REVIEW 2 major objections 2 minor 19 references
Reviewed by Pith at T0; open to challenge.
T0 means a machine referee read the full paper against a public rubric. The mark states how deep the mechanical check went, never who wrote it. the ladder, T0–T4 →
T0 review · grok-4.3
Late multi-image fusion lets text-only LLMs perform visual commonsense reasoning without multimodal training.
2026-05-23 23:49 UTC pith:S5L2URC5
load-bearing objection LaMI's late multi-image fusion offers a test-time way to add visual grounding to LLMs without retraining, but the abstract leaves the experimental support too thin to judge. the 2 major comments →
LaMI: Augmenting Large Language Models via Late Multi-Image Fusion
The pith
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
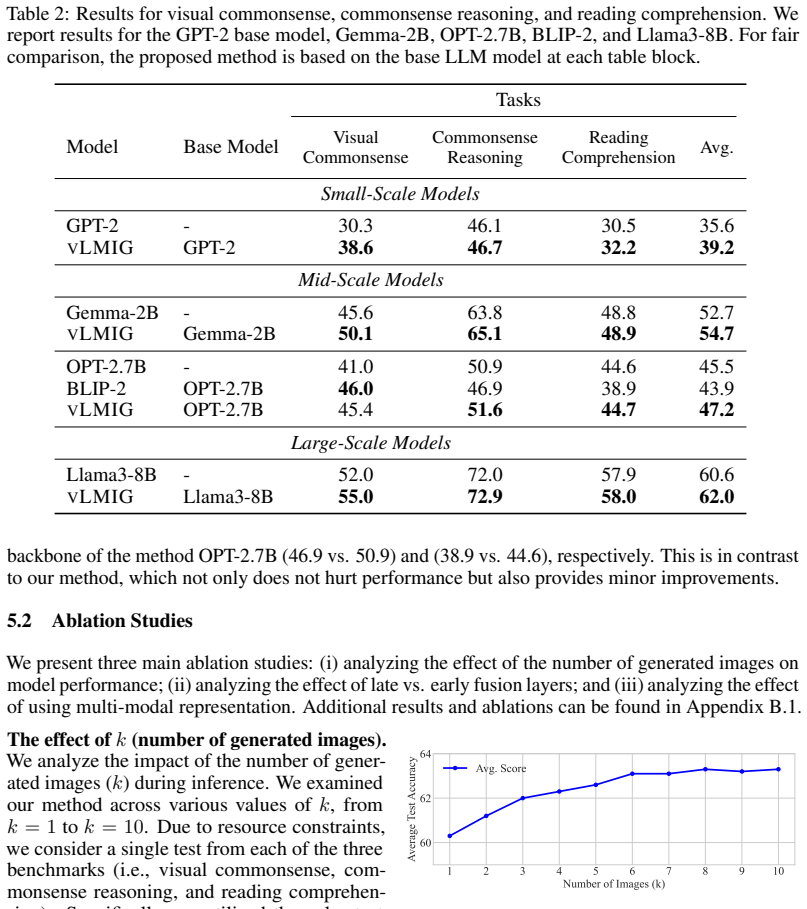
The central claim is that late fusion of multiple generated images via a dedicated layer improves visual reasoning performance over other test-time augmentation approaches, reaches parity with vision-language models on vision tasks, and can even lift NLP results on strong base models such as LLaMA 3, all while incurring only modest extra test-time cost and requiring no multimodal fine-tuning of the underlying LLM.
What carries the argument
The late-fusion layer that integrates projected visual features from multiple images with the text LLM's prediction probabilities immediately before the final output.
Load-bearing premise
That images generated from the text prompt supply reliable visual signals the fusion layer can add without introducing noise that hurts the original text reasoning path.
What would settle it
If the fused model shows no accuracy gain over the plain text LLM on visual commonsense benchmarks that test properties such as object color or spatial relations, the benefit of the late-fusion step would be falsified.
If this is right
- The method outperforms prior test-time visual augmentation techniques on visual reasoning benchmarks.
- Performance on vision-based tasks reaches levels comparable to dedicated vision-language models.
- NLP benchmark scores improve when the approach is applied to strong text-only LLMs such as LLaMA 3.
- Only modest extra computation is required at test time.
Where Pith is reading between the lines
- The same late-fusion pattern could be tested with other external signals such as audio clips or retrieved documents.
- Varying the number of generated images per prompt might reveal an optimal trade-off between accuracy and speed.
- The approach could be combined with retrieval-augmented generation to supply both visual and textual external knowledge.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes LaMI, a test-time augmentation for LLMs that generates multiple images from a text prompt via lightweight parallel sampling, projects their visual features, and combines them with the text-only LLM's prediction probabilities through a late-fusion layer. The central claim is that this yields significant gains on visual commonsense benchmarks over prior augmented LLMs, matches VLMs on vision tasks, improves NLP performance on strong models such as LLaMA 3, and incurs only modest overhead, all without any multimodal fine-tuning of the base LLM.
