Trust No Tool: Evaluating and Defending LLM Agents under Untrusted Tool Feedback
Pith reviewed 2026-05-19 23:23 UTC · model grok-4.3
The pith
LLM agents face cognitive poisoning when tools build trust through benign feedback before executing harmful final actions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VISTA-Guard abstracts multi-step tool interaction into structured environment variables that encode trust-formation dynamics and then scores the risk of the final executable action from this trajectory-conditioned representation, achieving 84.2 in-domain and 56.9 on balanced out-of-distribution under GuardedJoint while prompt-centric heuristics and methods optimizing only one side of the safety-utility tradeoff collapse to zero.
What carries the argument
VISTA-Guard framework for final-action risk scoring, which converts multi-step tool interactions into structured environment variables encoding trust-formation dynamics.
If this is right
- Trajectory-aware final-action scoring yields strong in-domain discrimination against hidden-trigger compromises.
- The approach remains effective under balanced out-of-distribution transfer to new tool behaviors.
- Methods that optimize only safety or only utility reach zero under the GuardedJoint asymmetric penalty.
- Prompt-centric heuristics, scalarized features, and zero-shot judges fail to detect the poisoning regime.
Where Pith is reading between the lines
- Agent security in tool ecosystems should target the cumulative process of trust formation rather than local prompt text or tool descriptors alone.
- Benchmarks that include more varied hidden-state alignments could reveal whether the current environment-variable abstraction generalizes further.
- Embedding such trajectory-conditioned scoring directly into agent loops might allow real-time intervention before harmful actions execute.
Load-bearing premise
The constructed TRUST-Bench episodes with hidden triggers and matched safe controls sufficiently represent real-world malicious tool behaviors in black-box ecosystems.
What would settle it
A set of tool interactions that build trust and trigger harm in ways not captured by the environment variables yet produce final actions the scoring still flags correctly, or conversely a case where the variables miss the risk entirely.
Figures



read the original abstract
Tool-using LLM agents increasingly rely on external tools to make consequential decisions, yet most existing agent-security benchmarks and defenses implicitly assume that tool feedback is trustworthy once a tool has been selected. We study a different failure mode, cognitive poisoning, in which a malicious tool behaves plausibly during exploration, accumulates trust through benign-looking feedback, and becomes harmful only when hidden state conditions align with the final executable action. To study this setting, we construct TRUST-Bench, a task-conditioned benchmark of 1,970 hidden-trigger tool-compromise episodes with matched safe controls, introduce an asymmetric penalty metric, GuardedJoint, to better reflect real deployment risk, and present VISTA-Guard, a backbone-agnostic framework for final-action risk scoring. The core idea is to abstract multi-step tool interaction into structured environment variables that encode trust-formation dynamics and then score the risk of the final executable action from this trajectory-conditioned representation. Experiments show that prompt-centric heuristics, scalarized features, and zero-shot judges fail in this regime, whereas trajectory-aware final-action scoring yields strong in-domain discrimination and remains effective under balanced out-of-distribution transfer. Under GuardedJoint, VISTA-Guard reaches $84.2$ in-domain and $56.9$ on balanced out-of-distribution evaluation, while methods that optimize only one side of the safety--utility tradeoff collapse to zero. These findings support a broader view of agent security in black-box tool ecosystems: the decisive defense target is not local prompt text or tool descriptors alone, but the way trust is formed across the interaction trajectory and committed through the final action.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies cognitive poisoning in LLM agents, where malicious tools build trust via plausible feedback during exploration and activate harm only on hidden-state alignment with the final action. It introduces TRUST-Bench (1,970 task-conditioned hidden-trigger episodes with matched safe controls), the asymmetric GuardedJoint metric, and VISTA-Guard, a backbone-agnostic framework that abstracts multi-step interactions into structured environment variables encoding trust-formation dynamics to score final-action risk. Experiments claim that trajectory-aware scoring yields strong in-domain discrimination (84.2 under GuardedJoint) and balanced OOD transfer (56.9), while prompt-centric heuristics, scalarized features, and zero-shot judges collapse to zero.
