Advancing the State-of-the-Art in Empirical Privacy Auditing
Pith reviewed 2026-06-27 13:45 UTC · model grok-4.3
The pith
Synthetic canaries generated by high-temperature sampling from LLMs enable stronger empirical privacy audits of fine-tuned models and their synthetic data outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
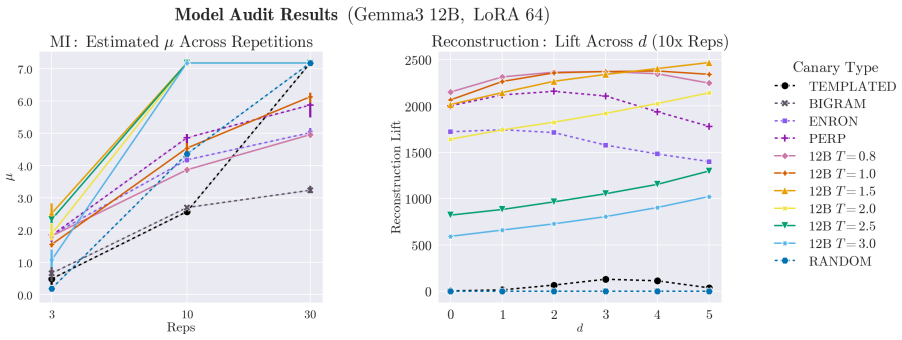
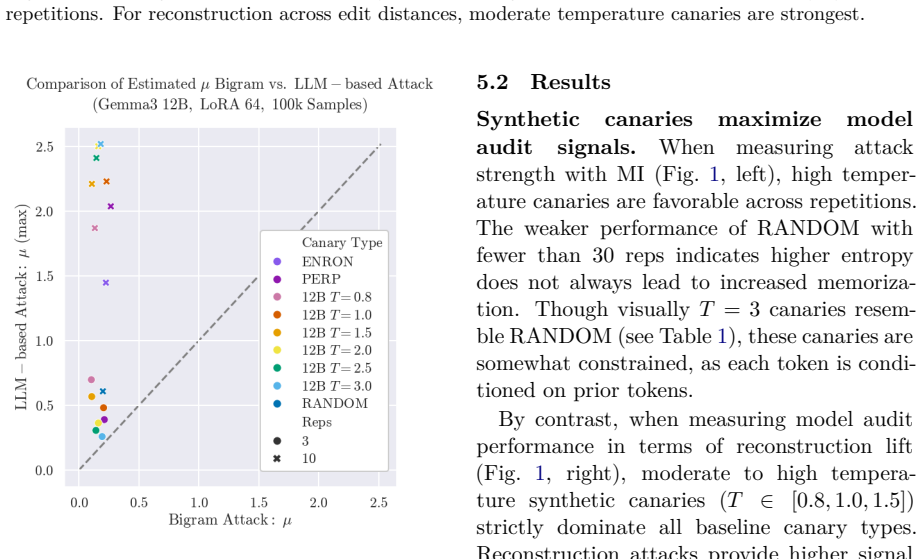
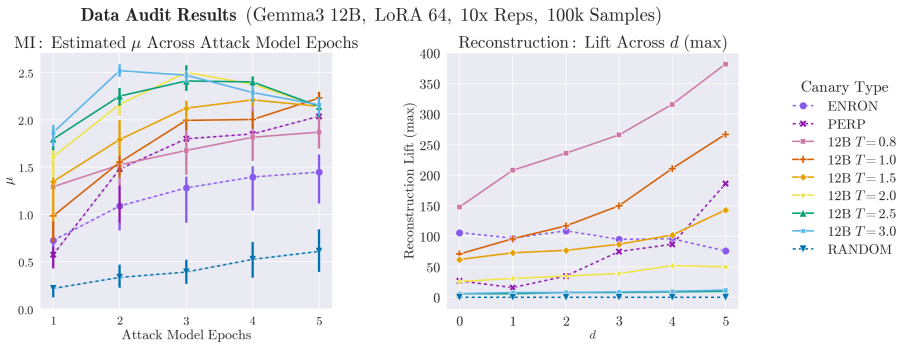
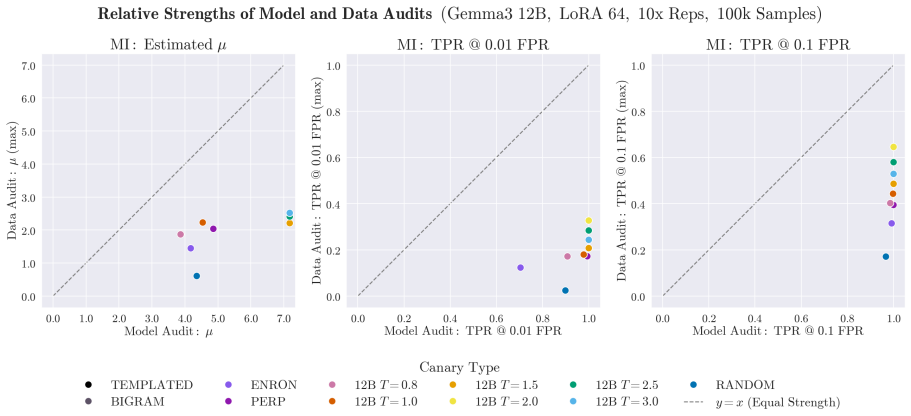
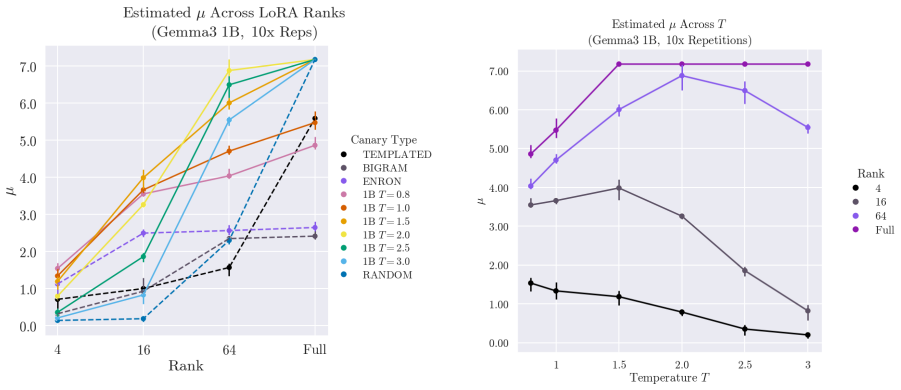
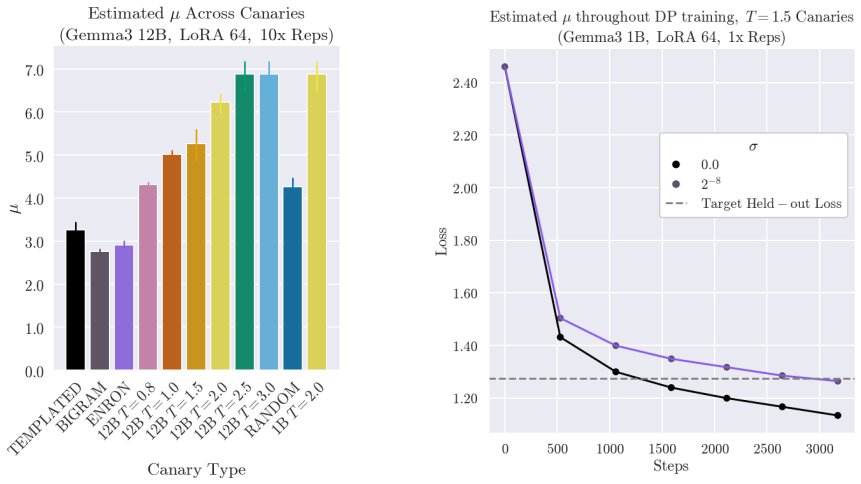
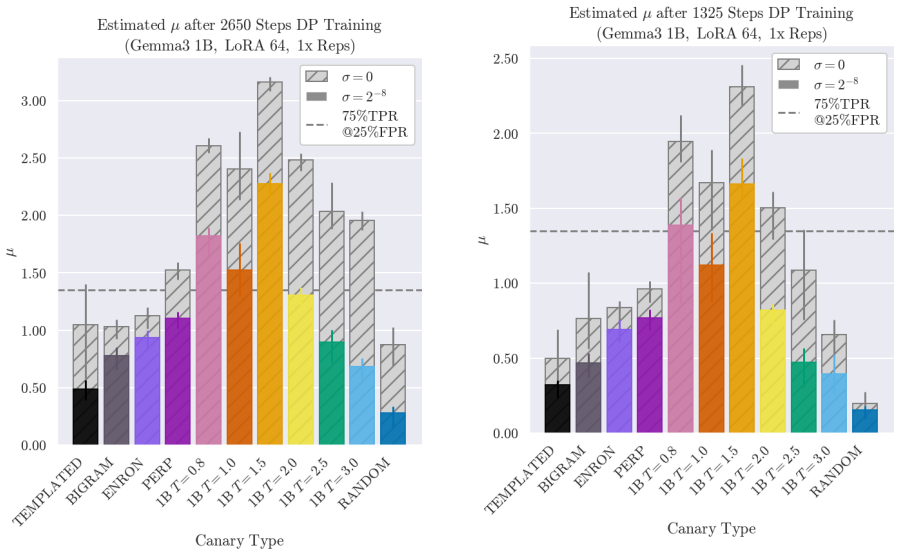
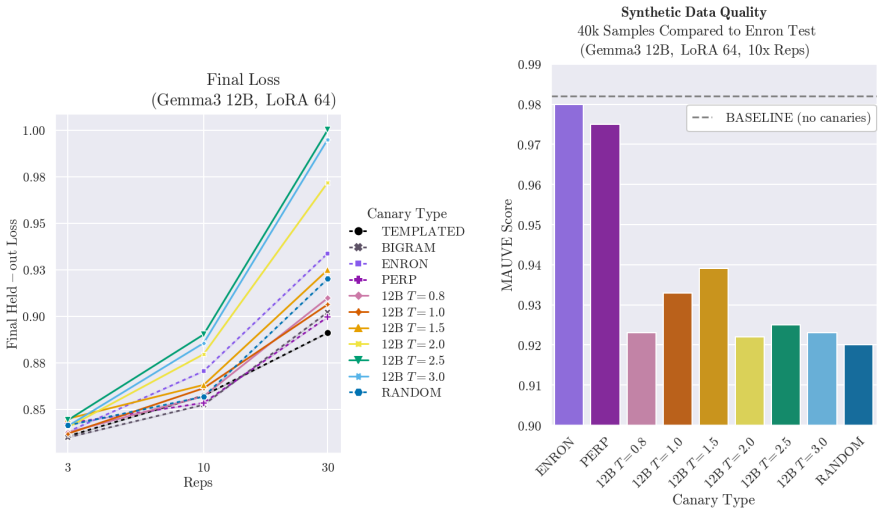
Generating synthetic canaries via high-temperature sampling (T ≥ 0.8) from LLMs using prompts tailored to the privacy-sensitive training data produces high-influence outliers that ensure high identifiability and strong audits. An auxiliary model fine-tuned on synthetic data