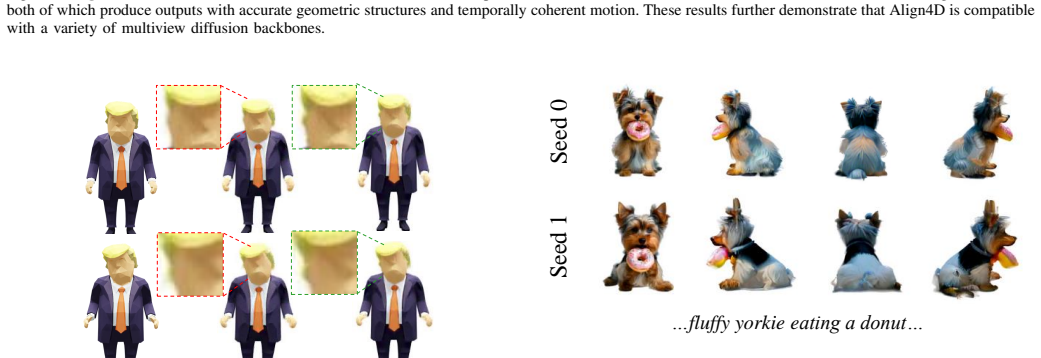
Alignment Is All You Need For X-to-4D Generation
Pith reviewed 2026-07-03 14:29 UTC · model grok-4.3
The pith
Align4D converts any-modal inputs into coherent 4D video-3D pairs via three targeted alignment steps.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
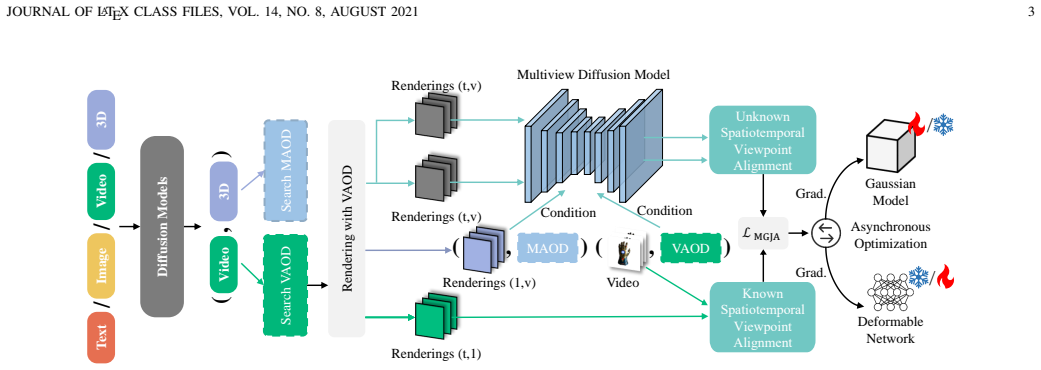
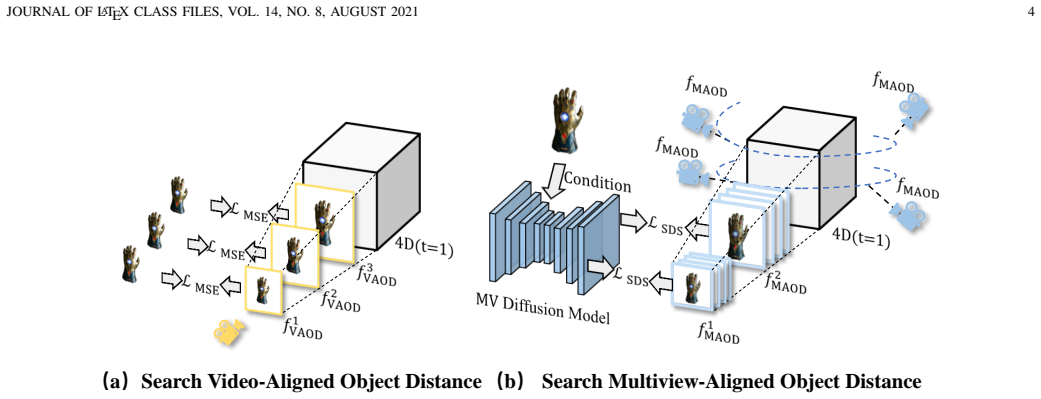
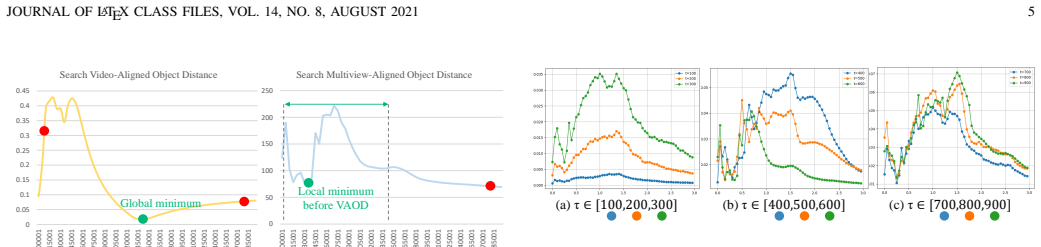
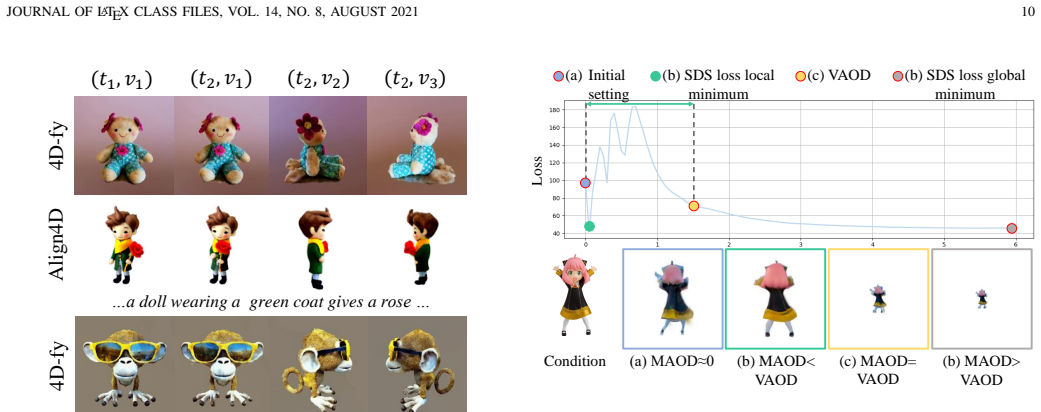
Align4D translates any-modal input into coherent video-3D pairs by searching Video-Aligned and Multiview-Aligned Object Distances to match 4D renderings against video and multiview priors, constraining known and unknown views through synchronized inputs for motion-geometry consistency, and decoupling Gaussian attribute and deformation network training via asynchronous optimization to improve fidelity.
What carries the argument
Object Distance Alignment (VAOD/MAOD search) together with Motion-Geometry Joint Alignment and Asynchronous Optimization, which together reconcile multimodal inputs against video and multiview diffusion priors.
If this is right
- X-to-4D generation becomes possible from arbitrary user inputs without constructing large paired training sets.
- Video and 3D data can jointly supervise 4D output to enforce both motion and geometry consistency.
- Decoupling attribute and deformation optimization improves separate control over appearance and dynamics.
- The released X4D dataset supplies a unified benchmark mixing prompt, image, video, and 3D inputs.
Where Pith is reading between the lines
- The same alignment pattern could be tested on additional input types such as audio or sketches to widen the set of usable controls.
- If the distance-search step generalizes, similar reconciliation methods might reduce view inconsistency in other 4D pipelines that combine diffusion priors.
- Asynchronous optimization might be examined in isolation on existing 4D methods to measure its isolated contribution to motion fidelity.
Load-bearing premise
