A Physics-Grounded Benchmark for Multi-Agent Dynamics in World Models
Pith reviewed 2026-06-30 09:49 UTC · model grok-4.3
The pith
World models generate visually realistic multi-agent collisions yet frequently violate momentum and energy conservation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
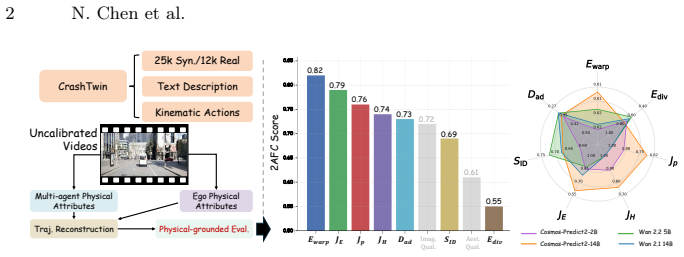
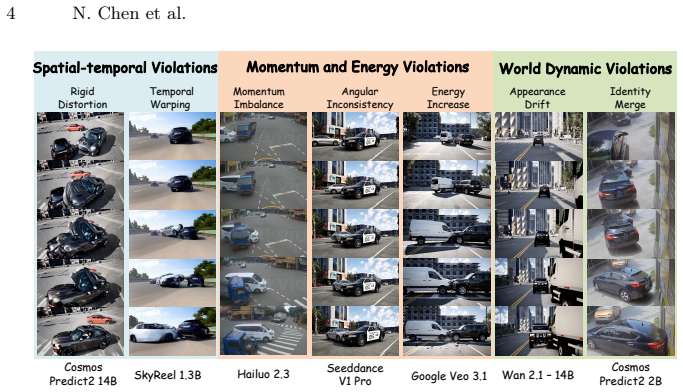
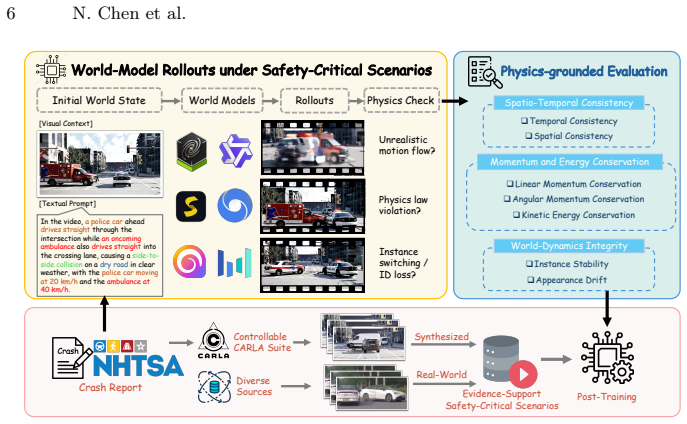
CrashTwin shows that state-of-the-art world models achieve high perceptual quality while committing severe physical violations during complex multi-agent interactions, as quantified by systematic failures across spatio-temporal consistency, momentum and kinetic energy conservation, and world-dynamics integrity.
What carries the argument
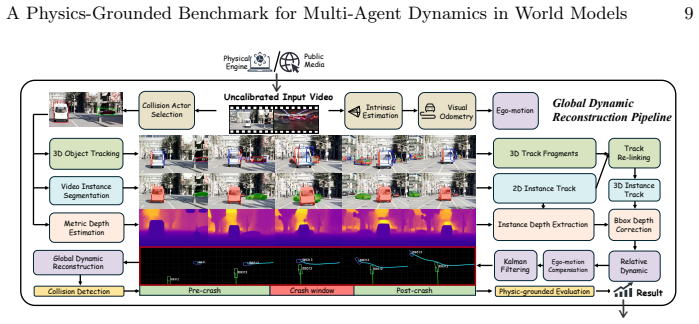
The calibration-free reconstruction pipeline that recovers metric-scale 3D kinematics and physical attributes from uncalibrated world-model video rollouts.
