Physics-Guided Spatiotemporal State Space Modeling for Lookahead Molten Pool Segmentation in Laser Wire-Feed Welding
Pith reviewed 2026-06-26 09:12 UTC · model grok-4.3
The pith
A physics-guided state space model forecasts the future layout of keyhole, wire, and molten pool from past images and signals.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
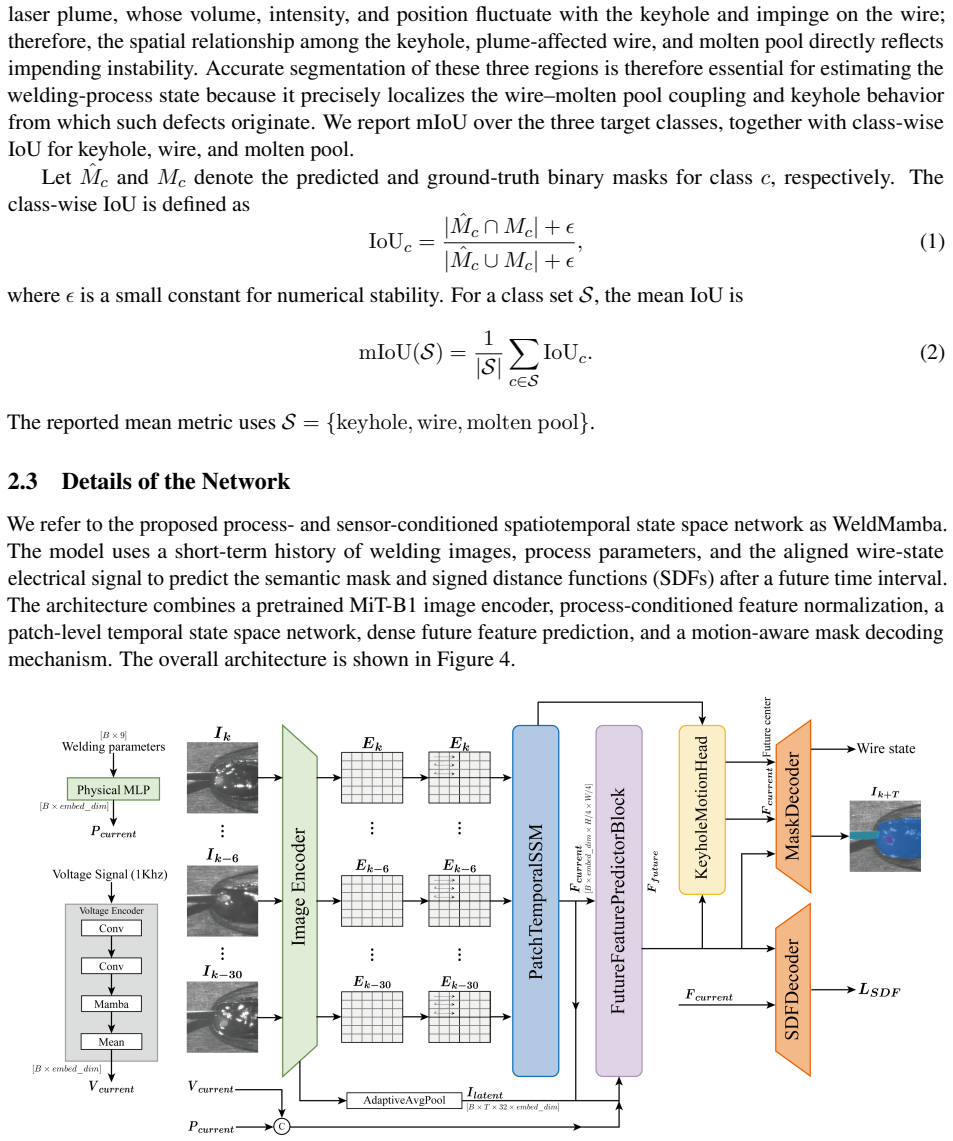
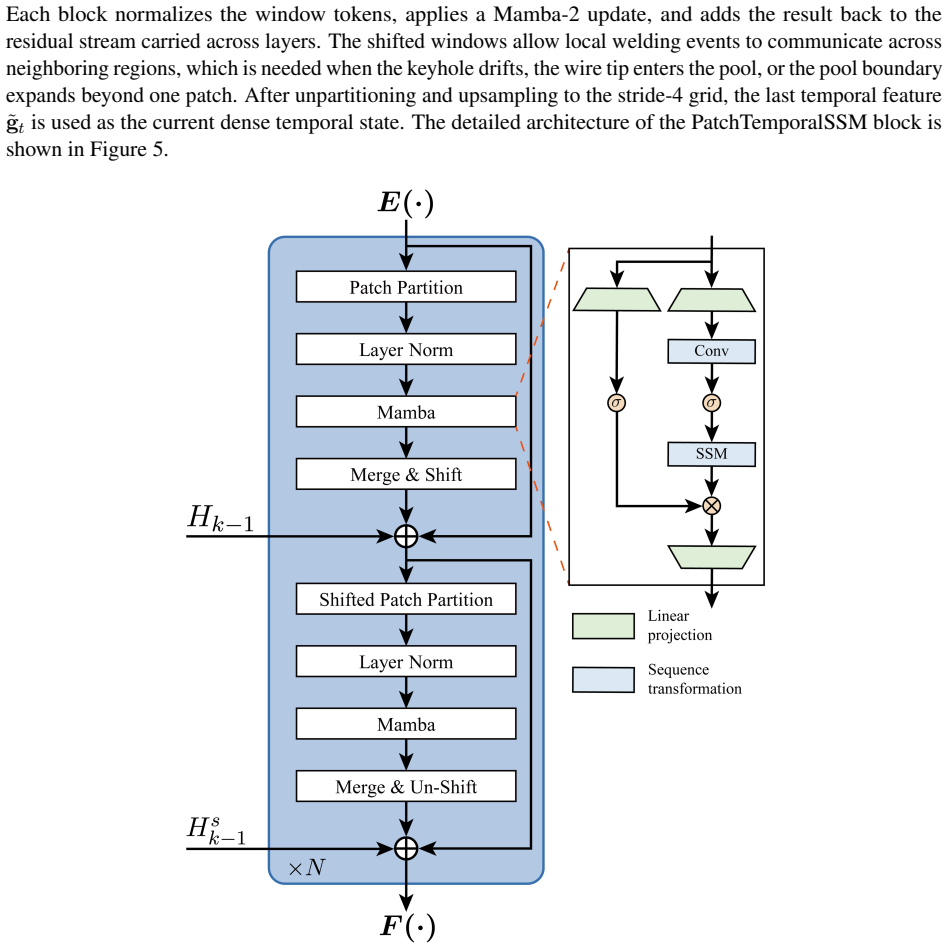
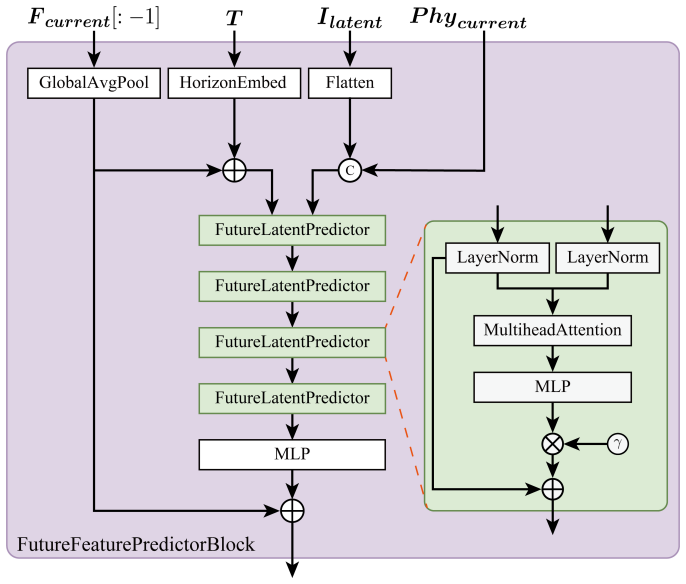
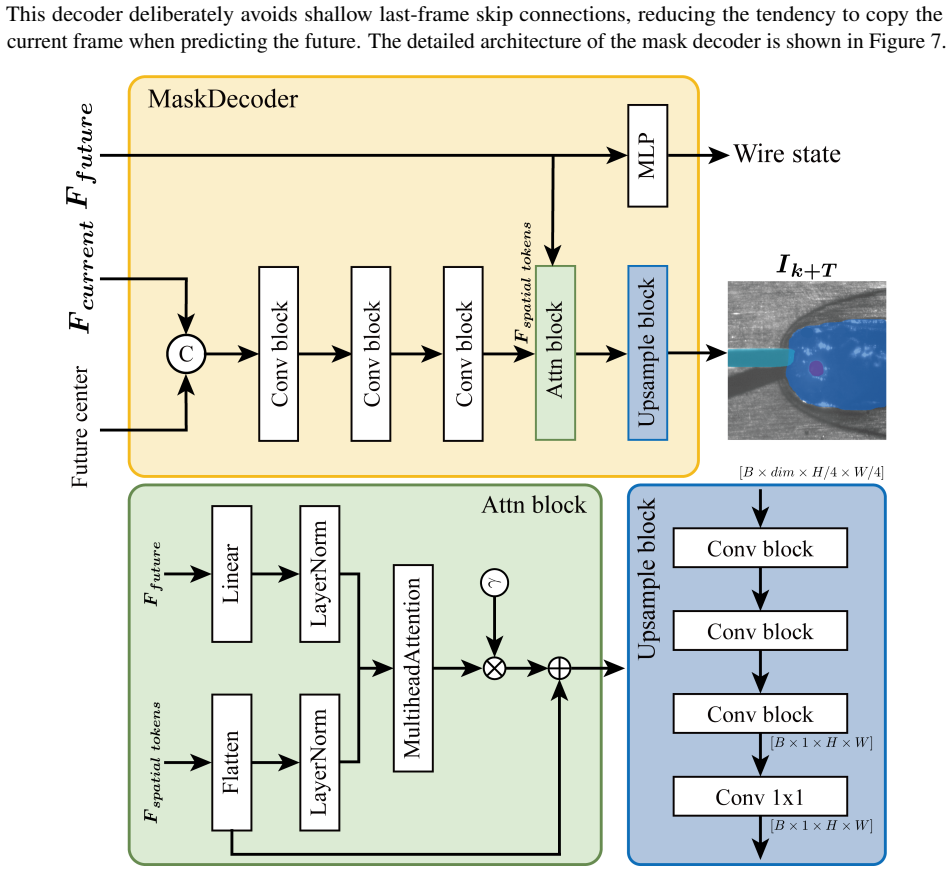
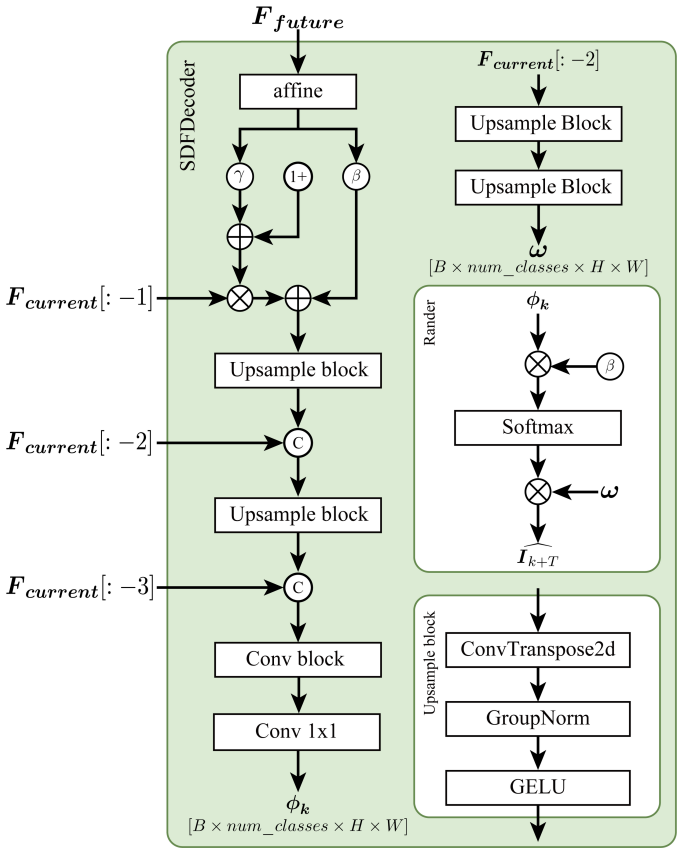
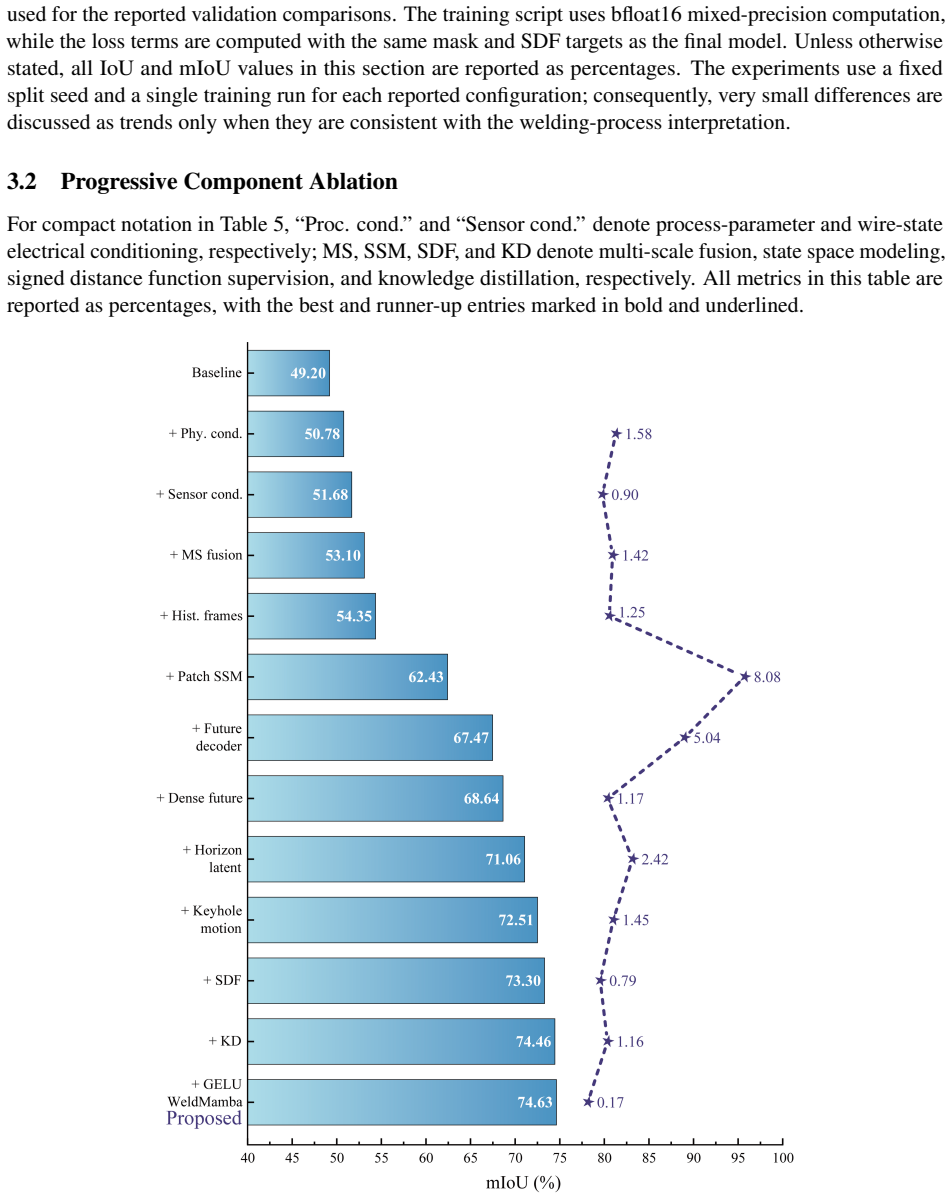
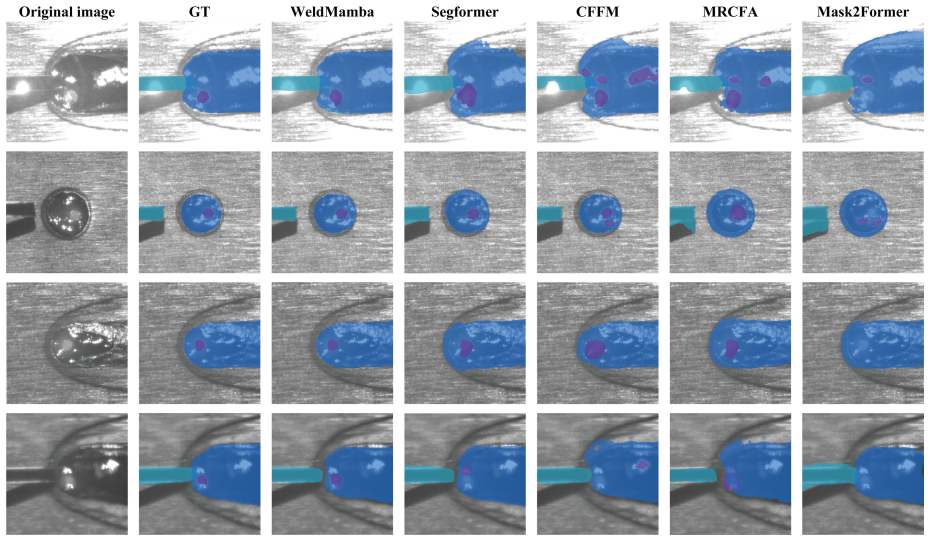
The WeldMamba architecture integrates a visual encoder, process- and sensor-conditioned feature normalization, patch-level temporal state space modeling, horizon-conditioned latent prediction, dense future feature prediction, and a motion-aware mask decoder, together with auxiliary signed-distance supervision and keyhole-specific losses, to produce accurate future semantic maps of the three regions.
What carries the argument
The spatiotemporal state space network that performs patch-level temporal modeling on conditioned visual features and then decodes motion-aware future masks.
