On Effectiveness and Efficiency of Agentic Tool-calling and RL Training
Pith reviewed 2026-06-29 08:36 UTC · model grok-4.3
The pith
Tool-calling evaluations for LLM agents shift with small undocumented choices in seeds, prompts, and history handling, while RL training wastes compute on rollouts and updates that carry no signal.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
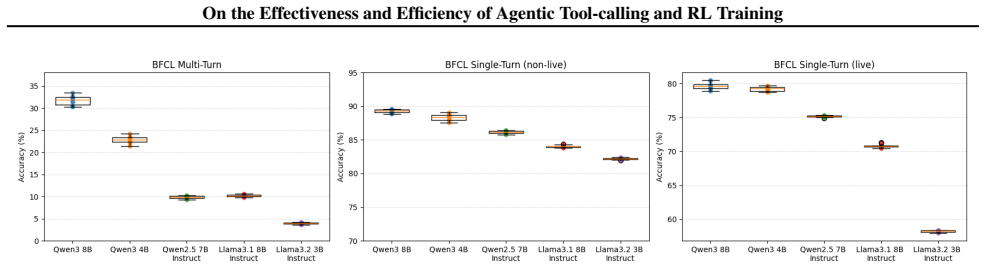
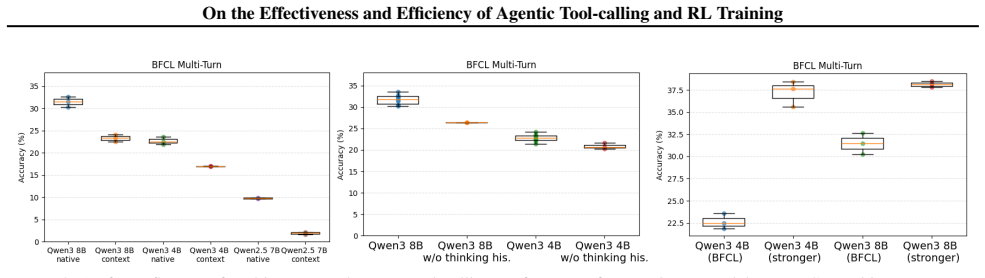
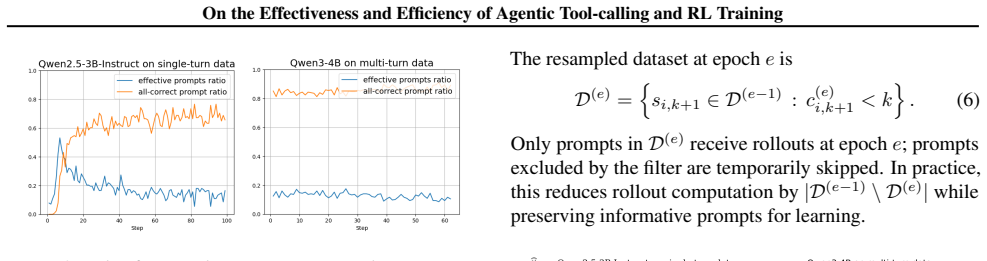
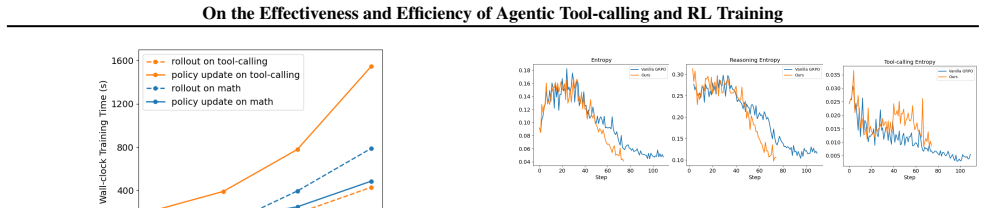
Tool-calling evaluation pipelines produce results that vary with minor, often undocumented choices including the random seed, system prompt, multi-turn template construction, and how prior interaction or reasoning history is carried forward; these variations are large enough in multi-turn settings to make leaderboard rankings unreliable. Standard RL for tool-calling incurs two forms of waste: many rollout prompts yield no learning signal and policy updates carry high computational cost. Two techniques that target these wastes deliver substantial wall-clock speedup while preserving performance and generalization.