If this is right
- Any world model intended for simulation of safety-critical interactions must be assessed on the three proposed physical dimensions in addition to visual metrics.
- Models that pass perceptual tests but fail conservation checks cannot be trusted for downstream planning or control tasks.
- The diagnostic suite supplies concrete numerical targets that can guide training or post-processing to enforce physical consistency.
- The paired synthetic and real-world collision datasets enable controlled ablation of which interaction types expose the largest physical gaps.
Where Pith is reading between the lines
- Adding the physical metrics as auxiliary losses during model training could reduce violations without separate post-hoc filtering.
- The same reconstruction approach might be applied to non-collision multi-agent scenarios to test whether physical failures are limited to high-contact regimes.
- Deployed simulators could reject or re-sample any rollout that exceeds the reported violation thresholds before using it for decision making.
Load-bearing premise
The calibration-free reconstruction pipeline can reliably recover accurate metric-scale 3D kinematics and physical attributes directly from uncalibrated video rollouts.
What would settle it
Applying the pipeline to controlled synthetic videos whose true 3D trajectories and energies are known and observing large systematic discrepancies between recovered and ground-truth momentum values would show the pipeline cannot support the claimed diagnostics.
Figures



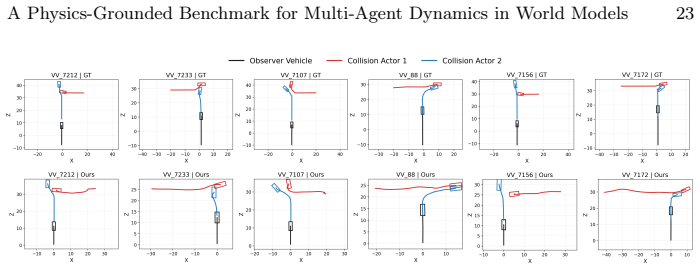
read the original abstract
Generative world models hold immense promise as scalable simulators for autonomous systems, particularly for synthesizing rare but safety-critical multi-agent interactions, such as vehicle collisions. However, current evaluation paradigms index heavily on visual fidelity and semantic alignment, leaving a critical blind spot: they cannot reliably quantify whether generated dynamics actually obey the fundamental physical laws required for reliable simulation. Assessing this physical plausibility is inherently difficult due to a lack of physical metrics and the challenge of extracting metric-scale kinematics from uncalibrated video rollouts. To bridge this gap, we introduce CrashTwin, a physics-grounded evaluation framework designed to stress-test the physical trustworthiness of world models. CrashTwin couples a diverse dataset of multi-agent collision scenarios, comprising 25K controllable synthetic and 12K in-the-wild real-world collision sequences with a novel calibration-free reconstruction pipeline, enabling the recovery of 3D physical attributes directly from world model rollouts. We propose a diagnostic suite that systematically evaluates three dimensions: spatio-temporal consistency, momentum and kinetic energy conservation, and world-dynamics integrity. Extensive benchmarking of state-of-the-art models reveals a crucial insight: high perceptual quality frequently masks severe physical violations during complex interactions. By quantitatively exposing these failure modes, CrashTwin provides a vital diagnostic tool for developing physically grounded world models capable of reliable real-world simulation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces CrashTwin, a physics-grounded benchmark for evaluating multi-agent dynamics in generative world models, with emphasis on vehicle collision scenarios. It contributes a dataset of 25K synthetic and 12K real-world collision sequences, a calibration-free reconstruction pipeline to recover 3D physical attributes (positions, velocities, masses) from uncalibrated video rollouts, and a diagnostic suite measuring spatio-temporal consistency, momentum/kinetic energy conservation, and world-dynamics integrity. Benchmarking of state-of-the-art models indicates that high perceptual quality often conceals severe physical violations.