If this is right
- Temporal history from past frames measurably raises lookahead segmentation accuracy.
- Patch-level state space modeling contributes more than alternative temporal mechanisms in this setting.
- Explicit modeling of keyhole motion improves geometric fidelity of the predicted pool and wire regions.
- Auxiliary geometric losses on signed distance and local motion further constrain the output to physically plausible shapes.
Where Pith is reading between the lines
- The same conditioning and state-space structure could be reused for other manufacturing tasks that must issue commands before full sensor data arrives.
- If the current dataset proves narrow, retraining with broader process-parameter ranges would be the direct next experiment.
- The 500 ms horizon could be treated as a tunable input rather than a fixed target to explore accuracy trade-offs at shorter and longer delays.
Load-bearing premise
The 43-sequence dataset and its train-test splits capture enough variation that the reported accuracy will generalize to unseen materials, speeds, or process conditions.
What would settle it
Running the trained model on a fresh collection of welding sequences recorded at different speeds or with different alloys and measuring whether mIoU at 500 ms lookahead falls well below 74.63 percent.
Figures

read the original abstract
Real-time weld-pool perception is critical for closed-loop control in laser wire-feed welding, where sensing, computation, and actuator response introduce unavoidable delay. This paper presents a physics-guided spatiotemporal state space network for lookahead weld-pool segmentation. The model uses historical coaxial grayscale images, welding process parameters, and aligned wire-state electrical signals to predict the future semantic layout of three physically meaningful regions: keyhole, wire, and molten pool. It combines a visual encoder, process- and sensor-conditioned feature normalization, patch-level temporal state space modeling, horizon-conditioned latent prediction, dense future feature prediction, and a motion-aware mask decoder. Auxiliary signed-distance-function supervision, temporal consistency, feature distillation, and fine-grained keyhole losses further constrain the predicted geometry and local motion. Experiments on a 43-sequence laser welding dataset show that the proposed WeldMamba reaches 74.63\% mIoU at a 500 ms lookahead. Ablation studies further show that temporal history, patch-level state space modeling, and keyhole motion awareness are the main contributors to robust future segmentation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces WeldMamba, a physics-guided spatiotemporal state space network for 500 ms lookahead segmentation of the weld pool in laser wire-feed welding. The model ingests historical coaxial grayscale images, welding parameters, and wire-state electrical signals to predict semantic layouts of the keyhole, wire, and molten pool regions. It integrates a visual encoder, process-conditioned normalization, patch-level temporal state space modeling, horizon-conditioned latent prediction, dense future feature prediction, a motion-aware mask decoder, and auxiliary losses (signed-distance functions, temporal consistency, feature distillation, keyhole motion). On a 43-sequence dataset the model reports 74.63% mIoU, with ablations identifying temporal history, patch-level SSM, and keyhole motion awareness as primary contributors.