What carries the argument
Sensitivity analysis of evaluation pipelines together with two techniques that eliminate no-signal rollouts and reduce the cost of policy updates in RL training.
If this is right
- Leaderboard comparisons for multi-turn tool-calling are unreliable unless evaluation pipelines are standardized.
- RL training for tool-calling agents can reach the same performance level in substantially less wall-clock time.
- Results must document random seeds, prompts, templates, and history handling to be reproducible.
- The acceleration techniques preserve generalization across different tool-calling settings.
Where Pith is reading between the lines
- Similar sensitivity to implementation details is likely present in other multi-turn agent benchmarks.
- The waste-reduction approach could shorten RL training in other domains that also produce many uninformative rollouts.
- Community adoption of fixed test suites or reference implementations would be needed to make rankings stable.
Load-bearing premise
The performance differences arise primarily from the listed implementation choices and that the two identified wastes are the main bottlenecks that the new techniques can remove without harming learning quality.
What would settle it
Re-run a set of published tool-calling evaluations across multiple random seeds and check whether the ranking of methods changes; separately, train the same agent with and without the two proposed techniques and measure both wall-clock time and final task performance.
Figures


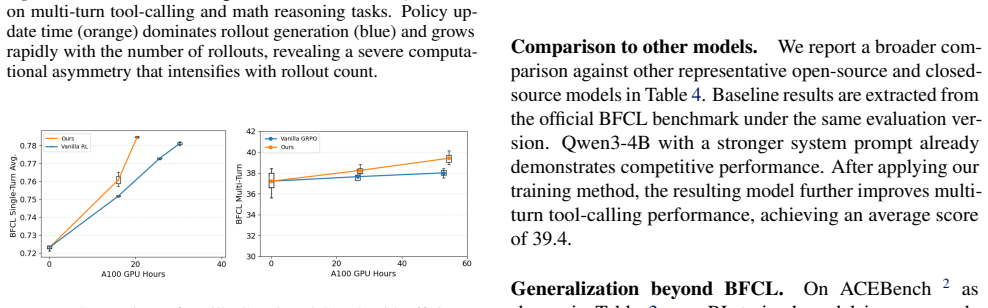


read the original abstract
Tool-calling is a central component of modern large language model (LLM) agents, equipping them with skills beyond their parametric knowledge. This paper studies tool-calling along two complementary axes: effectiveness, i.e., how this capability is measured, and efficiency, i.e., how it is learned. On effectiveness, we systematically analyze tool-calling evaluation pipelines and show that results can be highly sensitive to seemingly minor, often undocumented implementation choices including the random seed, system prompt, multi-turn template construction, and how prior interaction/reasoning history is carried forward. These choices can lead to substantial differences in reported performance, especially in multi-turn settings where without rigorous standardization, leaderboard rankings are unreliable. On efficiency, we examine standard reinforcement learning (RL) for tool-calling and identify two sources of computational waste: (i) during rollouts, many prompts produce no learning signal, and (ii) during policy updates, optimization incurs high computational cost. Guided by these findings, we introduce two techniques that accelerate RL-based tool-calling training, achieving substantial wall-clock speedup without degrading performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that tool-calling evaluation pipelines for LLM agents are highly sensitive to minor, often undocumented choices (random seed, system prompt, multi-turn template construction, and history handling), leading to unreliable leaderboard rankings especially in multi-turn settings. It further identifies two sources of computational waste in standard RL for tool-calling (no-learning-signal rollouts and high-cost policy updates) and introduces two techniques that deliver substantial wall-clock speedup without degrading performance.
Significance. If substantiated, the effectiveness analysis would be a useful contribution by documenting sources of variance that undermine current agent benchmarks and calling for standardization. The efficiency techniques address practical bottlenecks in RL training and could be impactful for scaling tool-calling agents if the no-degradation result is shown to be robust. The paper's empirical approach to identifying waste sources is a strength, though the joint claims require careful cross-validation between the two axes.
major comments (2)
- [Effectiveness and efficiency sections] Effectiveness section: the demonstrated sensitivity to seed, prompt, template, and history handling directly bears on the efficiency claims. The central assertion that the two techniques achieve speedup 'without degrading performance' (and preserve learning quality) is load-bearing, yet the manuscript does not state whether the RL experiments employed the standardized pipelines advocated in the effectiveness analysis.
