Scaling Diverse Language Generation for 3D Visual Grounding
Pith reviewed 2026-06-26 16:56 UTC · model grok-4.3
The pith
A scalable method using scene graphs and LLMs generates diverse 3D visual grounding queries that improve model performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
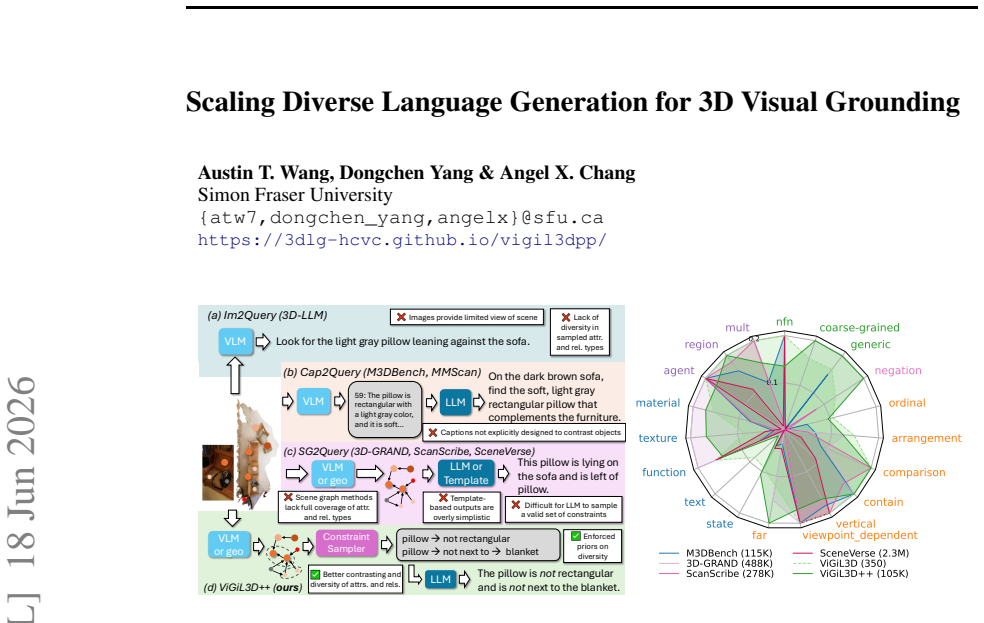
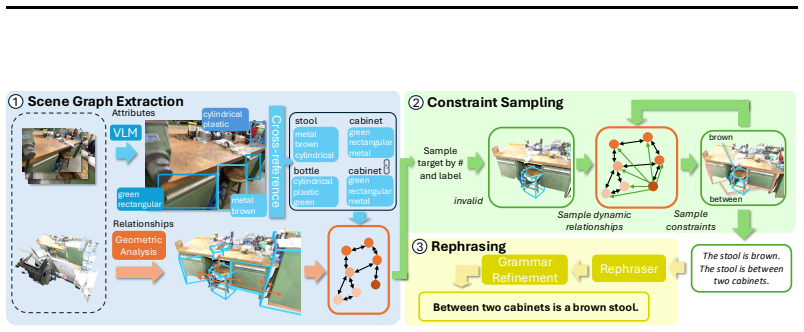
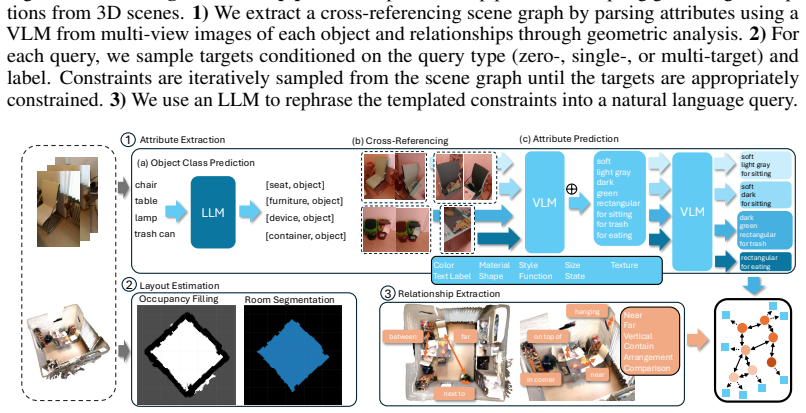
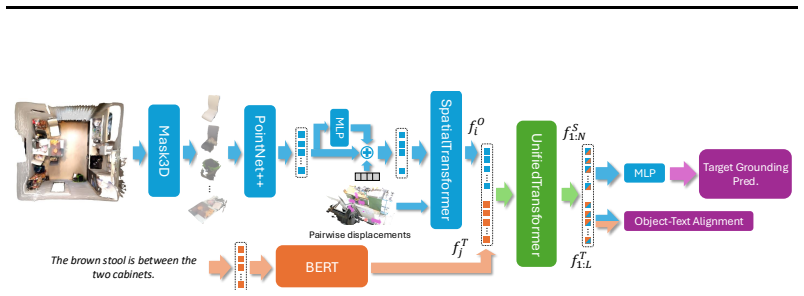
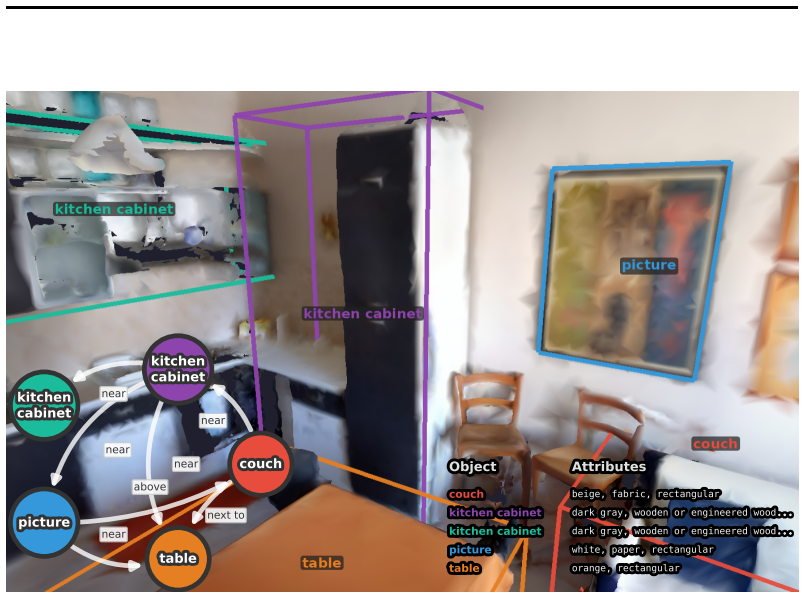
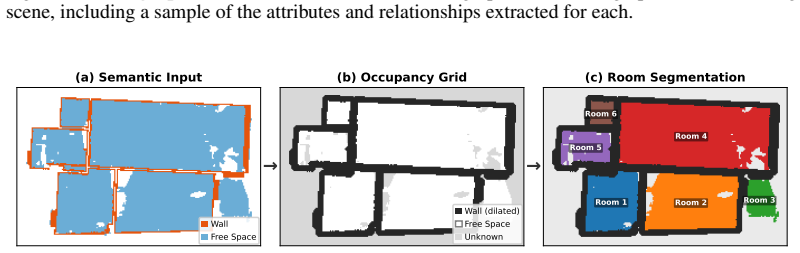
