When the Database Fails: Prompting LLM Dialogue Agents for Safe Recovery in Task-Oriented Dialogue
Pith reviewed 2026-07-01 06:03 UTC · model grok-4.3
The pith
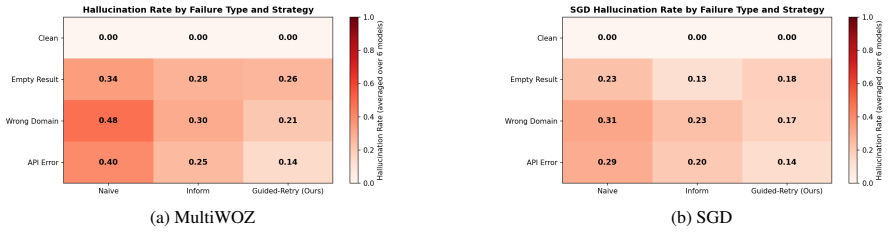
A guided retry prompt reduces LLM hallucinations by half when task-oriented dialogue databases fail.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
When database calls fail in task-oriented dialogue, LLMs hallucinate at rates of 30.5% on MultiWOZ and 20.9% on SGD. The Guided-Retry prompting strategy, conditioned on structured database status, lowers these rates to 15.3% and 12.2% respectively across six open-weight models, without requiring retraining or extra model calls. Wrong-domain retrieval remains the most difficult failure mode.
What carries the argument
The Guided-Retry strategy, a prompting-based recovery approach that conditions the model on structured database status information.
If this is right
- Agents become more robust to empty results, wrong-domain retrieval, and API errors.
- Performance gains hold across different model families and dataset structures.
- Human annotations confirm the automatic safety metric used in the evaluation.
- Residual hallucination stays between 6% and 37% depending on the model and failure type.
Where Pith is reading between the lines
- Similar prompting could help in other grounded generation tasks where external data sources fail.
- Developers might combine this with fine-tuning for further gains, though the paper focuses on zero-shot prompting.
- Real-world monitoring of database failure rates would help prioritize which failure types to address first.
Load-bearing premise
The artificial faults injected into the benchmarks match the frequency and types of database problems that occur in actual user interactions.
What would settle it
Measuring hallucination rates in a live deployment of the same models with the Guided-Retry prompt and comparing to the benchmark reductions.
Figures
read the original abstract
Large language models used in task-oriented dialogue often produce fluent but unsafe responses when backend database calls fail, return empty results, or surface mismatched information, inventing venues, confirmations, or booking details not grounded in the database. We study a lightweight prompting-based recovery approach that improves robustness without retraining or additional model calls. We compare three response strategies, including a guided recovery prompt conditioned on structured database status, across six open-weight model families (DeepSeek-R1, Gemma-2, Llama-3, Mistral, Phi-3, and Qwen-2.5) and four database conditions: empty result, wrong-domain retrieval, API error, and clean retrieval. Using fault-injected benchmarks built on two structurally different datasets, MultiWOZ 2.2 (5 domains) and SGD (20 domains), we find that naive agents hallucinate on 30.5% of failure turns on MultiWOZ and 20.9% on SGD. Our Guided-Retry strategy reduces hallucination by 50% on MultiWOZ (30.5 to 15.3%) and by 42% on SGD (20.9 to 12.2%) without retraining. However, residual hallucination remains substantial (6-37% across models), with wrong-domain failures the hardest case. Results are consistent across both datasets and all six model families, and human annotation shows substantial agreement while supporting the validity of the automatic commitment-safety metric.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a lightweight Guided-Retry prompting strategy, conditioned on structured database status, reduces hallucination rates in LLM task-oriented dialogue agents by 50% on MultiWOZ (30.5% to 15.3%) and 42% on SGD (20.9% to 12.2%) across six open-weight model families under four synthetically injected database conditions (empty result, wrong-domain retrieval, API error, clean), without retraining or extra calls. Results are reported as consistent across datasets, with human annotation supporting the automatic commitment-safety metric.
Significance. If the results hold, the work shows a training-free prompting method can substantially cut unsafe responses in dialogue systems facing backend failures, with the multi-model, multi-dataset design providing a solid empirical base. Credit is due for the consistent cross-model findings and the human validation step that bolsters the metric.
major comments (2)
- [Experimental Setup] The central quantitative claims rest on fault-injected benchmarks constructed via post-hoc modification of MultiWOZ 2.2 and SGD turns (see the Experimental Setup and Evaluation sections). No calibration against production logs, real failure corpora, or user-elicited failure distributions is reported, so it is unclear whether the four injected conditions (empty, wrong-domain, API error, clean) match the frequency, severity, or interaction patterns of actual deployment failures; this directly affects whether the 42–50% reductions demonstrate practical robustness.
- [Methods] The exact prompt templates for the Guided-Retry strategy and the two comparison strategies are not supplied in the main text, appendices, or supplementary material, nor are raw per-turn annotations or code for the commitment-safety metric. This prevents reproduction or independent verification of the reported hallucination percentages.
minor comments (1)
- [Abstract] The abstract introduces the 'commitment-safety metric' without a one-sentence definition or pointer to its formal definition later in the paper.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We respond to each major comment below, noting planned revisions where the manuscript can be strengthened.
read point-by-point responses
-
Referee: [Experimental Setup] The central quantitative claims rest on fault-injected benchmarks constructed via post-hoc modification of MultiWOZ 2.2 and SGD turns (see the Experimental Setup and Evaluation sections). No calibration against production logs, real failure corpora, or user-elicited failure distributions is reported, so it is unclear whether the four injected conditions (empty, wrong-domain, API error, clean) match the frequency, severity, or interaction patterns of actual deployment failures; this directly affects whether the 42–50% reductions demonstrate practical robustness.
