PRISM-VO: Scale-Aware Visual Odometry Using Photometric Plenoptic Bundle Adjustment
Pith reviewed 2026-07-02 19:25 UTC · model grok-4.3
The pith
Plenoptic bundle adjustment recovers reliable metric scale in visual odometry from a single sensor.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By combining geometric depth priors extracted directly from each plenoptic image with multi-view photometric residuals inside a joint optimization of poses and inverse depths, PRISM-VO produces accurate, drift-resilient motion estimates that recover consistent metric scale using only a single focused plenoptic camera.
What carries the argument
Photometric plenoptic bundle adjustment, which models the plenoptic projection to optimize poses and inverse depths together.
If this is right
- Metric-scale reconstructions become available without auxiliary sensors or manual initialization.
- Drift remains low across long sequences because depth priors and photometric constraints reinforce each other.
- Performance exceeds prior plenoptic visual-odometry algorithms on both indoor and outdoor data.
- Results rival other optimization-based and learning-based visual-odometry systems while retaining explicit metric scale.
- The sliding-window formulation supports real-time operation on a single plenoptic stream.
Where Pith is reading between the lines
- The same depth-prior fusion idea could be tested on other light-field or multi-lens cameras to see whether metric scale generalizes beyond the focused plenoptic design.
- If the plenoptic depth prior degrades in low-texture or distant scenes, hybrid use with occasional IMU measurements might restore robustness without losing the single-sensor advantage.
- Because scale is recovered explicitly, the output trajectories could be fed directly into metric mapping or planning modules that currently require stereo or RGB-D input.
Load-bearing premise
Geometric depth values computed from a single plenoptic image stay accurate and stable enough to serve as priors that keep the overall scale correct when fused with temporal constraints.
