Dropout-GRPO: Variational Stochasticity for Continuous Latent Reasoning
Pith reviewed 2026-06-27 17:16 UTC · model grok-4.3
The pith
A fixed Bernoulli mask per rollout supplies the diversity GRPO needs by sampling from a variational posterior over parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
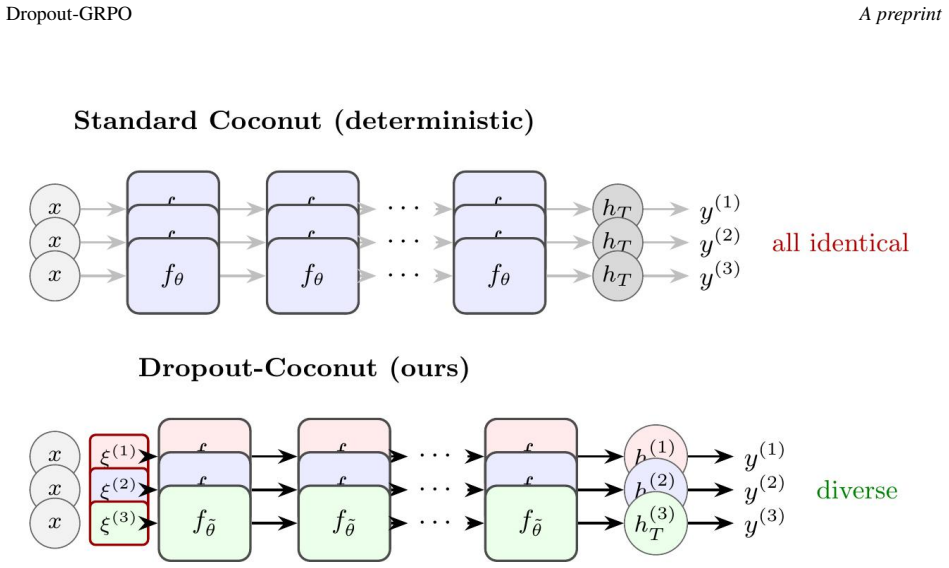
By applying a single Bernoulli mask held constant across all latent recurrence steps for a given rollout, the method generates essential trajectory variance. This shared mask effectively treats each rollout as a posterior sample from a variational distribution over parameters, allowing GRPO to optimize the expected reward of a Bayesian model-average policy while preserving unbiasedness, variance reduction, and well-defined latent gradients.
What carries the argument
A single Bernoulli dropout mask held constant across all latent recurrence steps within each rollout, which induces trajectory variance interpretable as variational posterior sampling over parameters.
If this is right
- GRPO becomes applicable to deterministic latent-reasoning models without trajectory collapse.
- The estimator for the group-relative advantage remains unbiased under the variational interpretation.
- Post-training of latent-reasoning LLMs can now use group-relative reinforcement learning.
- The same masking supplies both stochasticity and a well-defined gradient through the latent phase.
Where Pith is reading between the lines
- The same constant-mask construction could be tested on other recurrent latent architectures to check whether the variational interpretation generalizes.
- If the mask truly approximates posterior sampling, combining it with other policy-gradient methods beyond GRPO becomes a direct next step.
- Varying the mask probability across groups rather than fixing it might further reduce variance in the advantage estimates.
Load-bearing premise
That a shared Bernoulli mask across recurrence steps produces samples whose distribution matches a variational posterior over parameters well enough for the GRPO advantage estimator to stay unbiased and useful.
What would settle it
An experiment in which removing the shared-mask constraint (or replacing it with independent per-step masks) causes the observed performance gain on GSM8K to disappear while GRPO advantages become near-zero.