then yields a strong estimate of privacy leakage through that synthetic data. Leveraging these auditing methodologies, the paper performs a systematic investigation into the interacting effects of model capacity and canary entropy on memorization.
What carries the argument
High-temperature (T ≥ 0.8) synthetic canaries sampled from LLMs with tailored prompts, functioning as high-influence outliers for membership inference.
If this is right
- Membership inference attacks on parameter-efficient fine-tuned LLMs become more reliable and repeatable.
- Audits can insert canaries multiple times without increasing risk to the original private training examples.
- Privacy leakage through synthetic data generated by a fine-tuned model can be quantified by auditing an auxiliary model trained on that output.
- Memorization risk grows measurably with larger model capacity and with lower-entropy canaries.
Where Pith is reading between the lines
- This canary construction could be reused across different fine-tuning runs to create comparable privacy benchmarks.
- The auxiliary-model audit might extend to measuring leakage when fine-tuned models are released for downstream synthetic data tasks.
- If the canaries remain effective across model scales, the approach offers a practical way to test privacy before deployment without needing access to the original training distribution.
Load-bearing premise
High-temperature synthetic canaries generated from the model itself remain non-private and reliably function as high-influence outliers whose membership is detectable independently of the real data distribution.
What would settle it
An experiment showing that membership inference success rates on these high-temperature synthetic canaries are no higher than rates obtained with conventional canaries or random examples would falsify the claim of stronger audits.