What would settle it
Run the optimizer on a sequence in which the plenoptic depth estimates contain systematic bias or high variance; the resulting trajectories should then exhibit growing scale drift or outright failure to match ground-truth metric distances.
Figures
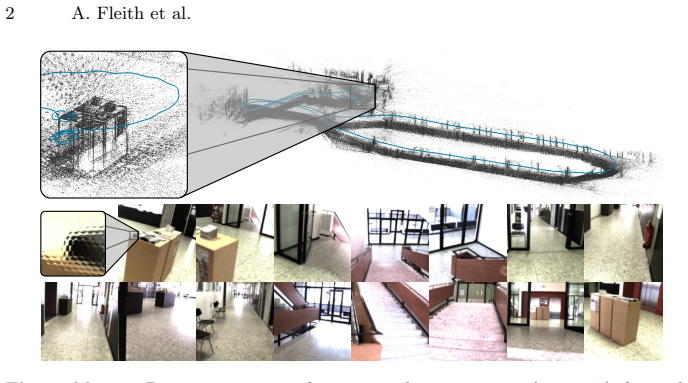
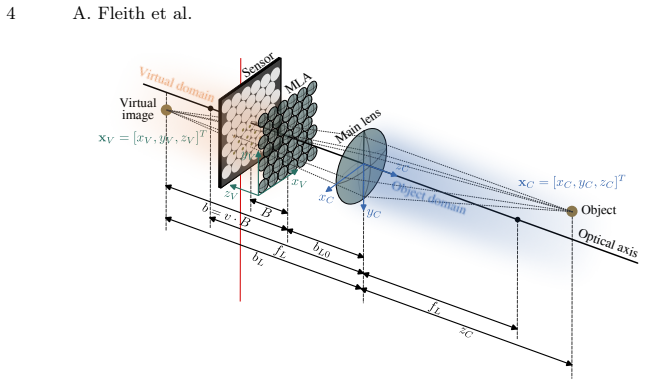

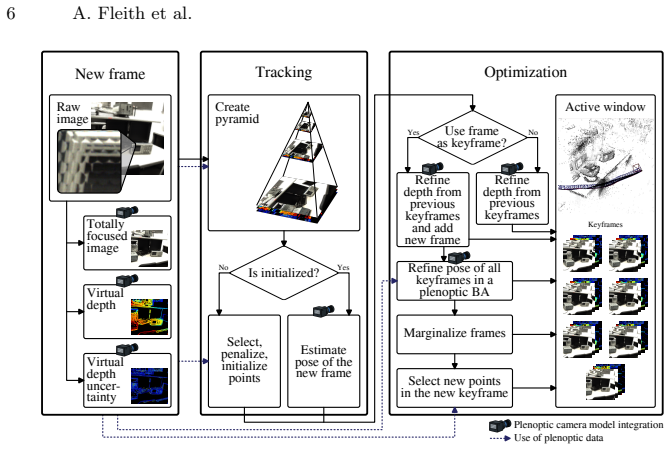
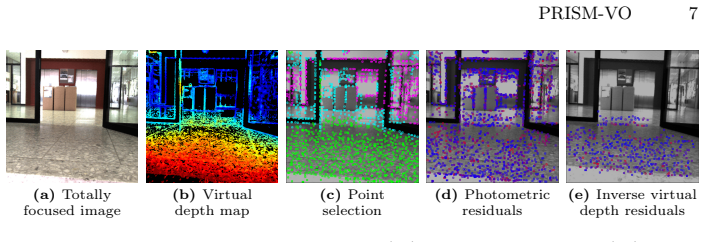
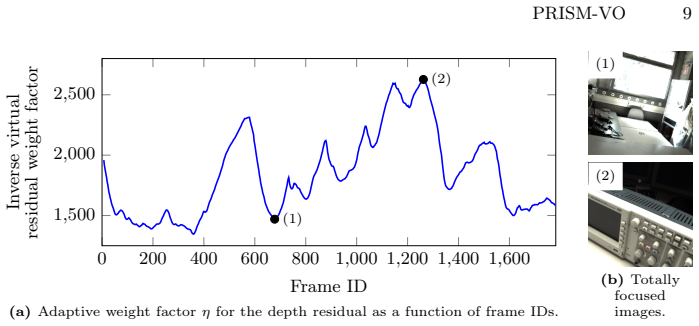
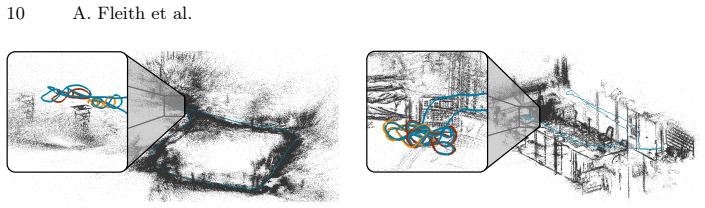


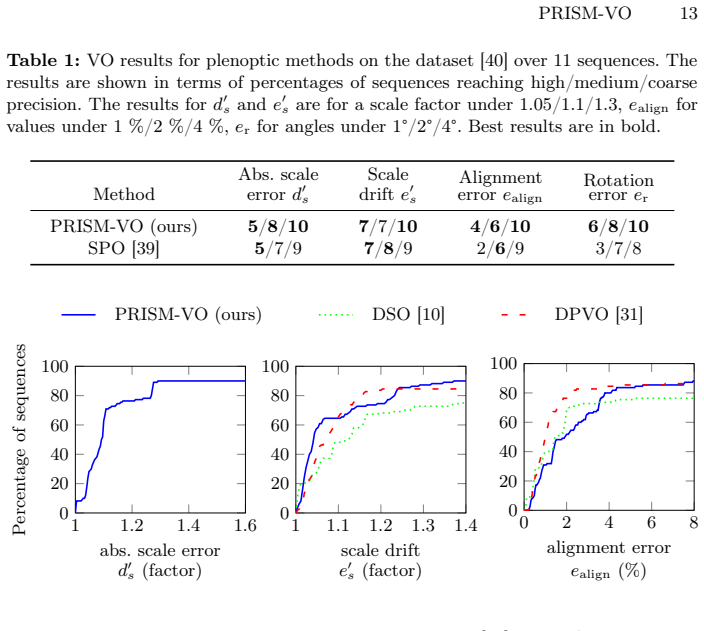
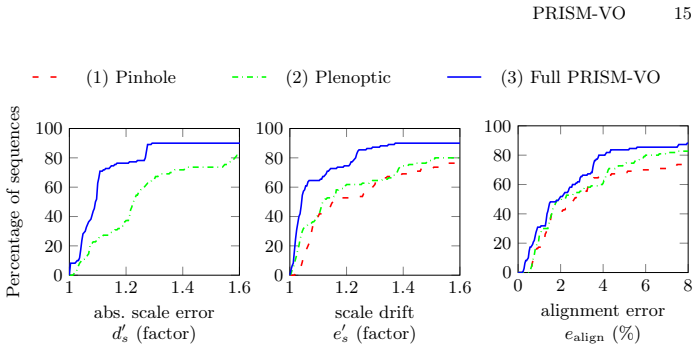
read the original abstract
We introduce PRISM-VO, a novel pure optimization-based sparse photometric visual odometry framework for focused plenoptic cameras. The core of PRISM-VO is a novel photometric plenoptic bundle adjustment which jointly optimizes camera poses and inverse depth values of points in a sliding window. By combining geometric depth from a single plenoptic image with temporal multi-view constraints, PRISM-VO achieves accurate and drift-resilient motion estimation. Through explicit modeling of the plenoptic projection, PRISM-VO provides reliable metric-scale reconstructions, overcoming the scale ambiguity of monocular SLAM algorithms. Importantly, our approach relies solely on a single plenoptic sensor and avoids complex initialization, as depth priors are computed directly from plenoptic imaging. Experiments show that PRISM-VO outperforms the current state-of-the-art plenoptic visual odometry method on indoor and outdoor scenes. The proposed approach rivals other optimization- and learning-based methods while accurately and reliably recovering a metric scale of the scene. Project page: https://prism-vo.github.io/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PRISM-VO, a sparse photometric visual odometry framework for focused plenoptic cameras. Its core contribution is a photometric plenoptic bundle adjustment that jointly optimizes camera poses and inverse depth values within a sliding window. By integrating geometric depth priors computed from a single