictions
full rationale
The paper introduces a multi-modal dataset and benchmark for infrastructure inventory, reporting collection over 53.8 km, 175k 2D boxes, thousands of 3D instances, and 181k annotations, plus baseline results on five tasks. No equations, parameter fitting, predictions derived from inputs, or self-citation chains appear in the abstract or described content. The central claims rest on empirical data release and standard benchmark evaluations rather than any reduction of outputs to inputs by construction. This is the expected non-finding for a dataset paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Caesar, V
H. Caesar, V . Bankiti, A. H. Lang, S. V ora, V . E. Li- ong, Q. Xu, A. Krishnan, Y . Pan, G. Baldan, O. Beijbom, nuscenes: A multimodal dataset for autonomous driving, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11621–11631
2020
-
[2]
Cordts, M
M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. En- zweiler, R. Benenson, U. Franke, S. Roth, B. Schiele, The cityscapes dataset for semantic urban scene understand- ing, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 3213–3223
2016
-
[3]
T. Hackel, N. Savinov, L. Ladicky, J. D. Wegner, K. Schindler, M. Pollefeys, Semantic3d. net: A new large- scale point cloud classification benchmark, arXiv preprint arXiv:1704.03847 (2017)
Pith/arXiv arXiv 2017
-
[4]
Z. Zhu, D. Liang, S. Zhang, X. Huang, B. Li, S. Hu, Traffic-sign detection and classification in the wild, in: Proceedings of the IEEE conference on computer vision and pattern recognition, 2016, pp. 2110–2118
2016
-
[5]
Wilson, T
D. Wilson, T. Alshaabi, C. Van Oort, X. Zhang, J. Nel- son, S. Wshah, Object tracking and geo-localization from street images, Remote Sensing 14 (2022) 2575
2022
-
[6]
Geiger, P
A. Geiger, P. Lenz, R. Urtasun, Are we ready for au- tonomous driving? the kitti vision benchmark suite, in: 2012 IEEE conference on computer vision and pattern recognition, IEEE, 2012, pp. 3354–3361. 14
2012
-
[7]
P. Sun, H. Kretzschmar, X. Dotiwalla, A. Chouard, V . Pat- naik, P. Tsui, J. Guo, Y . Zhou, Y . Chai, B. Caine, et al., Scalability in perception for autonomous driving: Waymo open dataset, in: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition, 2020, pp. 2446–2454
2020
-
[8]
Y . Liao, J. Xie, A. Geiger, Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d, IEEE Transactions on Pattern Analysis and Machine Intelligence 45 (2022) 3292–3310
2022
-
[9]
B. Wilson, W. Qi, T. Agarwal, J. Lambert, J. Singh, S. Khandelwal, B. Pan, R. Kumar, A. Hartnett, J. K. Pontes, et al., Argoverse 2: Next generation datasets for self-driving perception and forecasting, arXiv preprint arXiv:2301.00493 (2023)
Pith/arXiv arXiv 2023
-
[10]
Vallet, M
B. Vallet, M. Brédif, A. Serna, B. Marcotegui, N. Papar- oditis, Terramobilita/iqmulus urban point cloud analysis benchmark, Computers & Graphics 49 (2015) 126–133
2015
-
[11]
Neuhold, T
G. Neuhold, T. Ollmann, S. Rota Bulo, P. Kontschieder, The mapillary vistas dataset for semantic understanding of street scenes, in: Proceedings of the IEEE international conference on computer vision, 2017, pp. 4990–4999
2017
-
[12]
Roynard, J.-E
X. Roynard, J.-E. Deschaud, F. Goulette, Paris-lille- 3d: A large and high-quality ground-truth urban point cloud dataset for automatic segmentation and classifica- tion, The International Journal of Robotics Research 37 (2018) 545–557
2018
-
[13]
Behley, M
J. Behley, M. Garbade, A. Milioto, J. Quenzel, S. Behnke, C. Stachniss, J. Gall, Semantickitti: A dataset for seman- tic scene understanding of lidar sequences, in: Proceed- ings of the IEEE/CVF international conference on com- puter vision, 2019, pp. 9297–9307
2019
-
[14]
W. Tan, N. Qin, L. Ma, Y . Li, J. Du, G. Cai, K. Yang, J. Li, Toronto-3d: A large-scale mobile lidar dataset for seman- tic segmentation of urban roadways, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 202–203
