Test-Time Speculation
Pith reviewed 2026-05-20 22:49 UTC · model grok-4.3
The pith
Adapting the draft model online during generation keeps acceptance lengths high for long LLM outputs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By running online distillation at test time, where each verification step supplies the target model's outputs as training labels for the draft model at no extra cost, the speculator adapts to the specific long generation in progress and thereby maintains substantially longer acceptance lengths than any fixed offline-trained speculator.
What carries the argument
Test-Time Speculation (TTS), the online adaptation loop that updates the draft model after each verification round using the target's token predictions as supervision.
If this is right
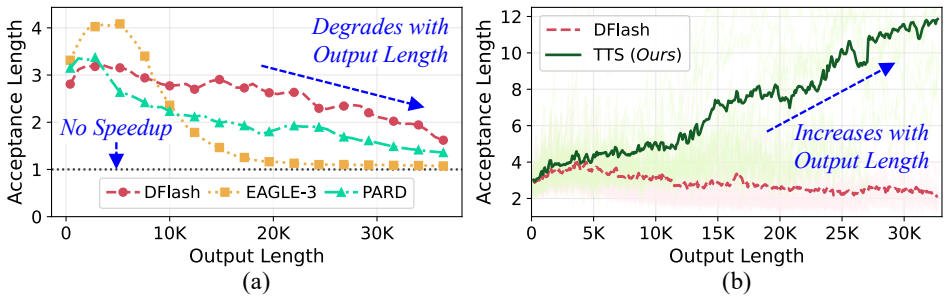
- Acceptance lengths rise by up to 72 percent over current state-of-the-art speculators on the tested models.
- Average gains reach 41 percent across Qwen-3, Qwen-3.5, and Llama 3.1 families.
- The improvement grows larger as the number of generated tokens increases.
- Speculative decoding retains useful speedup on long-response tasks where it previously provided almost none.
Where Pith is reading between the lines
- The same verification-driven update idea could be applied to other inference-time components that drift from their training distribution during extended outputs.
- Choosing different frequencies or learning rates for the online updates might further improve the speed-accuracy trade-off.
- This form of test-time adaptation may become standard for any draft model used in production systems that handle variable-length responses.
Load-bearing premise
The verification steps already provide enough training signal to improve the draft model's accuracy over time without adding net latency or causing instability in the updates.
What would settle it
Running TTS on a long-generation benchmark and observing that acceptance length still drops to near one after several thousand tokens, or that the added update steps increase total latency, would falsify the claim.
Figures






read the original abstract
Speculative decoding accelerates LLM inference by using a fast draft model to generate tokens and a more accurate target model to verify them. Its performance depends on the $\textit{acceptance length}$, or number of draft tokens accepted by the target. Our studies show that the acceptance length of even state-of-the-art speculators, like DFlash, EAGLE-3 and PARD degrade with generation length, reaching values close to 1 (i.e. no speedup) within just a few thousand output tokens, making speculators ineffective for long-response tasks. Acceptance lengths decline because most speculators are trained offline on short sequences, but are forced to match the target model on much longer outputs at inference, well beyond their training distribution. To address this issue, we propose $\textit{Test-Time Speculation (TTS)}$, an online distillation approach that continuously adapts the speculator at test-time. TTS leverages the key insight that the token verification step already invokes the target model for each draft token, providing the training signal needed to adapt the draft at no additional cost. Treating the draft as the student and the target as a teacher, TTS adjusts the draft over several speculation rounds, with each update improving the draft's accuracy as generation proceeds. Our results across multiple models from the Qwen-3, Qwen-3.5, and Llama3.1 families show that TTS improves acceptance lengths over state-of-the-art speculators by up to $72\%$ and $41\%$ on average, with the benefits scaling with increased generation lengths.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that acceptance lengths in speculative decoding degrade with longer generation sequences because speculators are trained offline on short sequences. It proposes Test-Time Speculation (TTS), an online distillation method that adapts the draft model using target model verification signals during inference at no additional cost. Experiments on Qwen-3, Qwen-3.5, and Llama3.1 families show acceptance length improvements of up to 72% and 41% on average, with benefits scaling as generation length increases.
