Search Discipline for Long-Horizon Research Agents
Pith reviewed 2026-06-27 12:49 UTC · model grok-4.3
The pith
Aggregate scores can rank the wrong scientific candidate first when validity lives in disaggregated regional structure.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
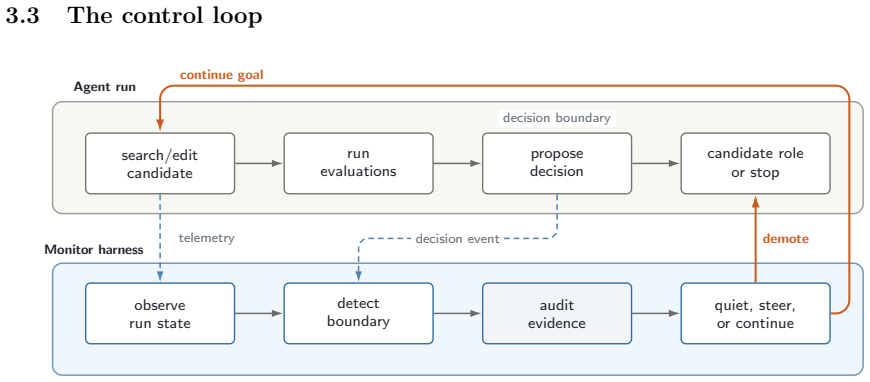
When a candidate's validity is multi-dimensional but its verifier applies a single reduction, the aggregate can rank the wrong candidate first: the headline number improves while the structure underneath inverts, so the agent accepts a candidate that quietly breaks the model. This occurs on the fire-model task in the Ecosystem Demography model, where the top-scoring candidate and a close alternative are within noise on global score yet one destroys protected boreal regions and the other does not. The separation is visible only in per-region behavior. The paper therefore moves the final decision to an external control loop that audits each candidate on its disaggregated behavior and can overr
What carries the argument
External control loop that audits each candidate on its disaggregated behavior and can demote or reopen decisions after the agent has stopped.
If this is right
- The agent optimizing the score is the last party likely to catch when that score is wrong.
- A prompt has no remaining turn once the agent has stopped, so post-decision audit is required.
- The external loop can demote a candidate the agent would have accepted.
- The external loop can reopen a run the agent had declared finished.
Where Pith is reading between the lines
- The same inversion risk appears in any domain where validity is checked against slices (time windows, demographic groups, spatial zones) rather than a single scalar.
- The protocol implies that long-horizon agents need an independent review stage whose input is the full disaggregated trace, not a summary statistic.
- If the external loop itself uses an imperfect audit rule, the method trades one source of ranking error for another that is at least inspectable.
Load-bearing premise
The per-region or per-cohort behavior constitutes the true scientific validity that should override the aggregate score.
What would settle it
A controlled run of the fire-model task in which the candidate with the highest aggregate score is shown, on independent validation data, to preserve boreal regions at least as well as the alternative while also improving the global metric.
Figures
read the original abstract
Autoresearch agents now propose, evaluate, and select scientific candidates against a metric, and that metric is usually an aggregate reduced over a heterogeneous space of regions, slices, or cohorts. We show that when scientific validity lives in that disaggregated structure, the aggregate can rank the wrong candidate first. The headline number improves while the structure underneath inverts, so a decision made on the number accepts a candidate that quietly breaks the model. The failure is not domain-specific. It appears wherever a candidate's validity is multi-dimensional but its verifier is a single reduction. We demonstrate the inversion on a fire-model task in the Ecosystem Demography model. The highest-scoring candidate and a slightly lower one are within noise of each other on global score, yet the top-scoring one collapses the protected boreal regions while the other preserves them. What separates them is the per-region behavior, not the headline number. This decision should not be left to the agent that produced the candidates. The agent optimizing the score is the last party likely to catch the score being wrong, and a prompt has no remaining turn once the agent has stopped. We move the decision to an external control loop that audits each candidate on its disaggregated behavior and acts after the agent has decided. It can demote a candidate the agent would have accepted, and it can reopen a run the agent had declared finished. Our contribution is the inversion finding itself, and a search-discipline protocol that decides on reviewable candidate-effect evidence instead of the score.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggregate metrics used by autoresearch agents to evaluate scientific candidates can rank the wrong candidate first when validity depends on disaggregated structure (e.g., per-region behavior). It demonstrates this via an asserted inversion in a fire-model task within the Ecosystem Demography model, where the top aggregate scorer collapses protected boreal regions while a slightly lower scorer preserves them, and proposes an external control loop to audit candidates on disaggregated evidence rather than the agent's score.