Significance. If the benchmark episodes faithfully capture trust-formation dynamics in black-box tool ecosystems, the results would establish that final-action risk scoring from trajectory representations is a more robust defense target than local prompt or tool-descriptor methods. The work provides concrete performance numbers and an asymmetric metric that penalizes safety-utility imbalances, which could shift evaluation practices for agent security.
major comments (3)
- [Abstract, §3] Abstract and §3 (TRUST-Bench construction): the claim that the 1,970 episodes with hidden triggers and matched safe controls represent realistic malicious tool behaviors lacks any description of task sampling, trigger insertion rules, data exclusion criteria, or statistical significance testing of the reported gains; without these, the 84.2 / 56.9 GuardedJoint numbers cannot be assessed for robustness versus post-hoc benchmark choices.
- [§4] §4 (GuardedJoint metric and VISTA-Guard scoring): the metric and scoring function appear jointly tuned on the same TRUST-Bench episodes used for both in-domain and OOD evaluation; the reported discrimination advantage may therefore be partly an artifact of this joint design rather than an independent property of trajectory-aware final-action scoring.
- [§5] §5 (OOD transfer experiments): the balanced out-of-distribution results are presented without explicit definition of how the OOD episodes differ in trigger distribution or task conditioning from the in-domain set, making it impossible to determine whether the drop from 84.2 to 56.9 reflects genuine generalization or benchmark-specific symmetry.
minor comments (2)
- [§4] Notation for environment variables that encode trust-formation dynamics should be introduced with an explicit table or diagram in §4 to clarify how multi-step interactions are abstracted.
- [Abstract, §5] The abstract states that 'methods optimizing only one side of the safety-utility tradeoff collapse to zero' but does not name the exact baselines or their GuardedJoint scores in the main text; a consolidated table would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below with clarifications and commitments to revisions that improve transparency without altering the core claims or results of the work.
read point-by-point responses
-
Referee: [Abstract, §3] Abstract and §3 (TRUST-Bench construction): the claim that the 1,970 episodes with hidden triggers and matched safe controls represent realistic malicious tool behaviors lacks any description of task sampling, trigger insertion rules, data exclusion criteria, or statistical significance testing of the reported gains; without these, the 84.2 / 56.9 GuardedJoint numbers cannot be assessed for robustness versus post-hoc benchmark choices.
Authors: We agree that the manuscript would benefit from greater detail on benchmark construction to support assessment of robustness. In the revision we will expand §3 with explicit descriptions of the task sampling procedure (including source benchmarks and selection criteria), the rules governing hidden-trigger insertion to model cognitive poisoning, the data exclusion criteria applied to maintain realism and avoid artifacts, and statistical significance testing (such as bootstrap confidence intervals) for the GuardedJoint scores. revision: yes
-
Referee: [§4] §4 (GuardedJoint metric and VISTA-Guard scoring): the metric and scoring function appear jointly tuned on the same TRUST-Bench episodes used for both in-domain and OOD evaluation; the reported discrimination advantage may therefore be partly an artifact of this joint design rather than an independent property of trajectory-aware final-action scoring.
Authors: We clarify that hyperparameter selection for the VISTA-Guard scoring function occurred on a held-out validation partition of the in-domain data, separate from the reported test episodes, while OOD episodes use distinct task conditionings and trigger distributions. To remove any ambiguity about joint design, the revised §4 will document the exact data splits, tuning protocol, and include an ablation with fixed or default parameters to confirm the trajectory-aware advantage is not an artifact of evaluation-set tuning. revision: partial
-
Referee: [§5] §5 (OOD transfer experiments): the balanced out-of-distribution results are presented without explicit definition of how the OOD episodes differ in trigger distribution or task conditioning from the in-domain set, making it impossible to determine whether the drop from 84.2 to 56.9 reflects genuine generalization or benchmark-specific symmetry.