Significance. If the central empirical result is shown to rest on sequence-disjoint evaluation and to generalize beyond the narrow 43-sequence corpus, the work would offer a concrete advance for delay-compensated closed-loop welding control by demonstrating that state-space temporal modeling plus physics-informed constraints can produce usable future geometry predictions. The explicit incorporation of process parameters and keyhole dynamics, together with the auxiliary geometric losses, constitutes a clear methodological contribution over purely data-driven video prediction baselines.
major comments (3)
- [Experiments section] Experiments / Dataset description: The central claim of 74.63% mIoU at 500 ms lookahead and the ablation rankings rest on a single 43-sequence corpus, yet no information is supplied on sequence-length statistics, material/speed/parameter diversity, or the train/test partitioning procedure (sequence-disjoint vs. frame-random). Without these details it is impossible to determine whether the reported performance reflects genuine extrapolation to unseen future frames and process conditions or merely interpolation within temporally correlated runs.
- [§4 or Evaluation subsection] Evaluation protocol: The manuscript provides no explicit statement or diagram confirming that the 500 ms predictions are generated from frames strictly after the last training/inference input rather than from interpolated or within-sequence data. This distinction is load-bearing for the “lookahead” claim and for the assertion that the model compensates for sensing/actuation delay.
- [Results / Ablation tables] Results presentation: Neither the abstract nor the reported experiments include baseline comparisons, per-sequence error bars, or statistical tests for the 74.63% mIoU figure or for the ablation deltas. Consequently the quantitative support for “temporal history, patch-level state space modeling, and keyhole motion awareness” as the main contributors cannot be assessed for robustness.
minor comments (2)
- [Method section] Notation for the horizon-conditioned latent prediction and the motion-aware decoder should be introduced with explicit equations rather than descriptive prose only.
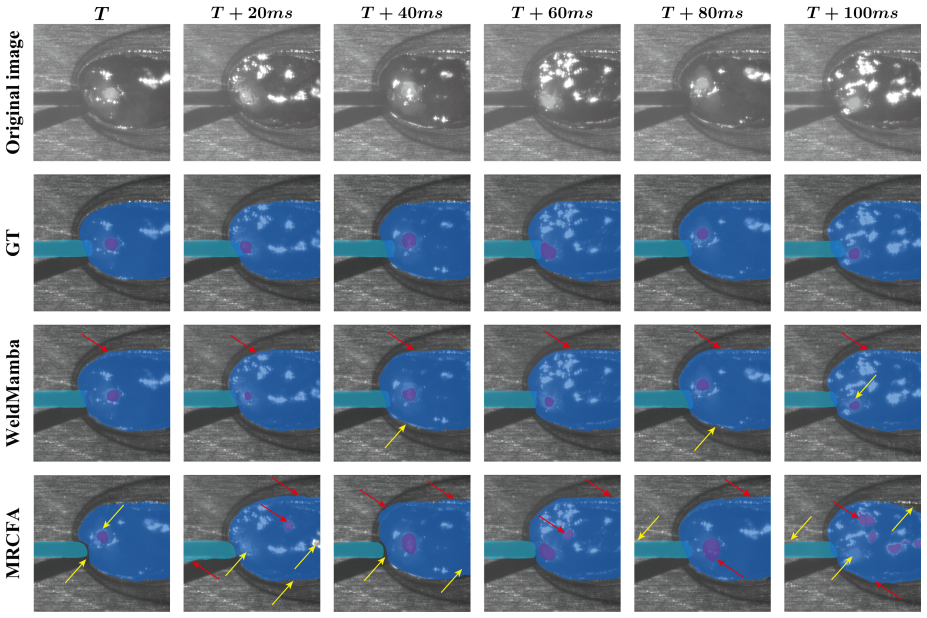
- [Figures] Figure captions for the qualitative results should state the exact lookahead horizon and the source sequence identifier for each example.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. The comments highlight important aspects of experimental rigor that will improve the clarity and credibility of the manuscript. We will revise the paper to provide the requested details on the dataset, evaluation protocol, and results presentation. Point-by-point responses follow.
read point-by-point responses
-
Referee: [Experiments section] Experiments / Dataset description: The central claim of 74.63% mIoU at 500 ms lookahead and the ablation rankings rest on a single 43-sequence corpus, yet no information is supplied on sequence-length statistics, material/speed/parameter diversity, or the train/test partitioning procedure (sequence-disjoint vs. frame-random). Without these details it is impossible to determine whether the reported performance reflects genuine extrapolation to unseen future frames and process conditions or merely interpolation within temporally correlated runs.
Authors: We agree that these details are essential for evaluating generalization. In the revised manuscript we will expand the dataset description to report sequence-length statistics (mean, min, max frames per sequence), the range of materials, welding speeds, laser powers, and wire-feed rates represented in the 43 sequences, and an explicit statement that the train/test split is sequence-disjoint (no temporal overlap or shared sequences between sets). revision: yes
-
Referee: [§4 or Evaluation subsection] Evaluation protocol: The manuscript provides no explicit statement or diagram confirming that the 500 ms predictions are generated from frames strictly after the last training/inference input rather than from interpolated or within-sequence data. This distinction is load-bearing for the “lookahead” claim and for the assertion that the model compensates for sensing/actuation delay.
Authors: We will add a dedicated paragraph and a schematic diagram in the Evaluation subsection that illustrates the temporal window: input frames end at time t, the model predicts the semantic layout at t + 500 ms, and no future or interpolated frames are used during inference. This will make the strict lookahead nature of the evaluation explicit. revision: yes
-
Referee: [Results / Ablation tables] Results presentation: Neither the abstract nor the reported experiments include baseline comparisons, per-sequence error bars, or statistical tests for the 74.63% mIoU figure or for the ablation deltas. Consequently the quantitative support for “temporal history, patch-level state space modeling, and keyhole motion awareness” as the main contributors cannot be assessed for robustness.