plenoptic image with temporal multi-view photometric constraints, the method claims to deliver accurate, drift-resilient motion estimation and reliable metric-scale scene reconstructions using only one plenoptic sensor, without external initialization or additional sensors. Experiments are stated to demonstrate outperformance over prior plenoptic VO methods on indoor and outdoor scenes while rivaling other optimization- and learning-based approaches in metric scale recovery.
Significance. If the central claims hold after verification, the work would offer a meaningful advance by resolving monocular scale ambiguity through explicit plenoptic projection modeling and single-image depth priors, potentially enabling metric VO in sensor-constrained settings. No machine-checked proofs, reproducible code releases, or parameter-free derivations are described in the provided text.
major comments (1)
- [Abstract] Abstract (final paragraph): The central claim that combining single-image plenoptic geometric depth with temporal photometric constraints produces drift-resilient metric trajectories is load-bearing, yet the text provides no error model for plenoptic depth, no weighting schedule between geometric and photometric residuals, and no ablation on how depth variance propagates into pose drift. This directly matches the stress-test concern that scale can wander when plenoptic depth noise exceeds photometric constraint strength, particularly at range or in low texture.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract (final paragraph): The central claim that combining single-image plenoptic geometric depth with temporal photometric constraints produces drift-resilient metric trajectories is load-bearing, yet the text provides no error model for plenoptic depth, no weighting schedule between geometric and photometric residuals, and no ablation on how depth variance propagates into pose drift. This directly matches the stress-test concern that scale can wander when plenoptic depth noise exceeds photometric constraint strength, particularly at range or in low texture.