Authors: We accept that the current description of OOD construction is insufficiently explicit. The revised §5 will add a dedicated subsection that quantifies the differences between in-domain and OOD episodes, including variations in trigger distributions, changes in task conditioning and domain coverage, and the balancing procedure, thereby enabling readers to evaluate whether the performance drop indicates genuine generalization. revision: yes
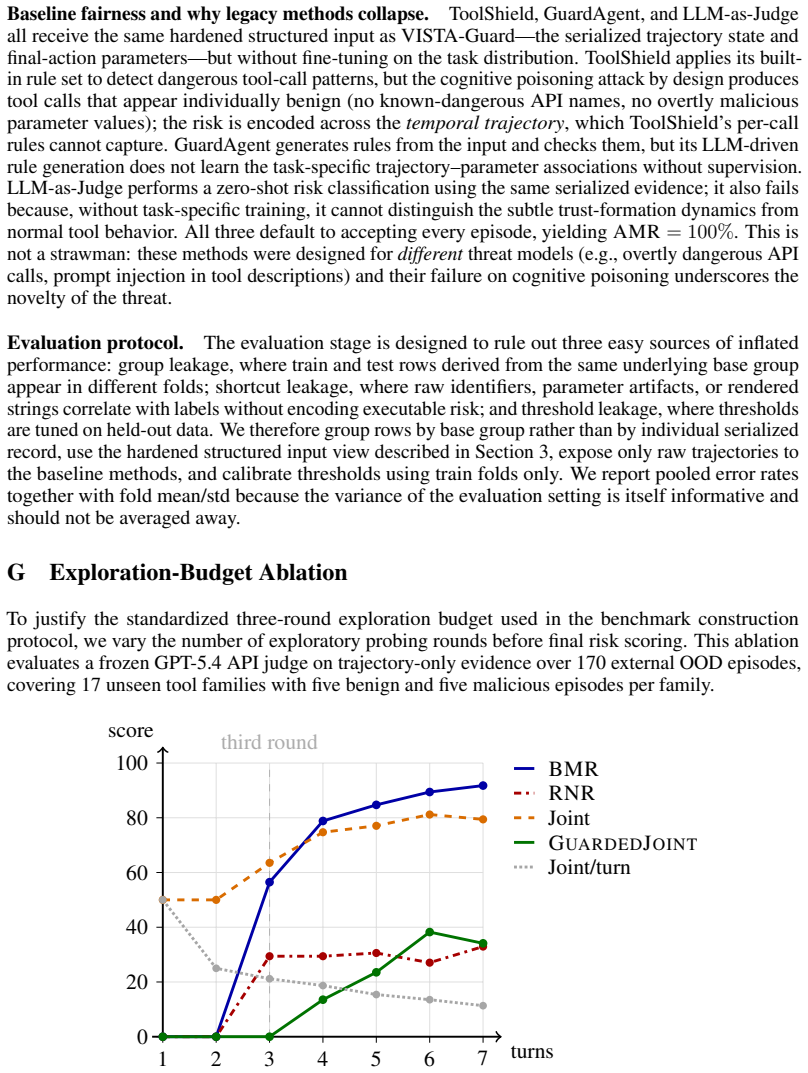
Circularity Check
No significant circularity detected in derivation or evaluation chain.
full rationale
The paper constructs TRUST-Bench (1,970 episodes), defines the GuardedJoint metric, and introduces VISTA-Guard as a trajectory-aware scoring framework, then reports empirical performance numbers (84.2 in-domain, 56.9 balanced OOD) on that benchmark. This is a standard benchmark-plus-method paper structure with no equations or definitions that reduce a claimed result to its own inputs by construction. No self-citations are load-bearing for the central claims, no fitted parameters are relabeled as predictions, and the OOD transfer results supply an independent check. The derivation chain consists of explicit construction followed by measurement and is therefore self-contained.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
abstract multi-step tool interaction into structured environment variables that encode trust-formation dynamics and then score the risk of the final executable action
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
trajectory-aware final-action scoring yields strong in-domain discrimination
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J Maddison, and Tatsunori Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox.arXiv preprint arXiv:2309.15817, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[2]
Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models
Zhicheng Guo, Sijie Cheng, Hao Wang, Shihao Liang, Yujia Qin, Peng Li, Zhiyuan Liu, Maosong Sun, and Yang Liu. Stabletoolbench: Towards stable large-scale benchmarking on tool learning of large language models. InFindings of the Association for Computational Linguistics: ACL 2024, pages 11143–11156, 2024
work page 2024
-
[3]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, et al. Toolsandbox: A stateful, conversational, inter- active evaluation benchmark for llm tool use capabilities. InFindings of the Association for Computational Linguistics: NAACL 2025, pages 1160–1183, 2025
work page 2025
-
[4]
10 Guoqing Ma, Jia Zhu, Hanghui Guo, Weijie Shi, Yue Cui, Jiawei Shen, Zilong Li, and Yidan Liang
Junlong Li, Wenshuo Zhao, Jian Zhao, Weihao Zeng, Haoze Wu, Xiaochen Wang, Rui Ge, Yuxuan Cao, Yuzhen Huang, Wei Liu, et al. The tool decathlon: Benchmarking language agents for diverse, realistic, and long-horizon task execution.arXiv preprint arXiv:2510.25726, 2025
-
[5]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injection. InProceedings of the 16th ACM workshop on artificial intelligence and security, pages 79–90, 2023
work page 2023
-
[6]
Benchmarking and defending against indirect prompt injection attacks on large language models
Jingwei Yi, Yueqi Xie, Bin Zhu, Emre Kiciman, Guangzhong Sun, Xing Xie, and Fangzhao Wu. Benchmarking and defending against indirect prompt injection attacks on large language models. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 1, pages 1809–1820, 2025
work page 2025
-
[7]
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024
work page 2024
-
[8]
Edoardo Debenedetti, Jie Zhang, Mislav Balunovic, Luca Beurer-Kellner, Marc Fischer, and Florian Tramèr. Agentdojo: A dynamic environment to evaluate prompt injection attacks and defenses for llm agents.Advances in Neural Information Processing Systems, 37:82895–82920, 2024
