Learning Stable Canonical Worlds for Novel View Synthesis and Beyond
Pith reviewed 2026-06-26 09:14 UTC · model grok-4.3
The pith
CanonicalGS builds stable scene representations by fusing multi-view evidence with uncertainty weighting to prioritize reliable observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
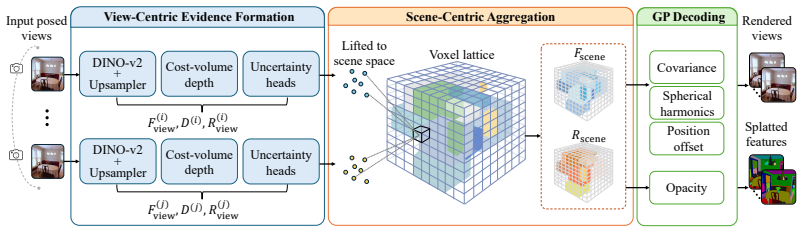
CanonicalGS maps cluttered multi-view observations into a stable, scene-centric representation by extracting view-centric evidence from depth, semantic features, and uncertainty estimates, then aggregating this evidence in a canonical latent world using uncertainty-aware fusion that emphasizes reliable observations while suppressing uncertain or redundant ones.
What carries the argument
Uncertainty-aware fusion inside the canonical latent world, which weights evidence extracted from depth, semantic features, and uncertainty estimates to suppress unreliable inputs.
If this is right
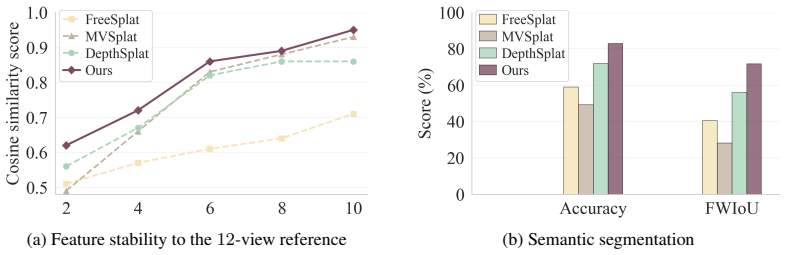
- Novel view synthesis quality improves rather than plateaus or degrades as more input views are supplied.
- The resulting representations transfer to raise semantic segmentation accuracy by 11 percent on downstream tasks.
- The pipeline remains fully feed-forward and real-time while achieving up to 2.5 dB higher PSNR.
- Redundant or noisy observations are suppressed, preventing accumulation of errors in cluttered multi-view settings.
Where Pith is reading between the lines
- The canonical latent world could serve as a reusable prior for other 3D perception modules beyond the tasks tested.
- Uncertainty estimates might be repurposed to guide active selection of new camera views during data capture.
- The same fusion logic could extend to non-Gaussian scene representations such as neural radiance fields or voxel grids.
Load-bearing premise
The uncertainty estimates extracted from depth and semantic features are reliable indicators for weighting the fusion process.
What would settle it
If increasing the number of input views fails to raise or even lowers PSNR on novel views while standard feed-forward methods also fail to improve, the scaling benefit of the canonical fusion would be falsified.
Figures









read the original abstract
Feed-forward Gaussian splatting (FFGS) facilitates real-time novel view synthesis, yet current methods often remain tied to view-dependent predictions. As more input views are added, they may accumulate noisy or redundant evidence instead of converging to a stable scene representation. In this paper, we introduce CanonicalGS, a feed-forward pipeline that maps cluttered multi-view observations into a stable, scene-centric representation. CanonicalGS first extracts view-centric evidence from depth, semantic features, and uncertainty estimates, and then aggregates this evidence in a canonical latent world using uncertainty-aware fusion. By emphasizing reliable observations while suppressing uncertain or redundant ones, CanonicalGS produces representations that scale more effectively for novel view synthesis and transfer to downstream visual perception tasks. Experiments show up to a $2.5$ dB improvement in peak signal-to-noise ratio for synthesizing novel views and an $11\%$ gain in semantic segmentation accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CanonicalGS, a feed-forward Gaussian splatting pipeline that extracts view-centric evidence (depth, semantic features, and uncertainty estimates) from multi-view observations and aggregates it into a stable canonical latent world via uncertainty-aware fusion. The central claim is that this emphasis on reliable observations (while suppressing uncertain or redundant ones) yields representations that scale more effectively with added views for novel view synthesis and transfer to downstream tasks such as semantic segmentation, with reported gains of up to 2.5 dB PSNR and 11% accuracy.