2020
-
[15]
X. Han, C. Liu, Y . Zhou, K. Tan, Z. Dong, B. Yang, Whu- urban3d: An urban scene lidar point cloud dataset for semantic instance segmentation, ISPRS Journal of Pho- togrammetry and Remote Sensing 209 (2024) 500–513
2024
-
[16]
Houben, J
S. Houben, J. Stallkamp, J. Salmen, M. Schlipsing, C. Igel, Detection of traffic signs in real-world images: The german traffic sign detection benchmark, in: The 2013 international joint conference on neural networks (IJCNN), Ieee, 2013, pp. 1–8
2013
-
[17]
Almutairy, T
F. Almutairy, T. Alshaabi, J. Nelson, S. Wshah, Arts: Au- tomotive repository of traffic signs for the united states, IEEE Transactions on Intelligent Transportation Systems 22 (2019) 457–465
2019
-
[18]
Chaabane, L
M. Chaabane, L. Gueguen, A. Trabelsi, R. Beveridge, S. O’Hara, End-to-end learning improves static object geo-localization from video, in: Proceedings of the IEEE/CVF Winter Conference on Applications of Com- puter Vision, 2021, pp. 2063–2072
2021
-
[19]
C. Liu, M. Xie, C. Yuan, F. Liang, Z. Dong, B. Yang, Training-free open-set 3d inventory of transportation in- frastructure by combining point clouds and images, Au- tomation in Construction 178 (2025) 106377
2025
-
[20]
Deep Residual Learning for Image Recognition
J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, in: 2016 IEEE Conference on Computer Vision and Pattern Recog- nition (CVPR), 2016, pp. 779–788. doi:10.1109/CVPR. 2016.91
-
[21]
S. Eri¸ sen, Sernet-former: Segmentation by efficient- resnet with attention-boosting gates and attention-fusion networks, in: IEEE International Conference on Com- puter Vision and Machine Intelligence, IEEE, 2024, pp. 1–6. doi:10.1109/cvmi61877.2024.10782648
-
[22]
W. Liu, D. Anguelov, D. Erhan, C. Szegedy, S. Reed, C.- Y . Fu, A. C. Berg, Ssd: Single shot multibox detector, in: Proceedings of the 2016 European Conference on Com- puter Vision (ECCV), 2016, pp. 21–37
2016
-
[23]
J. Jain, J. Li, M. T. Chiu, A. Hassani, N. Orlov, H. Shi, Oneformer: One transformer to rule universal image seg- mentation, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 2989–2998. doi:10.1109/cvpr52729.2023.00292
-
[24]
L. H. Li, P. Zhang, H. Zhang, J. Yang, C. Li, Y . Zhong, L. Wang, L. Yuan, L. Zhang, J.-N. Hwang, et al., Grounded language-image pre-training, in: Proceedings of the IEEE/CVF conference on computer vision and pat- tern recognition, 2022, pp. 10965–10975
2022
-
[26]
T. Ren, Q. Jiang, S. Liu, Z. Zeng, W. Liu, H. Gao, H. Huang, Z. Ma, X. Jiang, Y . Chen, Y . Xiong, H. Zhang, F. Li, P. Tang, K. Yu, L. Zhang, Grounding dino 1.5: Advance the" edge" of open-set object detection, arXiv preprint arXiv:2405.10300 (2024). doi:10.48550/ arXiv.2405.10300
arXiv 2024
-
[27]
T. Ren, Y . Chen, Q. Jiang, Z. Zeng, Y . Xiong, W. Liu, Z. Ma, J. Shen, Y . Gao, X. Jiang, et al., Dino-x: A unified vision model for open-world object detection and under- standing, arXiv preprint arXiv:2411.14347 (2024). 15
arXiv 2024
-
[28]
Q. Jiang, F. Li, Z. Zeng, T. Ren, S. Liu, L. Zhang, T- rex2: Towards generic object detection via text-visual prompt synergy, in: Proceedings of the European Con- ference on Computer Vision, Springer, 2024, pp. 38–57. doi:10.1007/978-3-031-73232-4
-
[29]
Kirillov, E
A. Kirillov, E. Mintun, N. Ravi, H. Mao, C. Rolland, L. Gustafson, T. Xiao, S. Whitehead, A. C. Berg, W.-Y . Lo, et al., Segment anything, in: Proceedings of the IEEE/CVF international conference on computer vision, 2023, pp. 4015–4026
2023
-
[30]
N. Ravi, V . Gabeur, Y .-T. Hu, R. Hu, C. Ryali, T. Ma, H. Khedr, R. Rädle, C. Rolland, L. Gustafson, et al., Sam 2: Segment anything in images and videos, arXiv preprint arXiv:2408.00714 (2024)
Pith/arXiv arXiv 2024
-
[31]