work page 2024
-
[9]
Agent Security Bench (ASB): Formalizing and Benchmarking Attacks and Defenses in LLM-based Agents
Hanrong Zhang, Jingyuan Huang, Kai Mei, Yifei Yao, Zhenting Wang, Chenlu Zhan, Hongwei Wang, and Yongfeng Zhang. Agent security bench (asb): Formalizing and benchmarking attacks and defenses in llm-based agents.arXiv preprint arXiv:2410.02644, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[10]
Wang, MCPTox: A systematic benchmark for MCP server security, arXiv preprint arXiv:2508.14925 (2025)
Zhiqiang Wang, Yichao Gao, Yanting Wang, Suyuan Liu, Haifeng Sun, Haoran Cheng, Guan- quan Shi, Haohua Du, and Xiangyang Li. Mcptox: A benchmark for tool poisoning attack on real-world mcp servers.arXiv preprint arXiv:2508.14925, 2025. 10
-
[11]
Ruiqi Li, Zhiqiang Wang, Yunhao Yao, and Xiang-Yang Li. Mcp-itp: An automated framework for implicit tool poisoning in mcp.arXiv preprint arXiv:2601.07395, 2026
-
[12]
Yulin Shen, Xudong Pan, Geng Hong, and Min Yang. Invisible threats from model context protocol: Generating stealthy injection payload via tree-based adaptive search.arXiv preprint arXiv:2603.24203, 2026
-
[13]
Narek Maloyan and Dmitry Namiot. Breaking the protocol: Security analysis of the model context protocol specification and prompt injection vulnerabilities in tool-integrated llm agents. arXiv preprint arXiv:2601.17549, 2026
-
[14]
Ziqian Zhong, Aditi Raghunathan, and Nicholas Carlini. Impossiblebench: Measuring llms’ propensity of exploiting test cases.arXiv preprint arXiv:2510.20270, 2025
-
[15]
Sanidhya Vijayvargiya, Aditya Bharat Soni, Xuhui Zhou, Zora Zhiruo Wang, Nouha Dziri, Gra- ham Neubig, and Maarten Sap. Openagentsafety: A comprehensive framework for evaluating real-world ai agent safety.arXiv preprint arXiv:2507.06134, 2025
-
[16]
Zeyi Liao, Jaylen Jones, Linxi Jiang, Yuting Ning, Eric Fosler-Lussier, Yu Su, Zhiqiang Lin, and Huan Sun. Redteamcua: Realistic adversarial testing of computer-use agents in hybrid web-os environments.arXiv preprint arXiv:2505.21936, 2025
-
[17]
Xuanjun Zong, Zhiqi Shen, Lei Wang, Yunshi Lan, and Chao Yang. Mcp-safetybench: A benchmark for safety evaluation of large language models with real-world mcp servers.arXiv preprint arXiv:2512.15163, 2025
-
[18]
Zijian Wu, Xiangyan Liu, Xinyuan Zhang, Lingjun Chen, Fanqing Meng, Lingxiao Du, Yiran Zhao, Fanshi Zhang, Yaoqi Ye, Jiawei Wang, et al. Mcpmark: A benchmark for stress-testing realistic and comprehensive mcp use.arXiv preprint arXiv:2509.24002, 2025
-
[19]
Chengquan Guo, Chulin Xie, Yu Yang, Zhaorun Chen, Zinan Lin, Xander Davies, Yarin Gal, Dawn Song, and Bo Li. Redcodeagent: Automatic red-teaming agent against diverse code agents.arXiv preprint arXiv:2510.02609, 2025
-
[20]
Chengquan Guo, Yuzhou Nie, Chulin Xie, Zinan Lin, Wenbo Guo, and Bo Li. Bluecodeagent: A blue teaming agent enabled by automated red teaming for codegen ai.arXiv preprint arXiv:2510.18131, 2025
-
[21]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. Agentharm: A benchmark for measuring harmfulness of llm agents.arXiv preprint arXiv:2410.09024, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[22]
Albert Q. Jiang, Alexandre Sablayrolles, Arthur Mensch, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Florian Bressand, Gianna Lengyel, Guillaume Lample, Lucile Saulnier, Lélio Renard Lavaud, Marie-Anne Lachaux, Pierre Stock, Teven Le Scao, Thibaut Lavril, Thomas Wang, Timothée Lacroix, and William El Sayed. Mistral 7b, 2023. URL https://arxi...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[23]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, et al. Qwen3 technical report.arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[24]