Significance. If the empirical results hold under rigorous controls, the work would demonstrate a practical route to visual grounding for text-only LLMs that avoids the cost of multimodal retraining and preserves (or even enhances) text-only reasoning, addressing a key limitation of both pure LLMs and current VLMs.
major comments (2)
- [Method description of late-fusion layer] The central assumption that a late-fusion layer can integrate projected features from generated images without introducing noise or misalignment (and without any multimodal training) is load-bearing for all three performance claims. The manuscript should supply explicit ablations that isolate the contribution of the fusion layer versus the text-only path and quantify degradation when generated images contain artifacts.
- [Experiments / results tables] The experimental claims of 'significantly outperforms' and 'matches VLMs' require quantitative support with error bars, statistical tests, and full baseline comparisons. The abstract supplies none of these details; the results section must include them to substantiate the cross-benchmark conclusions.
minor comments (2)
- [Method] Clarify the exact architecture of the projection and fusion layer (dimensions, activation, training status) so that the 'no multimodal fine-tuning' claim can be verified.
- [Abstract / conclusion] The project page URL is given but the manuscript should state whether code and prompts for image generation and fusion are released for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on LaMI. The comments highlight opportunities to strengthen the validation of the late-fusion approach and the statistical rigor of the results. We address each point below and will incorporate the suggested revisions.
read point-by-point responses
-
Referee: [Method description of late-fusion layer] The central assumption that a late-fusion layer can integrate projected features from generated images without introducing noise or misalignment (and without any multimodal training) is load-bearing for all three performance claims. The manuscript should supply explicit ablations that isolate the contribution of the fusion layer versus the text-only path and quantify degradation when generated images contain artifacts.
Authors: We agree that explicit ablations are needed to substantiate the late-fusion layer. In the revised manuscript we will add dedicated experiments that (i) compare the full LaMI model against the text-only LLM path alone, (ii) ablate the fusion layer itself, and (iii) quantify performance drop on subsets where the generated images exhibit visible artifacts. These additions will directly test whether the fusion integrates features without introducing misalignment or noise. revision: yes
-
Referee: [Experiments / results tables] The experimental claims of 'significantly outperforms' and 'matches VLMs' require quantitative support with error bars, statistical tests, and full baseline comparisons. The abstract supplies none of these details; the results section must include them to substantiate the cross-benchmark conclusions.
Authors: The abstract is a high-level summary and does not contain statistical details by design. We will revise the results section to report error bars across runs, include statistical significance tests (e.g., paired t-tests), and present complete baseline tables with identical metrics for all methods. These changes will provide the quantitative support required for the performance claims. revision: yes
Circularity Check
No circularity: empirical augmentation method with independent benchmark validation
full rationale
The paper presents an empirical method for late multi-image fusion to augment LLMs, with claims supported by benchmark results on visual commonsense and NLP tasks rather than any mathematical derivation chain. No equations, fitted parameters renamed as predictions, or self-citation load-bearing premises appear in the provided abstract or description. The approach is framed as a practical test-time augmentation without multimodal fine-tuning, and reported improvements are external to the method's internal definitions. This matches the default expectation for non-derivational papers.
Axiom & Free-Parameter Ledger
read the original abstract
Commonsense reasoning often requires both textual and visual knowledge, yet Large Language Models (LLMs) trained solely on text lack visual grounding (e.g., "what color is an emperor penguin's belly?"). Visual Language Models (VLMs) perform better on visually grounded tasks but face two limitations: (i) often reduced performance on text-only commonsense reasoning compared to text-trained LLMs, and (ii) adapting newly released LLMs to vision input typically requires costly multimodal training. An alternative augments LLMs with test-time visual signals, improving visual commonsense without harming textual reasoning, but prior designs often rely on early fusion and a single image, which can be suboptimal. We propose a late multi-image fusion method: multiple images are generated from the text prompt with a lightweight parallel sampling, and their prediction probabilities are combined with those of a text-only LLM through a late-fusion layer that integrates projected visual features just before the final prediction. Across visual commonsense and NLP benchmarks, our method significantly outperforms augmented LLMs on visual reasoning, matches VLMs on vision-based tasks, and, when applied to strong LLMs such as LLaMA 3, also improves NLP performance while adding only modest test-time overhead. Project page is available at: https://guyyariv.github.io/LaMI.