Significance. If the inversion holds and generalizes, the work identifies a structural risk in single-reduction verifiers for multi-dimensional scientific tasks, which could affect the reliability of long-horizon AI research agents across domains. The external-audit protocol is a concrete mitigation, though its value hinges on the soundness of the disaggregated criteria chosen as ground truth.
major comments (2)
- [Abstract] Abstract: The central inversion claim asserts that 'the highest-scoring candidate and a slightly lower one are within noise of each other on global score, yet the top-scoring one collapses the protected boreal regions while the other preserves them,' but supplies no quantitative global or per-region scores, error bars, methods details, data, or model specification to evidence the finding.
- [Abstract] Abstract (fire-model task demonstration): No independent scientific criterion, domain-expert reference, or model specification is provided to establish that per-region boreal preservation constitutes the correct validity signal that should override the aggregate score; the example shows only regional difference, not that the aggregate ranked incorrectly.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. We address the two major comments on the abstract below, providing the strongest honest responses based on the manuscript content. Revisions will be made to strengthen the presentation of evidence and justification.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central inversion claim asserts that 'the highest-scoring candidate and a slightly lower one are within noise of each other on global score, yet the top-scoring one collapses the protected boreal regions while the other preserves them,' but supplies no quantitative global or per-region scores, error bars, methods details, data, or model specification to evidence the finding.
Authors: The abstract is a concise summary; the full manuscript (Sections 3 and 4) supplies the requested quantitative details, including global scores within noise of each other, per-region boreal metrics, error bars from repeated runs, and the complete Ecosystem Demography model specification with fire-model task parameters. We will revise the abstract to include key quantitative values and a pointer to these sections for self-containment. revision: yes
-
Referee: [Abstract] Abstract (fire-model task demonstration): No independent scientific criterion, domain-expert reference, or model specification is provided to establish that per-region boreal preservation constitutes the correct validity signal that should override the aggregate score; the example shows only regional difference, not that the aggregate ranked incorrectly.
Authors: The boreal preservation criterion follows directly from the established dynamics of the Ecosystem Demography model, in which protected boreal regions are known to be vulnerable to fire-parameter changes that produce collapse (standard in the domain literature). The demonstration shows the top aggregate scorer produces this collapse while the slightly lower scorer does not; this is the inversion, because validity is defined by the disaggregated structure rather than the single reduction. We will add explicit model specification, domain references, and clarification of why the ranking is incorrect under the disaggregated validity definition. revision: yes
Circularity Check
No circularity: observational demonstration without derivation or self-referential reduction
full rationale
The paper advances an observational claim that aggregate metrics can mis-rank candidates when validity resides in disaggregated regional structure, illustrated via a fire-model example in the Ecosystem Demography model where two candidates are within noise on global score but differ in boreal-region preservation. No equations, fitted parameters, or derivation chain exist that reduce any prediction to its inputs by construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing steps. The central argument rests on the concrete task demonstration rather than any self-definitional or fitted-input mechanism, making the finding self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