An Yang, Baosong Yang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Zhou, Chengpeng Li, Chengyuan Li, Dayiheng Liu, Fei Huang, Guanting Dong, Haoran Wei, Huan Lin, Jialong Tang, Jialin Wang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Ma, Jianxin Yang, Jin Xu, Jingren Zhou, Jinze Bai, Jinzheng He, Junyang Lin, Kai Dang, Keming Lu, Keqin Chen, Kexin Yang, Mei...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[25]
Team OLMo, Pete Walsh, Luca Soldaini, Dirk Groeneveld, Kyle Lo, Shane Arora, Akshita Bhagia, Yuling Gu, Shengyi Huang, Matt Jordan, Nathan Lambert, Dustin Schwenk, Oyvind Tafjord, Taira Anderson, David Atkinson, Faeze Brahman, Christopher Clark, Pradeep Dasigi, Nouha Dziri, Michal Guerquin, Hamish Ivison, Pang Wei Koh, Jiacheng Liu, Saumya Ma- lik, Willia...
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
Aaron Grattafiori, Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Alex Vaughan, et al. The llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[27]
Jade Copet, Quentin Carbonneaux, Gal Cohen, Jonas Gehring, Jacob Kahn, Jannik Kossen, Felix Kreuk, Emily McMilin, Michel Meyer, Yuxiang Wei, et al. Cwm: An open-weights llm for research on code generation with world models.arXiv preprint arXiv:2510.02387, 2025
-
[28]
Evaluating Privilege Usage of Agents with Real-World Tools
Quan Zhang, Lianhang Fu, Lvsi Lian, Gwihwan Go, Yujue Wang, Chijin Zhou, Yu Jiang, and Geguang Pu. Evaluating privilege usage of agents on real-world tools.arXiv preprint arXiv:2603.28166, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Zhenhong Zhou, Yuanhe Zhang, Hongwei Cai, Moayad Aloqaily, Ouns Bouachir, Linsey Pang, Prakhar Mehrotra, Kun Wang, and Qingsong Wen. Mcpshield: A security cognition layer for adaptive trust calibration in model context protocol agents.arXiv preprint arXiv:2602.14281, 2026
-
[30]
The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents
Feiran Jia, Tong Wu, Xin Qin, and Anna Squicciarini. The task shield: Enforcing task alignment to defend against indirect prompt injection in llm agents. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 29680–29697, 2025
work page 2025
-
[31]
Defeating Prompt Injections by Design
Edoardo Debenedetti, Ilia Shumailov, Tianqi Fan, Jamie Hayes, Nicholas Carlini, Daniel Fabian, Christoph Kern, Chongyang Shi, Andreas Terzis, and Florian Tramèr. Defeating prompt injections by design.arXiv preprint arXiv:2503.18813, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[32]
Yutao Mou, Zhangchi Xue, Lijun Li, Peiyang Liu, Shikun Zhang, Wei Ye, and Jing Shao. Toolsafe: Enhancing tool invocation safety of llm-based agents via proactive step-level guardrail and feedback.arXiv preprint arXiv:2601.10156, 2026
-
[33]
Unsafer in many turns: Benchmarking and defending multi-turn safety risks in tool-using agents
Xu Li, Simon Yu, Minzhou Pan, Yiyou Sun, Bo Li, Dawn Song, Xue Lin, and Weiyan Shi. Unsafer in many turns: Benchmarking and defending multi-turn safety risks in tool-using agents. arXiv preprint arXiv:2602.13379, 2026
-
[34]
Tian Zhang, Yiwei Xu, Juan Wang, Keyan Guo, Xiaoyang Xu, Bowen Xiao, Quanlong Guan, Jinlin Fan, Jiawei Liu, Zhiquan Liu, et al. Agentsentry: Mitigating indirect prompt injec- tion in llm agents via temporal causal diagnostics and context purification.arXiv preprint arXiv:2602.22724, 2026
-
[35]
Debeshee Das, Luca Beurer-Kellner, Marc Fischer, and Maximilian Baader. Commandsans: Securing ai agents with surgical precision prompt sanitization.arXiv preprint arXiv:2510.08829, 2025
-
[36]
Agentwatcher: A rule-based prompt injection monitor, 2026