Figures

read the original abstract
Parameter-efficient fine-tuning of large language models (LLMs) can exhibit problematic memorization of individual training examples. Empirical privacy auditing (EPA) quantifies this risk by measuring realistic data leakage on membership inference (MI) or reconstruction attacks. A key challenge in EPA is designing ``canary'' examples that are mixed with the privacy-sensitive training data. We propose generating synthetic canaries via high-temperature sampling ($T \geq 0.8$) from LLMs, using prompts tailored to the privacy-sensitive training data. These canaries act as high-influence outliers, ensuring high identifiability and hence strong audits. Further, since the canaries are themselves non-private, they are inspectable and can be inserted with repetition without jeopardizing the privacy of the real data. An important use of models fine-tuned on privacy-sensitive data is the generation of synthetic data. This also comes with privacy risk. We introduce a powerful synthetic data audit based on fine-tuning an auxiliary model on the synthetic data. Auditing the auxiliary model for the original canaries then provides a strong estimate of the privacy leakage through the synthetic data. Finally, leveraging our strong auditing methodologies, we perform a systematic investigation into the interacting effects of model capacity and canary entropy on memorization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that synthetic canaries generated via high-temperature (T ≥ 0.8) sampling from LLMs using prompts derived from privacy-sensitive training data serve as high-influence outliers that enable strong empirical privacy audits via membership inference. It further proposes auditing privacy leakage in synthetic data by fine-tuning an auxiliary model on the synthetic outputs and testing it for the original canaries, and reports a systematic study of how model capacity and canary entropy interact to affect memorization in parameter-efficient fine-tuning of LLMs.
Significance. If the canary construction and auxiliary-model audit are shown to produce reliably stronger signals than standard canaries, the work would provide a practical, non-private mechanism for repeatable EPA and a direct way to quantify leakage through synthetic data pipelines. The capacity-entropy investigation could also clarify memorization dynamics in LLMs.
major comments (2)
- [Abstract] Abstract and § on canary generation: the claim that high-T synthetic canaries are high-influence outliers whose membership signal is independent of the real training distribution is load-bearing for both the strong-audit and synthetic-data-audit results, yet the generation process conditions on prompts drawn from the same private-data distribution the target model will see; no argument or experiment is supplied showing that the resulting strings lie outside the learned manifold rather than remaining within its support.
- [Synthetic data audit] Synthetic data audit section: the auxiliary-model procedure is presented as yielding a strong estimate of leakage through synthetic data, but the manuscript does not report controls that isolate whether the observed MI success on the original canaries is driven by leakage from the synthetic data itself versus residual information already present in the auxiliary model before fine-tuning on the synthetic outputs.
minor comments (2)
- The abstract refers to "parameter-efficient fine-tuning" throughout; the experimental sections should explicitly state whether the reported trends hold under full fine-tuning or only under LoRA/PEFT variants.
- Clarify the exact procedure used to tailor prompts to the privacy-sensitive training data and whether any filtering is applied to the high-T samples before insertion.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address each major comment below and indicate the planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract and § on canary generation: the claim that high-T synthetic canaries are high-influence outliers whose membership signal is independent of the real training distribution is load-bearing for both the strong-audit and synthetic-data-audit results, yet the generation process conditions on prompts drawn from the same private-data distribution the target model will see; no argument or experiment is supplied showing that the resulting strings lie outside the learned manifold rather than remaining within its support.
Authors: We agree that an explicit demonstration would strengthen the load-bearing claim. The high-temperature sampling is intended to produce low-likelihood sequences even when conditioned on domain-relevant prompts, but the manuscript does not currently include a direct comparison of model-assigned likelihoods for the synthetic canaries versus typical examples from the training distribution. We will add this analysis (e.g., perplexity or log-probability histograms) in the revised version. revision: yes
-
Referee: [Synthetic data audit] Synthetic data audit section: the auxiliary-model procedure is presented as yielding a strong estimate of leakage through synthetic data, but the manuscript does not report controls that isolate whether the observed MI success on the original canaries is driven by leakage from the synthetic data itself versus residual information already present in the auxiliary model before fine-tuning on the synthetic outputs.