MLE-bench: Evaluating Machine Learning Agents on Machine Learning Engineering
Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Lilian Weng, and Aleksander Mądry. MLE-bench: Evaluating machine learning agents on machine learning engineering. arXiv preprint arXiv:2410.07095, 2024. doi: 10.48550/arXiv.2410.07095
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2410.07095 2024
-
[2]
Ecosystem demography (ED) model.https://gel.umd.edu/ed.php,
Global Ecology Lab. Ecosystem demography (ED) model.https://gel.umd.edu/ed.php,
-
[3]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world GitHub issues? arXiv preprint arXiv:2310.06770, 2023. doi: 10.48550/arXiv.2310.06770
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2310.06770 2023
-
[4]
Lei Ma, George Hurtt, Lesley Ott, Ritvik Sahajpal, Justin Fisk, Rachel Lamb, Hao Tang, Steve Flanagan, Louise Chini, Abhishek Chatterjee, and Joseph Sullivan. Global evaluation of the ecosystem demography model (ED v3.0).Geoscientific Model Development, 15: 1971–1994, 2022. doi: 10.5194/gmd-15-1971-2022
-
[5]
Self-Refine: Iterative Refinement with Self-Feedback
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegr- effe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bod- hisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback.arXiv preprint arXiv:2303.17651, 2023. doi: ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.17651 2023
-
[6]
Paul R. Moorcroft, George C. Hurtt, and Stephen W. Pacala. A method for scaling vegetation dynamics: The ecosystem demography model (ED).Ecological Monographs, 71 (4):557–586, 2001. doi: 10.1890/0012-9615(2001)071[0557:AMFSVD]2.0.CO;2
-
[7]
Nhat-Minh Nguyen. Physics is all you need? a case study in physicist-supervised AI development of scientific software.arXiv preprint arXiv:2605.30353, 2026
Pith/arXiv arXiv 2026
-
[8]
Hermes agent: An open-source self-improving autonomous AI agent
Nous Research. Hermes agent: An open-source self-improving autonomous AI agent. https://hermes-agent.nousresearch.com/, 2026. Accessed 2026-06-08
2026
-
[9]
Alexander Novikov, Ngân V˜ u, Marvin Eisenberger, Emilien Dupont, Po-Sen Huang, Adam Zsolt Wagner, Sergey Shirobokov, Borislav Kozlovskii, Francisco J. R. Ruiz, Abbas Mehrabian, M. Pawan Kumar, Abigail See, Swarat Chaudhuri, George Holland, Alex Davies, Sebastian Nowozin, Pushmeet Kohli, and Matej Balog. AlphaEvolve: A coding agent for scientific and algo...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2506.13131 2025
-
[10]
Hidden stratification causes clinically meaningful failures in machine learning for medical imaging
Luke Oakden-Rayner, Jared Dunnmon, Gustavo Carneiro, and Christopher Ré. Hidden stratification causes clinically meaningful failures in machine learning for medical imaging. arXiv preprint arXiv:1909.12475, 2019. doi: 10.48550/arXiv.1909.12475
-
[11]
Introducing GPT-5.5
OpenAI. Introducing GPT-5.5. https://openai.com/index/introducing-gpt-5-5/,
-
[12]
Extending the autoresearch loop
Dev Paragiri. Extending the autoresearch loop. https://paragiri.com/blog/2026/ autoresearch-paradigm-fire/, 2026. Accessed 2026-05-30
2026
-
[13]
Reflexion: Language Agents with Verbal Reinforcement Learning
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning.arXiv preprint arXiv:2303.11366, 2023. doi: 10.48550/arXiv.2303.11366
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.11366 2023
-
[14]
Yutaro Yamada, Robert Tjarko Lange, Cong Lu, Shengran Hu, Chris Lu, Jakob Foerster, Jeff Clune, and David Ha. The AI scientist-v2: Workshop-level automated scientific discovery via agentic tree search.arXiv preprint arXiv:2504.08066, 2025. doi: 10.48550/ arXiv.2504.08066
Pith/arXiv arXiv 2025
-
[15]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM-as-a-judge with MT-bench and chatbot arena.arXiv preprint arXiv:2306.05685, 2023. doi: 10.48550/arXiv.2306.05685. 9
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2306.05685 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.