Figures


Reference graph
Works this paper leans on
-
[1]
Can language models understand physical concepts? arXiv preprint arXiv:2305.14057, 2023b
Lei Li, Jingjing Xu, Qingxiu Dong, Ce Zheng, Qi Liu, Lingpeng Kong, and Xu Sun. Can language models understand physical concepts? arXiv preprint arXiv:2305.14057, 2023b. Woojeong Jin, Tejas Srinivasan, Jesse Thomason, and Xiang Ren. Winoviz: Probing visual properties of objects under different states,
-
[2]
Does vision-and-language pretraining improve lexical grounding? arXiv preprint arXiv:2109.10246,
Tian Yun, Chen Sun, and Ellie Pavlick. Does vision-and-language pretraining improve lexical grounding? arXiv preprint arXiv:2109.10246,
-
[3]
The Falcon Series of Open Language Models
Ebtesam Almazrouei, Hamza Alobeidli, Abdulaziz Alshamsi, Alessandro Cappelli, Ruxandra Cojo- caru, Mérouane Debbah, Étienne Goffinet, Daniel Hesslow, Julien Launay, Quentin Malartic, et al. The falcon series of open language models. arXiv preprint arXiv:2311.16867,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
In: Proceedings of the 3rd Workshop on Trustworthy Natural Language Process- ing (TrustNLP 2023)
Association for Computational Linguistics. doi: 10.18653/v1/2023.trustnlp-1.28. URL https: //aclanthology.org/2023.trustnlp-1.28. Ranjay Krishna, Yuke Zhu, Oliver Groth, Justin Johnson, Kenji Hata, Joshua Kravitz, Stephanie Chen, Yannis Kalantidis, Li-Jia Li, David A. Shamma, Michael S. Bernstein, and Fei-Fei Li. Visual genome: Connecting language and vis...
-
[5]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian error linear units (gelus). arXiv preprint arXiv:1606.08415,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Imagenet: A large-scale hier- archical image database
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hier- archical image database. In 2009 IEEE Conference on Computer Vision and Pattern Recognition , pages 248–255,
work page 2009
-
[7]
ImageNet: A Large- Scale Hierarchical Image Database
doi: 10.1109/CVPR.2009.5206848. Yonatan Bisk, Rowan Zellers, Ronan Le Bras, Jianfeng Gao, and Yejin Choi. Piqa: Reasoning about physical commonsense in natural language,
-
[8]
SocialIQA: Commonsense Reasoning about Social Interactions
Maarten Sap, Hannah Rashkin, Derek Chen, Ronan LeBras, and Yejin Choi. Socialiqa: Commonsense reasoning about social interactions. arXiv preprint arXiv:1904.09728,
work page internal anchor Pith review Pith/arXiv arXiv 1904
-
[9]
HellaSwag: Can a Machine Really Finish Your Sentence?
Rowan Zellers, Ari Holtzman, Yonatan Bisk, Ali Farhadi, and Yejin Choi. Hellaswag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[10]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv preprint arXiv:1803.05457,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering
12 Todor Mihaylov, Peter Clark, Tushar Khot, and Ashish Sabharwal. Can a suit of armor conduct electricity? a new dataset for open book question answering. arXiv preprint arXiv:1809.02789,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge
Alon Talmor, Jonathan Herzig, Nicholas Lourie, and Jonathan Berant. Commonsenseqa: A question answering challenge targeting commonsense knowledge. arXiv preprint arXiv:1811.00937,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
Vered Shwartz, Peter West, Ronan Le Bras, Chandra Bhagavatula, and Yejin Choi. Unsupervised commonsense question answering with self-talk. arXiv preprint arXiv:2004.05483,
-
[14]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions
Christopher Clark, Kenton Lee, Ming-Wei Chang, Tom Kwiatkowski, Michael Collins, and Kristina Toutanova. Boolq: Exploring the surprising difficulty of natural yes/no questions. arXiv preprint arXiv:1905.10044,
work page internal anchor Pith review Pith/arXiv arXiv 1905
-
[15]
Know What You Don't Know: Unanswerable Questions for SQuAD
Pranav Rajpurkar, Robin Jia, and Percy Liang. Know what you don’t know: Unanswerable questions for squad. arXiv preprint arXiv:1806.03822,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
QuAC : Question Answering in Context
Eunsol Choi, He He, Mohit Iyyer, Mark Yatskar, Wen-tau Yih, Yejin Choi, Percy Liang, and Luke Zettlemoyer. Quac: Question answering in context. arXiv preprint arXiv:1808.07036,
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
The Pile: An 800GB Dataset of Diverse Text for Language Modeling
Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling. arXiv preprint arXiv:2101.00027,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
As our method uses these components, it inherits their associated issues
13 A Broader Impact The broader impact of our method has both potential risks and benefits associated with the use of LLMs, visual encoders and text-to-image generators. As our method uses these components, it inherits their associated issues. The following are points that should be considered: • Malicious input. This can be both at the text-to-image mode...
work page 2023
-
[19]
The effect of the image generation model
Although DINOv2 provides comparable or superior performance to the baseline methods, results suggest that CLIP still outperforms DINOv2, particularly in tasks requiring nuanced visual comprehension, validating our choice of CLIP for enhanced multimodal learning. The effect of the image generation model. To explore the impact of image fidelity on reasoning...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.