N. Carion, L. Gustafson, Y .-T. Hu, S. Debnath, R. Hu, D. Suris, C. Ryali, K. V . Alwala, H. Khedr, A. Huang, et al., Sam 3: Segment anything with concepts, arXiv preprint arXiv:2511.16719 (2025)
Pith/arXiv arXiv 2025
-
[32]
Wojke, A
N. Wojke, A. Bewley, D. Paulus, Simple online and realtime tracking with a deep association metric, in: 2017 IEEE international conference on image processing (ICIP), IEEE, 2017, pp. 3645–3649
2017
-
[33]
Meinhardt, A
T. Meinhardt, A. Kirillov, L. Leal-Taixe, C. Feichtenhofer, Trackformer: Multi-object tracking with transformers, in: Proceedings of the IEEE/CVF conference on computer vi- sion and pattern recognition, 2022, pp. 8844–8854
2022
-
[34]
V . A. Krylov, E. Kenny, R. Dahyot, Automatic discov- ery and geotagging of objects from street view imagery, Remote Sensing 10 (2018) 661
2018
-
[35]
A. S. Nassar, S. Lefèvre, J. D. Wegner, Simultaneous multi-view instance detection with learned geometric soft- constraints, in: Proceedings of the IEEE/CVF interna- tional conference on computer vision, 2019, pp. 6559– 6568
2019
-
[36]
A. S. Nassar, S. D’aronco, S. Lefèvre, J. D. Wegner, Geo- graph: Graph-based multi-view object detection with ge- ometric cues end-to-end, in: European Conference on Computer Vision, Springer, 2020, pp. 488–504
2020
-
[37]
C. Liu, L. Fu, Y . Jia, Z. Dong, B. Yang, Svii-3d: Advanc- ing roadside infrastructure inventory with decimeter-level 3d localization and comprehension from sparse street imagery, 2026. URL:https://arxiv.org/abs/2601. 10535.arXiv:2601.10535
arXiv 2026
-
[38]
Campbell, A
A. Campbell, A. Both, Q. C. Sun, Detecting and map- ping traffic signs from google street view images using deep learning and gis, Computers, Environment and Ur- ban Systems 77 (2019) 101350
2019
-
[39]
Z. Wang, L. Yang, Y . Sheng, M. Shen, Pole-like ob- jects segmentation and multiscale classification-based fu- sion from mobile point clouds in road scenes, Remote Sensing 13 (2021) 4382. doi:10.3390/rs13214382
-
[40]
J. Li, X. Cheng, Supervoxel-based extraction and clas- sification of pole-like objects from mls point cloud data, Optics & Laser Technology 146 (2022) 107562. doi:10. 1016/j.optlastec.2021.107562
arXiv 2022
-
[41]
F. Li, M. Lehtomäki, S. O. Elberink, G. V osselman, A. Kukko, E. Puttonen, Y . Chen, J. Hyyppä, Semantic seg- mentation of road furniture in mobile laser scanning data, ISPRS Journal of Photogrammetry and Remote Sensing 154 (2019) 98–113. doi:10.1016/j.isprsjprs.2019. 06.001
-
[42]
Truong-Hong, R
L. Truong-Hong, R. Lindenbergh, M. Vermeij, Efficient sparse street furniture extraction from mobile laser scanning point clouds, Interna- tional Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences-ISPRS Archives 48 (2022) 161–168. doi:10.5194/ isprs-archives-xlviii-4-w4-2022-161-2022
2022
-
[43]
C. R. Qi, L. Yi, H. Su, L. J. Guibas, Pointnet++: Deep hi- erarchical feature learning on point sets in a metric space, arXiv preprint arXiv:1706.02413 (2017). doi:10.48550/ arXiv.1706.02413
Pith/arXiv arXiv 2017
-
[44]
Thomas, C
H. Thomas, C. R. Qi, J.-E. Deschaud, B. Marcotegui, F. Goulette, L. J. Guibas, Kpconv: Flexible and de- formable convolution for point clouds, in: Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6411–6420
2019
-
[45]
C. Choy, J. Gwak, S. Savarese, 4d spatio-temporal con- vnets: Minkowski convolutional neural networks, in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 3075–3084. doi:10.1109/cvpr.2019.00319
-
[46]
X. Wu, L. Jiang, P.-S. Wang, Z. Liu, X. Liu, Y . Qiao, W. Ouyang, T. He, H. Zhao, Point transformer v3: Sim- pler faster stronger, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 4840–4851
2024
-
[47]
C. R. Qi, W. Liu, C. Wu, H. Su, L. J. Guibas, Frus- tum pointnets for 3d object detection from rgb-d data, in: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, 2018, pp. 918–927. doi:10.1109/cvpr.2018.00102