Authors: We agree that the evaluation relies on synthetically injected failures rather than real-world production data. The four conditions were selected to cover representative failure categories frequently cited in prior TOD literature. In revision we will expand the Limitations section to explicitly discuss the synthetic construction, its alignment with documented failure modes, and the desirability of future calibration against deployment logs. The reported consistency across two structurally distinct datasets and six model families provides supporting evidence of the approach, though we acknowledge this does not substitute for real-distribution validation. revision: partial
-
Referee: [Methods] The exact prompt templates for the Guided-Retry strategy and the two comparison strategies are not supplied in the main text, appendices, or supplementary material, nor are raw per-turn annotations or code for the commitment-safety metric. This prevents reproduction or independent verification of the reported hallucination percentages.
Authors: We accept this point. The revised manuscript will include the full prompt templates for all three strategies in the appendix. We will also make the commitment-safety metric implementation and a sample of the per-turn annotations available via a public repository or supplementary material to enable independent verification. revision: yes
Circularity Check
No circularity; purely empirical measurements on synthetic benchmarks
full rationale
The paper reports direct experimental outcomes (hallucination percentages under four injected failure conditions on MultiWOZ 2.2 and SGD) without any derivation chain, equations, fitted parameters, or first-principles predictions. The central claims are observational comparisons of prompting strategies; the reported reductions (30.5%→15.3%, 20.9%→12.2%) are measured quantities, not quantities forced by the authors' own definitions or self-citations. No load-bearing self-referential steps exist.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Large language models will follow structured database-status information in prompts to avoid generating ungrounded responses.
Reference graph
Works this paper leans on
-
[1]
Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue , year =
Are Large Language Models All You Need for Task-Oriented Dialogue? , author =. Proceedings of the 24th Annual Meeting of the Special Interest Group on Discourse and Dialogue , year =
-
[2]
2020 , pages =
Eric, Mihail and Goel, Rahul and Paul, Shachi and Kumar, Adarsh and Sethi, Abhishek and Ku, Peter and Goyal, Anuj Kumar and Agarwal, Sanchit and Gao, Shuyang and Hakkani-Tur, Dilek , booktitle =. 2020 , pages =
2020
-
[3]
2020 , pages =
Zang, Xiaoxue and Rastogi, Abhinav and Sunkara, Srinivas and Gupta, Raghav and Zhang, Jianguo and Chen, Jindong , booktitle =. 2020 , pages =
2020
-
[4]
Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
Towards Scalable Multi-Domain Conversational Agents: The Schema-Guided Dialogue Dataset , author =. Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence , year =
-
[5]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , author =. arXiv preprint arXiv:2501.12948 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma 2: Improving Open Language Models at a Practical Size , author =. arXiv preprint arXiv:2408.00118 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
The Llama 3 Herd of Models , author =. arXiv preprint arXiv:2407.21783 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Mistral 7B , author =. arXiv preprint arXiv:2310.06825 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone , author =. arXiv preprint arXiv:2404.14219 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Qwen2.5 Technical Report , author =. arXiv preprint arXiv:2412.15115 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
When Users Are Happy but Agents Are Wrong: Multi-Dimensional Evaluation of Tool-Augmented Dialogue
Multi-Faceted Evaluation of Tool-Augmented Dialogue Systems , author =. arXiv preprint arXiv:2510.19186 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Gupta, Aayush , journal =
-
[13]
Vuddanti, Sri Vatsa and Shah, Aarav and Chittiprolu, Satwik Kumar and Song, Tony and Dev, Sunishchal and Zhu, Kevin and Chaudhary, Maheep , journal =
-
[14]
arXiv preprint arXiv:2508.11027 , year =
Hell or High Water: Evaluating Agentic Recovery from External Failures , author =. arXiv preprint arXiv:2508.11027 , year =
-
[15]
arXiv preprint arXiv:2509.23124 , year =
Non-Collaborative User Simulators for Tool Agents , author =. arXiv preprint arXiv:2509.23124 , year =
-
[16]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author =. arXiv preprint arXiv:2406.12045 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Hamad, Hassan and Xu, Yingru and Zhao, Liang and Yan, Wenbo and Gyanchandani, Narendra , journal =
-
[18]
Zhang, Shuyu and Liu, Yujie and Wang, Xinru and Zhang, Cheng and Zhu, Yanmin and Li, Bin , journal =
-
[19]
The Behavior Gap: Evaluating Zero-shot
Baidya, Avinash and Das, Kamalika and Gao, Xiang , booktitle =. The Behavior Gap: Evaluating Zero-shot
-
[20]
Proceedings of ACL 2023 , year =
Heck, Michael and Lubis, Nurul and Ruppik, Benjamin and Vukovic, Renato and Feng, Shutong and Geishauser, Christian and Lin, Hsien-Chin and van Niekerk, Carel and Ga. Proceedings of ACL 2023 , year =
2023
-
[21]
Proceedings of EMNLP 2024 , year =
Tools Fail: Detecting Silent Errors in Faulty Tools , author =. Proceedings of EMNLP 2024 , year =
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.