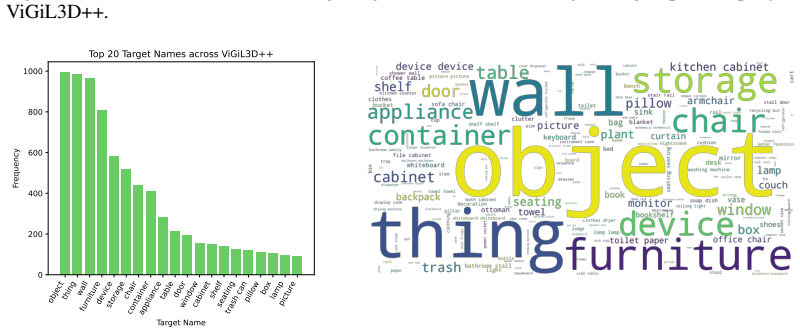
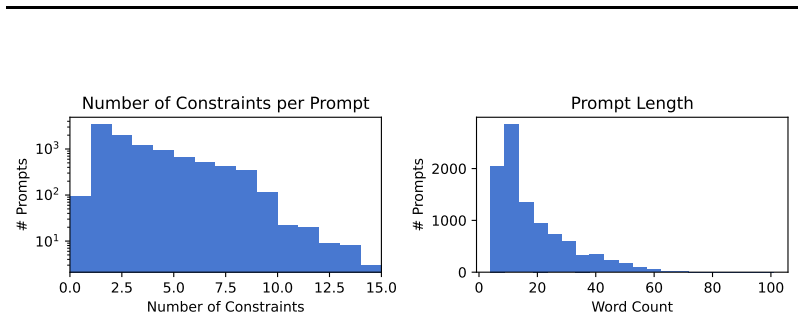
ViGiL3D++ is a scene-agnostic pipeline that samples constraint types from scene graphs and uses LLMs to generate natural language queries realizing those constraints. The resulting data shows greater diversity in language and constraint types than prior scaled datasets. Models trained on it achieve higher performance across several 3D visual grounding benchmarks, yet the evaluation also reveals ongoing limitations in how well VLMs handle the generated queries.