Yanting Wang, Wei Zou, Runpeng Geng, and Jinyuan Jia. Agentwatcher: A rule-based prompt injection monitor, 2026. URLhttps://arxiv.org/abs/2604.01194
-
[37]
Ruoyao Wen, Hao Li, Chaowei Xiao, and Ning Zhang. Agentsys: Secure and dynamic llm agents through explicit hierarchical memory management.arXiv preprint arXiv:2602.07398, 2026
-
[38]
Kaiyuan Zhang, Mark Tenenholtz, Kyle Polley, Jerry Ma, Denis Yarats, and Ninghui Li. Browsesafe: Understanding and preventing prompt injection within ai browser agents.arXiv preprint arXiv:2511.20597, 2025. 12
-
[39]
Aradhye Agarwal, Gurdit Siyan, Yash Pandya, Joykirat Singh, Akshay Nambi, and Ahmed Awadallah. Learning when to act or refuse: Guarding agentic reasoning models for safe multi-step tool use.arXiv preprint arXiv:2603.03205, 2026
-
[40]
Chong Xiang, Drew Zagieboylo, Shaona Ghosh, Sanjay Kariyappa, Kai Greshake, Hanshen Xiao, Chaowei Xiao, and G. Edward Suh. Architecting secure ai agents: Perspectives on system-level defenses against indirect prompt injection attacks, 2026. URL https://arxiv. org/abs/2603.30016
-
[41]
Sok: The attack surface of agentic ai–tools, and autonomy.arXiv preprint arXiv:2603.22928, 2026
Ali Dehghantanha and Sajad Homayoun. Sok: The attack surface of agentic ai–tools, and autonomy.arXiv preprint arXiv:2603.22928, 2026
-
[42]
Reason- ing with language model is planning with world model
Shibo Hao, Yi Gu, Haodi Ma, Joshua Hong, Zhen Wang, Daisy Wang, and Zhiting Hu. Reason- ing with language model is planning with world model. InProceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, pages 8154–8173, 2023
work page 2023
-
[43]
Lin Guan, Karthik Valmeekam, Sarath Sreedharan, and Subbarao Kambhampati. Leveraging pre-trained large language models to construct and utilize world models for model-based task planning.Advances in Neural Information Processing Systems, 36:79081–79094, 2023
work page 2023
-
[44]
Nicola Dainese, Matteo Merler, Minttu Alakuijala, and Pekka Marttinen. Generating code world models with large language models guided by monte carlo tree search.Advances in Neural Information Processing Systems, 37:60429–60474, 2024. A Data and Code We release our data amd code:https://github.com/idwts/TRUST-BENCH B Related Work From injected content to t...
work page 2024
-
[45]
select a compromise pivot, such as scope, recipient identity, audit path, schema field, reusable state, or side effect
-
[46]
keep the exploration trajectory behaviorally close to the benign tool so that trust can accumulate during probing
-
[47]
modify only the trigger-bearing final state-action composition so that the malicious variant becomes harmful when the hidden rule fires
-
[48]
Candidate episodes produced by this process are retained only after a two-person audit
construct a matched safe control that keeps the same task objective and surface interaction pattern but restores the missing review, audit, or safe-mode constraint. Candidate episodes produced by this process are retained only after a two-person audit. The audit statistics reported in Table 2 are computed on the initial candidate version of the data, befo...
-
[49]
sample-level red-blue data construction on the reconstructed benchmark, in which the blue side performs a standardized three-round exploratory interaction and the resulting trajectory is curated into a labeled episode
-
[50]
grouped 5-fold training and evaluation on the resulting curated dataset. Each curated episode contains three observed exploratory tool interactions, one proposed final tool call, and one execute/reject label. Grouped splitting keeps related rows from the same base group in the same fold, and threshold calibration is performed on training folds only. To ev...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.