Figures
read the original abstract
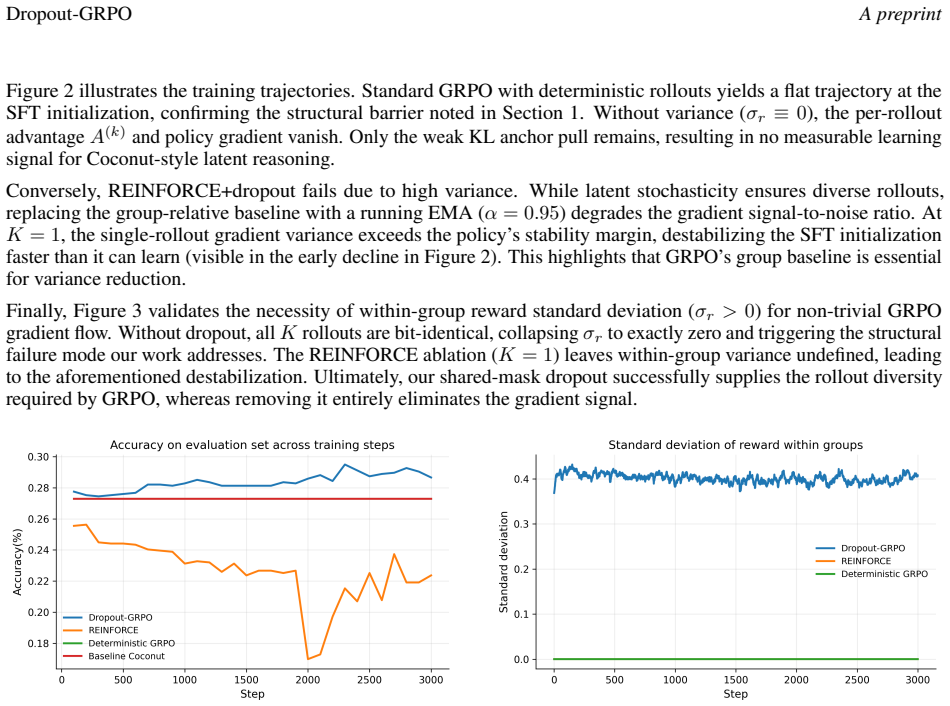
Group Relative Policy Optimization (GRPO) relies on the diversity of $K$ rollouts within each group; otherwise, the group-mean advantage $A^{(k)} = r^{(k)} - \mu_r$ collapses to zero. This presents a structural challenge for latent-reasoning models like Coconut, which feed continuous hidden states recurrently in place of discrete chain-of-thought tokens. Because the latent phase is inherently deterministic given the parameters and prompt, multiple rollouts produce identical trajectories, stalling GRPO's progress. Consequently, applying group-relative reinforcement learning to continuous latent reasoning has proven difficult. To address this, we propose sourcing the necessary stochasticity through structured dropout. By applying a single Bernoulli mask held constant across all latent recurrence steps for a given rollout, we generate essential trajectory variance. This shared mask effectively treats each rollout as a posterior sample from a variational distribution over parameters, allowing GRPO to optimize the expected reward of a Bayesian model-average policy. We provide both theoretical justification for this method -- including unbiasedness, variance reduction, and the well-definedness of the latent gradient -- and empirical validation. On GSM8K, dropout-GRPO improves a Coconut baseline from $27.29\%$ to $29.01\%$ pass@1, demonstrating the viability of GRPO learning for latent-reasoning models. Our work positions this as a practical, theoretically grounded approach for post-training latent-reasoning LLMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Dropout-GRPO to enable Group Relative Policy Optimization (GRPO) for continuous latent-reasoning models such as Coconut. It introduces structured dropout via a single Bernoulli mask held fixed across all latent recurrence steps within a rollout, claiming this generates trajectory diversity by treating each rollout as a sample from a variational posterior over parameters. This is asserted to allow GRPO to optimize the expected reward of a Bayesian model-average policy, with theoretical properties of unbiasedness, variance reduction, and well-defined latent gradients. Empirically, the method improves pass@1 on GSM8K from 27.29% to 29.01%.
