Acceptance-Test-Driven Evaluation Protocols for Business-Centric LLM Systems
Pith reviewed 2026-06-28 13:24 UTC · model grok-4.3
The pith
Acceptance-test protocols turn stakeholder goals into release gates that must pass before any LLM change is accepted.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
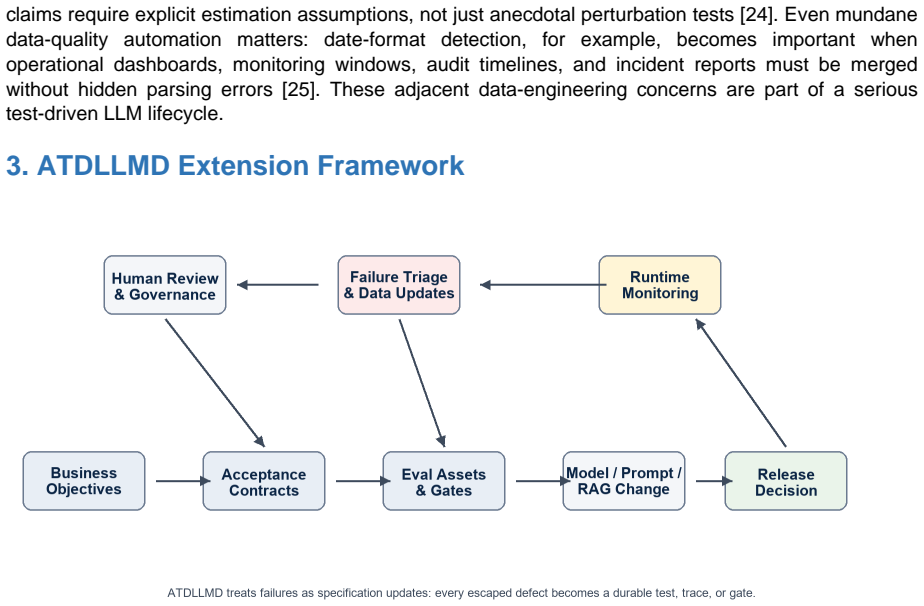
Translating stakeholder goals into executable acceptance tests before any prompt, model, retrieval, or agent change creates a red-train-green lifecycle in which systems are improved only until multidimensional release gates are satisfied, replacing post-hoc benchmarking with upfront behavioral contracts, monitoring signals, and evidence artifacts.
What carries the argument
The red-train-green lifecycle that defines failing acceptance tests first, then improves the LLM system, and releases only when gates pass.
If this is right
- LLM changes are accepted only after multidimensional gates are satisfied rather than after benchmark scores improve.
- Stakeholder requirements become executable contracts that generate monitoring signals and evidence artifacts.
- Development workflows can be compared using the governance-oriented metric stack.
- The protocol applies across prompt changes, retrieval design, fine-tuning, guardrails, and data augmentation.
Where Pith is reading between the lines
- The protocol could be embedded in existing continuous integration pipelines to enforce gates automatically.
- It may extend to regulated domains where audit trails must link each model change to specific institutional rules.
- Teams might discover that some goals resist translation into tests, revealing limits of the approach.
Load-bearing premise
Stakeholder goals for LLM behavior can be translated into executable acceptance tests that reliably capture deterministic requirements despite the underlying probabilistic nature of the models.
What would settle it
An empirical comparison in which acceptance-test-driven workflows produce no measurable improvement in safety, reliability, or auditability over prompt-first and benchmark-after workflows on the same institutional requirements.