Significance. If the no-cost adaptation claim holds and delivers net wall-clock gains, TTS could extend speculative decoding to long-form tasks where current methods fail. The multi-model family evaluation is a strength, but missing experimental details limit assessment of practical impact.
major comments (2)
- [Abstract] Abstract: The claim that the verification step supplies the training signal 'at no additional cost' is load-bearing for the net speedup argument. Any online update (gradient step, LoRA, or optimizer) on the draft model requires forward/backward passes beyond the target verification pass; without a timing or FLOPs breakdown separating these, it is unclear whether the reported acceptance-length gains already net out adaptation overhead or apply only to long generations.
- [Results] Results: The stated 41% average and up to 72% gains, plus the scaling-with-length claim, are presented without tables, error bars, run counts, or exact generation-length ranges. This prevents verification that improvements are robust rather than post-hoc and directly affects the central empirical contribution.
minor comments (2)
- [Abstract] Abstract: 'speculators' is used without explicit definition on first occurrence; clarify whether it denotes the draft model, the full algorithm, or both.
- Consider adding a plot of acceptance length versus output length for TTS versus baselines to make the scaling observation visually concrete.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments. We address the major comments point by point below, providing clarifications and committing to revisions that strengthen the empirical support and cost analysis without overstating our current results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the verification step supplies the training signal 'at no additional cost' is load-bearing for the net speedup argument. Any online update (gradient step, LoRA, or optimizer) on the draft model requires forward/backward passes beyond the target verification pass; without a timing or FLOPs breakdown separating these, it is unclear whether the reported acceptance-length gains already net out adaptation overhead or apply only to long generations.
Authors: We appreciate the referee highlighting the importance of net wall-clock impact. The target verification pass is performed in any case during speculative decoding and supplies the necessary logits for the distillation signal. However, the subsequent gradient-based update on the draft model does require additional forward and backward computation on the smaller draft model. We agree that a quantitative breakdown is needed to substantiate the net-gain claim. In the revision we will add a dedicated subsection with measured wall-clock overhead and FLOPs for the adaptation steps across generation lengths, showing that the overhead remains small relative to target-model savings and that net speedup improves with sequence length. revision: yes
-
Referee: [Results] Results: The stated 41% average and up to 72% gains, plus the scaling-with-length claim, are presented without tables, error bars, run counts, or exact generation-length ranges. This prevents verification that improvements are robust rather than post-hoc and directly affects the central empirical contribution.
Authors: We agree that the current presentation lacks sufficient detail for independent verification. The revised manuscript will include full tables of acceptance lengths for each model family and generation-length bucket, report means and standard deviations over five independent runs, and explicitly state the tested output-length ranges (512–4096 tokens). We will also add a plot of acceptance length versus generation length to illustrate the scaling trend with error bands. revision: yes
Circularity Check
No circularity: empirical online adaptation with independent experimental support
full rationale
The paper describes TTS as an online distillation process that reuses the existing target-model verification step for draft adaptation, with performance gains demonstrated through direct experiments on acceptance lengths across Qwen and Llama families. No equations, derivations, or fitted parameters are shown that reduce the claimed improvements to self-referential quantities by construction. The method is presented as an empirical procedure whose benefits are measured externally rather than defined into existence, and no load-bearing self-citations or uniqueness theorems are invoked in the provided text.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The token verification step already invokes the target model for each draft token, providing the training signal needed to adapt the draft at no additional cost.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Treating the draft as the student and the target as a teacher, TTS adjusts the draft over several speculation rounds, with each update improving the draft's accuracy as generation proceeds.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
TTS improves acceptance lengths over state-of-the-art speculators by up to 72% and 41% on average, with the benefits scaling with increased generation lengths.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
International Conference on Machine Learning , pages=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[2]
Accelerating Large Language Model Decoding with Speculative Sampling
Accelerating large language model decoding with speculative sampling , author=. arXiv preprint arXiv:2302.01318 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
EAGLE-3: Scaling up Inference Acceleration of Large Language Models via Training-Time Test
Eagle-3: Scaling up inference acceleration of large language models via training-time test , author=. arXiv preprint arXiv:2503.01840 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
arXiv preprint arXiv:2602.06036 , year=