Significance. If the claimed theoretical properties hold, the approach would address a structural barrier to applying group-relative RL to deterministic latent-reasoning models and could support post-training of such architectures. The reported gain is modest and limited to a single task, so broader significance would depend on validation across additional benchmarks and confirmation that the variational equivalence supports unbiased advantage estimation.
major comments (2)
- [Theory section] Theory section (asserted justification for unbiasedness): The manuscript states that the shared-mask construction yields samples from a variational posterior q(θ) such that the group-relative advantage A^(k) = r^(k) − μ_r remains an unbiased estimator of the gradient of expected reward under the Bayesian model average, yet provides no derivation showing that the policy-gradient identity is preserved after marginalization over the mask. The recurrence couples the mask to the hidden-state trajectory, which can introduce an extra covariance term not cancelled by the group baseline; this step must be shown explicitly for the central claim to hold.
- [Experiments] Empirical results (GSM8K evaluation): The reported 1.72-point gain is presented without error bars, multiple random seeds, or ablations isolating the contribution of the shared-mask variational interpretation versus generic dropout; given that the central claim rests on the specific equivalence to a variational posterior, these controls are required to establish that the improvement is not attributable to other factors.
minor comments (1)
- [Abstract] The abstract and introduction use the phrase 'well-definedness of the latent gradient' without defining the precise quantity being differentiated or the measure under which the gradient is taken.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important areas for strengthening the theoretical and empirical foundations of our work. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Theory section] Theory section (asserted justification for unbiasedness): The manuscript states that the shared-mask construction yields samples from a variational posterior q(θ) such that the group-relative advantage A^(k) = r^(k) − μ_r remains an unbiased estimator of the gradient of expected reward under the Bayesian model average, yet provides no derivation showing that the policy-gradient identity is preserved after marginalization over the mask. The recurrence couples the mask to the hidden-state trajectory, which can introduce an extra covariance term not cancelled by the group baseline; this step must be shown explicitly for the central claim to hold.
Authors: We agree that the manuscript currently asserts the unbiasedness property at a high level without providing the explicit derivation requested. The potential covariance term arising from the recurrent coupling of the mask to the hidden state is a valid concern that requires careful treatment. In the revised manuscript, we will add a detailed derivation in the Theory section that explicitly shows preservation of the policy-gradient identity after marginalization over the mask, demonstrating how the group baseline cancels the relevant covariance terms. revision: yes
-
Referee: [Experiments] Empirical results (GSM8K evaluation): The reported 1.72-point gain is presented without error bars, multiple random seeds, or ablations isolating the contribution of the shared-mask variational interpretation versus generic dropout; given that the central claim rests on the specific equivalence to a variational posterior, these controls are required to establish that the improvement is not attributable to other factors.
Authors: We acknowledge that the current results lack error bars, multi-seed statistics, and targeted ablations, which are necessary to substantiate that the gains stem from the variational posterior equivalence rather than generic dropout effects. In the revision, we will report results over multiple random seeds with standard error bars and include ablations that compare the shared-mask construction against standard per-step dropout to isolate the contribution of the proposed mechanism. revision: yes
Circularity Check
No significant circularity; modeling choice presented as independent step with claimed external justification
full rationale
The abstract and provided text introduce the shared Bernoulli mask as a deliberate modeling choice to generate trajectory variance, explicitly framing it as treating rollouts as variational posterior samples to enable GRPO on a Bayesian model-average policy. The paper asserts it supplies separate theoretical justification (unbiasedness, variance reduction, latent gradient well-definedness) plus empirical results on GSM8K. No equations are shown that reduce the advantage estimator or the variational equivalence to a fitted parameter defined by the same data, nor is any load-bearing premise justified solely by self-citation. The derivation chain therefore remains self-contained rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption A single Bernoulli mask held constant across latent recurrence steps produces samples from a variational distribution over parameters that supports unbiased GRPO updates.