The three alignment techniques can reconcile arbitrary multimodal inputs with video and multiview diffusion priors without large paired datasets or introducing inconsistencies.
What would settle it
A direct comparison on the X4D dataset in which Align4D produces visibly inconsistent geometry or motion across views while a prior method does not would falsify the central claim.
Figures








read the original abstract
Generative diffusion models excel at synthesizing high-quality images, videos, and 3D content under multimodal control. However, arbitrary user-defined modality-to-4D (X-to-4D) generation remains challenging due to the high cost of constructing diverse datasets and the limited scalability of existing methods. This paper presents Align4D, a flexible framework that translates any-modal input into coherent video-3D pairs, using video to guide 4D motion and 3D data to shape 4D geometry. Align4D introduces three key techniques: (1) Object Distance Alignment, which searches Video-Aligned and Multiview-Aligned Object Distances (VAOD/MAOD), respectively, to reconcile 4D renderings with video and the priors of multiview diffusion models; (2) Motion-Geometry Joint Alignment, which constrains known and unknown views through synchronized video and 3D inputs, ensuring consistent 4D generation; and (3) Asynchronous Optimization, which decouples Gaussian attribute and deformation network training to enhance motion and geometry fidelity. We further propose the X4D dataset, which integrates prompt, image, video, and 3D data for benchmarking. Experiments on X4D and Consistent4D demonstrate that Align4D achieves state-of-the-art quality and consistency in X-to-4D generation. Project page: https://miaoqiaowei.github.io/Align4D/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Align4D, a framework for arbitrary X-to-4D generation that converts multimodal inputs into coherent video-3D pairs. It proposes three alignment techniques—Object Distance Alignment (via VAOD/MAOD search), Motion-Geometry Joint Alignment, and Asynchronous Optimization—along with the new X4D dataset, and reports state-of-the-art quality and consistency on the X4D and Consistent4D benchmarks.