- [Efficiency experiments] RL experiments (efficiency portion): without explicit confirmation that evaluations used fixed seeds, consistent multi-turn templates, and documented history handling, any reported performance equivalence could be an artifact of a favorable configuration rather than a property of the proposed techniques. This makes the 'preserving learning quality' assumption a load-bearing point for the joint contribution.
minor comments (2)
- Add a dedicated reproducibility subsection detailing exact prompt templates, seed values, and history concatenation rules used in all reported experiments.
- Clarify the precise algorithmic definitions and hyperparameters of the two proposed techniques (e.g., how no-learning-signal detection is implemented and how policy-update cost is reduced).
Simulated Author's Rebuttal
We thank the referee for the thoughtful comments, which correctly identify an important linkage between the effectiveness and efficiency sections. We address each major comment below.
read point-by-point responses
-
Referee: [Effectiveness and efficiency sections] Effectiveness section: the demonstrated sensitivity to seed, prompt, template, and history handling directly bears on the efficiency claims. The central assertion that the two techniques achieve speedup 'without degrading performance' (and preserve learning quality) is load-bearing, yet the manuscript does not state whether the RL experiments employed the standardized pipelines advocated in the effectiveness analysis.
Authors: We agree that the sensitivity results have direct implications for interpreting the efficiency claims. The RL experiments were conducted using fixed random seeds, consistent multi-turn templates, and the documented history-handling protocol from the effectiveness analysis. This alignment was not explicitly stated in the original manuscript. In the revision we will add a dedicated paragraph in Section 4 (Efficiency Experiments) that documents the precise evaluation pipeline employed for all RL runs, including seed values, system prompt, template construction, and history handling, so that readers can verify the 'no degradation' result was obtained under the advocated standardized conditions. revision: yes
-
Referee: [Efficiency experiments] RL experiments (efficiency portion): without explicit confirmation that evaluations used fixed seeds, consistent multi-turn templates, and documented history handling, any reported performance equivalence could be an artifact of a favorable configuration rather than a property of the proposed techniques. This makes the 'preserving learning quality' assumption a load-bearing point for the joint contribution.
Authors: We concur that the absence of explicit confirmation leaves the performance-equivalence claim vulnerable to the interpretation raised. As noted in the response to the first comment, the experiments did follow the standardized pipeline. The revision will include the requested confirmation together with a short table or bullet list summarizing the fixed settings, thereby strengthening the joint contribution by making the evaluation protocol transparent and reproducible. revision: yes
Circularity Check
No circularity; claims rest on direct experimental observation without self-referential derivations
full rationale
The paper's central contributions are an empirical sensitivity analysis of tool-calling evaluation pipelines (varying seeds, prompts, history handling) and experimental identification of RL waste sources followed by proposed acceleration techniques. No equations, fitted parameters renamed as predictions, or derivation chains appear. Claims are grounded in reported experimental outcomes rather than any reduction to inputs by construction or load-bearing self-citations. The analysis is self-contained against external benchmarks via direct measurement.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek. DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning , journal =. 2025 , url =. doi:10.48550/ARXIV.2501.12948 , eprinttype =. 2501.12948 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2501.12948 2025
-
[2]
Shaokun Zhang and Yi Dong and Jieyu Zhang and Jan Kautz and Bryan Catanzaro and Andrew Tao and Qingyun Wu and Zhiding Yu and Guilin Liu , title =. CoRR , volume =. 2025 , doi =. 2505.00024 , timestamp =
-
[3]
ToolRL: Reward is All Tool Learning Needs
Cheng Qian and Emre Can Acikgoz and Qi He and Hongru Wang and Xiusi Chen and Dilek Hakkani. ToolRL: Reward is All Tool Learning Needs , journal =. 2025 , url =. doi:10.48550/ARXIV.2504.13958 , eprinttype =. 2504.13958 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13958 2025
-
[4]
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Yixuan Even Xu and Yash Savani and Fei Fang and Zico Kolter , title =. CoRR , volume =. 2025 , url =. doi:10.48550/ARXIV.2504.13818 , eprinttype =. 2504.13818 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.13818 2025
-
[5]
Forty-second International Conference on Machine Learning , year=
The Berkeley Function Calling Leaderboard (BFCL): From Tool Use to Agentic Evaluation of Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[6]