What carries the argument
ViGiL3D++, which samples scene-graph constraints and prompts LLMs to produce corresponding natural language descriptions for visual grounding.
If this is right
- Training on the generated queries leads to better generalization on 3DVG benchmarks.
- The dataset enables evaluation of models on a wider range of linguistic patterns and constraint combinations.
- It provides a way to scale up data without relying on human annotation for every description.
- The method highlights that VLMs have trouble with certain types of complex grounding even when trained on diverse data.
Where Pith is reading between the lines
- The approach might transfer to generating data for other tasks involving spatial language and 3D scenes, such as navigation or manipulation.
- Biases or hallucinations from the LLMs could affect the quality of the data in ways not fully captured by the diversity metrics.
- Future work could combine this generation with verification mechanisms to reduce semantic drift.
- This could help in creating more robust benchmarks that better test compositional understanding in grounding models.
Load-bearing premise
LLM outputs will faithfully express only the sampled scene graph constraints without adding unintended details or errors.
What would settle it
If a large sample of the generated queries is manually verified against their source scene graphs and many are found to contain mismatches or extra information, the performance improvements could be attributed to noise rather than true diversity gains.
Figures


read the original abstract
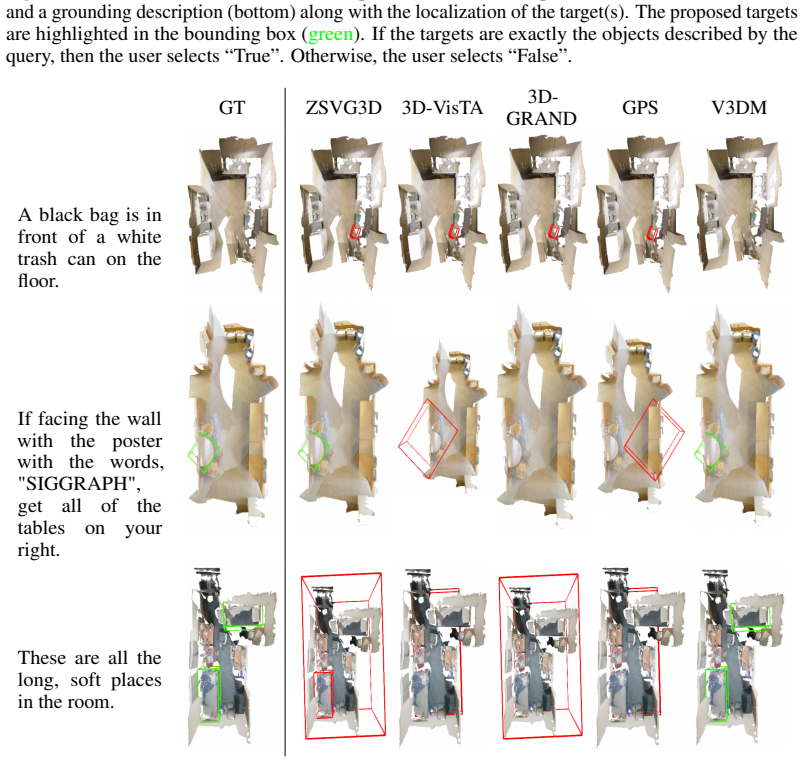
Developing robust models for 3D visual grounding (3DVG), the localization of entities in a 3D scene described in natural language, is important for enabling agents to correspond spatial language with objects in the physical world. However, the lack of diverse descriptions at scale prevents models from generalizing beyond simple linguistic patterns. Recent such attempts lack diversity in the constraint types and language used to ground objects. Captioning methods cannot precisely contrast objects, which is important for visual grounding. We therefore propose ViGiL3D++, a scalable, scene-agnostic method that generates diverse visual grounding queries by combining constraint sampling in scene graphs with the language generation of LLMs. We show that it has greater diversity over existing scaled datasets and improves model performance over several 3DVG benchmarks but also illuminates outstanding limitations of VLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes ViGiL3D++, a scalable scene-agnostic method for generating diverse natural-language queries for 3D visual grounding. Constraints are sampled from scene graphs and fed to LLMs to produce sentences; the authors claim this yields greater diversity than existing scaled datasets, improves performance on multiple 3DVG benchmarks, and reveals limitations of current VLMs.
Significance. If the generated queries are shown to be faithful realizations of the sampled constraints, the approach would address a documented gap in 3DVG training data by enabling controlled diversity at scale, moving beyond the limitations of captioning methods that cannot precisely contrast objects. This could support better generalization in spatial language grounding tasks.
major comments (1)
- [Method / generation procedure] Method / generation procedure: The central claims of greater diversity and benchmark gains rest on the premise that LLM-generated sentences faithfully realize exactly the sampled scene-graph constraints (no extra relations, no dropped constraints, no object mis-identifications). No quantitative check—constraint-adherence rate, human verification of a held-out sample, or direct comparison of generated text against the original graph—is reported. This verification is load-bearing; without it, diversity metrics and performance improvements cannot be attributed to controlled constraint coverage rather than LLM style, data volume, or noise.
minor comments (1)
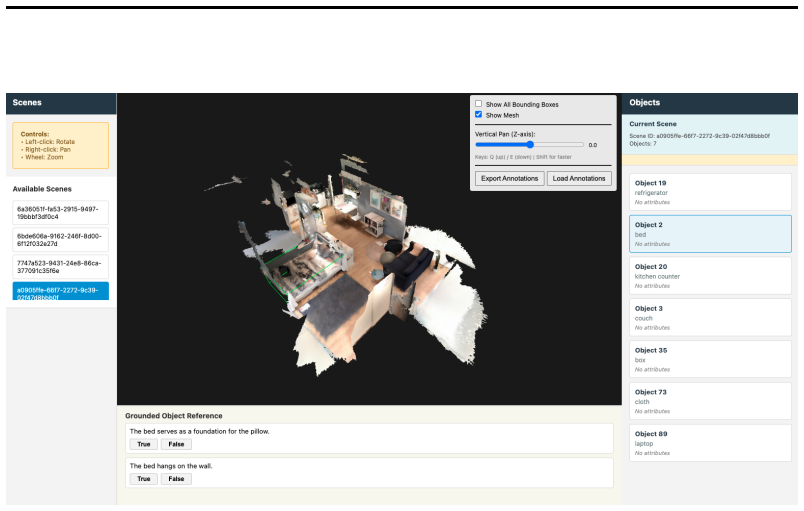
- [Abstract] Abstract: The abstract states diversity gains and benchmark improvements but supplies no numerical values, diversity measures, or ablation details, forcing readers to consult later sections for any assessment of the claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback emphasizing the need to verify constraint fidelity. We address the major comment below.
read point-by-point responses
-
Referee: The central claims of greater diversity and benchmark gains rest on the premise that LLM-generated sentences faithfully realize exactly the sampled scene-graph constraints (no extra relations, no dropped constraints, no object mis-identifications). No quantitative check—constraint-adherence rate, human verification of a held-out sample, or direct comparison of generated text against the original graph—is reported. This verification is load-bearing; without it, diversity metrics and performance improvements cannot be attributed to controlled constraint coverage rather than LLM style, data volume, or noise.