Significance. If the experimental claims hold, the work could meaningfully advance flexible multimodal 4D synthesis by avoiding the need for large paired training sets through explicit alignment of video motion priors and multiview geometry priors. The introduction of the X4D benchmark dataset is a concrete contribution that enables future comparisons.
minor comments (2)
- The abstract asserts SOTA results but does not include any quantitative metrics, baseline comparisons, or error bars; the experimental section should be cross-referenced in the abstract for immediate clarity.
- Notation for VAOD and MAOD is introduced in the abstract without an accompanying equation or definition in the main text; add a short formal definition in §3.1.
Simulated Author's Rebuttal
We thank the referee for the positive summary, recognition of the significance of Align4D and the X4D dataset, and the recommendation for minor revision. No specific major comments were provided in the report.
Circularity Check
No significant circularity detected
full rationale
The paper presents Align4D as a new framework with three explicitly introduced alignment techniques and a new X4D dataset. No derivation chain, equations, or predictions are shown that reduce by construction to fitted inputs, self-definitions, or self-citation load-bearing premises. The abstract and described contributions treat the methods as independent innovations evaluated on external benchmarks, rendering the central claims self-contained.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models,
H. Ling, S. W. Kim, A. Torralba, S. Fidler, and K. Kreis, “Align your gaussians: Text-to-4d with dynamic 3d gaussians and composed diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 8576–8588
2024
-
[2]
4d-fy: Text-to-4d generation using hybrid score distillation sampling,
S. Bahmani, I. Skorokhodov, V . Rong, G. Wetzstein, L. Guibas, P. Wonka, S. Tulyakov, J. J. Park, A. Tagliasacchi, and D. B. Lindell, “4d-fy: Text-to-4d generation using hybrid score distillation sampling,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7996–8006
2024
-
[4]
Text-to- 4d dynamic scene generation,
U. Singer, S. Sheynin, A. Polyak, O. Ashual, I. Makarov, F. Kokkinos, N. Goyal, A. Vedaldi, D. Parikh, J. Johnson, and Y . Taigman, “Text-to- 4d dynamic scene generation,” inInternational Conference on Machine Learning, 2023
2023
-
[5]
Consistent4d: Consistent 360° dynamic object generation from monocular video,
Y . Jiang, L. Zhang, J. Gao, W. Hu, and Y . Yao, “Consistent4d: Consistent 360° dynamic object generation from monocular video,” in International Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=sPUrdFGepF
2024
-
[6]
Ani- mate124: Animating one image to 4d dynamic scene,
Y . Zhao, Z. Yan, E. Xie, L. Hong, Z. Li, and G. H. Lee, “Ani- mate124: Animating one image to 4d dynamic scene,”arXiv preprint arXiv:2311.14603, 2023
-
[7]
Dreamgaussian4d: Generative 4d gaussian splatting,
J. Ren, L. Pan, J. Tang, C. Zhang, A. Cao, G. Zeng, and Z. Liu, “Dreamgaussian4d: Generative 4d gaussian splatting,”arXiv preprint arXiv:2312.17142, 2023
-
[8]
L4gm: Large 4d gaussian reconstruction model,
J. Ren, C. Xie, A. Mirzaei, K. Kreis, Z. Liu, A. Torralba, S. Fidler, S. W. Kim, H. Linget al., “L4gm: Large 4d gaussian reconstruction model,” Annual Conference on Neural Information Processing Systems, vol. 37, pp. 56 828–56 858, 2024
2024
-
[9]
Efficient4d: Fast dy- namic 3d object generation from a single-view video,
Z. Pan, Z. Yang, X. Zhu, and L. Zhang, “Efficient4d: Fast dy- namic 3d object generation from a single-view video,”arXiv preprint arXiv:2401.08742, 2024. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 13
-
[10]
Sc4d: Sparse- controlled video-to-4d generation and motion transfer,
Z. Wu, C. Yu, Y . Jiang, C. Cao, F. Wang, and X. Bai, “Sc4d: Sparse- controlled video-to-4d generation and motion transfer,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 361–379
2024
-
[11]
Diffusion$ˆ2$: Dynamic 3d content generation via score composition of video and multi- view diffusion models,