Significance. If the reconstruction pipeline is shown to recover accurate metric-scale kinematics with bounded error, the benchmark would provide a valuable, falsifiable diagnostic for physical trustworthiness in world models intended for simulation. The focus on conservation laws during complex interactions and the scale of the collision dataset are strengths that address a genuine gap beyond visual metrics.
major comments (2)
- [Reconstruction pipeline (§3)] Reconstruction pipeline (abstract and §3): The claim that the calibration-free pipeline 'enables the recovery of 3D physical attributes directly' from monocular rollouts is load-bearing for all three diagnostic dimensions, yet no quantitative validation (e.g., MAE on recovered velocities, depths, or masses against ground truth on the 25K synthetic sequences) or error bounds are reported. Systematic bias from depth estimation on collision scenes or domain shift to generated videos would appear as physical violations even if the world model is correct.
- [Conservation metrics (§4.2)] Conservation metrics (§4.2): Momentum and kinetic energy conservation checks require absolute metric velocities and masses; any unquantified scale ambiguity or reconstruction variance directly undermines attribution of violations to the models rather than the measurement process. Explicit sensitivity analysis to reconstruction noise should be added.
minor comments (1)
- [Abstract / §4] The distinction between 'world-dynamics integrity' and the conservation checks is not immediately clear from the abstract or high-level description; a concise definition or table of metrics would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting the importance of validating the reconstruction pipeline and quantifying its impact on the conservation metrics. We address each major comment below and commit to revisions that strengthen the manuscript's claims without altering its core contributions.
read point-by-point responses
-
Referee: [Reconstruction pipeline (§3)] Reconstruction pipeline (abstract and §3): The claim that the calibration-free pipeline 'enables the recovery of 3D physical attributes directly' from monocular rollouts is load-bearing for all three diagnostic dimensions, yet no quantitative validation (e.g., MAE on recovered velocities, depths, or masses against ground truth on the 25K synthetic sequences) or error bounds are reported. Systematic bias from depth estimation on collision scenes or domain shift to generated videos would appear as physical violations even if the world model is correct.
Authors: We agree that explicit quantitative validation of the reconstruction pipeline against ground truth is essential to support the load-bearing claims. The 25K synthetic sequences were generated with known metric-scale ground truth (positions, velocities, masses), which enables direct computation of errors. The current manuscript focuses on the pipeline's application to both synthetic and real-world data but does not report MAE or error bounds. We will add a dedicated validation subsection in §3 reporting MAE, RMSE, and relative error for velocities, depths, and masses on the full synthetic set, along with analysis of potential biases in collision scenes (e.g., occlusion, fast motion) and a brief discussion of domain shift considerations for generated videos. This revision will include error bounds and confidence intervals. revision: yes
-
Referee: [Conservation metrics (§4.2)] Conservation metrics (§4.2): Momentum and kinetic energy conservation checks require absolute metric velocities and masses; any unquantified scale ambiguity or reconstruction variance directly undermines attribution of violations to the models rather than the measurement process. Explicit sensitivity analysis to reconstruction noise should be added.
Authors: We concur that reconstruction variance must be quantified to ensure violations are attributable to the world models. While the pipeline recovers metric-scale attributes via the synthetic calibration and real-world priors described in §3, we did not include sensitivity analysis in the original submission. We will add this analysis to §4.2 by (i) injecting controlled Gaussian noise at levels matching the reported reconstruction errors into the recovered velocities and masses, (ii) recomputing the conservation violation rates, and (iii) reporting how the diagnostic scores vary with noise magnitude. This will demonstrate robustness and clarify the separation between measurement error and model violations. revision: yes
Circularity Check
No significant circularity; benchmark pipeline is independent contribution
full rationale
The paper introduces CrashTwin as an evaluation framework consisting of a dataset and a calibration-free reconstruction pipeline to extract 3D physical attributes from video rollouts, followed by computation of conservation and consistency metrics. No derivation chain, prediction, or first-principles result is presented that reduces by construction to fitted inputs, self-definitions, or self-citations. The pipeline is framed as a novel enabling tool rather than a result derived from the metrics it produces. The abstract and provided text contain no load-bearing self-citations, ansatzes smuggled via prior work, or renaming of known results. This is a standard benchmark paper whose central claims rest on the proposed method's external applicability, not internal equivalence to its inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption World models for autonomous systems must obey fundamental physical laws such as momentum and kinetic energy conservation to be reliable simulators.