ToolACE: Winning the points of LLM function calling, 2024
Toolace: Winning the points of llm function calling , author=. arXiv preprint arXiv:2409.00920 , year=
-
[7]
arXiv preprint arXiv:2410.04587 , year=
Hammer: Robust function-calling for on-device language models via function masking , author=. arXiv preprint arXiv:2410.04587 , year=
-
[8]
xlam: A family of large action models to empower ai agent systems , author=. Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers) , pages=
2025
-
[9]
arXiv preprint arXiv:2504.03601 , year=
Apigen-mt: Agentic pipeline for multi-turn data generation via simulated agent-human interplay , author=. arXiv preprint arXiv:2504.03601 , year=
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning , author=. arXiv preprint arXiv:2501.12948 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
2024 , journal =
HybridFlow: A Flexible and Efficient RLHF Framework , author =. 2024 , journal =
2024
-
[12]
Not All Rollouts are Useful: Down-Sampling Rollouts in LLM Reinforcement Learning
Not all rollouts are useful: Down-sampling rollouts in llm reinforcement learning , author=. arXiv preprint arXiv:2504.13818 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Dapo: An open-source llm reinforcement learning system at scale , author=. arXiv preprint arXiv:2503.14476 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
2025 , eprint=
LoopTool: Closing the Data-Training Loop for Robust LLM Tool Calls , author=. 2025 , eprint=
2025
-
[15]
2025 , howpublished =
Anthropic , title =. 2025 , howpublished =
2025
-
[16]
The Amazon Nova family of models: Technical report and model card , year =
-
[17]
2025 , howpublished =
MistralAI , title =. 2025 , howpublished =
2025
-
[18]
2025 , howpublished =
Openai , title =. 2025 , howpublished =
2025
-
[19]
2025 , howpublished =
Deepmind , title =. 2025 , howpublished =
2025
-
[20]
2025 , howpublished =
xAI , title =. 2025 , howpublished =
2025
-
[21]
2025 , howpublished =
Meta , title =. 2025 , howpublished =
2025
-
[22]
2025 , eprint=
^2 -Bench: Evaluating Conversational Agents in a Dual-Control Environment , author=. 2025 , eprint=
2025
-
[23]
arXiv preprint arXiv:2107.07002 , year=
The benchmark lottery , author=. arXiv preprint arXiv:2107.07002 , year=
-
[24]
Proceedings of the AAAI conference on artificial intelligence , volume=
Deep reinforcement learning that matters , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[25]
Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
Are we learning yet? a meta review of evaluation failures across machine learning , author=. Thirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2) , year=
-
[26]
Advances in Neural Information Processing Systems , volume=
Betterbench: Assessing ai benchmarks, uncovering issues, and establishing best practices , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
Lessons from the Trenches on Reproducible Evaluation of Language Models
Lessons from the trenches on reproducible evaluation of language models , author=. arXiv preprint arXiv:2405.14782 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
arXiv preprint arXiv:2504.07086 , year=
A sober look at progress in language model reasoning: Pitfalls and paths to reproducibility , author=. arXiv preprint arXiv:2504.07086 , year=
-
[29]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Deepseekmath: Pushing the limits of mathematical reasoning in open language models , author=. arXiv preprint arXiv:2402.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Proximal Policy Optimization Algorithms
Proximal policy optimization algorithms , author=. arXiv preprint arXiv:1707.06347 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Qwen3 technical report , author=. arXiv preprint arXiv:2505.09388 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[32]
Act Only When It Pays: Efficient Reinforcement Learning for LLM Reasoning via Selective Rollouts , author=. arXiv preprint arXiv:2506.02177 , year=
-
[33]
HellaSwag: Can a Machine Really Finish Your Sentence?
Hellaswag: Can a machine really finish your sentence? , author=. arXiv preprint arXiv:1905.07830 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[34]
Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
Truthfulqa: Measuring how models mimic human falsehoods , author=. Proceedings of the 60th annual meeting of the association for computational linguistics (volume 1: long papers) , pages=
-
[35]
Measuring Massive Multitask Language Understanding
Measuring massive multitask language understanding , author=. arXiv preprint arXiv:2009.03300 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2009
-
[36]
Communications of the ACM , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Communications of the ACM , volume=. 2021 , publisher=
2021
-
[37]
Gao, Leo and Tow, Jonathan and Abbasi, Baber and Biderman, Stella and Black, Sid and DiPofi, Anthony and Foster, Charles and Golding, Laurence and Hsu, Jeffrey and Le Noac'h, Alain and Li, Haonan and McDonell, Kyle and Muennighoff, Niklas and Ociepa, Chris and Phang, Jason and Reynolds, Laria and Schoelkopf, Hailey and Skowron, Aviya and Sutawika, Lintang...