Z. Yang, Z. Pan, C. Gu, and L. Zhang, “Diffusion$ˆ2$: Dynamic 3d content generation via score composition of video and multi- view diffusion models,” inInternational Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/ forum?id=fectsEG2GU
2025
-
[12]
Disco4d: Disentangled 4d human generation and animation from a single image,
H. E. Pang, S. Liu, Z. Cai, L. Yang, T. Zhang, and Z. Liu, “Disco4d: Disentangled 4d human generation and animation from a single image,” inProceedings of the Computer Vision and Pattern Recognition Confer- ence, 2025, pp. 26 331–26 344
2025
-
[13]
Vidu4d: Single generated video to high-fidelity 4d reconstruction with dynamic gaussian surfels,
Y . Wang, X. Wang, Z. Chen, Z. Wang, F. Sun, and J. Zhu, “Vidu4d: Single generated video to high-fidelity 4d reconstruction with dynamic gaussian surfels,”Annual Conference on Neural Information Processing Systems, vol. 37, pp. 131 316–131 343, 2024
2024
-
[14]
SV4d: Dynamic 3d content generation with multi-frame and multi-view consistency,
Y . Xie, C.-H. Yao, V . V oleti, H. Jiang, and V . Jampani, “SV4d: Dynamic 3d content generation with multi-frame and multi-view consistency,” in International Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=tJoS2d0Onf
2025
-
[15]
Diffusion4d: fast spatial-temporal consistent 4d generation via video diffusion models,
H. Liang, Y . Yin, D. Xu, H. Liang, Z. Wang, K. N. Plataniotis, Y . Zhao, and Y . Wei, “Diffusion4d: fast spatial-temporal consistent 4d generation via video diffusion models,” inAnnual Conference on Neural Information Processing Systems, 2024
2024
-
[16]
VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
H. Chen, M. Xia, Y . He, Y . Zhang, X. Cun, S. Yang, J. Xing, Y . Liu, Q. Chen, X. Wanget al., “Videocrafter1: Open diffusion models for high-quality video generation,”arXiv preprint arXiv:2310.19512, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[17]
Videocrafter2: Overcoming data limitations for high-quality video diffusion models,
H. Chen, Y . Zhang, X. Cun, M. Xia, X. Wang, C. Weng, and Y . Shan, “Videocrafter2: Overcoming data limitations for high-quality video diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7310–7320
2024
-
[18]
Video generation models as world simulators,
T. Brooks, B. Peebles, C. Holmes, W. DePue, Y . Guo, L. Jing, D. Schnurr, J. Taylor, T. Luhman, E. Luhman, C. Ng, R. Wang, and A. Ramesh, “Video generation models as world simulators,” 2024. [Online]. Available: https: //openai.com/research/video-generation-models-as-world-simulators
2024
-
[19]
Stable Video Diffusion: Scaling Latent Video Diffusion Models to Large Datasets
A. Blattmann, T. Dockhorn, S. Kulal, D. Mendelevitch, M. Kilian, D. Lorenz, Y . Levi, Z. English, V . V oleti, A. Lettset al., “Stable video diffusion: Scaling latent video diffusion models to large datasets,”arXiv preprint arXiv:2311.15127, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[20]
Lgm: Large multi-view gaussian model for high-resolution 3d content creation,
J. Tang, Z. Chen, X. Chen, T. Wang, G. Zeng, and Z. Liu, “Lgm: Large multi-view gaussian model for high-resolution 3d content creation,” in European Conference on Computer Vision. Springer, 2024, pp. 1–18
2024
-
[21]
Crm: Single image to 3d textured mesh with convolutional reconstruction model,
Z. Wang, Y . Wang, Y . Chen, C. Xiang, S. Chen, D. Yu, C. Li, H. Su, and J. Zhu, “Crm: Single image to 3d textured mesh with convolutional reconstruction model,” inEuropean Conference on Computer Vision,
-
[22]
Available: https://api.semanticscholar.org/CorpusID: 268297409
[Online]. Available: https://api.semanticscholar.org/CorpusID: 268297409
-
[23]
Meshy AI: The #1 ai 3d model generator for creators,
Meshy AI, “Meshy AI: The #1 ai 3d model generator for creators,” https://www.meshy.ai/, 2025, accessed: 2025-04-17
2025
-
[24]
Dreammesh4d: Video-to-4d generation with sparse-controlled gaussian-mesh hybrid representation,
Z. Li, Y . Chen, and P. Liu, “Dreammesh4d: Video-to-4d generation with sparse-controlled gaussian-mesh hybrid representation,” inAnnual Conference on Neural Information Processing Systems, 2024