invented entities (1)
-
CrashTwin framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Waymo safety report. Tech. rep., Waymo LLC (Dec 2021),https://storage. googleapis . com / waymo - uploads / files / documents / safety / 2021 - 12 - waymo - safety-report.pdf, accessed 2026-03-04
2021
-
[2]
DOT HS810(767), 4 (2007)
Administration, N.H.T.S., et al.: Pre-crash scenario typology for crash avoidance research. DOT HS810(767), 4 (2007)
2007
-
[3]
Cosmos World Foundation Model Platform for Physical AI
Agarwal, N., Ali, A., Bala, M., Balaji, Y., Barker, E., Cai, T., Chattopadhyay, P., Chen, Y., Cui, Y., Ding, Y., et al.: Cosmos world foundation model platform for physical ai. arXiv preprint arXiv:2501.03575 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
In: Asian Conference on Computer Vision
Aliakbarian, M.S., Saleh, F.S., Salzmann, M., Fernando, B., Petersson, L., Ander- sson, L.: Viena: A driving anticipation dataset. In: Asian Conference on Computer Vision. pp. 449–466. Springer (2018)
2018
-
[5]
VideoPhy: Evaluating Physical Commonsense for Video Generation
Bansal, H., Lin, Z., Xie, T., Zong, Z., Yarom, M., Bitton, Y., Jiang, C., Sun, Y., Chang, K.W., Grover, A.: Videophy: Evaluating physical commonsense for video generation. arXiv preprint arXiv:2406.03520 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[6]
In: Proceedings of the 28th ACM International Conference on Multimedia
Bao, W., Yu, Q., Kong, Y.: Uncertainty-based traffic accident anticipation with spatio-temporal relational learning. In: Proceedings of the 28th ACM International Conference on Multimedia. pp. 2682–2690 (2020)
2020
-
[7]
Brach, R.M., Brach, R.M.: A review of impact models for vehicle collision (1987)
1987
-
[8]
In: Asian conference on computer vision
Chan, F.H., Chen, Y.T., Xiang, Y., Sun, M.: Anticipating accidents in dashcam videos. In: Asian conference on computer vision. pp. 136–153. Springer (2016)
2016
-
[9]
Cornell University (1997)
Chatterjee, A.: Rigid body collisions: some general considerations, new collision laws, and some experimental data. Cornell University (1997)
1997
-
[10]
SkyReels-V2: Infinite-length Film Generative Model
Chen, G., Lin, D., Yang, J., Lin, C., Zhu, J., Fan, M., Zhang, H., Chen, S., Chen, Z., Ma, C., et al.: Skyreels-v2: Infinite-length film generative model. arXiv preprint arXiv:2504.13074 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Comanici, G., Bieber, E., Schaekermann, M., Pasupat, I., Sachdeva, N., Dhillon, I., Blistein, M., Ram, O., Zhang, D., Rosen, E., et al.: Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities. arXiv preprint arXiv:2507.06261 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [12]
-
[13]
In: Conference on robot learning
Dosovitskiy, A., Ros, G., Codevilla, F., Lopez, A., Koltun, V.: Carla: An open urban driving simulator. In: Conference on robot learning. pp. 1–16. PMLR (2017)
2017
-
[14]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Fang, J., Li, L.l., Zhou, J., Xiao, J., Yu, H., Lv, C., Xue, J., Chua, T.S.: Abductive ego-view accident video understanding for safe driving perception. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22030–22040 (2024)
2024
-
[15]
IEEE transactions on intelligent transportation systems 23(6), 4959–4971 (2021) A Physics-Grounded Benchmark for Multi-Agent Dynamics in World Models 31
Fang, J., Yan, D., Qiao, J., Xue, J., Yu, H.: Dada: Driver attention prediction in driving accident scenarios. IEEE transactions on intelligent transportation systems 23(6), 4959–4971 (2021) A Physics-Grounded Benchmark for Multi-Agent Dynamics in World Models 31
2021
-