Authors: We accept that the current results section lacks these elements. The revised version will include (i) comparisons against standard video-prediction and spatiotemporal baselines, (ii) per-sequence mIoU values with standard deviations across the test sequences, and (iii) paired statistical tests (e.g., Wilcoxon signed-rank) on the ablation deltas to quantify significance. revision: yes
Circularity Check
No circularity: empirical model performance measured on held-out sequences
full rationale
The paper presents an empirical neural network (WeldMamba) for lookahead segmentation, with results given as measured mIoU on a 43-sequence dataset. No derivation chain, equations, or predictions reduce the reported performance to fitted inputs by construction. Architectural choices (patch-level SSM, keyhole losses, etc.) are trained end-to-end and validated via standard ablations; no self-citation is load-bearing for the central claim, and no uniqueness theorem or ansatz is smuggled in. The evaluation is self-contained against external benchmarks (held-out sequences), so the finding is no significant circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Historical coaxial grayscale images, welding parameters, and wire-state electrical signals contain sufficient information to predict future semantic layout of keyhole, wire, and molten pool.
- domain assumption Auxiliary signed-distance-function, temporal consistency, and keyhole motion losses improve geometric fidelity of the predicted masks.
Reference graph
Works this paper leans on
-
[1]
Kyung-Min Hong and Yung C. Shin. Prospects of laser welding technology in the automotive industry: A review.Journal of Materials Processing Technology, 245:46–69, 2017. doi: 10.1016/j.jmatprotec. 2017.02.008
-
[3]
Machine learning-based in-process monitoring for laser deep penetration welding: A survey
Rundong Lu, Ming Lou, Yujun Xia, Shuang Huang, Zhuoran Li, Tianle Lyu, Yidi Wu, and Yongbing Li. Machine learning-based in-process monitoring for laser deep penetration welding: A survey. Engineering Applications of Artificial Intelligence, 137:109059, 2024. doi: 10.1016/j.engappai.2024. 109059
-
[4]
Coaxial monitoring of keyhole during Yb:YAG laser welding
Cheol-Hee Kim and Do-Chang Ahn. Coaxial monitoring of keyhole during Yb:YAG laser welding. Optics & Laser Technology, 44(6):1874–1880, 2012. doi: 10.1016/j.optlastec.2012.02.025
-
[5]
Deyong You, Xiangdong Gao, and Seiji Katayama. Monitoring of high-power laser welding using high-speed photographing and image processing.Mechanical Systems and Signal Processing, 49(1–2): 39–52, 2014. doi: 10.1016/j.ymssp.2013.10.024
-
[6]
Masiyang Luo and Yung C. Shin. Vision-based weld pool boundary extraction and width measurement during keyhole fiber laser welding.Optics and Lasers in Engineering, 64:59–70, 2015. doi: 10.1016/j. optlaseng.2014.07.004
work page doi:10.1016/j 2015
-
[7]
Jiajun Xu, Youmin Rong, Yu Huang, Pingjiang Wang, and Chunming Wang. Keyhole-induced porosity formation during laser welding.Journal of Materials Processing Technology, 252:720–727, 2018. doi: 10.1016/j.jmatprotec.2017.10.038
-
[8]
Yanxi Zhang, Deyong You, Xiangdong Gao, and Seiji Katayama. Online monitoring of welding status based on a DBN model during laser welding.Engineering, 5(4):671–678, 2019. doi: 10.1016/j.eng. 2019.01.016
-
[9]
Zhehao Zhang, Bin Li, Weifeng Zhang, Rundong Lu, Satoshi Wada, and Yi Zhang. Real-time penetration state monitoring using convolutional neural network for laser welding of tailor rolled blanks.Journal of Manufacturing Systems, 54:348–360, 2020. doi: 10.1016/j.jmsy.2020.01.006
-
[10]
Bin Zhang, Kyung-Min Hong, and Yung C. Shin. Deep-learning-based porosity monitoring of laser welding process.Manufacturing Letters, 23:62–66, 2020. doi: 10.1016/j.mfglet.2020.01.001
-
[11]
Hyeongwon Kim, Kimoon Nam, Sehyeok Oh, and Hyungson Ki. Deep-learning-based real-time monitoring of full-penetration laser keyhole welding by using the synchronized coaxial observation method.Journal of Manufacturing Processes, 68:1018–1030, 2021. doi: 10.1016/j.jmapro.2021.06.029
-
[12]
Yanxi Zhang, Deyong You, Xiangdong Gao, Nanfeng Zhang, and Perry P. Gao. Welding defects detection based on deep learning with multiple optical sensors during disk laser welding of thick plates. Journal of Manufacturing Systems, 51:87–94, 2019. doi: 10.1016/j.jmsy.2019.02.004. 28
-
[13]
Longchao Cao, Jingchang Li, Libin Zhang, Shuyang Luo, Menglei Li, and Xufeng Huang. Cross- attention-based multi-sensing signals fusion for penetration state monitoring during laser welding of aluminum alloy.Knowledge-Based Systems, 261:110212, 2023. doi: 10.1016/j.knosys.2022.110212