2024
-
[25]
Dreamfusion: Text-to-3d using 2d diffusion,
B. Poole, A. Jain, J. T. Barron, and B. Mildenhall, “Dreamfusion: Text-to-3d using 2d diffusion,” inInternational Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/ forum?id=FjNys5c7VyY
2023
-
[26]
Advances in 4d generation: A survey,
Q. Miao, K. Li, J. Quan, Z. Min, S. Ma, Y . Xu, Y . Yang, P. Liu, and Y . Luo, “Advances in 4d generation: A survey,” 2025. [Online]. Available: https://arxiv.org/abs/2503.14501
-
[27]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogni- tion, June 2022, pp. 10 684–10 695
2022
-
[28]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,” inAnnual Conference on Neural Information Processing Systems, 2022
2022
-
[29]
Sgdm: An adaptive style- guided diffusion model for personalized text to image generation,
Y . Xu, X. Xu, H. Gao, and F. Xiao, “Sgdm: An adaptive style- guided diffusion model for personalized text to image generation,”IEEE Transactions on Multimedia, vol. 26, pp. 9804–9813, 2024
2024
-
[30]
Model-guided generative adversarial networks for unsupervised fine-grained image generation,
J. Xiao and X. Bi, “Model-guided generative adversarial networks for unsupervised fine-grained image generation,”IEEE Transactions on Multimedia, vol. 26, pp. 1188–1199, 2024
2024
-
[31]
Align your latents: High-resolution video synthesis with latent diffusion models,
A. Blattmann, R. Rombach, H. Ling, T. Dockhorn, S. W. Kim, S. Fidler, and K. Kreis, “Align your latents: High-resolution video synthesis with latent diffusion models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2023, pp. 22 563–22 575
2023
-
[32]
Preserve your own correlation: A noise prior for video diffusion models,
S. Ge, S. Nah, G. Liu, T. Poon, A. Tao, B. Catanzaro, D. Jacobs, J.- B. Huang, M.-Y . Liu, and Y . Balaji, “Preserve your own correlation: A noise prior for video diffusion models,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 22 930–22 941
2023
-
[33]
Factorizing text-to-video generation by explicit image conditioning,
R. Girdhar, M. Singh, A. Brown, Q. Duval, S. Azadi, S. S. Rambhatla, A. Shah, X. Yin, D. Parikh, and I. Misra, “Factorizing text-to-video generation by explicit image conditioning,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 205–224
2024
-
[34]
Animatediff: Animate your personalized text- to-image diffusion models without specific tuning,
Y . Guo, C. Yang, A. Rao, Z. Liang, Y . Wang, Y . Qiao, M. Agrawala, D. Lin, and B. Dai, “Animatediff: Animate your personalized text- to-image diffusion models without specific tuning,” inInternational Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=Fx2SbBgcte
2024
-
[35]
Imagen Video: High Definition Video Generation with Diffusion Models
J. Ho, W. Chan, C. Saharia, J. Whang, R. Gao, A. Gritsenko, D. P. Kingma, B. Poole, M. Norouzi, D. J. Fleetet al., “Imagen video: High definition video generation with diffusion models,”arXiv preprint arXiv:2210.02303, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[36]
Text2video-zero: Text-to-image diffusion models are zero-shot video generators,
L. Khachatryan, A. Movsisyan, V . Tadevosyan, R. Henschel, Z. Wang, S. Navasardyan, and H. Shi, “Text2video-zero: Text-to-image diffusion models are zero-shot video generators,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 15 954–15 964
2023
-
[37]
Controllable video generation with text-based instructions,
A. K ¨oksal, K. E. Ak, Y . Sun, D. Rajan, and J. H. Lim, “Controllable video generation with text-based instructions,”IEEE Transactions on Multimedia, vol. 26, pp. 190–201, 2024
2024
-
[38]
Video2roleplay: A multimodal dataset and framework for video-guided role-playing agents,
X. Zhang, C. Zhang, J. Xu, Y . Zhu, X. Shi, Y . Yang, and Y . Luo, “Video2roleplay: A multimodal dataset and framework for video-guided role-playing agents,” inProceedings of the 2025 Conference on Empiri- cal Methods in Natural Language Processing, 2025, pp. 23 688–23 714
2025
-
[39]