Reference graph
Works this paper leans on
-
[1]
Weight uncertainty in neural network
Charles Blundell, Julien Cornebise, Koray Kavukcuoglu, and Daan Wierstra. Weight uncertainty in neural network. InProceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 1613–1622. PMLR, 2015. URL https://proceedings.mlr.press/ v37/blundell15.html
2015
-
[2]
Yilong Chen, Junyuan Shang, Zhenyu Zhang, Yanxi Xie, Jiawei Sheng, Tingwen Liu, Shuohuan Wang, Yu Sun, Hua Wu, and Haifeng Wang. Inner thinking transformer: Leveraging dynamic depth scaling to foster adaptive internal thinking.arXiv preprint arXiv:2502.13842, 2025. URLhttps://arxiv.org/abs/2502.13842
arXiv 2025
-
[3]
Jeffrey Cheng and Benjamin Van Durme. Compressed chain of thought: Efficient reasoning through dense representations.arXiv preprint arXiv:2412.13171, 2024. URLhttps://arxiv.org/abs/2412.13171
Pith/arXiv arXiv 2024
-
[4]
Llm latent reasoning as chain of superposition.arXiv preprint arXiv:2510.15522, 2025
Jingcheng Deng, Liang Pang, Zihao Wei, Shicheng Xu, Zenghao Duan, Kun Xu, Yang Song, Huawei Shen, and Xueqi Cheng. Llm latent reasoning as chain of superposition.arXiv preprint arXiv:2510.15522, 2025. doi: 10.48550/arXiv.2510.15522. URLhttps://arxiv.org/abs/2510.15522
-
[5]
Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023
Yuntian Deng, Kiran Prasad, Roland Fernandez, Paul Smolensky, Vishrav Chaudhary, and Stuart Shieber. Implicit chain of thought reasoning via knowledge distillation.arXiv preprint arXiv:2311.01460, 2023. URL https: //arxiv.org/abs/2311.01460
arXiv 2023
-
[6]
Yuntian Deng, Yejin Choi, and Stuart Shieber. From explicit cot to implicit cot: Learning to internalize cot step by step.arXiv preprint arXiv:2405.14838, 2024. URLhttps://arxiv.org/abs/2405.14838
Pith/arXiv arXiv 2024
-
[7]
Hanwen Du, Yuxin Dong, and Xia Ning. Latent thinking optimization: Your latent reasoning language model secretly encodes reward signals in its latent thoughts.arXiv preprint arXiv:2509.26314, 2025. URL https: //arxiv.org/abs/2509.26314
arXiv 2025
-
[8]
Towards revealing the mystery behind chain of thought: A theoretical perspective
Guhao Feng, Bohang Zhang, Yuntian Gu, Haotian Ye, Di He, and Liwei Wang. Towards revealing the mystery behind chain of thought: A theoretical perspective. InAdvances in Neural Information Processing Systems (NeurIPS), volume 36, pages 70757–70798, 2023
2023
-
[9]
Dropout as a bayesian approximation: Representing model uncertainty in deep learning
Yarin Gal and Zoubin Ghahramani. Dropout as a bayesian approximation: Representing model uncertainty in deep learning. InProceedings of the 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1050–1059. PMLR, 2016. URL https://proceedings.mlr.press/ v48/gal16.html
2016
-
[10]
Pal: Program-aided language models.arXiv preprint arXiv:2211.10435, 2022
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. Pal: Program-aided language models.arXiv preprint arXiv:2211.10435, 2022. URL https://arxiv.org/abs/ 2211.10435. 9 Dropout-GRPO A preprint
Pith/arXiv arXiv 2022
-
[11]
Paul Glasserman and David D. Yao. Some guidelines and guarantees for common random numbers.Management Science, 38(6):884–908, 1992. doi: 10.1287/mnsc.38.6.884
-
[12]
Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak
Halil Alperen Gozeten, M. Emrullah Ildiz, Xuechen Zhang, Hrayr Harutyunyan, Ankit Singh Rawat, and Samet Oymak. Continuous chain of thought enables parallel exploration and reasoning.arXiv preprint arXiv:2505.23648,
-
[13]
URLhttps://arxiv.org/abs/2505.23648
doi: 10.48550/arXiv.2505.23648. URLhttps://arxiv.org/abs/2505.23648
-
[14]
Shibo Hao, Sainbayar Sukhbaatar, DiJia Su, Xian Li, Zhiting Hu, Jason Weston, and Yuandong Tian. Training large language models to reason in a continuous latent space.arXiv preprint arXiv:2412.06769, 2024. URL https://arxiv.org/abs/2412.06769
Pith/arXiv arXiv 2024
-
[15]
In: Findings of the Association for Computational Linguistics: ACL 2023
Cheng-Yu Hsieh, Chun-Liang Li, Chih-kuan Yeh, Hootan Nakhost, Yasuhisa Fujii, Alex Ratner, Ranjay Krishna, Chen-Yu Lee, and Tomas Pfister. Distilling step-by-step! outperforming larger language models with less training data and smaller model sizes. InFindings of the Association for Computational Linguistics (ACL), pages 8003–8017, 2023. doi: 10.18653/v1/...