Figures
read the original abstract
Large language model (LLM) applications are increasingly expected to satisfy deterministic institutional requirements while relying on probabilistic generative components. This mismatch makes ordinary post-hoc benchmarking insufficient for systems that must be safe, reliable, auditable, and economically useful. This paper contributes an evaluation-protocol extension for operational LLM systems grounded in acceptance-test-driven development, safety engineering, and business-centric validation. The extension translates stakeholder goals into executable behavioral contracts, release gates, monitoring signals, and evidence artifacts before prompt, model, retrieval, or agent changes are accepted. It adapts the red-green-refactor discipline of test-driven development to a red-train-green lifecycle: first define failing acceptance tests for desired behavior, then improve the LLM system through prompt changes, retrieval design, fine-tuning, guardrails, or data augmentation, and finally release only when multidimensional gates are satisfied. The contribution is a governance-oriented metric stack, reference architecture, and empirical protocol for comparing acceptance-test-driven LLM development against prompt-first and benchmark-after workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes an acceptance-test-driven evaluation protocol for business-centric LLM systems to address the mismatch between deterministic institutional requirements and probabilistic generative components. It contributes a governance-oriented metric stack, reference architecture, and empirical protocol by adapting test-driven development into a red-train-green lifecycle: define failing acceptance tests for desired behavior, improve via prompt changes or other means, and release only when multidimensional gates are satisfied. The protocol translates stakeholder goals into executable behavioral contracts, release gates, monitoring signals, and evidence artifacts.
Significance. If the protocol can be operationalized with reliable mechanisms for non-determinism, it could meaningfully extend software engineering practices to LLM systems, enabling more auditable and business-aligned development workflows than post-hoc benchmarking. The manuscript provides no derivations, data, comparisons, or validation, so any significance remains conditional on future empirical demonstration.
major comments (2)
- [Abstract] Abstract, second paragraph: the central claim that the protocol supplies executable behavioral contracts and release gates enforcing deterministic requirements is load-bearing for the contribution but unsupported, as no mechanism is specified for reconciling LLM output variability with consistent pass/fail decisions (e.g., sampling strategy, aggregation rule, or tolerance for non-determinism).
- [red-train-green lifecycle] Description of the red-train-green lifecycle: the adaptation presupposes that acceptance tests can reliably capture deterministic requirements despite probabilistic generation, yet the text supplies no concrete semantics for test execution or failure criteria, which directly undermines the claim that this lifecycle solves the mismatch identified in the opening.
minor comments (1)
- The term 'red-train-green lifecycle' is introduced as an invented entity without reference to related work on test-driven adaptations in AI or probabilistic systems.
Simulated Author's Rebuttal
We thank the referee for the constructive review. The comments correctly identify that the submitted manuscript lacks concrete mechanisms and semantics for handling non-determinism in acceptance testing. We will undertake major revisions to address these gaps by adding explicit specifications, while preserving the conceptual contribution of the red-train-green protocol.
read point-by-point responses
-
Referee: [Abstract] Abstract, second paragraph: the central claim that the protocol supplies executable behavioral contracts and release gates enforcing deterministic requirements is load-bearing for the contribution but unsupported, as no mechanism is specified for reconciling LLM output variability with consistent pass/fail decisions (e.g., sampling strategy, aggregation rule, or tolerance for non-determinism).
Authors: We agree that the abstract's claim is unsupported in the current text, as no mechanisms for variability are described. This is a genuine limitation of the initial submission. We will revise the abstract to qualify the claim and add a dedicated subsection on non-determinism reconciliation, specifying sampling strategies (e.g., 5-10 generations per test), aggregation rules (e.g., majority vote or statistical thresholds), and tolerance levels (e.g., allowing up to 20% variance if business requirements permit). These additions will make the executable contracts and release gates operational. revision: yes
-
Referee: [red-train-green lifecycle] Description of the red-train-green lifecycle: the adaptation presupposes that acceptance tests can reliably capture deterministic requirements despite probabilistic generation, yet the text supplies no concrete semantics for test execution or failure criteria, which directly undermines the claim that this lifecycle solves the mismatch identified in the opening.