Authors: We agree that the presentation of the central claim can be strengthened by making the supporting analysis more explicit. The manuscript describes the plenoptic depth prior computation (Section 3.2) and its integration into the joint photometric-geometric bundle adjustment (Section 5, Equation 7), with the weighting factor between the two residual types set proportionally to the inverse depth variance. However, we did not provide a dedicated error propagation derivation or ablation study. We will revise the manuscript to add (i) an explicit error model for the single-image plenoptic depth estimates, (ii) the precise weighting schedule used in the optimizer, and (iii) an ablation examining how depth variance affects pose drift at varying ranges and texture levels. revision: yes
Circularity Check
No significant circularity; derivation relies on external plenoptic geometry as independent input.
full rationale
The paper introduces a photometric plenoptic bundle adjustment that jointly optimizes poses and inverse depths while incorporating geometric depth priors computed directly from single plenoptic images. This scale source is presented as an external sensor property rather than a fitted parameter or self-referential quantity. No equations or claims reduce the metric-scale output to a definition or prediction derived from the optimization itself. No load-bearing self-citations or uniqueness theorems from prior author work are invoked to force the result. The central claim remains self-contained against the plenoptic camera model as an independent prior.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Al Assaad, M., Bazeille, S., Cudel, C.: Indirect visual odometry with a light-field camera. Intelligent Systems with Applications (ISWA)28, 200600 (2025).https: //doi.org/10.1016/j.iswa.2025.200600
-
[2]
Bok, Y., Jeon, H.G., Kweon, I.S.: Geometric calibration of micro-lens-based light field cameras using line features. Transactions on Pattern Analysis and Machine Intelligence (TPAMI)39(2), 287–300 (2017).https://doi.org/10.1109/tpami. 2016.2541145
-
[3]
Transactions on Robotics (T-RO)37(6), 1874–1890 (2021).https://doi
Campos, C., Elvira, R., Rodríguez, J.J.G., Montiel, J.M., Tardós, J.D.: ORB- SLAM3: An accurate open-source library for visual, visual-inertial, and multi-map SLAM. Transactions on Robotics (T-RO)37(6), 1874–1890 (2021).https://doi. org/10.1109/TRO.2021.3075644
-
[4]
In: International Conference on Intelligent Robots and Systems (IROS)
Dansereau, D.G., Mahon, I., Pizarro, O., Williams, S.B.: Plenoptic flow: Closed- form visual odometry for light field cameras. In: International Conference on Intelligent Robots and Systems (IROS). pp. 4455–4462. IEEE (2011).https: //doi.org/10.1109/IROS.2011.6095080
-
[5]
In: Conference on Computer Vi- sion and Pattern Recognition (CVPR)
Dansereau, D.G., Pizarro, O., Williams, S.B.: Decoding, calibration and recti- fication for lenslet-based plenoptic cameras. In: Conference on Computer Vi- sion and Pattern Recognition (CVPR). pp. 1027–1034. IEEE (2013).https: //doi.org/10.1109/cvpr.2013.137
-
[6]
In: International Conference on Image Processing (ICIP)
Darwish, W., Bolsee, Q., Munteanu, A.: Plenoptic camera calibration based on sub-aperture images. In: International Conference on Image Processing (ICIP). pp. 3527–3531. IEEE (2019).https://doi.org/10.1109/icip.2019.8803473
-
[7]