Motionvideogan: A novel video generator based on the motion space learned from image pairs,
J. Zhu, H. Ma, J. Chen, and J. Yuan, “Motionvideogan: A novel video generator based on the motion space learned from image pairs,”IEEE Transactions on Multimedia, vol. 25, pp. 9370–9382, 2023
2023
-
[40]
Make-a-video: Text-to-video generation without text-video data,
U. Singer, A. Polyak, T. Hayes, X. Yin, J. An, S. Zhang, Q. Hu, H. Yang, O. Ashual, O. Gafni, D. Parikh, S. Gupta, and Y . Taigman, “Make-a-video: Text-to-video generation without text-video data,” in International Conference on Learning Representations, 2023. [Online]. Available: https://openreview.net/forum?id=nJfylDvgzlq
2023
-
[41]
MVDream: Multi- view diffusion for 3d generation,
Y . Shi, P. Wang, J. Ye, L. Mai, K. Li, and X. Yang, “MVDream: Multi- view diffusion for 3d generation,” inInternational Conference on Learning Representations, 2024. [Online]. Available: https: //openreview.net/forum?id=FUgrjq2pbB
2024
-
[42]
Zero123++: a Single Image to Consistent Multi-view Diffusion Base Model
R. Shi, H. Chen, Z. Zhang, M. Liu, C. Xu, X. Wei, L. Chen, C. Zeng, and H. Su, “Zero123++: a single image to consistent multi-view diffusion base model,”arXiv preprint arXiv:2310.15110, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[43]
Wonder3d: Single image to 3d using cross-domain diffusion,
X. Long, Y .-C. Guo, C. Lin, Y . Liu, Z. Dou, L. Liu, Y . Ma, S.-H. Zhang, M. Habermann, C. Theobaltet al., “Wonder3d: Single image to 3d using cross-domain diffusion,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 9970–9980
2024
-
[44]
Shapegpt: 3d shape generation with a unified multi-modal language model,
F. Yin, X. Chen, C. Zhang, B. Jiang, Z. Zhao, W. Liu, G. Yu, and T. Chen, “Shapegpt: 3d shape generation with a unified multi-modal language model,”IEEE Transactions on Multimedia, vol. 27, pp. 4107– 4120, 2025
2025
-
[45]
Maan: Memory-augmented auto-regressive network for text-driven 3d indoor scene generation,
Z. Ye, Y . Liu, and Y . Peng, “Maan: Memory-augmented auto-regressive network for text-driven 3d indoor scene generation,”IEEE Transactions on Multimedia, vol. 26, pp. 11 057–11 069, 2024
2024
-
[46]
Dream- texture: High-fidelity synthetic 3d data generation through decoupled geometry and texture synthesis,
J. Li, Y . Luo, Y . Li, X. Li, X. Li, Y . Hao, L. Wang, and Z. Li, “Dream- texture: High-fidelity synthetic 3d data generation through decoupled geometry and texture synthesis,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 303–320
2024
-
[47]
Entangled view- epipolar information aggregation for generalizable neural radiance fields,
Z. Min, Y . Luo, W. Yang, Y . Wang, and Y . Yang, “Entangled view- epipolar information aggregation for generalizable neural radiance fields,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 4906–4916
2024
-
[48]
Epipolar-free 3d gaussian splatting for generalizable novel view synthesis,
Z. Min, Y . Luo, J. Sun, and Y . Yang, “Epipolar-free 3d gaussian splatting for generalizable novel view synthesis,” inAnnual Conference on Neural Information Processing Systems, 2024, pp. 39 573–39 596
2024
-
[49]
Stag4d: Spatial-temporal anchored generative 4d gaussians,
Y . Zeng, Y . Jiang, S. Zhu, Y . Lu, Y . Lin, H. Zhu, W. Hu, X. Cao, and Y . Yao, “Stag4d: Spatial-temporal anchored generative 4d gaussians,” in European Conference on Computer Vision. Springer, 2025, pp. 163– 179
2025
-
[50]
A unified approach for text-and image-guided 4d scene generation,
Y . Zheng, X. Li, K. Nagano, S. Liu, O. Hilliges, and S. De Mello, “A unified approach for text-and image-guided 4d scene generation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024, pp. 7300–7309
2024
-
[51]
Particlegs: Learning neural gaussian particle dynamics from videos JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 for prior-free physical motion extrapolation,
J. Quan, Q. Miao, Y . Xu, Z. Lin, Y . Li, W. Yang, Z. Li, and Y . Luo, “Particlegs: Learning neural gaussian particle dynamics from videos JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 14 for prior-free physical motion extrapolation,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 8331–8341