[16]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Gao, Y., Guo, H., Hoang, T., Huang, W., Jiang, L., Kong, F., Li, H., Li, J., Li, L., Li, X., et al.: Seedance 1.0: Exploring the boundaries of video generation models. arXiv preprint arXiv:2506.09113 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[17]
Technical report, Google DeepMind (2026),https: //blog.google/innovation-and-ai/technology/ai/veo-3-1-ingredients-to- video/, released: January 13, 2026
Google DeepMind: Veo 3.1. Technical report, Google DeepMind (2026),https: //blog.google/innovation-and-ai/technology/ai/veo-3-1-ingredients-to- video/, released: January 13, 2026. Accessed: March 5, 2026
2026
-
[18]
arXiv preprint arXiv:2506.00227 (2025)
Gosselin, A., Luo, G.Y., Lara, L., Golemo, F., Nowrouzezahrai, D., Paull, L., Jolicoeur-Martineau, A., Pal, C.: Ctrl-crash: Controllable diffusion for realistic car crashes. arXiv preprint arXiv:2506.00227 (2025)
-
[19]
Green, D.M., Swets, J.A., et al.: Signal detection theory and psychophysics, vol. 1. Wiley New York (1966)
1966
-
[20]
In: 2024 IEEE International Conference on Multimedia and Expo (ICME)
Guo, Z., Zhou, Y., Gou, C.: Drivinggen: Efficient safety-critical driving video gen- eration with latent diffusion models. In: 2024 IEEE International Conference on Multimedia and Expo (ICME). pp. 1–6. IEEE (2024)
2024
-
[21]
In: International conference on machine learning
Hafner, D., Lillicrap, T., Fischer, I., Villegas, R., Ha, D., Lee, H., Davidson, J.: Learning latent dynamics for planning from pixels. In: International conference on machine learning. pp. 2555–2565. PMLR (2019)
2019
-
[22]
HailuoAI: Hailuo.https://hailuoai.video/(2024), accessed: 2025-02-24
2024
-
[23]
In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference
Han, H., Li, S., Chen, J., Yuan, Y., Wu, Y., Deng, Y., Leong, C.T., Du, H., Fu, J., Li, Y., et al.: Video-bench: Human-aligned video generation benchmark. In: Pro- ceedings of the Computer Vision and Pattern Recognition Conference. pp. 18858– 18868 (2025)
2025
-
[24]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Hassan, M., Stapf, S., Rahimi, A., Rezende, P., Haghighi, Y., Brüggemann, D., Katircioglu,I.,Zhang,L.,Chen,X.,Saha,S.,etal.:Gem:Ageneralizableego-vision multimodal world model for fine-grained ego-motion, object dynamics, and scene composition control. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 22404–22415 (2025)
2025
-
[25]
Advances in neural information processing systems30(2017)
Heusel,M.,Ramsauer,H.,Unterthiner,T.,Nessler,B.,Hochreiter,S.:Ganstrained by a two time-scale update rule converge to a local nash equilibrium. Advances in neural information processing systems30(2017)
2017
-
[26]
GAIA-1: A Generative World Model for Autonomous Driving
Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., Corrado, G.: Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 (2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[27]
Iclr1(2), 3 (2022)
Hu, E.J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., Chen, W., et al.: Lora: Low-rank adaptation of large language models. Iclr1(2), 3 (2022)
2022
-
[28]
IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10579–10596 (2024)
Hu, M., Yin, W., Zhang, C., Cai, Z., Long, X., Chen, H., Wang, K., Yu, G., Shen, C., Shen, S.: Metric3d v2: A versatile monocular geometric foundation model for zero-shot metric depth and surface normal estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence46(12), 10579–10596 (2024)
2024
-
[29]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video gener- ative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024)
2024
-
[30]
Kalman, R.E.: A new approach to linear filtering and prediction problems (1960)