In: International Conference on Intelligent Robots and Systems (IROS)
Digumarti, S.T., Daniel, J., Ravendran, A., Griffiths, R., Dansereau, D.G.: Unsu- pervised learning of depth estimation and visual odometry for sparse light field cameras. In: International Conference on Intelligent Robots and Systems (IROS). pp. 278–285. IEEE (2021).https://doi.org/10.1109/IROS51168.2021.9636570
-
[8]
Dong, F., Ieng, S.H., Savatier, X., Etienne-Cummings, R., Benosman, R.: Plenoptic cameras in real-time robotics. International Journal of Robotics Research (IJRR) 32(2), 206–217 (2013).https://doi.org/10.1177/0278364912469420
-
[9]
Dury, S., Bonatto, D., Sancho, J., Juarez, E., Teratani, M., Lafruit, G.: Structure- from-motion in the micro-image domain for uncalibrated plenoptic 2.0 cameras. International Journal of Computer Vision (IJCV)134(1), 34 (2026).https:// doi.org/10.1007/s11263-025-02612-2
-
[10]
Engel, J., Koltun, V., Cremers, D.: Direct sparse odometry. Transactions on Pat- tern Analysis and Machine Intelligence (TPAMI)40(3), 611–625 (2018).https: //doi.org/10.1109/TPAMI.2017.2658577
-
[11]
In: European Conference on Computer Vision (ECCV)
Engel, J., Schöps, T., Cremers, D.: LSD-SLAM: Large-scale direct monocular SLAM. In: European Conference on Computer Vision (ECCV). pp. 834–849. Springer (2014).https://doi.org/10.1007/978-3-319-10605-2_54
-
[12]
Transactions on Multimedia27, 7179–7191 (2025).https://doi.org/10.1109/TMM.2025.3590906
Fachada, S., Bonatto, D., Lafruit, G., Teratani, M.: Micro-image domain view synthesizer for free navigation with focused plenoptic cameras. Transactions on Multimedia27, 7179–7191 (2025).https://doi.org/10.1109/TMM.2025.3590906
-
[13]
In: International Workshop on Multimedia Sig- nal Processing (MMSP)
Fachada, S., Bonatto, D., Losfeld, A., Lafruit, G., Teratani, M.: Pattern-free plenoptic 2.0 camera calibration. In: International Workshop on Multimedia Sig- nal Processing (MMSP). pp. 1–6. IEEE (2022).https://doi.org/10.1109/ mmsp55362.2022.9949312
-
[14]
In: International Workshop PRISM-VO 17 on Multimedia Signal Processing (MMSP)
Fachada, S., Losfeld, A., Senoh, T., Lafruit, G., Teratani, M.: A calibration method for sub-aperture views of plenoptic 2.0 camera arrays. In: International Workshop PRISM-VO 17 on Multimedia Signal Processing (MMSP). pp. 1–6. IEEE (2021).https://doi. org/10.1109/mmsp53017.2021.9733556
-
[15]
In: DAGM German Conference on Pattern Recognition (GCPR)
Fleith, A., Ahmed, D., Cremers, D., Zeller, N.: LiFCal: Online light field cam- era calibration via bundle adjustment. In: DAGM German Conference on Pattern Recognition (GCPR). pp. 120–136. Springer (2024).https://doi.org/10.1007/ 978-3-031-85187-2_8
2024
-
[16]
In: International Symposium on Visual Computing (ISVC)
Fleith, A., Zirbel, J., Cremers, D., Zeller, N.: LiFMCR: Dataset and benchmark for light field multi-camera registration. In: International Symposium on Visual Computing (ISVC). Springer Nature Switzerland (2026).https://doi.org/10. 1007/978-3-032-14492-8_35
2026
-
[17]
Optics Express24(19), 21521–21540 (2016)
Hahne, C., Aggoun, A., Velisavljevic, V., Fiebig, S., Pesch, M.: Refocusing dis- tance of a standard plenoptic camera. Optics Express24(19), 21521–21540 (2016). https://doi.org/10.1364/OE.24.021521
-
[18]
arXiv preprint arXiv:2012.10714 (2020).https://doi.org/10.48550/ arXiv.2012.10714
Kaveti, P., Singh, H.: A light field front-end for robust SLAM in dynamic envi- ronments. arXiv preprint arXiv:2012.10714 (2020).https://doi.org/10.48550/ arXiv.2012.10714