-
[16]
LLML ingua: Compressing Prompts for Accelerated Inference of Large Language Models
Huiqiang Jiang, Qianhui Wu, Chin-Yew Lin, Yuqing Yang, and Lili Qiu. Llmlingua: Compressing prompts for accelerated inference of large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 13358–13376, Singapore, 2023. Association for Computational Linguistics. doi: 10.18653/v1/2023.emnlp-main.825...
-
[17]
Large language models are zero-shot reasoners
Takeshi Kojima, Shixiang Shane Gu, Machel Reid, Yutaka Matsuo, and Yusuke Iwasawa. Large language models are zero-shot reasoners. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 22199–22213, 2022. URLhttps://arxiv.org/abs/2205.11916
Pith/arXiv arXiv 2022
-
[18]
Houjun Liu, John Bauer, and Christopher D. Manning. Drop dropout on single epoch language model pretraining. InFindings of the Association for Computational Linguistics: ACL 2025, pages 2157–2166, Vienna, Austria,
2025
-
[19]
doi: 10.18653/v1/2025.findings-acl.111
Association for Computational Linguistics. doi: 10.18653/v1/2025.findings-acl.111. URL https:// aclanthology.org/2025.findings-acl.111/
-
[20]
Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025. URL https://arxiv.org/abs/2503.20783
Pith/arXiv arXiv 2025
-
[21]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. Are NLP models really able to solve simple math word problems? InProceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080–2094, Online, 2021. Association for Computational Linguistics. doi: 10.18653/v1/2021.n...
work page internal anchor Pith review doi:10.18653/v1/2021.naacl-main.168 2021
-
[22]
Solving general arithmetic word problems
Subhro Roy and Dan Roth. Solving general arithmetic word problems. InProceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, pages 1743–1752. Association for Computational Linguistics,
2015
-
[23]
URLhttps://aclanthology.org/D15-1202/
doi: 10.18653/v1/D15-1202. URLhttps://aclanthology.org/D15-1202/
-
[24]
Nikunj Saunshi, Nishanth Dikkala, Zhiyuan Li, Sanjiv Kumar, and Sashank J. Reddi. Reasoning with latent thoughts: On the power of looped transformers.arXiv preprint arXiv:2502.17416, 2025. URL https://arxiv. org/abs/2502.17416
arXiv 2025
-
[25]
Approximating kl divergence
John Schulman. Approximating kl divergence. Blog post, 2020. http://joschu.net/blog/kl-approx.html
2020
-
[26]
Gradient estimation using stochastic computation graphs
John Schulman, Nicolas Heess, Theophane Weber, and Pieter Abbeel. Gradient estimation using stochastic computation graphs. InAdvances in Neural Information Processing Systems, 2015
2015
-
[27]
Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
Pith/arXiv arXiv 2017
-
[28]
Zhihong Shao et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[29]
CODI: Compressing Chain-of-Thought into Continuous Space via Self-Distillation
Zhenyi Shen, Hanqi Yan, Linhai Zhang, Zhanghao Hu, Yali Du, and Yulan He. Codi: Compressing chain-of- thought into continuous space via self-distillation.arXiv preprint arXiv:2502.21074, 2025. doi: 10.48550/arXiv. 2502.21074. URLhttps://arxiv.org/abs/2502.21074
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv 2025
-
[30]
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data.arXiv preprint arXiv:2410.01560, 2024. doi: 10.48550/arXiv.2410.01560. URLhttps://arxiv.org/abs/2410.01560
-
[31]
Le, and Denny Zhou
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V . Le, and Denny Zhou. Chain-of-thought prompting elicits reasoning in large language 10 Dropout-GRPO A preprint models. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 24824–24837, 2022. URL https://proceedings.neurips.cc/paper_fil...