Authors: The referee accurately notes the absence of concrete semantics. The manuscript provides only a high-level description without execution details or failure criteria. We will expand the red-train-green lifecycle section with explicit test execution protocols (e.g., API invocation parameters, use of temperature=0 where feasible, or controlled sampling) and failure criteria (e.g., hybrid deterministic checks for format plus probabilistic ones such as embedding cosine similarity thresholds or calibrated LLM-as-judge scores with human audit trails). This will directly operationalize how the lifecycle addresses the deterministic-probabilistic mismatch. revision: yes
Circularity Check
No significant circularity; proposal is self-contained conceptual framework
full rationale
The paper presents a methodological proposal for an acceptance-test-driven evaluation protocol adapted from TDD practices, without any equations, fitted parameters, predictions, or derivations that reduce to their own inputs. No self-citations are invoked as load-bearing uniqueness theorems, and the central contribution is framed as an extension of existing engineering disciplines rather than a result derived from the protocol itself. The description of translating goals into contracts and gates is definitional of the proposed method but does not create a self-referential loop where success is asserted solely by the framing.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Stakeholder goals can be expressed as executable behavioral contracts that LLM systems can be made to satisfy
invented entities (1)
-
red-train-green lifecycle
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Beck, K. (2003). Test-Driven Development: By Example. Addison-Wesley
2003
-
[2]
Farago, D. (2024). ATDLLMD: Acceptance test-driven LLM development. Softwaretechnik-Trends, 44(2), 49th Workshop on Test, Analysis and Verification
2024
-
[3]
Parupally, V. R. (2026). ATDLLMD: A test-driven framework for safe, reliable, and business-centric LLM development. IET Conference Proceedings CP967, 2025(43), 612-618. https://doi.org/10.1049/icp.2025.4778
-
[4]
T., Wu, T., Guestrin, C., and Singh, S
Ribeiro, M. T., Wu, T., Guestrin, C., & Singh, S. (2020). Beyond accuracy: Behavioral testing of NLP models with CheckList. Proceedings of ACL, 4902-4912. https://doi.org/10.18653/v1/2020.acl-main.442 Preprint 7
-
[5]
D., Re, C., Acosta-Navas, D., Hudson, D
Liang, P., Bommasani, R., Lee, T., Tsipras, D., Soylu, D., Yasunaga, M., Zhang, Y., Narayanan, D., Wu, Y., Kumar, A., Newman, B., Yuan, B., Yan, B., Zhang, C., Cosgrove, C., Manning, C. D., Re, C., Acosta-Navas, D., Hudson, D. A., Zelikman, E., et al. (2023). Holistic evaluation of language models. Transactions on Machine Learning Research
2023
-
[6]
Gao, L., Tow, J., Abbasi, B., Biderman, S., Black, S., DiPofi, A., Foster, C., Golding, L., Hsu, J., Le Noac'h, A., Li, H., McDonell, K., Muennighoff, N., Ociepa, C., Phang, J., Reynolds, L., Schoelkopf, H., Skowron, A., Sutawika, L., Tang, E., Thite, A., Wang, B., Wang, K., & Zou, A. (2024). The Language Model Evaluation Harness. Zenodo. https://doi.org/...
-
[7]
P., Zhang, H., Gonzalez, J
Zheng, L., Chiang, W.-L., Sheng, Y., Zhuang, S., Wu, Z., Zhuang, Y., Lin, Z., Li, Z., Li, D., Xing, E. P., Zhang, H., Gonzalez, J. E., & Stoica, I. (2023). Judging LLM-as-a-judge with MT-Bench and Chatbot Arena. Advances in Neural Information Processing Systems, Datasets and Benchmarks Track
2023
-
[8]
Zhang, Z., Lei, L., Wu, L., Sun, R., Huang, Y., Long, C., Liu, X., Lei, X., Tang, J., & Huang, M. (2024). SafetyBench: Evaluating the safety of large language models. Proceedings of ACL
2024
-
[9]
Perez, E., Huang, S., Song, F., Cai, T., Ring, R., Aslanides, J., Glaese, A., McAleese, N., & Irving, G. (2022). Red teaming language models with language models. Proceedings of EMNLP, 3419-3448. https://doi.org/10.18653/v1/2022.emnlp-main.225