Significance. If the uncertainty estimates are well-calibrated and the fusion step demonstrably improves stability and scaling, the approach could address a key limitation of existing feed-forward methods by preventing noise accumulation in multi-view settings. This would strengthen real-time NVS pipelines and enable better transfer to perception tasks. The introduction of a canonical latent world as an aggregation target is a potentially useful organizing concept, though its novelty relative to existing canonical representations in 3D vision requires clarification.
major comments (2)
- [Abstract] Abstract: The abstract asserts quantitative improvements (2.5 dB PSNR for NVS and 11% segmentation accuracy) and attributes them to uncertainty-aware fusion, yet supplies no information on datasets, baselines, number of input views, implementation of the fusion operator, or how uncertainty is extracted and normalized. Without these details the central claim that the method 'scales more effectively' cannot be evaluated.
- [Method (uncertainty-aware fusion)] Method description of uncertainty-aware fusion: The pipeline relies on uncertainty estimates from depth and semantic features to weight observations during aggregation into the canonical latent world. No calibration study, correlation analysis with ground-truth reliability, or ablation removing the uncertainty weighting is described; if these estimates are poorly calibrated the fusion reduces to unweighted averaging and the claimed scaling/stability benefit does not follow.
minor comments (1)
- [Abstract] The abstract introduces the term 'canonical latent world' without a concise formal definition or pointer to the section where its construction is specified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to improve clarity and strengthen the validation of our claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts quantitative improvements (2.5 dB PSNR for NVS and 11% segmentation accuracy) and attributes them to uncertainty-aware fusion, yet supplies no information on datasets, baselines, number of input views, implementation of the fusion operator, or how uncertainty is extracted and normalized. Without these details the central claim that the method 'scales more effectively' cannot be evaluated.
Authors: We agree that the abstract, while necessarily concise, would benefit from additional context to allow readers to evaluate the claims. In the revised manuscript we will expand the abstract to briefly specify the primary datasets, the range of input views evaluated, and high-level details on the uncertainty extraction (from depth and semantic heads) and the fusion operator. Complete experimental protocols, baselines, and implementation details remain in Sections 4 and 5. revision: yes
-
Referee: [Method (uncertainty-aware fusion)] Method description of uncertainty-aware fusion: The pipeline relies on uncertainty estimates from depth and semantic features to weight observations during aggregation into the canonical latent world. No calibration study, correlation analysis with ground-truth reliability, or ablation removing the uncertainty weighting is described; if these estimates are poorly calibrated the fusion reduces to unweighted averaging and the claimed scaling/stability benefit does not follow.
Authors: The referee correctly notes the absence of explicit validation for the uncertainty estimates. Section 3 describes the extraction and use of uncertainty for weighting, but the manuscript does not include calibration analysis or an ablation against uniform averaging. We will add these elements in the revision: (i) calibration plots and expected calibration error on held-out data, (ii) correlation between predicted uncertainty and observed reconstruction error, and (iii) an ablation comparing uncertainty-weighted fusion to unweighted averaging to quantify the scaling benefit. revision: yes
Circularity Check
No significant circularity; pipeline is self-contained with independent empirical assumptions
full rationale
