ProfBench: Multi-Domain Rubrics requiring Professional Knowledge to Answer and Judge
Pith reviewed 2026-05-21 19:31 UTC · model grok-4.3
The pith
ProfBench creates expert rubrics across physics, chemistry, finance and consulting that expose large gaps in how current LLMs handle professional documents and reports.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
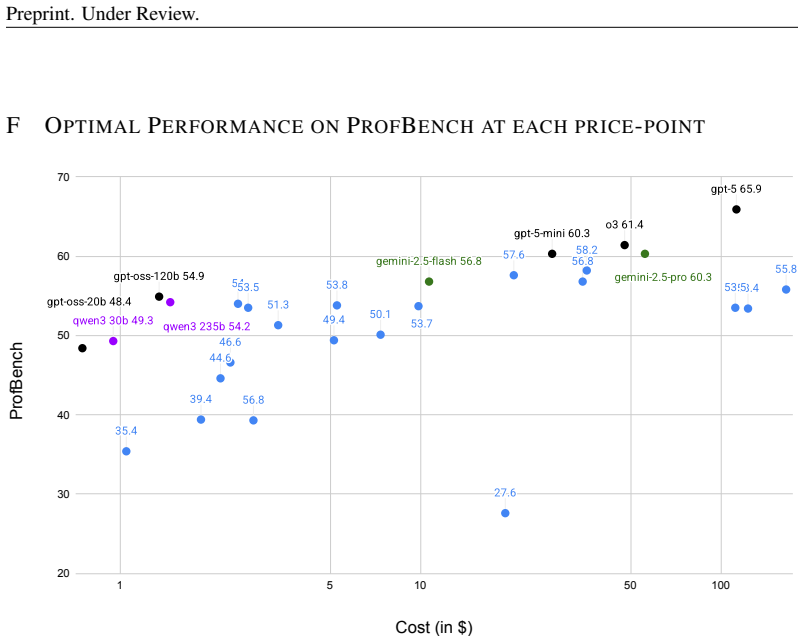
ProfBench supplies over 7000 human-expert-scored response-criterion pairs in Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA domains, then supplies affordable LLM judges that mitigate self-enhancement bias; when these judges are run on current models the highest score is 65.9 percent, proprietary systems outperform open-weight ones, and extended thinking improves results on the hardest items.
What carries the argument
ProfBench rubrics consisting of response-criterion pairs that require domain-specific synthesis and are scored first by human experts then by the authors' bias-mitigated LLM judges.
If this is right
- Models will need stronger mechanisms for long-context synthesis and professional judgment before they can be trusted on report-style tasks.
- Extended chain-of-thought or thinking budgets become a measurable lever for closing the gap on complex professional queries.
- Open-weight models will continue to trail proprietary ones on these rubrics until training data or alignment techniques close the observed disparity.
- Evaluation budgets can drop dramatically once reliable LLM judges replace repeated human review.
- Future benchmarks in additional professional fields can reuse the same rubric-plus-LLM-judge pattern.
Where Pith is reading between the lines
- If the benchmark holds, organizations that rely on LLMs for research summaries or client reports will need human oversight for longer than current accuracy numbers suggest.
- The rubric format could be adapted to measure whether models can maintain consistency when updating reports after new documents arrive.
- Performance gaps between model families may widen further when the rubrics are expanded to fields that require quantitative modeling or regulatory reasoning.
- The cost reduction achieved by the LLM judges makes repeated evaluation during model development feasible for smaller research groups.
Load-bearing premise
The constructed LLM judges can stand in for human experts across these four domains without introducing large distortions from self-enhancement or domain mismatch.
What would settle it
A side-by-side study in which the same set of model outputs is scored both by the authors' LLM judges and by fresh human experts from the same four fields, checking whether agreement rates stay above 80 percent on average.
Figures




read the original abstract
Evaluating progress in large language models (LLMs) is often constrained by the challenge of verifying responses, limiting assessments to tasks like mathematics, programming, and short-form question-answering. However, many real-world applications require evaluating LLMs in processing professional documents, synthesizing information, and generating comprehensive reports in response to user queries. We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias and reducing the cost of evaluation by 2-3 orders of magnitude, to make it fair and accessible to the broader community. Our findings reveal that ProfBench poses significant challenges even for state-of-the-art LLMs, with top-performing models like GPT-5-high achieving only 65.9% overall performance. Furthermore, we identify notable performance disparities between proprietary and open-weight models and provide insights into the role that extended thinking plays in addressing complex, professional-domain tasks. Data: https://huggingface.co/datasets/nvidia/ProfBench and Code: https://github.com/NVlabs/ProfBench and Leaderboard: https://huggingface.co/spaces/nvidia/ProfBench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. ProfBench introduces a benchmark consisting of over 7000 response-criterion pairs in Physics, Chemistry, Finance, and Consulting domains, with rubrics created by human experts with professional knowledge. The authors develop LLM-Judges to score model responses against these rubrics, claiming to mitigate self-enhancement bias and reduce evaluation costs by 2-3 orders of magnitude. The central empirical claim is that even state-of-the-art models such as GPT-5-high achieve only 65.9% overall performance, with additional findings on proprietary vs. open-weight model gaps and the role of extended thinking. The dataset, code, and leaderboard are released publicly.