-
[10]
Wang, W., Haddow, B., Birch, A., & Peng, W. (2024). Assessing factual reliability of large language model knowledge. Proceedings of NAACL-HLT, 805-819. https://doi.org/10.18653/v1/2024.naacl-long.46
-
[11]
Mugaanyi, J., Cai, L., Cheng, S., Lu, C., & Huang, J. (2024). Evaluation of large language model performance and reliability for citations and references in scholarly writing: Cross-disciplinary study. Journal of Medical Internet Research, 26, e52935. https://doi.org/10.2196/52935
-
[12]
and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =
Bender, E. M., Gebru, T., McMillan-Major, A., & Shmitchell, S. (2021). On the dangers of stochastic parrots: Can language models be too big? Proceedings of FAccT, 610-623. https://doi.org/10.1145/3442188.3445922
-
[13]
On the Opportunities and Risks of Foundation Models
Bommasani, R., Hudson, D. A., Adeli, E., Altman, R., Arora, S., von Arx, S., Bernstein, M. S., Bohg, J., Bosselut, A., Brunskill, E., Brynjolfsson, E., Buch, S., Card, D., Castellon, R., Chatterji, N., Chen, A., Creel, K., Davis, J. Q., Demszky, D., Donahue, C., et al. (2021). On the opportunities and risks of foundation models. arXiv:2108.07258
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[14]
National Institute of Standards and Technology. (2023). Artificial Intelligence Risk Management Framework (AI RMF 1.0). NIST AI 100-1. https://doi.org/10.6028/NIST.AI.100-1
-
[15]
National Institute of Standards and Technology. (2024). Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile. NIST AI 600-1. https://doi.org/10.6028/NIST.AI.600-1
-
[16]
OWASP Foundation. (2024). OWASP Top 10 for LLM Applications 2025. OWASP GenAI Security Project
2024
-
[17]
ISO/IEC. (2023). ISO/IEC 42001:2023: Information technology - Artificial intelligence - Management system. International Organization for Standardization
2023
-
[18]
Bai, Y., Kadavath, S., Kundu, S., Askell, A., Kernion, J., Jones, A., Chen, A., Goldie, A., Mirhoseini, A., McKinnon, C., Chen, C., Olsson, C., Olah, C., Hernandez, D., Drain, D., Ganguli, D., Li, D., Tran-Johnson, E., Perez, E., Kerr, J., et al. (2022). Constitutional AI: Harmlessness from AI feedback. arXiv:2212.08073
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[19]
Stiennon, N., Ouyang, L., Wu, J., Ziegler, D., Lowe, R., Voss, C., Radford, A., Amodei, D., & Christiano, P. (2020). Learning to summarize with human feedback. Advances in Neural Information Processing Systems, 33, 3008-3021
2020
-
[20]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Kuttler, H., Lewis, M., Yih, W.-t., Rocktaschel, T., Riedel, S., & Kiela, D. (2020). Retrieval-augmented generation for knowledge-intensive NLP tasks. Advances in Neural Information Processing Systems, 33, 9459-9474
2020
-
[21]
Ferreira, M., Viegas, L., Faria, J. P., & Lima, B. (2025). Acceptance test generation with large language models: An industrial case study. arXiv:2504.07244
-
[22]
(2025, July)
Liang, Z. (2025, July). Efficient representations for high-cardinality categorical variables in machine learning. In 2025 International Conference on Advanced Machine Learning and Data Science (AMLDS) (pp. 1-11). IEEE
2025
-
[23]
(2024, December)
Liang, Z. (2024, December). Harmonizing metadata of language resources for enhanced querying and accessibility. In 2024 5th International Conference on Computers and Artificial Intelligence Technology (CAIT) (pp. 642-650). IEEE
2024
-
[24]
(2025, May)
Liang, Z. (2025, May). Enhanced Estimation Techniques for Certified Radii in Randomized Smoothing. In 2025 8th International Conference on Artificial Intelligence and Big Data (ICAIBD) (pp. 375-384). IEEE
2025
-
[25]
(2025, July)
Liang, Z. (2025, July). Automating Date Format Detection for Data Visualization. In 2025 International Conference on Advanced Machine Learning and Data Science (AMLDS) (pp. 756-764). IEEE
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.