1960
-
[31]
How Far is Video Generation from World Model: A Physical Law Perspective
Kang, B., Yue, Y., Lu, R., Lin, Z., Zhao, Y., Wang, K., Huang, G., Feng, J.: How far is video generation from world model: A physical law perspective, 2024. URL https://arxiv. org/abs/2411.023852, 36
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
IEEE Trans- actions on Intelligent Vehicles9(1), 1792–1803 (2023) 32 N
Karim, M.M., Yin, Z., Qin, R.: An attention-guided multistream feature fusion network for early localization of risky traffic agents in driving videos. IEEE Trans- actions on Intelligent Vehicles9(1), 1792–1803 (2023) 32 N. Chen et al
2023
-
[33]
MapAnything: Universal Feed-Forward Metric 3D Reconstruction
Keetha, N., Müller, N., Schönberger, J., Porzi, L., Zhang, Y., Fischer, T., Knapitsch, A., Zauss, D., Weber, E., Antunes, N., et al.: Mapanything: Univer- sal feed-forward metric 3d reconstruction. arXiv preprint arXiv:2509.13414 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Kim, H., Lee, K., Hwang, G., Suh, C.: Crash to not crash: Learn to identify dan- gerous vehicles using a simulator. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 33, pp. 978–985 (2019)
2019
-
[35]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Li, C., Zhou, K., Liu, T., Wang, Y., Zhuang, M., Gao, H.a., Jin, B., Zhao, H.: Avd2: Accident video diffusion for accident video description. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 13289–13296. IEEE (2025)
2025
-
[36]
Advances in Neural Information Processing Systems37, 109790–109816 (2024)
Liao, M., Ye, Q., Zuo, W., Wan, F., Wang, T., Zhao, Y., Wang, J., Zhang, X., et al.: Evaluation of text-to-video generation models: A dynamics perspective. Advances in Neural Information Processing Systems37, 109790–109816 (2024)
2024
-
[37]
IEEE Transactions on Intelligent Transportation Systems23(8), 12518–12530 (2021)
Liu, C., Li, Z., Chang, F., Li, S., Xie, J.: Temporal shift and spatial attention-based two-stream network for traffic risk assessment. IEEE Transactions on Intelligent Transportation Systems23(8), 12518–12530 (2021)
2021
- [38]
-
[39]
In: European Conference on Computer Vision
Liu, S., Ren, Z., Gupta, S., Wang, S.: Physgen: Rigid-body physics-grounded image-to-video generation. In: European Conference on Computer Vision. pp. 360–
-
[40]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Liu, Y., Cun, X., Liu, X., Wang, X., Zhang, Y., Chen, H., Liu, Y., Zeng, T., Chan, R., Shan, Y.: Evalcrafter: Benchmarking and evaluating large video generation models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22139–22149 (2024)
2024
-
[41]
Decoupled Weight Decay Regularization
Loshchilov, I., Hutter, F.: Decoupled weight decay regularization. arXiv preprint arXiv:1711.05101 (2017)
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[42]
In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Luo, H., Wang, F.: A simulation-based framework for urban traffic accident detec- tion. In: ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2023)
2023
-
[43]
Towards World Simulator: Crafting Physical Commonsense-Based Benchmark for Video Generation
Meng, F., Liao, J., Tan, X., Shao, W., Lu, Q., Zhang, K., Cheng, Y., Li, D., Qiao, Y., Luo, P.: Towards world simulator: Crafting physical commonsense-based benchmark for video generation. arXiv preprint arXiv:2410.05363 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[44]
https://www.ecfr.gov/current/title-49/subtitle-B/chapter-V/part-563/ section-563.7
National Highway Traffic Safety Administration: 49 CFR §563.7, Data Elements. https://www.ecfr.gov/current/title-49/subtitle-B/chapter-V/part-563/ section-563.7