Authors: The referee correctly identifies a missing control. We will add experiments that evaluate the auxiliary model on the original canaries both before and after fine-tuning on the synthetic outputs, thereby isolating the incremental leakage attributable to the synthetic data pipeline. revision: yes
Circularity Check
No circularity; empirical method rests on external attack evaluation
full rationale
The paper advances an empirical privacy auditing technique by proposing high-temperature sampling to generate synthetic canaries and an auxiliary-model audit for synthetic data leakage. No equations, fitted parameters, or derivations are shown that reduce any claimed result to its own inputs by construction. The load-bearing steps (canary identifiability and leakage estimation) are justified by reference to membership-inference attack success rates on the generated examples, which are external to the generation process itself. No self-citation chains, uniqueness theorems, or ansatzes are invoked to force the outcome. The work is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
User inference attacks on large language models , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[3]
30th USENIX security symposium (USENIX Security 21) , pages=
Extracting training data from large language models , author=. 30th USENIX security symposium (USENIX Security 21) , pages=
-
[4]
2017 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks against machine learning models , author=. 2017 IEEE symposium on security and privacy (SP) , pages=. 2017 , organization=
2017
-
[5]
Attention is All you Need , url =
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and Kaiser, ukasz and Polosukhin, Illia , booktitle =. Attention is All you Need , url =
-
[6]
, booktitle=
Song, Shuang and Chaudhuri, Kamalika and Sarwate, Anand D. , booktitle=. Stochastic gradient descent with differentially private updates , year=
-
[7]
Deep Learning with Differential Privacy , booktitle =
Mart. Deep Learning with Differential Privacy , booktitle =
-
[8]
Mironov, Ilya , booktitle=. R. 2017 , organization=
2017
-
[9]
Proceedings of the 41st International Conference on Machine Learning , pages =
Low-Cost High-Power Membership Inference Attacks , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
2024
-
[11]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
-
[12]
Theory of cryptography conference , pages=
Concentrated differential privacy: Simplifications, extensions, and lower bounds , author=. Theory of cryptography conference , pages=. 2016 , organization=
2016
-
[13]
Brendan and Vassilvitskii, Sergei and Chien, Steve and Thakurta, Abhradeep Guha , year=
Ponomareva, Natalia and Hazimeh, Hussein and Kurakin, Alex and Xu, Zheng and Denison, Carson and McMahan, H. Brendan and Vassilvitskii, Sergei and Chien, Steve and Thakurta, Abhradeep Guha , year=. How to DP-fy ML: A Practical Guide to Machine Learning with Differential Privacy , volume=. doi:10.1613/jair.1.14649 , journal=
-
[14]
Google's differential privacy libraries
DP Team. Google's differential privacy libraries
-
[15]
Balle, Borja and Berrada, Leonard and Charles, Zachary and Choquette-Choo, Christopher A and De, Soham and Doroshenko, Vadym and Dvijotham, Dj and Andrew, Galen and Ganesh, Arun and Ghalebikesabi, Sahra and Hayes, Jamie and Kairouz, Peter and McKenna, Ryan and McMahan, Brendan and Pappu, Aneesh and Ponomareva, Natalia and Pravilov, Mikhail and Rush, Keith...
-
[16]
The Fourteenth International Conference on Learning Representations , year=
Optimizing Canaries for Privacy Auditing with Metagradient Descent , author=. The Fourteenth International Conference on Learning Representations , year=
-
[17]
The Fourteenth International Conference on Learning Representations , year=
Benchmarking Empirical Privacy Protection for Adaptations of Large Language Models , author=. The Fourteenth International Conference on Learning Representations , year=
-
[18]
2004 , institution=
Enron email dataset database schema and brief statistical report , author=. 2004 , institution=
2004
-
[19]
2025 , institution=
Gemma 3 Technical Report , author=. 2025 , institution=
2025
-
[20]
28th USENIX security symposium (USENIX security 19) , pages=
The secret sharer: Evaluating and testing unintended memorization in neural networks , author=. 28th USENIX security symposium (USENIX security 19) , pages=
-
[22]
2021 IEEE Symposium on security and privacy (SP) , pages=