The paper presents CanonicalGS as a feed-forward pipeline that extracts view-centric evidence (depth, semantics, uncertainty) and performs uncertainty-aware fusion in a canonical latent space. The scaling benefit is claimed to follow from the fusion step emphasizing reliable observations, but this rests on the external assumption that the extracted uncertainties are calibrated indicators of reliability—an empirical claim, not a definitional or fitted reduction. No equations or steps reduce by construction to their own inputs, no self-citation chains are load-bearing for the core derivation, and no predictions are statistically forced by parameter fitting. The derivation remains independent of the target results.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Canonical latent world
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Xin Fei, Wenzhao Zheng, Yueqi Duan, Wei Zhan, Masayoshi Tomizuka, Kurt Keutzer, and Jiwen Lu. Pixel- Gaussian: Generalizable 3D Gaussian reconstruction from arbitrary views.arXiv preprint arXiv:2410.18979,
-
[2]
Ranran Huang and Krystian Mikolajczyk. No pose at all: Self-supervised pose-free 3D Gaussian splatting from sparse views.arXiv preprint arXiv:2508.01171,
-
[3]
GlobalSplat: Efficient Feed-Forward 3D Gaussian Splatting via Global Scene Tokens
Roni Itkin, Noam Issachar, Yehonatan Keypur, Anpei Chen, and Sagie Benaim. GlobalSplat: Efficient feed- forward 3D Gaussian splatting via global scene tokens.arXiv preprint arXiv:2604.15284,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
Lihan Jiang, Yucheng Mao, Linning Xu, Tao Lu, Kerui Ren, Yichen Jin, Xudong Xu, Mulin Yu, Jiangmiao Pang, Feng Zhao, et al. AnySplat: Feed-forward 3D Gaussian splatting from unconstrained views.arXiv preprint arXiv:2505.23716,
-
[5]
Yihui Li, Chengxin Lv, Zichen Tang, Hongyu Yang, and Di Huang. TokenSplat: Token-aligned 3D Gaussian splatting for feed-forward pose-free reconstruction.arXiv preprint arXiv:2603.00697,
-
[6]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. DINOv2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Chen, Zeyu Zhang, Duochao Shi, Akide Liu, and Bohan Zhuang
Weijie Wang, Donny Y . Chen, Zeyu Zhang, Duochao Shi, Akide Liu, and Bohan Zhuang. ZPressor: Bottleneck- aware compression for scalable feed-forward 3DGS.arXiv preprint arXiv:2505.23734, 2025a. Weijie Wang, Yeqing Chen, Zeyu Zhang, Hengyu Liu, Haoxiao Wang, Zhiyuan Feng, Wenkang Qin, Feng Chen, Zheng Zhu, Donny Y . Chen, et al. V olSplat: Rethinking feed-...
-
[8]
arXiv preprint arXiv:2410.24207 , year=
Botao Ye, Sifei Liu, Haofei Xu, Xueting Li, Marc Pollefeys, Ming-Hsuan Yang, and Songyou Peng. No pose, no problem: Surprisingly simple 3D Gaussian splats from sparse unposed images.arXiv preprint arXiv:2410.24207,
-
[9]
12 Botao Ye, Boqi Chen, Haofei Xu, Daniel Barath, and Marc Pollefeys. YoNoSplat: You only need one model for feedforward 3D Gaussian splatting.arXiv preprint arXiv:2511.07321,
-
[10]
Dagger ( †) marks Gaussian-space merging variants
in the bounded-view setting. Dagger ( †) marks Gaussian-space merging variants. Method PSNR↑SSIM↑LPIPS↓ MVSplat 26.39 0.869 0.128 DepthSplat 26.84 0.878 0.122 MVSplat† 24.50 0.701 0.188 DepthSplat† 25.22 0.840 0.166 FreeSplat 26.41 0.871 0.132 ZPressor 24.70 0.827 0.176 CanonicalGS (Ours)27.36 0.886 0.114 Table 7:Zero-shot transfer to ACID (Liu et al., 20...
2021
-
[11]
Table 7 shows that CanonicalGS transfers best across datasets while using fewer parameters than FreeSplat (Wang et al.,
with four target views, following the DepthSplat split (Xu et al., 2025). Table 7 shows that CanonicalGS transfers best across datasets while using fewer parameters than FreeSplat (Wang et al.,
2025
-
[12]
This result suggests that aggregating reliable evidence in scene space improves generalization, rather than merely increasing model capacity
and ZPressor (Wang et al., 2025a). This result suggests that aggregating reliable evidence in scene space improves generalization, rather than merely increasing model capacity. C Runtime Analysis We report inference efficiency on DL3DV with256×256 images, four input views, 50 target views, and batch size one. Table 8 compares rendering speed in frames per...
2024
-
[13]
and DL3DV (Ling et al., 2024). Across increasing input views, CanonicalGS more consistently preserves geometry and appearance, supporting the quantitative trend that additional observations are consolidated rather than accumulated as independent view-centric predictions. Figs 8–10 show additional semantic segmentation visualizations on RE10K. Each figure ...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.