-
[45]
Puyin, L., Xiang, T., Mao, E., Wei, S., Chen, X., Masood, A., Fei-Fei, L., Adeli, E.: Quantiphy: A quantitative benchmark evaluating physical reasoning abilities of vision-language models. arXiv preprint arXiv:2512.19526 (2025)
-
[46]
In: International conference on machine learning
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021)
2021
-
[47]
AIAA journal3(8), 1445–1450 (1965)
Rauch, H.E., Tung, F., Striebel, C.T.: Maximum likelihood estimates of linear dynamic systems. AIAA journal3(8), 1445–1450 (1965)
1965
-
[48]
SAM 2: Segment Anything in Images and Videos
Ravi, N., Gabeur, V., Hu, Y.T., Hu, R., Ryali, C., Ma, T., Khedr, H., Rädle, R., Rolland, C., Gustafson, L., et al.: Sam 2: Segment anything in images and videos. arXiv preprint arXiv:2408.00714 (2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[49]
nature163(4148), 688–688 (1949)
Simpson, E.H.: Measurement of diversity. nature163(4148), 688–688 (1949)
1949
-
[50]
Cambridge university press (2018) A Physics-Grounded Benchmark for Multi-Agent Dynamics in World Models 33
Stronge, W.J.: Impact mechanics. Cambridge university press (2018) A Physics-Grounded Benchmark for Multi-Agent Dynamics in World Models 33
2018
-
[51]
In: Proceed- ings of the Computer Vision and Pattern Recognition Conference
Sun, K., Huang, K., Liu, X., Wu, Y., Xu, Z., Li, Z., Liu, X.: T2v-compbench: A comprehensive benchmark for compositional text-to-video generation. In: Proceed- ings of the Computer Vision and Pattern Recognition Conference. pp. 8406–8416 (2025)
2025
-
[52]
Advances in neural information processing systems34, 16558–16569 (2021)
Teed, Z., Deng, J.: Droid-slam: Deep visual slam for monocular, stereo, and rgb- d cameras. Advances in neural information processing systems34, 16558–16569 (2021)
2021
-
[53]
Playerone: Egocentric world simulator.arXiv preprint arXiv:2506.09995, 2025
Tu, Y., Luo, H., Chen, X., Bai, X., Wang, F., Zhao, H.: Playerone: Egocentric world simulator. arXiv preprint arXiv:2506.09995 (2025)
-
[54]
Towards Accurate Generative Models of Video: A New Metric & Challenges
Unterthiner, T., Van Steenkiste, S., Kurach, K., Marinier, R., Michalski, M., Gelly, S.: Towards accurate generative models of video: A new metric & challenges. arXiv preprint arXiv:1812.01717 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[55]
Wan: Open and Advanced Large-Scale Video Generative Models
Wan, T., Wang, A., Ai, B., Wen, B., Mao, C., Xie, C.W., Chen, D., Yu, F., Zhao, H., Yang, J., et al.: Wan: Open and advanced large-scale video generative models. arXiv preprint arXiv:2503.20314 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Wang, T., Kim, S., Wenxuan, J., Xie, E., Ge, C., Chen, J., Li, Z., Luo, P.: Deepac- cident: A motion and accident prediction benchmark for v2x autonomous driving. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 38, pp. 5599–5606 (2024)
2024
-
[57]
In: European conference on computer vision
Wang, X., Zhu, Z., Huang, G., Chen, X., Zhu, J., Lu, J.: Drivedreamer: Towards real-world-drive world models for autonomous driving. In: European conference on computer vision. pp. 55–72. Springer (2024)
2024
-
[58]
In: European Conference on Computer Vision
Wang, Y., Lipson, L., Deng, J.: Sea-raft: Simple, efficient, accurate raft for optical flow. In: European Conference on Computer Vision. pp. 36–54. Springer (2024)
2024
-
[59]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wang, Y., He, J., Fan, L., Li, H., Chen, Y., Zhang, Z.: Driving into the future: Mul- tiview visual forecasting and planning with world model for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 14749–14759 (2024)