Adversary instantiation: Lower bounds for differentially private machine learning , author=. 2021 IEEE Symposium on security and privacy (SP) , pages=. 2021 , organization=
2021
-
[23]
Advances in Neural Information Processing Systems , volume=
Auditing differentially private machine learning: How private is private SGD? , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
International conference on machine learning , pages=
The composition theorem for differential privacy , author=. International conference on machine learning , pages=. 2015 , organization=
2015
-
[25]
2022 IEEE symposium on security and privacy (SP) , pages=
Membership inference attacks from first principles , author=. 2022 IEEE symposium on security and privacy (SP) , pages=. 2022 , organization=
2022
-
[26]
32nd USENIX Security Symposium (USENIX Security 23) , pages=
Tight auditing of differentially private machine learning , author=. 32nd USENIX Security Symposium (USENIX Security 23) , pages=
-
[27]
arXiv preprint arXiv:2302.03098 , year=
One-shot empirical privacy estimation for federated learning , author=. arXiv preprint arXiv:2302.03098 , year=
-
[29]
2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=
Auditing differential privacy guarantees using density estimation , author=. 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML) , pages=. 2025 , organization=
2025
-
[30]
Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
Deep learning with differential privacy , author=. Proceedings of the 2016 ACM SIGSAC conference on computer and communications security , pages=
2016
-
[31]
, author=
Lora: Low-rank adaptation of large language models. , author=. Iclr , volume=
-
[32]
Cognitive science , volume=
A learning algorithm for Boltzmann machines , author=. Cognitive science , volume=. 1985 , publisher=
1985
-
[33]
Advances in Neural Information Processing Systems , volume=
Mauve: Measuring the gap between neural text and human text using divergence frontiers , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
The algorithmic foundations of differ- ential privacy
Dwork, Cynthia and Roth, Aaron , title =. 2014 , issue_date =. doi:10.1561/0400000042 , journal =
-
[35]
Theory of cryptography conference , pages=
Calibrating noise to sensitivity in private data analysis , author=. Theory of cryptography conference , pages=. 2006 , organization=
2006
-
[36]
Journal of the American statistical Association , volume=
Better bootstrap confidence intervals , author=. Journal of the American statistical Association , volume=. 1987 , publisher=
1987
-
[37]
2025 , eprint=
How to DP-fy Your Data: A Practical Guide to Generating Synthetic Data With Differential Privacy , author=. 2025 , eprint=
2025
-
[38]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Gaussian differential privacy , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2022 , publisher=
2022
-
[40]
Proceedings of the 42nd International Conference on Machine Learning , articleno =
Mahloujifar, Saeed and Melis, Luca and Chaudhuri, Kamalika , title =. Proceedings of the 42nd International Conference on Machine Learning , articleno =. 2026 , publisher =
2026
-
[41]
The Canary
Matthieu Meeus and Lukas Wutschitz and Santiago Zanella-Beguelin and Shruti Tople and Reza Shokri , booktitle=. The Canary. 2025 , url=
2025
-
[42]
A Statistical Framework for Differential Privacy , urldate =
Larry Wasserman and Shuheng Zhou , journal =. A Statistical Framework for Differential Privacy , urldate =
-
[43]
2025 , howpublished=
Tunix (Tune-in-JAX) , author=. 2025 , howpublished=
2025
-
[44]
2024 , howpublished =
Qwix: A Quantization Library for Jax , author=. 2024 , howpublished =
2024
-
[46]
Goodfellow, H
Mart \' n Abadi, Andy Chu, Ian J. Goodfellow, H. Brendan McMahan, Ilya Mironov, Kunal Talwar, and Li Zhang. 2016. Deep learning with differential privacy. In Proc. of the 2016 ACM SIGSAC Conf. on Computer and Communications Security ( CCS '16) , pages 308--318
2016
-
[47]
David H Ackley, Geoffrey E Hinton, and Terrence J Sejnowski. 1985. A learning algorithm for boltzmann machines. Cognitive science, 9(1):147--169
1985
-
[48]
Borja Balle, Leonard Berrada, Zachary Charles, Christopher A Choquette-Choo, Soham De, Vadym Doroshenko, Dj Dvijotham, Galen Andrew, Arun Ganesh, Sahra Ghalebikesabi, Jamie Hayes, Peter Kairouz, Ryan McKenna, Brendan McMahan, Aneesh Pappu, Natalia Ponomareva, Mikhail Pravilov, Keith Rush, Samuel L Smith, and Robert Stanforth. 2025. http://github.com/googl...