-
[19]
In: International Symposium on Mixed and Augmented Reality (ISMAR)
Klein, G., Murray, D.: Parallel tracking and mapping for small AR workspaces. In: International Symposium on Mixed and Augmented Reality (ISMAR). pp. 225–
-
[20]
IEEE (2007).https://doi.org/10.1109/ISMAR.2007.4538852
-
[21]
Labussière, M., Teulière, C., Bernardin, F., Ait-Aider, O.: Blur-aware calibration of multi-focus plenoptic cameras. In: Conference on Computer Vision and Pattern Recognition (CVPR). pp. 2542–2551. IEEE (2020).https://doi.org/10.1109/ cvpr42600.2020.00262
-
[22]
Labussière, M., Teulière, C., Bernardin, F., Ait-Aider, O.: Leveraging blur in- formation for plenoptic camera calibration. International journal of computer vi- sion (IJCV)130(7), 1655–1677 (2022).https://doi.org/10.1007/s11263-022- 01582-z
-
[23]
In: Inter- national Conference on Robotics and Automation (ICRA)
Lasheras-Hernandez, B., Strobl, K.H., Izquierdo, S., Bodenmüller, T., Triebel, R., Civera, J.: Single-shot metric depth from focused plenoptic cameras. In: Inter- national Conference on Robotics and Automation (ICRA). pp. 9566–9573. IEEE (2025).https://doi.org/10.1109/ICRA55743.2025.11128276
-
[24]
In: International Con- ference on Computational Photography (ICCP)
Lumsdaine, A., Georgiev, T.: The focused plenoptic camera. In: International Con- ference on Computational Photography (ICCP). pp. 1–8. IEEE (2009).https: //doi.org/10.1109/iccphot.2009.5559008
-
[25]
Indiana University and Adobe Systems, Tech
Lumsdaine, A., Georgiev, T., et al.: Full-resolution light field rendering. Indiana University and Adobe Systems, Tech. Rep91, 92 (2008)
2008
-
[26]
Transactions on Robotics (T-RO)31(5), 1147–1163 (2015).https://doi.org/10.1109/TRO.2015.2463671
Mur-Artal, R., Montiel, J.M.M., Tardos, J.D.: ORB-SLAM: A versatile and accu- rate monocular SLAM system. Transactions on Robotics (T-RO)31(5), 1147–1163 (2015).https://doi.org/10.1109/TRO.2015.2463671
-
[27]
In: International Conference on Computer Vision (ICCV)
Newcombe, R.A., Lovegrove, S.J., Davison, A.J.: DTAM: Dense tracking and map- ping in real-time. In: International Conference on Computer Vision (ICCV). pp. 2320–2327. IEEE (2011).https://doi.org/10.1109/ICCV.2011.6126513
-
[28]
In: International Conference on Digital Image Computing: Techniques and Applications (DICTA)
Noury, C.A., Teulière, C., Dhome, M.: Light-field camera calibration from raw images. In: International Conference on Digital Image Computing: Techniques and Applications (DICTA). pp. 1–8. IEEE (2017).https://doi.org/10.1109/DICTA. 2017.8227459
-
[29]
In: International conference on 3D vision (3DV)
O’brien, S., Trumpf, J., Ila, V., Mahony, R.: Calibrating light-field cameras using plenoptic disc features. In: International conference on 3D vision (3DV). pp. 286–
-
[30]
IEEE (2018).https://doi.org/10.1109/3dv.2018.00041 18 A. Fleith et al
-
[31]
In: Human Vision and Electronic Imaging (HVEI)
Perwass, C., Wietzke, L.: Single-lens 3D camera with extended depth of field. In: Human Vision and Electronic Imaging (HVEI). vol. 8291, pp. 45–59. SPIE (2012). https://doi.org/10.1117/12.909882
-
[32]
Advances in Neural Information Processing Systems (NeurIPS) 34, 16558–16569 (2021)
Teed, Z., Deng, J.: DROID-SLAM: Deep visual SLAM for monocular, stereo, and RGB-D cameras. Advances in Neural Information Processing Systems (NeurIPS) 34, 16558–16569 (2021)