DFlash: Block Diffusion for Flash Speculative Decoding , author=. arXiv preprint arXiv:2602.06036 , year=
work page internal anchor Pith review arXiv
-
[5]
Pard: Accelerating llm inference with low-cost parallel draft model adaptation , author=. arXiv preprint arXiv:2504.18583 , year=
-
[6]
Training Verifiers to Solve Math Word Problems
Training verifiers to solve math word problems , author=. arXiv preprint arXiv:2110.14168 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
arXiv preprint arXiv:2408.07055 , year=
Longwriter: Unleashing 10,000+ word generation from long context llms , author=. arXiv preprint arXiv:2408.07055 , year=
-
[9]
Longbench: A bilingual, multitask benchmark for long context understanding , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
International Conference on Learning Representations (ICLR) , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. International Conference on Learning Representations (ICLR) , year=
-
[12]
ACM Transactions on Storage , year=
Mooncake: A kvcache-centric disaggregated architecture for llm serving , author=. ACM Transactions on Storage , year=
-
[13]
18th USENIX symposium on operating systems design and implementation (OSDI 24) , pages=
Taming \ Throughput-Latency \ tradeoff in \ LLM \ inference with \ Sarathi-Serve \ , author=. 18th USENIX symposium on operating systems design and implementation (OSDI 24) , pages=
-
[14]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
gpt-oss-120b & gpt-oss-20b Model Card
gpt-oss-120b & gpt-oss-20b model card , author=. arXiv preprint arXiv:2508.10925 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
LongSpec: Long-Context Lossless Speculative Decoding with Efficient Drafting and Verification
LongSpec: Long-Context Lossless Speculative Decoding with Efficient Drafting and Verification , author=. arXiv preprint arXiv:2502.17421 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
The Twelfth International Conference on Learning Representations , year=
YaRN: Efficient Context Window Extension of Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[19]
arXiv preprint arXiv:2512.02337 , year=
SpecPV: Improving Self-Speculative Decoding for Long-Context Generation via Partial Verification , author=. arXiv preprint arXiv:2512.02337 , year=
-
[20]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Enhancing chat language models by scaling high-quality instructional conversations , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
- [21]
-
[22]
Advances in neural information processing systems , volume=
Learning to summarize with human feedback , author=. Advances in neural information processing systems , volume=
-
[23]
Advances in neural information processing systems , volume=
Language models are few-shot learners , author=. Advances in neural information processing systems , volume=
-
[24]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. arXiv preprint arXiv:2403.07974 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
The twelfth international conference on learning representations , year=
Let's verify step by step , author=. The twelfth international conference on learning representations , year=
-
[26]
Measuring Mathematical Problem Solving With the MATH Dataset
Measuring mathematical problem solving with the math dataset , author=. arXiv preprint arXiv:2103.03874 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[27]
Olympiadbench: A challenging benchmark for promoting agi with olympiad-level bilingual multimodal scientific problems , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[28]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
Gpqa: A graduate-level google-proof q&a benchmark , author=. arXiv preprint arXiv:2311.12022 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Theoremqa: A theorem-driven question answering dataset , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
- [30]
- [31]
- [32]
-
[33]
arXiv preprint arXiv:2310.07177 , year=
Online speculative decoding , author=. arXiv preprint arXiv:2310.07177 , year=
- [34]
-
[35]
Lmsys-chat-1m: A large-scale real-world llm conversation dataset , author=. arXiv preprint arXiv:2309.11998 , year=
-
[36]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
Gqa: Training generalized multi-query transformer models from multi-head checkpoints , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2023
-
[37]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer , author=. arXiv preprint arXiv:1701.06538 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[38]
Journal of Machine Learning Research , volume=
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity , author=. Journal of Machine Learning Research , volume=
-
[39]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Mamba: Linear-time sequence modeling with selective state spaces , author=. arXiv preprint arXiv:2312.00752 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[40]
arXiv preprint arXiv:2508.08192 , year=
Efficient speculative decoding for llama at scale: Challenges and solutions , author=. arXiv preprint arXiv:2508.08192 , year=
-
[41]
Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task , author=. Proceedings of the 2018 conference on empirical methods in natural language processing , pages=
work page 2018
-
[42]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
Codesearchnet challenge: Evaluating the state of semantic code search , author=. arXiv preprint arXiv:1909.09436 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1909
-
[43]
Finance-Alpaca: An Instruction-Following Dataset for Financial Question Answering , author=. 2023 , howpublished=
work page 2023
-
[44]
Advances in neural information processing systems , volume=
Sglang: Efficient execution of structured language model programs , author=. Advances in neural information processing systems , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.