-
[48]
Y . Zhou, X. Han, M. Peng, H. Li, B. Yang, Z. Dong, B. Yang, Street-view imagery guided street furniture in- ventory from mobile laser scanning point clouds, IS- PRS Journal of Photogrammetry and Remote Sensing 189 (2022) 63–77. doi:10.1016/j.isprsjprs.2022. 04.023
-
[49]
Z. Gong, H. Lin, D. Zhang, Z. Luo, J. Zelek, Y . Chen, A. Nurunnabi, C. Wang, J. Li, A frustum-based prob- abilistic framework for 3d object detection by fusion of lidar and camera data, ISPRS Journal of Photogrammetry 16 and Remote Sensing 159 (2020) 90–100. doi:10.1016/ j.isprsjprs.2019.10.015
2020
-
[50]
N. Ma, J. Fan, W. Wang, J. Wu, Y . Jiang, L. Xie, R. Fan, Computer vision for road imaging and pothole detection: a state-of-the-art review of systems and algorithms, Trans- portation safety and Environment 4 (2022) tdac026
2022
-
[51]
Behrendt, L
K. Behrendt, L. Novak, R. Botros, A deep learning ap- proach to traffic lights: Detection, tracking, and classifica- tion, in: 2017 IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2017, pp. 1370–1377
2017
-
[52]
Aygün, M
Z. Aygün, M. Kocaman, S. Aydemir, B. Konako ˘glu, Building damage detection using deep learning architec- ture with satellite images: The case of the 6 february 2023 kahramanmara¸ s earthquake, International Journal of Pio- neering Technology and Engineering 3 (2024) 53–61
2023
-
[53]
Tabernik, D
D. Tabernik, D. Sko ˇcaj, Deep learning for large-scale traffic-sign detection and recognition, IEEE transactions on intelligent transportation systems 21 (2019) 1427– 1440
2019
-
[54]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, et al., Learning transferable visual models from natural language supervision, in: International conference on ma- chine learning, PmLR, 2021, pp. 8748–8763
2021
-
[56]
L. Fu, C. Liu, B. Yang, Z. Dong, Unleashing the capabil- ities of large vision-language models for intelligent per- ception of roadside infrastructure, 2026. URL:https: //arxiv.org/abs/2601.10551.arXiv:2601.10551
arXiv 2026
-
[57]
S. Ren, K. He, R. Girshick, J. Sun, Faster r-cnn: To- wards real-time object detection with region proposal net- works, Advances in neural information processing sys- tems 28 (2015)
2015
-
[58]
Zhang, F
H. Zhang, F. Li, S. Liu, L. Zhang, H. Su, J. Zhu, L. M. Ni, H.-Y . Shum, Dino: Detr with improved denoising anchor boxes for end-to-end object detection, in: International Conference on Learning Representa- tions (ICLR), 2023. URL:https://openreview.net/ forum?id=pS_p766Sj0
2023
-
[59]
Sapkota, R
R. Sapkota, R. H. Cheppally, A. Sharda, M. Kar- kee, Yolo26: Key architectural enhancements and per- formance benchmarking for real-time object detection,
- [60]
-
[61]
Cheng, L
T. Cheng, L. Song, Y . Ge, W. Liu, X. Wang, Y . Shan, Yolo-world: Real-time open-vocabulary object detection, in: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2024, pp. 16901–16911
2024
-
[62]
Hurst, et al., Gpt-4o system card, arXiv preprint arXiv:2410.21276 (2024)
A. Hurst, et al., Gpt-4o system card, arXiv preprint arXiv:2410.21276 (2024)
Pith/arXiv arXiv 2024
-
[63]
H. Liu, C. Li, Q. Wu, Y . J. Lee, Visual instruction tuning, in: Advances in Neural Information Processing Systems, 2024
2024
-
[64]
J. Bai, et al., Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, arXiv preprint arXiv:2308.12966 (2023)
Pith/arXiv arXiv 2023
-
[65]
E. J. Hu, et al., Lora: Low-rank adaptation of large lan- guage models, arXiv preprint arXiv:2106.09685 (2022)
Pith/arXiv arXiv 2022
-
[66]
Lewis, et al., Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Advances in Neural Information Processing Systems, 2020
P. Lewis, et al., Retrieval-augmented generation for knowledge-intensive nlp tasks, in: Advances in Neural Information Processing Systems, 2020. 17
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.