-
[14]
Sanghoon Kang, Kidong Lee, Minjung Kang, Yong Hoon Jang, and Cheolhee Kim. Weld-penetration- depth estimation using deep learning models and multisensor signals in Al/Cu laser overlap welding. Optics & Laser Technology, 161:109179, 2023. doi: 10.1016/j.optlastec.2023.109179
-
[15]
Wang Cai, LeShi Shu, ShaoNing Geng, Qi Zhou, and LongChao Cao. Real-time monitoring of weld surface morphology with lightweight semantic segmentation model improved by attention mechanism during laser keyhole welding.Optics & Laser Technology, 174:110707, 2024. doi: 10.1016/j.optlastec. 2024.110707
-
[16]
Tianpu Li, Yue Cao, and YuMing Zhang. Analysis of weld pool region constituents in GMAW for dynamic reconstruction through characteristic enhancement and LSTM U-Net networks.Journal of Manufacturing Processes, 127:573–588, 2024. doi: 10.1016/j.jmapro.2024.07.084
-
[17]
Yuewei Ai, Chang Lei, Jian Cheng, and Jie Mei. Prediction of weld area based on image recognition and machine learning in laser oscillation welding of aluminum alloy.Optics and Lasers in Engineering, 160:107258, 2023. doi: 10.1016/j.optlaseng.2022.107258
-
[18]
Sen Li, Haichao Cui, Chendong Shao, Yaqi Wang, and Xinhua Tang. A multi-task spatiotemporal deep neural network for predicting penetration depth and morphology in laser welding.Engineering Applications of Artificial Intelligence, 166:113641, 2026. doi: 10.1016/j.engappai.2025.113641
-
[19]
Sen Li, Xiaoying Liu, Xiaojian Xu, Chendong Shao, Yaqi Wang, Ling Lan, Xinhua Tang, and Haichao Cui. A welding penetration prediction model for laser welding process based on self-supervised learning using physics-informed neural networks.Journal of Manufacturing Processes, 160:642–662, 2026. doi: 10.1016/j.jmapro.2026.01.035
-
[20]
Rundong Lu, Haiying Wei, Fazhi Li, Zhehao Zhang, Zhichao Liang, and Bin Li. In-situ monitoring of the penetration status of keyhole laser welding by using a support vector machine with interaction time conditioned keyhole behaviors.Optics and Lasers in Engineering, 130:106099, 2020. doi: 10.1016/j.optlaseng.2020.106099
-
[21]
Rui Yu, Joseph Kershaw, Peng Wang, and YuMing Zhang. How to accurately monitor the weld penetration from dynamic weld pool serial images using CNN-LSTM deep learning model?IEEE Robotics and Automation Letters, 7(3):6519–6525, 2022. doi: 10.1109/LRA.2022.3173659
-
[22]
Guangwen Ye, Xiangdong Gao, Qianwen Liu, Jiakai Wu, Yanxi Zhang, and Perry P. Gao. Prediction of weld back width based on top vision sensing during laser-MIG hybrid welding.Journal of Manufacturing Processes, 84:1376–1388, 2022. doi: 10.1016/j.jmapro.2022.11.021
-
[23]
Gao, Xiangdong Gao, and Yuhui Huang
Xi’an Fan, Perry P. Gao, Xiangdong Gao, and Yuhui Huang. Prediction of weld widths for laser-MIG hybrid welding using informer model.IEEE Transactions on Industrial Electronics, 71(6):6221–6230,
-
[24]
doi: 10.1109/TIE.2023.3294634
-
[25]
Zhuang Zhao, Peng Gao, Jun Lu, and Lianfa Bai. Dynamic penetration prediction based on continuous video learning.Welding in the World, 68(4):867–877, 2024. doi: 10.1007/s40194-024-01745-1
-
[26]
Wenchao Ke, Zhi Zeng, J. P. Oliveira, Bei Peng, Jiajia Shen, Caiwang Tan, Xiaoguo Song, and Wentao Yan. Heat transfer and melt flow of keyhole, transition and conduction modes in laser beam 29 oscillating welding.International Journal of Heat and Mass Transfer, 203:123821, 2023. doi: 10.1016/ j.ijheatmasstransfer.2022.123821
arXiv 2023
-
[27]
Yuxiang Hong, Xingxing He, Jing Xu, Ruiling Yuan, Kai Lin, Baohua Chang, and Dong Du. AF- FTTSnet: An end-to-end two-stream convolutional neural network for online quality monitoring of robotic welding.Journal of Manufacturing Systems, 74:422–434, 2024. doi: 10.1016/j.jmsy.2024.04. 006
-
[28]
Yuxiang Hong, Mingxuan Yang, Ruiling Yuan, Dong Du, and Baohua Chang. A novel quality monitoring approach based on multigranularity spatiotemporal attentive representation learning during climbing GTAW.IEEE Transactions on Industrial Informatics, 20(6):8218–8228, 2024. doi: 10.1109/TII.2024. 3369235
-
[29]
Shenghong Yan, Bo Chen, Han Gao, Caiwang Tan, Xiaoguo Song, and Guodong Wang. Cross-attention time-series multi-feature fusion vision transformer for joint formation monitoring in laser scanning welding.Mechanical Systems and Signal Processing, 229:112531, 2025. doi: 10.1016/j.ymssp.2025. 112531
-
[30]
Yeh, Xiaoou Tang, Yiming Liu, and Aseem Agarwala
Ziwei Liu, Raymond A. Yeh, Xiaoou Tang, Yiming Liu, and Aseem Agarwala. Video frame synthesis using deep voxel flow. InICCV, pages 4463–4471, 2017
2017
-
[31]
World models
David Ha and Juergen Schmidhuber. World models. InNeurIPS, 2018
2018
-
[32]