Significance. If the LLM-Judges are shown to be reliable proxies for human expert judgment, ProfBench would address a clear gap in current LLM evaluation by targeting professional document processing and report synthesis. The public data release, code, and leaderboard are explicit strengths that enable reproducibility and community use. The work could support more realistic assessment of LLMs on complex, domain-specific tasks beyond mathematics and short-form QA.
major comments (2)
- [LLM-Judge Construction and Validation] The abstract and methods description state that LLM-Judges are constructed to evaluate the rubrics while mitigating self-enhancement bias. No domain-specific agreement statistics (Pearson r, Cohen's kappa, or exact-match rate) are reported between LLM-Judge scores and human-expert labels on the >7000 response-criterion pairs. Because the headline 65.9% result for GPT-5-high and the claim that ProfBench poses significant challenges are produced by these judges rather than direct human scoring, the absence of quantified validation is load-bearing for the central performance claims.
- [Results] Results section: the overall 65.9% figure and model comparisons should be accompanied by domain-level breakdowns and any available inter-judge or judge-human agreement numbers; without them the disparity claims between proprietary and open-weight models rest on unverified judge reliability.
minor comments (2)
- [Abstract] Abstract: the sentence 'response-criterion pairs as evaluated by human-experts' is ambiguous about whether humans scored the model responses or only created the rubrics; a single clarifying clause would improve precision.
- [Methods] The cost-reduction claim of 2-3 orders of magnitude is stated without a concrete baseline comparison (e.g., human-expert hours vs. LLM-Judge API cost); adding this detail would strengthen the accessibility argument.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which highlight important aspects of validation and presentation. We address each major comment below and have revised the manuscript to incorporate the requested details on LLM-Judge reliability and domain-level results.
read point-by-point responses
-
Referee: [LLM-Judge Construction and Validation] The abstract and methods description state that LLM-Judges are constructed to evaluate the rubrics while mitigating self-enhancement bias. No domain-specific agreement statistics (Pearson r, Cohen's kappa, or exact-match rate) are reported between LLM-Judge scores and human-expert labels on the >7000 response-criterion pairs. Because the headline 65.9% result for GPT-5-high and the claim that ProfBench poses significant challenges are produced by these judges rather than direct human scoring, the absence of quantified validation is load-bearing for the central performance claims.
Authors: We agree that explicit domain-specific agreement statistics are necessary to substantiate the reliability of the LLM-Judges and the resulting performance claims. The manuscript describes the LLM-Judge construction process, including the use of separate models to reduce self-enhancement bias, but does not report quantitative agreement metrics against human experts. In the revised manuscript we will add a new validation subsection that reports Pearson r, Cohen's kappa, and exact-match rates computed on a representative sample of response-criterion pairs for each domain. These metrics will directly support the 65.9% headline result and the broader claim that ProfBench presents significant challenges. revision: yes
-
Referee: [Results] Results section: the overall 65.9% figure and model comparisons should be accompanied by domain-level breakdowns and any available inter-judge or judge-human agreement numbers; without them the disparity claims between proprietary and open-weight models rest on unverified judge reliability.
Authors: We concur that domain-level breakdowns and agreement statistics would strengthen the presentation of results and the interpretation of proprietary versus open-weight model gaps. The revised Results section will include per-domain performance tables for all models evaluated, together with the judge-human agreement numbers referenced in the response to the first comment. This addition will provide a clearer empirical foundation for the reported disparities and the role of extended thinking. revision: yes
Circularity Check
No significant circularity; evaluation chain grounded in human-expert labels
full rationale
The paper constructs ProfBench from over 7000 response-criterion pairs directly evaluated by human experts with domain-specific professional knowledge (Physics PhD, Chemistry PhD, Finance/Consulting MBA). LLM-Judges are subsequently developed to approximate these human judgments at lower cost while explicitly mitigating self-enhancement bias. Reported model performances (e.g., GPT-5-high at 65.9%) are obtained by applying the judges to model outputs on the fixed benchmark. No derivation step reduces by construction to its own inputs: there are no self-definitional equations, fitted parameters renamed as predictions, load-bearing self-citations, or ansatzes smuggled via prior work. The chain remains self-contained against the external human-expert benchmark and does not rely on circular reductions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human experts holding Physics PhD, Chemistry PhD, Finance MBA, or Consulting MBA degrees produce reliable and representative rubrics for evaluating LLM responses on professional tasks.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce ProfBench: a set of over 7000 response-criterion pairs as evaluated by human-experts with professional knowledge across Physics PhD, Chemistry PhD, Finance MBA and Consulting MBA. We build robust and affordable LLM-Judges to evaluate ProfBench rubrics, by mitigating self-enhancement bias...