Authors: We agree that explicit verification of constraint adherence is necessary to attribute gains specifically to controlled coverage. Our pipeline samples constraints from scene graphs and prompts the LLM with instructions to realize exactly those constraints in the output sentence. However, the manuscript does not include a quantitative adherence rate, human verification on a held-out sample, or automated comparison of generated text to the input graph. We will add this analysis in revision, reporting both automated parsing where feasible and human evaluation of adherence on a sample of generations. revision: yes
Circularity Check
No circularity in empirical generation procedure
full rationale
The paper presents an empirical method that samples constraints from scene graphs and prompts LLMs to generate natural-language queries for 3D visual grounding. Diversity and benchmark gains are reported via direct measurement on external datasets and models. No mathematical derivations, equations, fitted parameters, or predictions are claimed that could reduce to self-referential inputs by construction. The central construction relies on independent external components (scene graphs, LLMs) rather than any self-definition or load-bearing self-citation chain. This is the expected non-finding for a purely empirical scaling paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Scene graphs provide a complete and accurate basis for sampling contrastive constraints in 3D scenes.
- domain assumption LLMs can reliably translate sampled constraints into diverse, accurate natural language without semantic alteration.
Reference graph
Works this paper leans on
-
[1]
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova
URL https://openaccess.thecvf.com/content/CVPR2024/papers/Delitzas_ SceneFun3D_Fine-Grained_Functionality_and_Affordance_Understanding_in_ 3D_Scenes_CVPR_2024_paper.pdf. Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. Bert: Pre-training of deep bidirectional transformers for language understanding. InProceedings of the 2019 conference of...
-
[2]
Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, and Junwei Liang
URLhttps://arxiv.org/abs/2312.10763. Rong Li, Shijie Li, Lingdong Kong, Xulei Yang, and Junwei Liang. SeeGround: See and ground for zero-shot open-vocabulary 3D visual grounding. InProceedings of the Computer Vision and Pattern Recognition Conference, pp. 3707–3717, 2025. Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv prepri...
-
[3]
Habitat-Matterport 3D Dataset (HM3D): 1000 Large-scale 3D Environments for Embodied AI
URLhttps://arxiv.org/abs/2109.08238. Jonas Schult, Francis Engelmann, Alexander Hermans, Or Litany, Siyu Tang, and Bastian Leibe. Mask3D: Mask transformer for 3D semantic instance segmentation. InIEEE International Conference on Robotics and Automation (ICRA), pp. 8216–8223. IEEE, 2023. URLhttps://arxiv.org/abs/2210.03105. Chantal Shaib, Venkata S Govinda...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.01366 2023
-
[4]
URLhttps://arxiv.org/abs/2309.05251. Zhuofan Zhang, Ziyu Zhu, Pengxiang Li, Tengyu Liu, Xiaojian Ma, Yixin Chen, Baoxiong Jia, Siyuan Huang, and Qing Li. Task-oriented sequential grounding in 3D scenes.arXiv preprint arXiv:2408.04034, 2024b. URLhttps://arxiv.org/abs/2408.04034. Jiahe Zhao, Ruibing Hou, Zejie Tian, Hong Chang, and Shiguang Shan. HIS-GPT: T...
-
[14]
|", and no other text. The descriptions should vary in content and style
There is a row of black rolling chairs along the wall. Pick the one furthest to the left when facing them. You should return {num_candidates} candidate descriptions, separated by "|", and no other text. The descriptions should vary in content and style. """ Listing 1:Im2Query Prompt.We provide a list of annotated multiple views and the target name and ask...
-
[15]
Of such boxes, it is the one not next to an armchair
This is a cardboard box against the wall and right next to two doors. Of such boxes, it is the one not next to an armchair
-
[16]
On the brown, wooden table is a small, rectangular projector
-
[17]
This is the larger of the two toolboxes near the piano
-
[18]
Find the object with wheels
-
[19]
When facing the radiator, the metal rail is directly on your left
-
[20]
To the left of the sink is a set of paper towel rolls
-
[21]
This circular object is supported by a white mini fridge
-
[22]
Underneath the sink is a cabinet for storing cleaning supplies
-
[23]
Locate the tallest appliance in the kitchen
-
[24]
|", and no other text. The descriptions should vary in content and style
There is a row of black rolling chairs along the wall. Pick the one furthest to the left when facing them. You should return {num_candidates} candidate descriptions, separated by "|", and no other text. The descriptions should vary in content and style. """ Listing 2:Cap2Query Prompt.We provide a list of annotated multiple views for each object and ask th...