2021
-
[52]
Frequency-aware dynamic gaussian splatting,
Q. Miao, J. Quan, K. Li, Y . Xu, Y . Yang, and Y . Luo, “Frequency-aware dynamic gaussian splatting,” inThe F ourteenth International Conference on Learning Representations, 2026
2026
-
[53]
Langfield4d: Learning identity-adaptive and spatio-temporal continuous 4d language fields for dynamic scenes,
Y . Xu, Q. Miao, J. Quan, W. Yang, Z. Li, and Y . Luo, “Langfield4d: Learning identity-adaptive and spatio-temporal continuous 4d language fields for dynamic scenes,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026, pp. 9558–9569
2026
-
[54]
Zero-1-to-3: Zero-shot one image to 3d object,
R. Liu, R. Wu, B. Van Hoorick, P. Tokmakov, S. Zakharov, and C. V on- drick, “Zero-1-to-3: Zero-shot one image to 3d object,” inProceedings of the IEEE/CVF International Conference on Computer Vision, 2023, pp. 9298–9309
2023
-
[55]
Prolific- dreamer: High-fidelity and diverse text-to-3d generation with variational score distillation,
Z. Wang, C. Lu, Y . Wang, F. Bao, C. Li, H. Su, and J. Zhu, “Prolific- dreamer: High-fidelity and diverse text-to-3d generation with variational score distillation,”Annual Conference on Neural Information Processing Systems, vol. 36, 2024
2024
-
[56]
Variational diffusion models,
D. Kingma, T. Salimans, B. Poole, and J. Ho, “Variational diffusion models,”Annual Conference on Neural Information Processing Systems, vol. 34, pp. 21 696–21 707, 2021
2021
-
[57]
Score-based generative modeling through stochastic differential equations,
Y . Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, and B. Poole, “Score-based generative modeling through stochastic differential equations,” inInternational Conference on Learning Representations, 2021. [Online]. Available: https://openreview.net/ forum?id=PxTIG12RRHS
2021
-
[58]
SDXL: Improving latent diffusion models for high-resolution image synthesis,
D. Podell, Z. English, K. Lacey, A. Blattmann, T. Dockhorn, J. M ¨uller, J. Penna, and R. Rombach, “SDXL: Improving latent diffusion models for high-resolution image synthesis,” inInternational Conference on Learning Representations, 2024. [Online]. Available: https://openreview.net/forum?id=di52zR8xgf
2024
-
[59]
imagetoprompt,
C. Holtz, “imagetoprompt,” Feb. 2025. [Online]. Available: https: //imagetoprompt.com/
2025
-
[60]
Kling AI: Next-generation ai creative studio,
Kling, “Kling AI: Next-generation ai creative studio,” https://klingai. com/, 2025, accessed: 2025-04-17
2025
-
[61]
A Formal Evaluation of PSNR as Quality Measurement Parameter for Image Segmentation Algorithms
F. A. Fardo, V . H. Conforto, F. C. de Oliveira, and P. S. Rodrigues, “A formal evaluation of psnr as quality measurement parameter for image segmentation algorithms,”arXiv preprint arXiv:1605.07116, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[62]
Multiscale structural similarity for image quality assessment,
Z. Wang, E. P. Simoncelli, and A. C. Bovik, “Multiscale structural similarity for image quality assessment,” inAsilomar Conference on Signals, Systems & Computers, vol. 2. Ieee, 2003, pp. 1398–1402
2003
-
[63]
The unreasonable effectiveness of deep features as a perceptual metric,
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang, “The unreasonable effectiveness of deep features as a perceptual metric,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2018, pp. 586–595
2018
-
[64]
Learning Transferable Visual Models From Natural Language Supervision
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever, “Learning transferable visual models from natural language supervision,” 2021. [Online]. Available: https://arxiv.org/abs/2103.00020
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[65]
FVD: A new metric for video generation,
T. Unterthiner, S. van Steenkiste, K. Kurach, R. Marinier, M. Michalski, and S. Gelly, “FVD: A new metric for video generation,” 2019. [Online]. Available: https://openreview.net/forum?id=rylgEULtdN