2024
-
[60]
Warner, C.Y., Smith, G.C., James, M.B., Germane, G.J.: Friction applications in accident reconstruction. Tech. rep., SAE Technical Paper (1983)
1983
-
[61]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Wen, Y., Zhao, Y., Liu, Y., Jia, F., Wang, Y., Luo, C., Zhang, C., Wang, T., Sun, X., Zhang, X.: Panacea: Panoramic and controllable video generation for autonomous driving. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 6902–6912 (2024)
2024
-
[62]
arXiv preprint arXiv:2401.07781 (2024)
Wu, J.Z., Fang, G., Wu, H., Wang, X., Ge, Y., Cun, X., Zhang, D.J., Liu, J.W., Gu, Y., Zhao, R., et al.: Towards a better metric for text-to-video generation. arXiv preprint arXiv:2401.07781 (2024)
-
[63]
Xu, R., Lin, H., Jeon, W., Feng, H., Zou, Y., Sun, L., Gorman, J., Tolstaya, E., Tang, S., White, B., et al.: Wod-e2e: Waymo open dataset for end-to-end driving in challenging long-tail scenarios. arXiv preprint arXiv:2510.26125 (2025)
-
[64]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Xue, Q., Yin, X., Yang, B., Gao, W.: Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 18826–18836 (2025)
2025
-
[65]
IEEE transactions on pattern analysis and machine intelligence45(1), 444–459 (2022)
Yao, Y., Wang, X., Xu, M., Pu, Z., Wang, Y., Atkins, E., Crandall, D.J.: Dota: Unsupervised detection of traffic anomaly in driving videos. IEEE transactions on pattern analysis and machine intelligence45(1), 444–459 (2022)
2022
-
[66]
In: 2019 IEEE/RSJ International conference on intelligent robots and systems (IROS)
Yao, Y., Xu, M., Wang, Y., Crandall, D.J., Atkins, E.M.: Unsupervised traffic acci- dent detection in first-person videos. In: 2019 IEEE/RSJ International conference on intelligent robots and systems (IROS). pp. 273–280. IEEE (2019)
2019
-
[67]
In: Euro- pean Conference on Computer Vision
You, T., Han, B.: Traffic accident benchmark for causality recognition. In: Euro- pean Conference on Computer Vision. pp. 540–556. Springer (2020) 34 N. Chen et al
2020
-
[68]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Zhang, K., Tang, Z., Hu, X., Pan, X., Guo, X., Liu, Y., Huang, J., Yuan, L., Zhang, Q., Long, X.X., et al.: Epona: Autoregressive diffusion world model for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27220–27230 (2025)
2025
-
[69]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Zhao, G., Wang, X., Zhu, Z., Chen, X., Huang, G., Bao, X., Wang, X.: Drivedreamer-2: Llm-enhanced world models for diverse driving video generation. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 10412–10420 (2025)
2025
-
[70]
VBench-2.0: Advancing Video Generation Benchmark Suite for Intrinsic Faithfulness
Zheng, D., Huang, Z., Liu, H., Zou, K., He, Y., Zhang, F., Gu, L., Zhang, Y., He, J., Zheng, W.S., et al.: Vbench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness. arXiv preprint arXiv:2503.21755 (2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[71]
In: European conference on computer vision
Zheng, W., Chen, W., Huang, Y., Zhang, B., Duan, Y., Lu, J.: Occworld: Learning a 3d occupancy world model for autonomous driving. In: European conference on computer vision. pp. 55–72. Springer (2024)
2024
-
[72]
Vehicle System Dynamics46(S1), 3–15 (2008)
Zhou, J., Peng, H., Lu, J.: Collision model for vehicle motion prediction after light impacts. Vehicle System Dynamics46(S1), 3–15 (2008)
2008
-
[73]
In: European conference on computer vision
Zhou, X., Koltun, V., Krähenbühl, P.: Tracking objects as points. In: European conference on computer vision. pp. 474–490. Springer (2020)
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.