2021
-
[33]
Advances in Neural Information Processing Systems (NeurIPS)36, 39033–39051 (2023)
Teed, Z., Lipson, L., Deng, J.: Deep patch visual odometry. Advances in Neural Information Processing Systems (NeurIPS)36, 39033–39051 (2023)
2023
-
[34]
Robotics and Automation Letters (RA-L)7(2), 1408–1415 (2022)
Von Stumberg, L., Cremers, D.: DM-VIO: Delayed marginalization visual-inertial odometry. Robotics and Automation Letters (RA-L)7(2), 1408–1415 (2022). https://doi.org/10.1109/LRA.2021.3140129
-
[35]
Wang, Y., Wang, L., Liang, Z., Yang, J., An, W., Guo, Y.: Occlusion-aware cost constructor for light field depth estimation. In: Conference on Computer Vision and Pattern Recognition (CVPR). pp. 19777–19786. IEEE (2022).https://doi. org/10.1109/cvpr52688.2022.01919
-
[36]
In: Conference on Computer Vision and Pattern Recognition (CVPR)
Xiao, Z., Liu, Y., Gao, R., Xiong, Z.: CutMIB: Boosting light field super-resolution via multi-view image blending. In: Conference on Computer Vision and Pattern Recognition (CVPR). pp. 1672–1682. IEEE (2023).https://doi.org/10.1109/ cvpr52729.2023.00167
-
[37]
Zeller, N., Noury, C.A., Quint, F., Teulière, C., Stilla, U., Dhome, M.: Metric calibration of a focused plenoptic camera based on a 3D calibration target. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences (ISPRS Annals)III–3, 449–456 (2016).https://doi.org/10.5194/isprsannals- iii-3-449-2016
-
[38]
Zeller, N., Quint, F., Stilla, U.: Establishing a probabilistic depth map from focused plenopticcameras.In:InternationalConferenceon3DVision(3DV)(2015).https: //doi.org/10.1109/3DV.2015.18
-
[39]
Zeller, N., Quint, F., Stilla, U.: Depth estimation and camera calibration of a focused plenoptic camera for visual odometry. ISPRS Journal of Photogrammetry and Remote Sensing (P&RS)118, 83–100 (2016).https://doi.org/10.1016/j. isprsjprs.2016.04.010
work page doi:10.1016/j 2016
-
[40]
Zeller, N., Quint, F., Stilla, U.: From the calibration of a light-field camera to direct plenopticodometry.JournalofSelectedTopicsinSignalProcessing(JSTSP)11(7), 1004–1019 (2017).https://doi.org/10.1109/jstsp.2017.2737965
-
[41]
In: European Conference on Computer Vision (ECCV)
Zeller, N., Quint, F., Stilla, U.: Scale-awareness of light-field camera-based visual odometry. In: European Conference on Computer Vision (ECCV). p. 732–747. Springer (2018).https://doi.org/10.1007/978-3-030-01237-3_44
-
[42]
A Synchronized Stereo and Plenoptic Visual Odometry Dataset
Zeller, N., Quint, F., Stilla, U.: A synchronized stereo and plenoptic visual odome- try dataset. arXiv preprint arXiv:1807.09372 (2018).https://doi.org/10.48550/ arXiv.1807.09372
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[43]
Optical Engineering59(7), 073104– 073104 (2020).https://doi.org/10.1117/1.oe.59.7.073104
Zhao, Y., Li, H., Mei, D., Shi, S.: Metric calibration of unfocused plenoptic cam- eras for three-dimensional shape measurement. Optical Engineering59(7), 073104– 073104 (2020).https://doi.org/10.1117/1.oe.59.7.073104
-
[44]
Optics and Lasers in Engineering115, 190–196 (2019).https://doi.org/10.1016/j.optlaseng.2018.11.024
Zhou, P., Cai, W., Yu, Y., Zhang, Y., Zhou, G.: A two-step calibration method of lenslet-based light field cameras. Optics and Lasers in Engineering115, 190–196 (2019).https://doi.org/10.1016/j.optlaseng.2018.11.024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.