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Agreement with Human Annotations... Macro-F1 based on the ground-truth human-labeled criterion-fulfillment... Bias-Index... Overall performance is Macro-F1 minus Bias-Index.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 5 Pith papers
-
SCICONVBENCH: Benchmarking LLMs on Multi-Turn Clarification for Task Formulation in Computational Science
SCICONVBENCH is a new benchmark evaluating LLMs on multi-turn disambiguation and inconsistency resolution for task formulation in computational science, with frontier models reaching only 52.7% success on fluid mechan...
-
Evaluating Deep Research Agents on Expert Consulting Work: A Benchmark with Verifiers, Rubrics, and Cognitive Traps
New benchmark evaluates three frontier deep research agents on 42 SME prompts with verifiers and rubrics, reporting low acceptance rates of 9.5-21.4% and agent-specific failure modes.
-
Visual Preference Optimization with Rubric Rewards
rDPO uses offline-built rubrics to generate on-policy preference data for DPO, raising benchmark scores in visual tasks over outcome-based filtering and style baselines.
-
Reward Hacking in Rubric-Based Reinforcement Learning
Rubric-based RL verifiers can be gamed via partial criterion satisfaction and implicit-to-explicit tricks, yielding proxy gains that do not improve quality under rubric-free judges; stronger verifiers reduce but do no...
-
BankerToolBench: Evaluating AI Agents in End-to-End Investment Banking Workflows
BankerToolBench is a new open benchmark of end-to-end investment banking workflows developed with 502 bankers; even the best tested model (GPT-5.4) fails nearly half the expert rubric criteria and produces zero client...
Reference graph
Works this paper leans on
-
[1]
Llama-nemotron: Efficient reasoning models,
URLhttps://arxiv.org/abs/2505.00949. Samuel R. Bowman, Gabor Angeli, Christopher Potts, and Christopher D. Manning. A large annotated corpus for learning natural language inference, 2015. URLhttps://arxiv.org/abs/1508. 05326. DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi,...
-
[2]
URLhttps://arxiv.org/abs/2508.13180. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024. URL https://arxiv.org/abs/2403. 07974. JazzCore. Pdfkit.https://pypi.org/project/pdfkit/...
-
[3]
Tulu 3: Pushing Frontiers in Open Language Model Post-Training
URLhttps://openreview.net/forum?id=UHPnqSTBPO. Nathan Lambert, Jacob Morrison, Valentina Pyatkin, Shengyi Huang, Hamish Ivison, Faeze Brahman, Lester James V . Miranda, Alisa Liu, Nouha Dziri, Shane Lyu, Yuling Gu, Saumya Malik, Victoria Graf, Jena D. Hwang, Jiangjiang Yang, Ronan Le Bras, Oyvind Tafjord, Chris Wilhelm, Luca Soldaini, Noah A. Smith, Yizho...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
URLhttps://arxiv.org/abs/2311.12022. SearXNG. Searxng.https://github.com/searxng/searxng, 2025. Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. Paperbench: Evaluating ai’s ability to replicate ai research...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Calculate the volume of NaOH titrant required to reach the point where the two conjugate bases have equal concentrations
-
[6]
Calculate the concentrations of the acids and their conjugate bases at the point referenced in part 1
-
[7]
Calculate the concentration of hydronium ions and the pH of the analyte at the point referenced in part 1
-
[8]
Calculate the volume of NaOH titrant required to reach the point where the pH of the analyte is 7.0
-
[9]
Calculate the concentrations of the acids and their conjugate bases at the point referenced in part 4
-
[10]
Calculate the volume of NaOH titrant required to neutralize both acids
-
[11]
Calculate the concentrations of the acids and their conjugate bases at the point referenced in part 6
-
[12]
Calculate the concentration of hydronium ion and the pH of the analyte at the point referenced in part 6. Example Extraction Rubric: Determines the volume of NaOH titrant required to reach the point where the pH of the analyte is 7.0 as 0.11938 ± 0.001 L Example Reasoning Rubric: Determines the pH of the analyte at the point at which both acids are neutra...
-
[13]
Delivery: Pick one (i) On-Campus Partner (classes hosted at partner school premises), (ii) Learning Center (dedicated provider-run teaching location), or (iii) Hybrid: Kit + Video (take- home kit plus guided videos). 3. Pedagogy: Pick one (i) Teacher-Centered (teacher leads instruction; students follow), (ii) Project-Based (students build projects to lear...
-
[14]
Venue rental offers: Harrow is offering weekend windows at their standard base rental rate for the first hour, then HK$150/h thereafter, +10% weekend surcharge. DSC is offering weekday windows at their standard base rental rate for two hours, + HK$500 tech, + HK$200 cleaning per booking. Calculate the total venue rental cost per school, assuming the Clien...
-
[15]
France: 1 Consulting MBA:We generally require annotators to have had 2 years of work experience at McKinsey, Boston Consulting Group, Bain & Company, Deloitte, PricewaterhouseCoopers, Ernst and Young or KPMG. Alternatively, they could have 4 years of experience at another consulting firm. These work experience includes those prior to the completion of the...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.