2019
-
[66]
Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints,
J. Bai, M. Xia, X. Wang, Z. Yuan, Z. Liu, H. Hu, P. Wan, and D. ZHANG, “Syncammaster: Synchronizing multi-camera video generation from diverse viewpoints,” inInternational Conference on Learning Representations, 2025. [Online]. Available: https: //openreview.net/forum?id=m8Rk3HLGFx
2025
-
[67]
VBench: Comprehensive benchmark suite for video generative models,
Z. Huang, Y . He, J. Yu, F. Zhang, C. Si, Y . Jiang, Y . Zhang, T. Wu, Q. Jin, N. Chanpaisit, Y . Wang, X. Chen, L. Wang, D. Lin, Y . Qiao, and Z. Liu, “VBench: Comprehensive benchmark suite for video generative models,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2024
2024
-
[68]
Free4d: Tuning-free 4d scene generation with spatial- temporal consistency,
T. Liu, Z. Huang, Z. Chen, G. Wang, S. Hu, L. Shen, H. Sun, Z. Cao, W. Li, and Z. Liu, “Free4d: Tuning-free 4d scene generation with spatial- temporal consistency,” inProceedings of the IEEE/CVF International Conference on Computer Vision, October 2025, pp. 25 571–25 582
2025
-
[69]
4diffusion: Multi-view video diffusion model for 4d generation,
H. Zhang, X. Chen, Y . Wang, X. Liu, Y . Wang, and Y . Qiao, “4diffusion: Multi-view video diffusion model for 4d generation,” in Annual Conference on Neural Information Processing Systems, 2024. [Online]. Available: https://openreview.net/forum?id=SFk7AMpyhx
2024
-
[70]
Crm: Single image to 3d textured mesh with convolutional reconstruction model,
Z. Wang, Y . Wang, Y . Chen, C. Xiang, S. Chen, D. Yu, C. Li, H. Su, and J. Zhu, “Crm: Single image to 3d textured mesh with convolutional reconstruction model,” inEuropean Conference on Computer Vision. Springer, 2024, pp. 57–74
2024
-
[71]
4dgen: Grounded 4d content generation with spatial-temporal consistency,
Y . Yin, D. Xu, Z. Wang, Y . Zhao, and Y . Wei, “4dgen: Grounded 4d content generation with spatial-temporal consistency,”arXiv preprint arXiv:2312.17225, 2023
-
[72]
MonST3r: A simple approach for estimating geometry in the presence of motion,
J. Zhang, C. Herrmann, J. Hur, V . Jampani, T. Darrell, F. Cole, D. Sun, and M.-H. Yang, “MonST3r: A simple approach for estimating geometry in the presence of motion,” inInternational Conference on Learning Representations, 2025. [Online]. Available: https://openreview.net/forum?id=lJpqxFgWCM
2025
-
[73]
arXiv preprint arXiv:2312.02201 , year=
P. Wang and Y . Shi, “Imagedream: Image-prompt multi-view diffusion for 3d generation,” 2023. [Online]. Available: https: //arxiv.org/abs/2312.02201
-
[74]
rembg: Tool for removing image background,
D. Gatis, “rembg: Tool for removing image background,” https://github. com/danielgatis/rembg, Feb. 2021
2021
-
[75]
U2-net: Going deeper with nested u-structure for salient object detection,
X. Qin, Z. Zhang, C. Huang, M. Dehghan, O. R. Zaiane, and M. Jagersand, “U2-net: Going deeper with nested u-structure for salient object detection,”Pattern Recognition, vol. 106, p. 107404, Oct. 2020. [Online]. Available: http://dx.doi.org/10.1016/j.patcog.2020.107404
-
[76]
Tripo Studio 3D AI: Image to 3d model ai tool,
Tripo3D AI, “Tripo Studio 3D AI: Image to 3d model ai tool,” https: //studio.tripo3d.ai/, 2025, accessed: 2025-04-17. Qiaowei Miaoreceived a bachelor’s degree in com- puter science and technology from Hebei University, China, in 2021. He is working toward a PhD at the School of Software Technology, Zhejiang University, China. His research interests includ...
2025
-
[77]
He was a postdoctoral researcher with CCAI, College of Computer Science and Technology in Zhejiang University from 2020 to 2023
He is a ZJU 100 young professor with the School of Software Technology, Zhejiang Univer- sity. He was a postdoctoral researcher with CCAI, College of Computer Science and Technology in Zhejiang University from 2020 to 2023. He was a visiting Ph.D student with ReLER lab, AAII, Univer- sity of Technology Sydney, from 2017 to 2019. His research interests inc...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.