2022
-
[32]
Flipout: Efficient pseudo-independent weight perturbations on mini-batches
Yeming Wen, Paul Vicol, Jimmy Ba, Dustin Tran, and Roger Grosse. Flipout: Efficient pseudo-independent weight perturbations on mini-batches. InInternational Conference on Learning Representations, 2018. URL https://openreview.net/forum?id=rJNpifWAb
2018
-
[33]
URLhttps://doi.org/10.1007/BF00992696
Ronald J. Williams. Simple statistical gradient-following algorithms for connectionist reinforcement learning. Machine Learning, 8(3-4):229–256, 1992. doi: 10.1007/BF00992696
-
[34]
An Yang et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2024. doi: 10.48550/arXiv.2412.15115. URLhttps://arxiv.org/abs/2412.15115
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2412.15115 2024
-
[35]
Qiying Yu et al. Dapo: An open-source llm reinforcement learning system at scale.arXiv preprint arXiv:2503.14476, 2025. URLhttps://arxiv.org/abs/2503.14476
Pith/arXiv arXiv 2025
-
[36]
Hybrid latent reasoning via reinforcement learning.arXiv preprint arXiv:2505.18454, 2025
Zhenrui Yue, Bowen Jin, Huimin Zeng, Honglei Zhuang, Zhen Qin, Jinsung Yoon, Lanyu Shang, Jiawei Han, and Dong Wang. Hybrid latent reasoning via reinforcement learning.arXiv preprint arXiv:2505.18454, 2025. URL https://arxiv.org/abs/2505.18454
arXiv 2025
-
[37]
arXiv preprint arXiv:2505.15778 , year=
Zhen Zhang, Xuehai He, Weixiang Yan, Ao Shen, Chenyang Zhao, Shuohang Wang, Yelong Shen, and Xin Eric Wang. Soft thinking: Unlocking the reasoning potential of llms in continuous concept space.arXiv, 2025. doi: 10.48550/arxiv.2505.15778
-
[38]
Least-to-most prompting enables complex reasoning in large language models
Denny Zhou, Nathanael Schärli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, et al. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625, 2022. URLhttps://arxiv.org/abs/2205.10625
Pith/arXiv arXiv 2022
-
[39]
Yuyan Zhou, Jiarui Yu, Hande Dong, Zhezheng Hao, Hong Wang, Jianqing Zhang, and Qiang Lin. Lepo: Latent reasoning policy optimization for large language models.arXiv preprint arXiv:2604.17892, 2026. URL https://arxiv.org/abs/2604.17892
Pith/arXiv arXiv 2026
-
[40]
Reasoning by superposition: A theoretical perspective on chain of continuous thought.arXiv, 2025
Hanlin Zhu, Shibo Hao, Zhiting Hu, Jiantao Jiao, Stuart Russell, and Yuandong Tian. Reasoning by superposition: A theoretical perspective on chain of continuous thought.arXiv, 2025. doi: 10.48550/arxiv.2505.12514. A Extended Discussion and Future Work A.1 Interpreting the performance gain from Dropout-GRPO The empirical improvement of 2.03 percentage poin...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.