2025
-
[49]
Tianshu Bao, Jeff Carpenter, Lin Chai, Haoyu Gao, Yangmu Jiang, Shadi Noghabi, Abheesht Sharma, Sizhi Tan, Lance Wang, Ann Yan, Weiren Yu, and 1 others. 2025. Tunix (tune-in-jax). https://github.com/google/tunix
2025
-
[50]
Matteo Boglioni, Terrance Liu, Andrew Ilyas, and Steven Wu. 2026. https://openreview.net/forum?id=3xkYXuHDA6 Optimizing canaries for privacy auditing with metagradient descent . In The Fourteenth International Conference on Learning Representations
2026
-
[51]
Nicholas Carlini, Steve Chien, Milad Nasr, Shuang Song, Andreas Terzis, and Florian Tramer. 2022. Membership inference attacks from first principles. In 2022 IEEE symposium on security and privacy (SP), pages 1897--1914. IEEE
2022
-
[52]
Nicholas Carlini, Chang Liu, \'U lfar Erlingsson, Jernej Kos, and Dawn Song. 2019. The secret sharer: Evaluating and testing unintended memorization in neural networks. In 28th USENIX security symposium (USENIX security 19), pages 267--284
2019
-
[53]
Nicholas Carlini, Florian Tramer, Eric Wallace, Matthew Jagielski, Ariel Herbert-Voss, Katherine Lee, Adam Roberts, Tom Brown, Dawn Song, Ulfar Erlingsson, and 1 others. 2021. Extracting training data from large language models. In 30th USENIX security symposium (USENIX Security 21), pages 2633--2650
2021
-
[54]
Lynn Chua, Badih Ghazi, Pritish Kamath, Ravi Kumar, Pasin Manurangsi, Amer Sinha, and Chiyuan Zhang. 2024. https://doi.org/10.52202/079017-2238 Scalable dp-sgd: Shuffling vs. poisson subsampling . In Advances in Neural Information Processing Systems, volume 37, pages 70026--70047. Curran Associates, Inc
-
[55]
Alex Cloud, Minh Le, James Chua, Jan Betley, Anna Sztyber-Betley, S \"o ren Mindermann, Jacob Hilton, Samuel Marks, and Owain Evans. 2026. https://doi.org/10.1038/s41586-026-10319-8 Language models transmit behavioural traits through hidden signals in data . Nature, 652:615--621
-
[56]
Dangyi Liu, Jiwon Shin
et al. Dangyi Liu, Jiwon Shin. 2024. Qwix: A quantization library for jax. https://github.com/google/qwix
2024
-
[57]
Jinshuo Dong, Aaron Roth, and Weijie J Su. 2022. Gaussian differential privacy. Journal of the Royal Statistical Society Series B: Statistical Methodology, 84(1):3--37
2022
-
[58]
Bradley Efron. 1987. Better bootstrap confidence intervals. Journal of the American statistical Association, 82(397):171--185
1987
-
[59]
Juan Felipe Gomez, Bogdan Kulynych, Georgios Kaissis, Flavio P Calmon, Jamie Hayes, Borja Balle, and Antti Honkela. 2025. Gaussian dp for reporting differential privacy guarantees in machine learning. arXiv preprint arXiv:2503.10945
Pith/arXiv arXiv 2025
-
[60]
Jamie Hayes, Luca Melis, George Danezis, and Emiliano De Cristofaro. 2017. Logan: Membership inference attacks against generative models. arXiv preprint arXiv:1705.07663
Pith/arXiv arXiv 2017
-
[61]
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, and 1 others. 2022. Lora: Low-rank adaptation of large language models. Iclr, 1(2):3
2022
-
[62]
Matthew Jagielski, Jonathan Ullman, and Alina Oprea. 2020. Auditing differentially private machine learning: How private is private sgd? Advances in Neural Information Processing Systems, 33:22205--22216
2020
-
[63]
Peter Kairouz, Sewoong Oh, and Pramod Viswanath. 2015. The composition theorem for differential privacy. In International conference on machine learning, pages 1376--1385. PMLR
2015
-
[64]
Nikhil Kandpal, Krishna Pillutla, Alina Oprea, Peter Kairouz, Christopher A Choquette-Choo, and Zheng Xu. 2024. User inference attacks on large language models. In Proceedings of the 2024 conference on empirical methods in natural language processing, pages 18238--18265
2024
-
[65]
Antti Koskela and Jafar Aco Mohammadi. 2025. Auditing differential privacy guarantees using density estimation. In 2025 IEEE Conference on Secure and Trustworthy Machine Learning (SaTML), pages 1007--1026. IEEE
2025
-
[66]