-
[38]
The eleventh international conference on learning representations , year=
React: Synergizing reasoning and acting in language models , author=. The eleventh international conference on learning representations , year=
-
[39]
Advances in Neural Information Processing Systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Findings of the Association for Computational Linguistics: ACL 2024 , pages=
Freshllms: Refreshing large language models with search engine augmentation , author=. Findings of the Association for Computational Linguistics: ACL 2024 , pages=
2024
-
[41]
Search-R1: Training LLMs to Reason and Leverage Search Engines with Reinforcement Learning
Search-r1: Training llms to reason and leverage search engines with reinforcement learning , author=. arXiv preprint arXiv:2503.09516 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[42]
Program of thoughts prompting: Disentangling computation from reasoning for numerical reasoning tasks , author=. arXiv preprint arXiv:2211.12588 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[43]
International Conference on Machine Learning , pages=
Pal: Program-aided language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[44]
Advances in Neural Information Processing Systems , volume=
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
ART: Automatic multi-step reasoning and tool-use for large language models
Art: Automatic multi-step reasoning and tool-use for large language models , author=. arXiv preprint arXiv:2303.09014 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
ToolLLM: Facilitating Large Language Models to Master 16000+ Real-world APIs
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. arXiv preprint arXiv:2307.16789 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[47]
Advances in Neural Information Processing Systems , volume=
Gorilla: Large language model connected with massive apis , author=. Advances in Neural Information Processing Systems , volume=
-
[48]
Journal of Artificial Intelligence Research , volume=
Revisiting the arcade learning environment: Evaluation protocols and open problems for general agents , author=. Journal of Artificial Intelligence Research , volume=
-
[49]
Reproducibility of Benchmarked Deep Reinforcement Learning Tasks for Continuous Control
Reproducibility of benchmarked deep reinforcement learning tasks for continuous control , author=. arXiv preprint arXiv:1708.04133 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[50]
Advances in neural information processing systems , volume=
Deep reinforcement learning at the edge of the statistical precipice , author=. Advances in neural information processing systems , volume=
-
[51]
arXiv preprint arXiv:1912.05663 , year=
Measuring the reliability of reinforcement learning algorithms , author=. arXiv preprint arXiv:1912.05663 , year=
-
[52]
Journal of Machine Learning Research , volume=
Empirical design in reinforcement learning , author=. Journal of Machine Learning Research , volume=
-
[53]
How Many Random Seeds? Statistical Power Analysis in Deep Reinforcement Learning Experiments
How many random seeds? statistical power analysis in deep reinforcement learning experiments , author=. arXiv preprint arXiv:1806.08295 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
arXiv preprint arXiv:2501.12851 , year=
ACEBench: Who Wins the Match Point in Tool Learning? , author=. arXiv preprint arXiv:2501.12851 , year=
-
[55]
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Gepa: Reflective prompt evolution can outperform reinforcement learning , author=. arXiv preprint arXiv:2507.19457 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[56]
Gemma 3 technical report , author=. arXiv preprint arXiv:2503.19786 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[57]
arXiv preprint arXiv:2509.21880 , year=
No prompt left behind: Exploiting zero-variance prompts in llm reinforcement learning via entropy-guided advantage shaping , author=. arXiv preprint arXiv:2509.21880 , year=
-
[58]
arXiv e-prints , pages=
Reinforce-ada: An adaptive sampling framework for reinforce-style llm training , author=. arXiv e-prints , pages=
-
[59]
arXiv preprint arXiv:2603.04370 , year=
-Knowledge: Evaluating Conversational Agents over Unstructured Knowledge , author=. arXiv preprint arXiv:2603.04370 , year=
-
[60]
Sentence-bert: Sentence embeddings using siamese bert-networks , author=. Proceedings of the 2019 conference on empirical methods in natural language processing and the 9th international joint conference on natural language processing (EMNLP-IJCNLP) , pages=
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.