2014
-
[25]
on" (inverse:
"on" (inverse: "s u p p o r t s"):if the subject object is physically resting on top of the recipient object (e.g . a book on a table, a bottle on a shelf)
-
[26]
i n" (inverse:
"i n" (inverse: "c o n t a i n s"): if the subject object is physically inside, or embedded inside, the recipient object (e.g. a book in a box, a cup in a cupboard, door in a wall)
-
[27]
embeddedi n
"embeddedi n" (inverse: "embeds"): if the subject object is partially inside the recipient object, such that part of the subject is accessible at the surface of the recipient (e.g. a stove embedded in the counter, a sink embedded in the counter)
-
[28]
l e a n i n g on
"l e a n i n g on" (inverse: "s u p p o r t s"):if the subject object is leaning against the recipient object, such that if you were to remove the recipient, the subject would obviously fall. Horizontal contact of one object against another on its own does not count as leaning (e.g. a ladder leaning on a wall, an instrument case leaning against a table)
-
[29]
h a n g i n g on
"h a n g i n g on" (inverse: "s u p p o r t s"):if the subject object is hanging from the recipient object (e.g. a towel hanging on a rack, a lamp hanging from the ceiling, a picture hanging on the wall)
-
[30]
none" (inverse:
"none" (inverse: "none"): if none of the above relationships apply. # How to Determine the Relationship You will be provided the IDs and labels of the objects. The objects of interest should be marked with blue ( subject) and orange (recipient) outlines around the objects, and ignore the highlighted red area. You should determine the appropriate relations...
-
[31]
on" the shelf and not
How are the objects typically described? (e.g. if a book is supported by a shelf, the book is usually described as "on" the shelf and not "i n" the shelf)
-
[32]
none") # Output Format The output should be a JSON object with the following format: {
Are the objects in the scene actually exhibiting the relationship? (e.g. if the book is actually only next to the table, then the relationship is "none") # Output Format The output should be a JSON object with the following format: { "s u b j e c t _ t o _ r e c i p i e n t":one of ["s u p p o r t s","on", "c o n t a i n s", "i n", "l e a n i n g on", "h ...
2021
-
[33]
a", "an",
or by prompting a VLM with the rendered image (Wang et al., 2024b; Yang et al., 2024b). Object attributes are typically obtained from a combination of ground-truth annotations (e.g. semantic class of the object), 3D reasoning (e.g. using the size of the bounding box to estimate the size of the object), and appearance attributes (e.g. color, style) from a ...
2014
-
[34]
Go to <URL> to view the scene assignments
-
[35]
In the scene viewer, select the corresponding scene ID from the left bar
-
[36]
The object should be marked with a green bounding box in the visualizer
Click on an object in the``Objects'' tab on the right to pull up all of the descriptions of that object in the scene. The object should be marked with a green bounding box in the visualizer
-
[37]
For multi-target prompts, click on``Multi-Target Prompts'' on the right side and then click on each prompt to see its corresponding targets
-
[38]
For zero-target prompts, no objects will be marked in the scene
-
[39]
For each description, select``True'' if the prompt correctly describes every annotated target (and no other segmented objects in the scene), or``False'' otherwise
-
[40]
True”. Otherwise, the user selects “False
Export and upload your annotation at <URL>. Listing 11:User study instructions. Unique Multiple Overall Trained Acc@25 Acc@50 Acc@25 Acc@50 Acc@25 Acc@50 3D-VisTA ScanScribe 46.1 43.6 20.3 18.4 25.3 23.3 GPS SceneVerse50.1 46.819.9 17.7 25.8 23.4 V3DM ViGiL3D++ 44.0 41.3 17.4 15.6 22.5 20.6 V3DM ViGiL3D++ SR 48.0 45.3 22.8 20.8 27.7 25.5 Table 14: Accurac...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.