Ilya Loshchilov and Frank Hutter. 2017. https://api.semanticscholar.org/CorpusID:53592270 Decoupled weight decay regularization . In International Conference on Learning Representations
2017
-
[67]
Samuel Maddock, Alexandre Sablayrolles, and Pierre Stock. 2022. Canife: Crafting canaries for empirical privacy measurement in federated learning. arXiv preprint arXiv:2210.02912
arXiv 2022
-
[68]
Saeed Mahloujifar, Luca Melis, and Kamalika Chaudhuri. 2026. Auditing f-differential privacy in one run. In Proceedings of the 42nd International Conference on Machine Learning, ICML'25. JMLR.org
2026
-
[69]
Bart omiej Marek, Lorenzo Rossi, Vincent Hanke, Xun Wang, Michael Backes, Franziska Boenisch, and Adam Dziedzic. 2026. https://openreview.net/forum?id=jY7fAo9rfK Benchmarking empirical privacy protection for adaptations of large language models . In The Fourteenth International Conference on Learning Representations
2026
-
[70]
Matthieu Meeus, Lukas Wutschitz, Santiago Zanella-Beguelin, Shruti Tople, and Reza Shokri. 2025. https://openreview.net/forum?id=f3mQ0xYA1I The canary s echo: Auditing privacy risks of LLM -generated synthetic text . In Forty-second International Conference on Machine Learning
2025
-
[71]
Milad Nasr, Jamie Hayes, Thomas Steinke, Borja Balle, Florian Tram \`e r, Matthew Jagielski, Nicholas Carlini, and Andreas Terzis. 2023. Tight auditing of differentially private machine learning. In 32nd USENIX Security Symposium (USENIX Security 23), pages 1631--1648
2023
-
[72]
Milad Nasr, Shuang Song, Abhradeep Thakurta, Nicolas Papernot, and Nicholas Carlini. 2021. Adversary instantiation: Lower bounds for differentially private machine learning. In 2021 IEEE Symposium on security and privacy (SP), pages 866--882. IEEE
2021
-
[73]
Ashwinee Panda, Xinyu Tang, Milad Nasr, Christopher A Choquette-Choo, and Prateek Mittal. 2025. Privacy auditing of large language models. arXiv preprint arXiv:2503.06808
arXiv 2025
-
[74]
Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, and Zaid Harchaoui. 2021. Mauve: Measuring the gap between neural text and human text using divergence frontiers. Advances in Neural Information Processing Systems, 34:4816--4828
2021
-
[75]
Natalia Ponomareva, Zheng Xu, H. Brendan McMahan, Peter Kairouz, Lucas Rosenblatt, Vincent Cohen-Addad, Cristóbal Guzmán, Ryan McKenna, Galen Andrew, Alex Bie, Da Yu, Alex Kurakin, Morteza Zadimoghaddam, Sergei Vassilvitskii, and Andreas Terzis. 2025. https://arxiv.org/abs/2512.03238 How to dp-fy your data: A practical guide to generating synthetic data w...
arXiv 2025
-
[76]
Jitesh Shetty and Jafar Adibi. 2004. http://www.isi.edu/ adibi/Enron/Enron_Dataset_Report.pdf Enron email dataset database schema and brief statistical report . Technical report, University of Southern California Information Sciences Institute
2004
-
[77]
Reza Shokri, Marco Stronati, Congzheng Song, and Vitaly Shmatikov. 2017. Membership inference attacks against machine learning models. In 2017 IEEE symposium on security and privacy (SP), pages 3--18. IEEE
2017
-
[78]
Shuang Song, Kamalika Chaudhuri, and Anand D. Sarwate. 2013. https://doi.org/10.1109/GlobalSIP.2013.6736861 Stochastic gradient descent with differentially private updates . In 2013 IEEE Global Conference on Signal and Information Processing, pages 245--248
-
[79]
Gemma Team. 2025. https://arxiv.org/abs/2503.19786 Gemma 3 technical report . Technical report, Google
Pith/arXiv arXiv 2025
-
[80]
Larry Wasserman and Shuheng Zhou. 2010. http://www.jstor.org/stable/29747034 A statistical framework for differential privacy . Journal of the American Statistical Association, 105(489):375--389
arXiv 2010
-
[81]
Sajjad Zarifzadeh, Philippe Liu, and Reza Shokri. 2024. https://proceedings.mlr.press/v235/zarifzadeh24a.html Low-cost high-power membership inference attacks . In Proceedings of the 41st International Conference on Machine Learning, volume 235 of Proceedings of Machine Learning Research, pages 58244--58282. PMLR
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.