Dream to control: Learning behaviors by latent imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination. InICLR, 2020
2020
-
[33]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Xinlei Chen, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video. arXiv preprint arXiv:2404.08471, 2024. doi: 10.48550/arXiv.2404.08471
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2404.08471 2024
-
[34]
Are self-attentions effective for time series forecasting? InNeurIPS, 2024
Dongbin Kim, Jinseong Park, Jaewook Lee, and Hoki Kim. Are self-attentions effective for time series forecasting? InNeurIPS, 2024. arXiv:2405.16877
arXiv 2024
-
[35]
Yuxuan Wang, Haixu Wu, Jiaxiang Dong, Guo Qin, Haoran Zhang, Yong Liu, Yunzhong Qiu, Jianmin Wang, and Mingsheng Long. TimeXer: Empowering transformers for time series forecasting with exogenous variables.arXiv preprint arXiv:2402.19072, 2024. doi: 10.48550/arXiv.2402.19072
-
[36]
Zehua Fan, Wenqi Lyu, Wenxuan Song, Linge Zhao, Yifei Yang, Xi Wang, Junjie He, Lida Huang, Haiyan Liu, Bingchuan Sun, Guangjun Bao, Xuanyao Mao, Liang Xu, Yan Wang, and Feng Gao. PROSPECT: Unified streaming vision-language navigation via semantic–spatial fusion and latent predictive representation.arXiv preprint arXiv:2603.03739, 2026. doi: 10.48550/arXi...
-
[37]
Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality
Tri Dao and Albert Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InICML, Proceedings of Machine Learning Research, pages 10041–10071. PMLR, 2024
2024
-
[38]
Vi- sion mamba: Efficient visual representation learning with bidirectional state space model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vi- sion mamba: Efficient visual representation learning with bidirectional state space model. InICML, Proceedings of Machine Learning Research, pages 62429–62442. PMLR, 2024
2024
-
[39]
VMamba: Visual state space model
Yue Liu, Yunjie Tian, Yuzhong Zhao, Hongtian Yu, Lingxi Xie, Yaowei Wang, Qixiang Ye, Jianbin Jiao, and Yunfan Liu. VMamba: Visual state space model. InNeurIPS, 2024. 30
2024
-
[40]
Chenhongyi Yang, Zehui Chen, Miguel Espinosa, Linus Ericsson, Zhenyu Wang, Jiaming Liu, and Elliot J. Crowley. PlainMamba: Improving non-hierarchical mamba in visual recognition. InBMVC. BMV A Press, 2024
2024
-
[41]
Exploiting temporal state space sharing for video semantic segmentation
Syed Ariff Syed Hesham, Yun Liu, Guolei Sun, Henghui Ding, Jing Yang, Ender Konukoglu, Xue Geng, and Xudong Jiang. Exploiting temporal state space sharing for video semantic segmentation. InCVPR,
-
[42]
doi: 10.1109/CVPR52734.2025.02255
-
[43]
Woodhead Publishing, 2016
Augusto Di Gianfrancesco, editor.Materials for Ultra-Supercritical and Advanced Ultra-Supercritical Power Plants. Woodhead Publishing, 2016. ISBN 978-0-08-100552-1
2016
-
[44]
Alvarez, and Ping Luo
Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, and Ping Luo. SegFormer: Simple and efficient design for semantic segmentation with transformers. InNeurIPS, 2021
2021
-
[45]
Oriane Simeoni, Huy V . V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michael Ramamonjisoa, Francisco Massa, Daniel Haziza, Luca Wehrstedt, Jianyuan Wang, Timothee Darcet, Theo Moutakanni, Leonel Sentana, Claire Roberts, Andrea Vedaldi, Jamie Tolan, John Brandt, Camille Couprie, Julie...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10104 2025
-
[46]
Coarse-to-fine feature mining for video semantic segmentation
Guolei Sun, Yun Liu, Henghui Ding, Thomas Probst, and Luc Van Gool. Coarse-to-fine feature mining for video semantic segmentation. InCVPR, pages 3126–3137, 2022
2022
-
[47]
Mining relations among cross-frame affinities for video semantic segmentation
Guolei Sun, Yun Liu, Hao Tang, Ajad Chhatkuli, Le Zhang, and Luc Van Gool. Mining relations among cross-frame affinities for video semantic segmentation. InECCV, 2022
2022
-
[48]
Schwing, Alexander Kirillov, and Rohit Girdhar
Bowen Cheng, Ishan Misra, Alexander G. Schwing, Alexander Kirillov, and Rohit Girdhar. Masked- attention mask transformer for universal image segmentation. InCVPR, pages 1290–1299, 2022
2022
-
[49]
Encoder- decoder with atrous separable convolution for semantic image segmentation
Liang-Chieh Chen, Yukun Zhu, George Papandreou, Florian Schroff, and Hartwig Adam. Encoder- decoder with atrous separable convolution for semantic image segmentation. InECCV, pages 801–818, 2018
2018
-
[50]
Focal loss for dense object detection,
Ramprasaath R. Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In ICCV, pages 618–626, 2017. doi: 10.1109/ICCV .2017.74. 31 Algorithm 1:Training – Physics-Guided Lookahead Weld-Pool Segmentation In Training set Dtrain, validatio...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.